







8.1 概述
联邦学习作为一种保障数据安全的建模方法,在保险、金融等行业中的应用前景十分广泛,因为这类行业昔谝受到更为严格的监管和隐私保护法律法规的约束,跨部门或者跨枧构之间的数据,无法被直接共卓进行机器学习模型训练。因此,信助联邦学习来训练一个联邦模型不失为一种有效的解决方案。
以智慧零售业务为例,智慧零售业务涉及的数据特征。通常可以分为用户资产属性、用户个人偏好,以及产品特征三大部分。这三种数据特征很可能分散在三个不同的部门或企业中。例如,银行拥有用户的资产属性数据,社交产品拥有用户个人的画像数据,而购物网站则拥有产品的数据特征。在这种情况下,集中式的处理流程如图8-1所示。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M19qrgc0-1692151567370)(https://p6-novel.byteimg.com/large/novel-pic/188e7319e63963f9c10bbf08d43ad785)]](https://img-blog.csdnimg.cn/93e50d9770b6419d80b21f1dd98cfdd9.png)
图8-1中式的处理流程。利用分散在不同机构的异构特征数据进行中心化训练
但在当前的数据监管法律法规约束下,特别是隐私数据法案不断完善的前提下,这种中心化建模方式面临着两大难题:
第一,出于保护用户隐私及企业数据安全等原因,银行、社交网站和购物网站三方之间通常存在数据壁垒,即三方的数据通常以割裂的形式存在,因此,智慧零售的业务部门无法同时获取这三方数据进行聚合并建模。
第二,三方的特征数据通常是异构的,即三方数据所在的特征空间不一致,传统的机器学习模型对异构特征数据的处理,需要先对数据进行有效的预处理,转化为统一的数据特征表示。如第一点所述,如果由于数据割裂导致不能获取某一方的数据,相当于造成了特征的缺失,本地单点建模的性能效果将受到很大的影响。
而联邦学习的提出为解决这一类问题提供了可行的解决方案,在本书第1章中,我们介绍了联邦学习的分类,包括横向联邦学习和纵向联邦学习两大主流类型,本章我们将探讨这两种类型的联邦学习如何应用于金融保险领域。
具体来说,本章将分析两个具体的应用案例,分别是:基于纵向联邦学习进行保险个性化定价;基于横向联邦学习进行银行间的反洗钱建模。我们将详细分析如何使用联邦学习技术打破机构间的数据壁垒,保证数据在不出本地的前提下,仍然能够有效地训练机器学习模型,并利用联邦模型提升金融产品的能力。
8.2 基于纵向联邦学习的保险个性化定价案例
由于受到其他行业高度个性化服务的影响,保险行业的发屉已经从过去的统一保险费用定价向个性化定价转变,高度个性化的保费俨然是一个新的发屉趋势,《2020年保险业技术发屉趋势》中指出,当前有超过80%的保险消费者会寻找某种形式的个性化服务,比如定价、推荐或来自保险公司的信息。
8.2.1 案例描述
保险个性化定价,与其他个性化服务一样,需要平衡保险公司和客户之间的关系。一方面,消费者会根据自身的需要选择符合个人的产品;而另一方面,为了提高客户满意度,保险公司也需要具备扎实的数据洞察力基础。
埃森哲咨洵公司的一项研究显,77%的保险客户愿意提供自己的使用和行为数据以换取保险建议、更快的理赔或更低的保费。保险领域显然正在利用这一点,因为只有20%的客户认为他们的保险提供商没有任何客户定制方面的经验。
但保险业的个性化定价却受到很多因素的制约,导致其模型的构建往往不准确,其中主要的难点在于数据层面。对保险进行个性化定价,需要结合每一位客户的特征属性,但是客户的数据属性多种多样,包括央行征信报告、税收、信贷、消费能力、年龄、职业等。然而,对于金融粗构来说,能直接使用的数据一般只有中央银行的信用报告和信贷数据,其他数据都在其他机构中,数据的缺失是致个性化建模不准确的最关键因素。
图8-2所示的是建模中的数据情况,图8-2(a)所示的是理想情况下,构建保险定价模型期望韋到的数据,包括社交属性中的年龄、职业、收入等;购买属性中的消费额度等;银行属性中的贷款记录和征信等。但在现实情况中,如前面所述,每一项数据都保存在不同的机构中,银行能获取的只有贷款记录数据和征信数据,如图8一2(b)
为此,我们利用前面提到的纵向联邦学习的思想,它非常适合处理跨部门或者跨机构之间联台建模的问题。
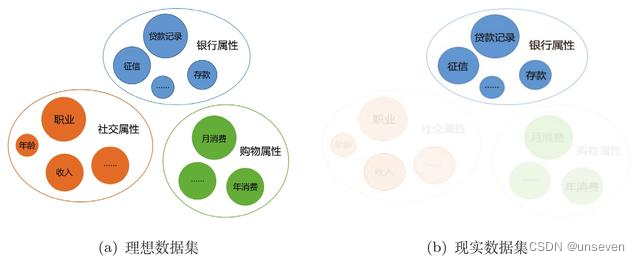
图8-2保睑个性化定价在理想和现实场吕下的数庭建倥情况
8.2.2 保险个性化定价的纵向联邦建模
本案例我们要解决的是:联合多方数据构建一个保险个性化定价模型,用来预测一个客户的出险概率。假设现在保险公司与一家出租车公司合作,希望通过个性化模型帮助出租车公司预测客户的出险概率,同时保险公司还与其他行业构公司有合作,但是这三方之间的数据是不连通、也是不能共享的,如图8-3所示。保险公司如何在合法合规的前提下,朕合两方的数据联合建模,提升保险定价的模型效果呢?
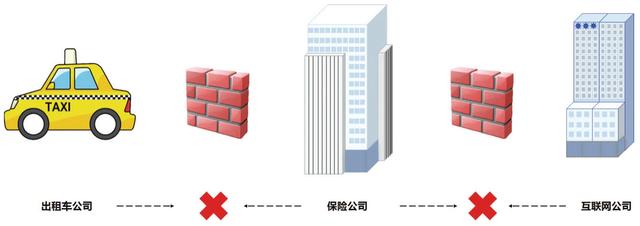
图8.3 本例的三个参与方
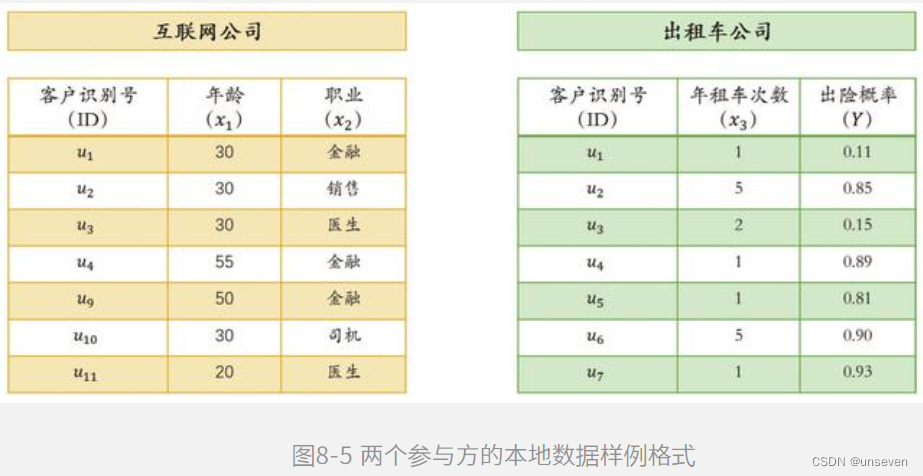
出租车公司有每一个客户的订单信息、车辆信息和业务表现等,我们把这些特征数据记为X1,同时出租车公司还有历史订单中客户的出险概率,记为Y。此外,该保险公司与另一家互朕网公司也有业务合作在该互朕网公司的产品中,用户注册时会带有客户的画像属性,包括人口属性、兴趣爱好、教育信息和财务状况等,我们将这部分特征数据记为X2,这样,可以将问题构建为如图8-4所示的纵向联邦学习建模。

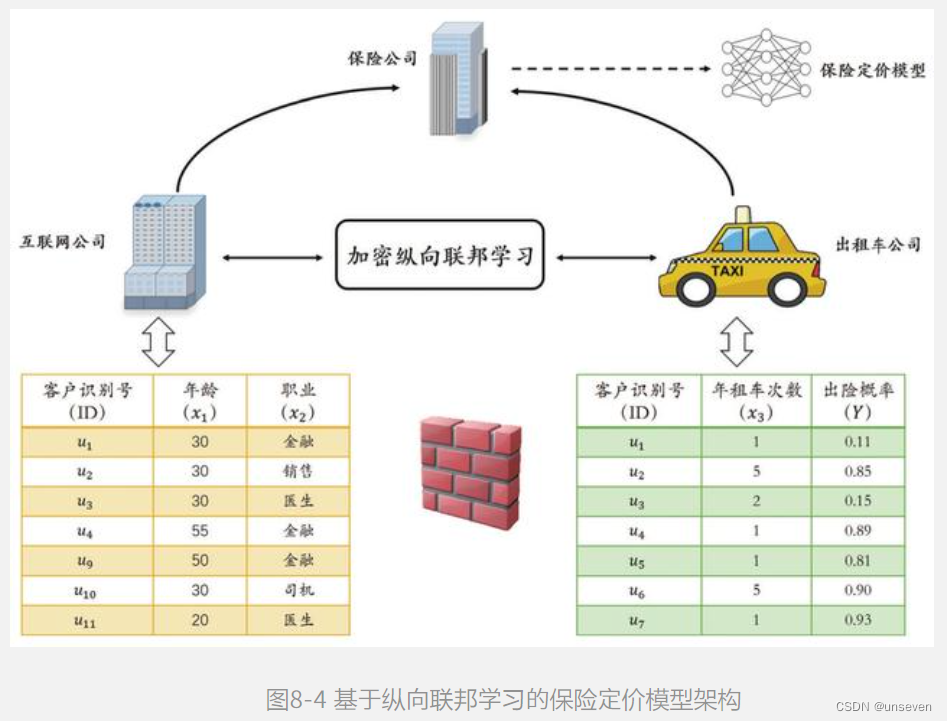
个性化的保险定价,本质上是根据客户的特征信息预测出险概率,可以将问题归结为二分类问题,本案例中我们使厍渣辑斯蒂回归模型来预测保险定价:

要在数据不共享的前提下,求解式(8.1)的最优参数W,这是纵向联邦学习的经典应用,第6章详细讲解了如何使用FATE进行纵向线性回归的训练求解,本案例的求解过程基本与其一致,只需要将训练模型从线性回归改为逻辑斯蒂回归朗可,主要的执行步骤包括:
(1)求取相交的用户ID集合:在图8-5中,我们看到在联合建模的时候,两家公司所含有的用户旧集合不同,即用户群体不可能完全重叠,因此第一步需要找到相同的用户ID集合,这种在不泄露数据的前提下,找到双方公共ID集合的技术称为私有集交集(PSI),本届提供一种基于散列与RSA加密法相结合的实现方案。
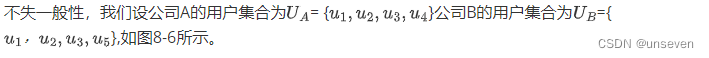

步骤1:公司B利用RSA算法生成公钥对(n,e)和私钥对(n,d),并将公钥对(n,e)发送给公司A




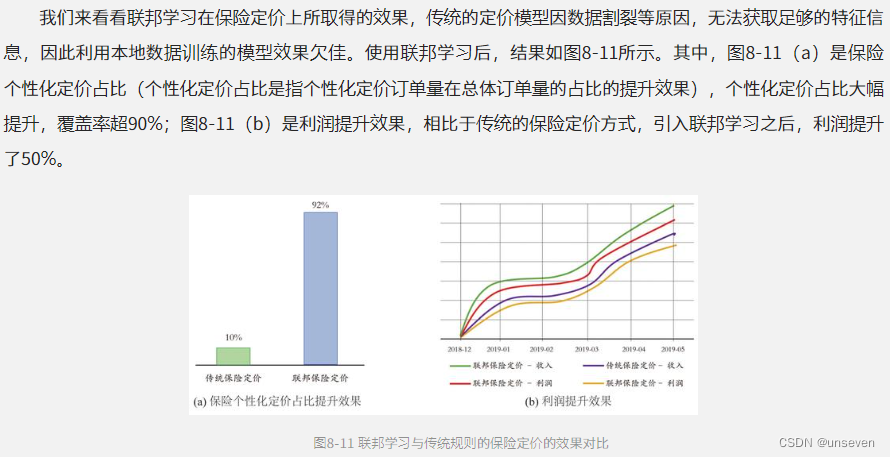
8.2.3 效果对比
8.3 基于横向联邦的银行间反洗钱模型案例

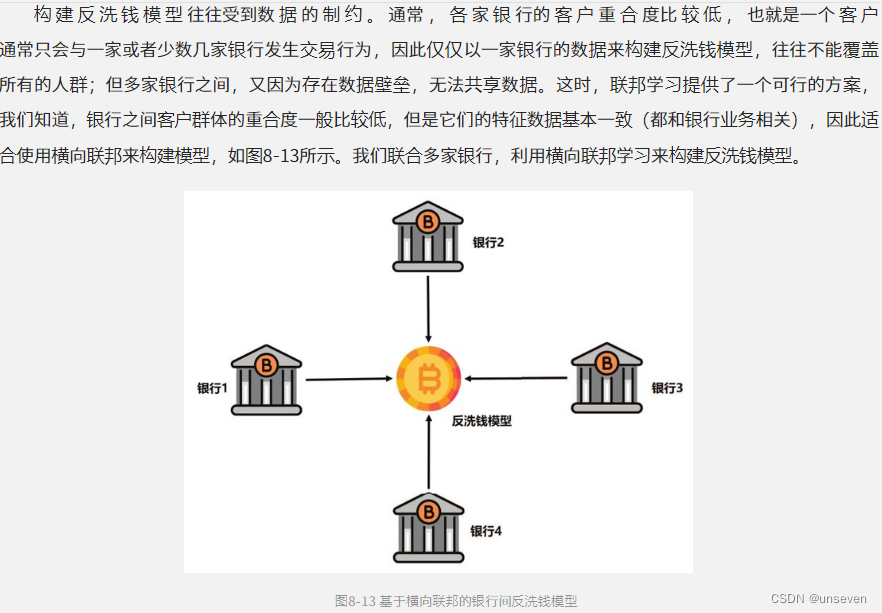
8.3.2 反洗钱模型的横向联邦建模
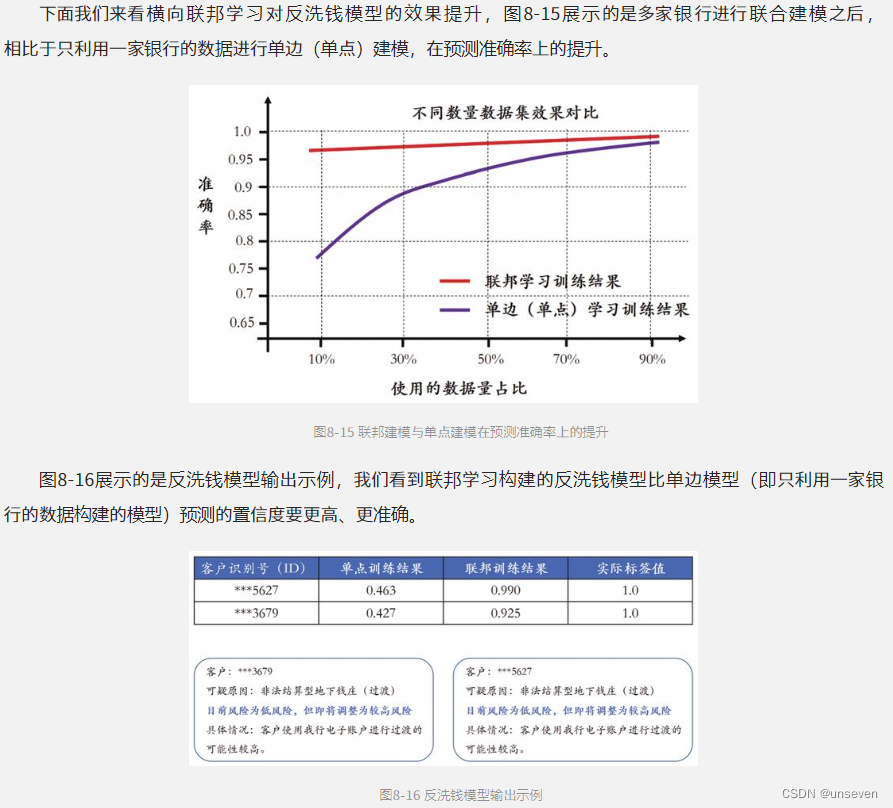
8.3.3 效果对比
8.4 金融领域的联邦建模难点
8.4.1 数据不平衡

8.4.2 可解析性
事实上,在金领域,绝大部分场景下我们采用的都是线性模型,其中一个主要原因是考虑可解析性。在金场景下,面向的可解析对象包括客户、政府监管机构和开发人员,线性模型相比于复杂的神经网络筻法,在性能上可能会微下降,但是具有很强的可解析性。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











