








 该专栏为热销专栏榜 第23名
该专栏为热销专栏榜 第23名 超级会员免费看
超级会员免费看


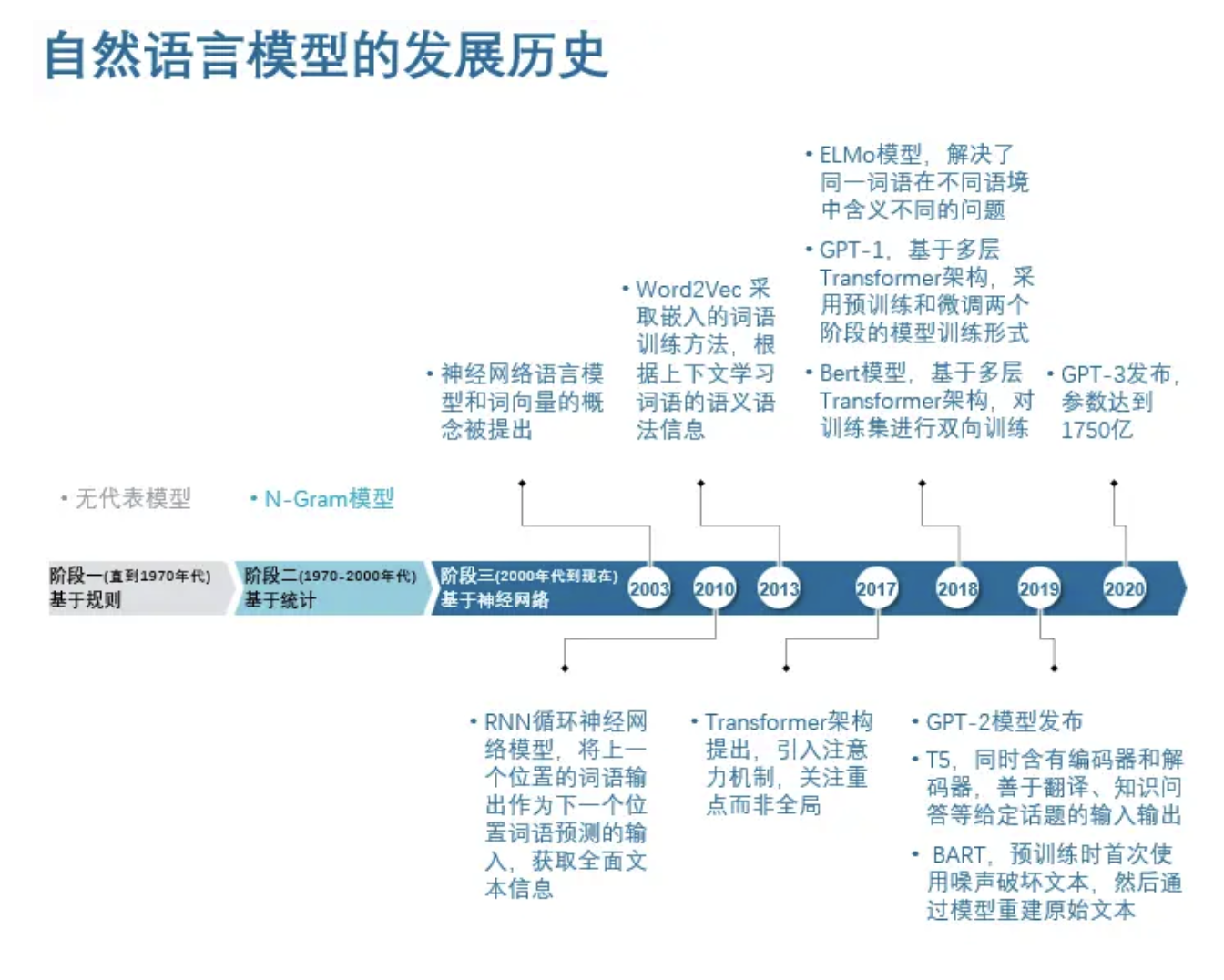
阶段一(直到1970年代),模型基于规则:该阶段自然语言处理主要基于手写规则,只能处理少量数据
阶段二(1970-2000年代),模型基于统计:从数学统计的角度预测下个词的出现概率,代表模型如N-Gram等,推理过程非常直观,但是推理结果非常受数据集的影响,容易出现数据稀疏(即空值)等问题
阶段三(2000年代到现在),模型基于神经网络:模型开始像人脑一样学习,2017年以前主要是小模型阶段, 在 2017年Transformer发布之后,模型开始尝试大量数据的训练学习,进入大语言模型阶段,在加入人工干预的反馈基础上,模型效果攀上新的台阶。
自然语言模型的发展历程
作者:禅与计算机程序设计艺术 / Zen and the Art of Computer Programming / TextGenWebUILLM
文章目录
- 自然语言模型的发展历程
-
- 自然语言模型的发展历程1
- 1. 背景介绍
- 2. 核心概念与联系
-
- 2.1 语言模型(Language Model)
- 2.2 n-gram模型
- 2.3 平滑技术(Smoothing)
- 2.4 神经网络语言模型(Neural Network Language Model,NNLM)
- 2.5 词嵌入(Word Embedding)
- 2.6 循环神经网络(Recurrent Neural Network,RNN)
- 2.7 长短期记忆网络(Long Short-Term Memory,LSTM)
- 2.8 注意力机制(Attention Mechanism)
- 2.9 Transformer
- 2.10 预训练语言模型(Pre-trained Language Model)
- 3. 核心算法原理 & 具体操作步骤
- 4. 数学模型和公式 & 详细讲解 & 举例说明
- 5. 项目实践:代码实例和详细解释说明
- 6. 实际应用场景
- 7. 工具和资源推荐
- 8. 总结:未来发展趋势与挑战
- 9. 附录:常见问题与解答
- 自然语言模型的发展历程2
- 1. 背景介绍
- 2. 核心概念与联系
- 3. 核心算法原理与具体操作步骤
- 4. 数学模型和公式详细讲解与举例说明
- 5. 项目实践:代码实例和详细解释说明
- 6. 实际应用场景
- 7. 工具和资源推荐
- 8. 总结:未来发展趋势与挑战
- 9. 附录:常见问题与解答
自然语言模型的发展历程1
关键词:统计语言模型、n-gram模型、神经网络语言模型、Transformer、GPT、BERT

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 61
61

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











