







 超级会员免费看
超级会员免费看
 本文介绍了视觉Transformer的基本架构,包括图像块的分块和嵌入,以及Transformer编码器的使用。接着讨论了多种改进策略,如训练策略优化、patch tokenization、self-attention改进和卷积层的引入,以提升模型性能和训练效率。这些模型适用于图像分类,并可进一步应用于目标检测、图像分割等任务。
本文介绍了视觉Transformer的基本架构,包括图像块的分块和嵌入,以及Transformer编码器的使用。接着讨论了多种改进策略,如训练策略优化、patch tokenization、self-attention改进和卷积层的引入,以提升模型性能和训练效率。这些模型适用于图像分类,并可进一步应用于目标检测、图像分割等任务。
视觉Transformer(Vision Transformer)
Vision Transformer.
Transformer是基于自注意力机制(self-attention mechanism)的深度神经网络,该模型在$2017$年$6$月被提出,并逐渐在自然语言处理任务上取得最好的性能。
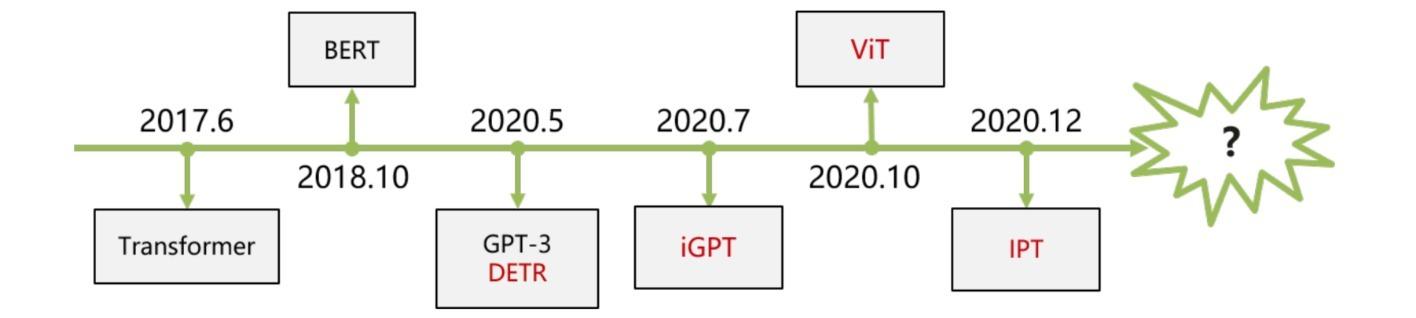
Transformer最近被扩展到计算机视觉任务上。由于Transformer缺少CNN的inductive biases如平移等变性 (Translation equivariance),通常认为Transformer在图像领域需要大量的数据或较强的数据增强才能完成训练。随着结构设计不断精细,也有一些视觉Transformer只依赖小数据集就能取得较好的表现。
本文主要介绍视觉

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 6629
6629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











