






利用多模态信息进行可视化问题回答,近年来受到了越来越多的关注。然而,由于视觉内容和自然语言具有截然不同的统计特性,这是一项非常具有挑战性的任务。本文提出了一个称为对抗性多模态网络(AMN)的方法,以更好地理解视频故事的问题回答。在AMN中,受到生成式对抗网络的启发,通过为视频剪辑和相应的文本(例如,字幕和问题)寻找更一致的子空间来学习多模态特征表示。此外,引入了一个自我注意机制来加强所谓的一致性约束,以保持在学习的多模态表示中原始视频片段的视觉线索的自相关性。
文章链接:Adversarial Multimodal Network for Movie Question Answering
一、文章引入
与典型的多模态VQA相比,在多模态MovieQA环境下,跨模态间隙问题更加严重。首先,不同的电影可能有不同的背景、色彩基调、拍摄风格,这使得学习鲁棒的多模态表式非常困难。其次,视觉剪辑和文本字幕在时间坐标上不对齐是很常见的。对于许多视频剪辑来说,不同模式下的语意可能在某个时间点上存在差异,而故事线索通常隐藏在长时间电影的不同时间点上。
多模式MovieQA有三种方法结合视觉剪辑和字幕。第一个基于embedding mapping,它学习一个视觉嵌入矩阵,将视觉嵌入表示和文本特征之和作为组合的多模态表示。第二种方法是基于注意机制的,注意每个视觉区域特征的单词和句子的文本记忆。第三种方法基于紧凑双线性池,计算视觉特征与文本特征之间的紧类外积,得到联合表示。在上述方法中,将视觉表式投射到文本空间的任务中基于注意的模型获得了更好的性能,这得益于组合表示的文本形式。由于问答是文本性的,视频字幕整合表现形式最终必须与之互动,因此将视觉剪辑投射到语言嵌入空间中,可以使其与文本的问答连贯。然而,它们主要关注的是模型应该关注哪些部分而不是视觉部分,而忽略了学习多模态表示分布的特征和故事线索的信息保留问题。
本文从不同的角度解决了多模态电影的问题。作者认为从视觉剪辑和字幕中学习的多模态表示是一个数据生成的过程,在这个过程中获得了健壮的多模态特征,并保留了核心的故事线索。生成式对抗网络(GAN)是一个强大的数据生成框架,它提供了一种生成电影多模态表示的方法。基于上述思想,本文提出了一种新的多模态对抗网络(AMN)模型用于多模态电影查询。将多模态表示学习过程置于GAN框架中。

GAN主要流程类似上图:首先,一代的generator生成一些很差的图片,而一代的discriminator能准确的把生成的图片和真实的图片进行分类(二分类器,对生成的图片输出0,真实的图片输出1)。接着训练出二代的generator,它能生成较好一点的图片,能够让一代的discrminator认为这些生成的图片是真实的图片。然后训练出二代的discriminator,能够准确的识别出真实的图片和二代generator生成的图片。以此类推,训练出三代、四代……N代的generator和discriminator,最后的discriminator无法分辨出生成的图片和真实图片,这个网络就拟合了。
二、主要框架

给定视频片段,相应的字幕,以及一个关于电影的自然语言问题,任务是从多项选择中预测一个准确的自然语言答案。本文的基本思想是通过将视觉剪辑的特征投射到文本空间中来学习电影剪辑的多模态表示,并将任务置于GAN框架中。在该框架中,生成器将可视剪辑特征映射到多模态表示中,期望这些表示与字幕和问题难以区分,而鉴别器则鼓励将它们区分开来。正确的答案是基于学习的多模态表示和相应的问题和候选答案推断出来的。同时,为了在投射过程中保留故事线索的信息,提出了一种自注意机制,对学习后的多模态表式实施一致性约束。
本文提出的AMN框架如上图所示,包括三项内容:对抗性多模态表示学习、基于自注意的一致性约束和答案推理。
2.1 Adversarial Multimodal Representation Learning
将从视觉片段和字幕到多模态特征的多模态表示学习过程视为映射函数G:(V,S)→H,该函数采用预先训练的CNN网络提取的视觉特征图V和基于单词词典We计算出的文本字幕S 作为输入,并输出对抗性多峰表示H。
我们希望H与文字问题和答案保持一致。 将映射函数G作为GAN中的生成器,并考虑另一个模块D作为鉴别器。 对于生成器,鼓励其输出H与相应文本的相关子空间没有区别;对于鉴别符,鼓励对其进行区分。 目标表示为:

其中z表示实际的文本数据。文中使用字幕和问题作为真实的文本数据,并利用一个多重神经网络作为鉴别器。
对于生成器,采用了两层注意力学习过程。在第一层注意中,将H×W区域特征加入到单词字典中。对于框架It中的每个区域特征vtj,首先通过一个映射矩阵Wl将其线性映射到词空间:

然后,给otj∈Rd加上一个词嵌入存储器We:

其中We,k为单词存储器的第k行向量,其帧特征由区域特征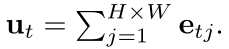 求和计算得到。
求和计算得到。
在第二个注意中,给ut加上嵌入式字幕特征{s1,…,sK}:

由于剪辑特征是根据视觉内容和文字字幕计算的,因此从G生成的H = {h1,…,hT}可以视为学习的电影多模态表示。
2.2 Self-attention based Consistency Constraints
由于上述投影过程可能会丢失电影信息,尤其是故事线索,因此本文提出了一个一致性约束条件,并尝试从已学习的多模态表式中重建视频片段表示。然而,这是困难的,因为原始视觉表示V的元素的维度不同于H的维度。
为了解决这个问题,文中利用一种自注意机制将它们映射到一个固定的维度空间。除了维度的问题,自关注也反映了电影内在的关系,捕捉了电影内部的长时间依赖性,这对于长故事的理解是很重要的。如果他们的自我关注的结果彼此接近,那么整个故事线索就会在两层投射中被保留下来。对于V,首先通过平均池化其区域特征V来缩减其维度,得到V`∈RT×c。然后通过计算T个特征之间的相互作用,得到电影中T个特征之间的关系:

基于片段内关系矩阵α,由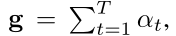 计算得到最终自注意表示,其中αt表示矩阵α的第t行。 同样地,H也有这种自注意机制,只是没有均值运算,因为H本身就是二阶张量,得到自注意表示c。
计算得到最终自注意表示,其中αt表示矩阵α的第t行。 同样地,H也有这种自注意机制,只是没有均值运算,因为H本身就是二阶张量,得到自注意表示c。
为了使g和c的自注意表示尽可能接近,取cos距离作为一致性损失:

2.3 Answer Inference
基于所学习的多模态表示H,计算用于电影问答的剪辑特征为: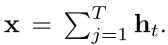 然后使用MovieQA中的方法来回答电影开放式答案的问题:
然后使用MovieQA中的方法来回答电影开放式答案的问题:

最小化答案推理的交叉熵损失:

其中tcorrect是ground-truth的正确答案的标签,I表示指示函数,有5个候选答案,其中只有一个是正确的(即 n = 5)。
到目前为止,电影表现形式x仅仅是基于视觉内容和字幕,与问题和候选答案无关,因此很难发现问题和答案所需的相关信息。此外,还有一些不相关的信息与字幕剪辑,应该删除。为了解决这个问题,我们用q, a, x来更新字幕:

其中s(i)n表示第i个字幕表示的第n个句子,而λ是问题与查询的其余部分之间的折衷超参数。
2.4 Overall Formulation
基于以上,我们的目标是解决以下优化问题:

其中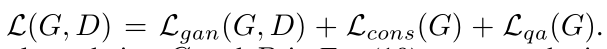
通过对上式中的G和D进行迭代更新,得到最终解:

在学习过程中,采用随机梯度下降法进行优化。
三、实验结果

不同方法在MovieQA数据集的官方验证集和测试集上的结果。

字幕、问题、LMN和AMN的特征分布可视化。
四、主要贡献
(1)提出了一种新的对抗式多模态网络(AMN)模型。
(2)与现有的方法不同,本文将多模态表示学习作为一个数据生成过程,引入了一个对抗性多模态表示学习模块和一个自注意机制来确保满足一致性约束。在多模态电影问答场景中,得到了较好的多模态表示。















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









