








 该专栏为热销专栏榜 第22名
该专栏为热销专栏榜 第22名 超级会员免费看
超级会员免费看


模仿学习 (Imitation Learning) 原理与代码实例讲解
文章目录
1.背景介绍
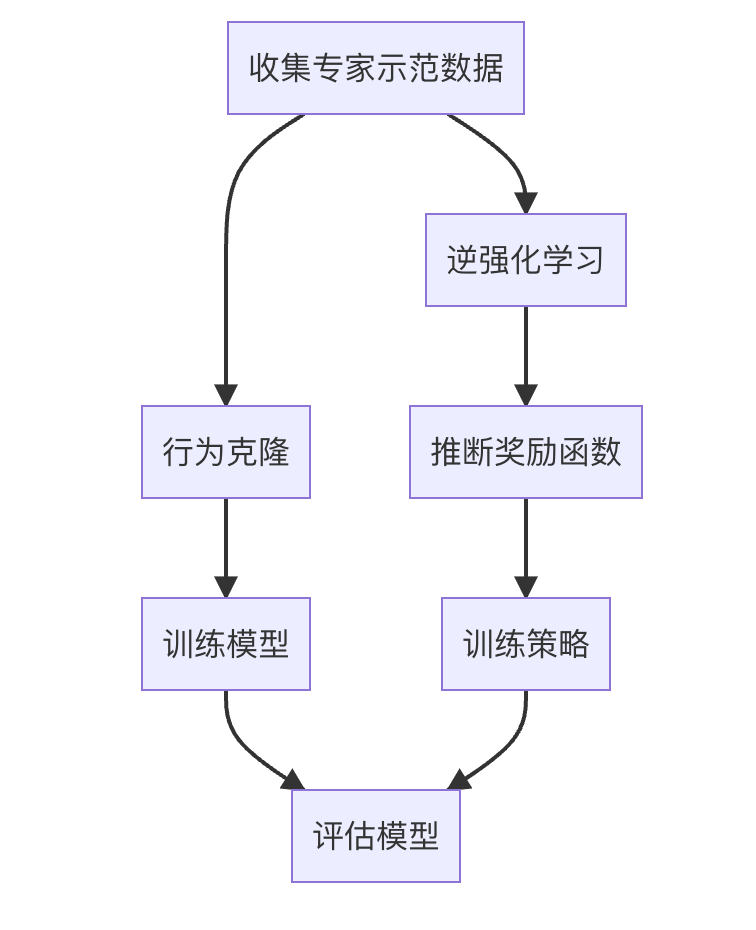
模仿学习(Imitation Learning,IL)是一种机器学习方法,旨在通过模仿专家的行为来训练智能体。与传统的强化学习不同,模仿学习不需要明确的奖励函数,而是通过观察和模仿专家的行为来学习策略。这种方法在机器人控制、自动驾驶、游戏AI等领域有广泛应用。
模仿学习的核心思想是通过专家示范的数据来训练模型,使其能够在相似的环境中执行类似的任务。模仿学习的优势在于可以快速收敛,尤其在奖励函数难以设计或环境复杂的情况下,模仿学习提供了一种有效的解决方案。
2.核心概念与联系
2.1 模仿学习的基本概念
模仿学习主要包括以下几个基本概念:
- 专家示范(Expert Demonstration):专家在特定任务中的行为数据,通常包括状态、动作对。
- 策略

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 127
127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











