






在分析数据时,不可能总是对单个数据表进行分析,有时需要把多个数据表导入到PowerBI中,通过多个表中的数据及其关系来执行一些复杂的数据分析任务,因此,为准确计算分析的结果,需要在数据建模中,创建数据表之间的关系。在PowerBI中,关系(Relationship)是指数据表之间的基数(Cardinality)和交叉筛选方向(Cross Filter Direction)。
我的PowerBI开发系列的文章目录:PowerBI开发
基数(Cardinality)
基数关系类似于关系表的外键引用,都是通过两个数据表之间的单个数据列进行关联,该数据列叫做查找列,两个数据表之间的基数关系是1:1,或者1:N,或者N:1,基数关系表示的含义是:
- 多对一 (N:1):这是最常见的默认类型。这意味着一个表中的列可具有一个值的多个实例,而另一个相关表(常称为查找表)仅具有一个值的一个实例。
- 一对一 (1:1):这意味着一个表中的列仅具有特定值的一个实例,而另一个相关表也是如此。
例如,TableA和TableB之间的基数关系是1:N,那么TableA是TableB的查找表,TableB叫做引用表,在查找表中,查找列的值是唯一的,不允许存在重复值,而在引用表中,查找列的值不唯一。
在PowerBI中,有时,引用表会引用查找表中不存在的数据,默认情况下,PowerBI会自动在查找表中增加一个查找值Blank,所有不存在于查找表中的值,都映射到Blank。
交叉筛选方向(Cross Filter Direction)
筛选方向是筛选的流向,表示一个筛选条件对其他相关表进行过滤,例如,TableA对TableB过滤,其筛选方向可以是双向,或单向:
- 双向:默认方向,这意味着为进行筛选,两个表均被视为是同一个表,这非常适用于其周围具有多个查找表的单个表。
- 单向:这意味着一个表只能对另外一个表进行筛选,而不能反向过滤。
一,双向筛选关系
在星型结构中,中间是一个引用表,周围是多个查找表,引用表和查找表之间的筛选关系是双向的,如下所示:
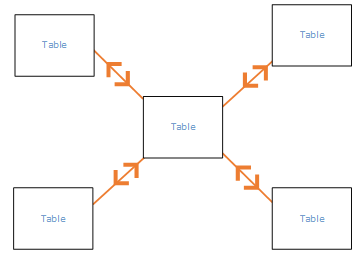
通常情况下,双向筛选用于星型结构,是默认的方向,但是,双向筛选不太适合以下关系图中的模式,在该模式中,筛选方向形成一个循环,对于此类关系模式,双向筛选会创建一组语义不明的关系,例如,求取 TableX 中某个字段的总和,如果选择按照 TableY 中的某个字段进行筛选,则不清楚筛选器应该如何流动,是通过顶部表,还是底部表进行流动?
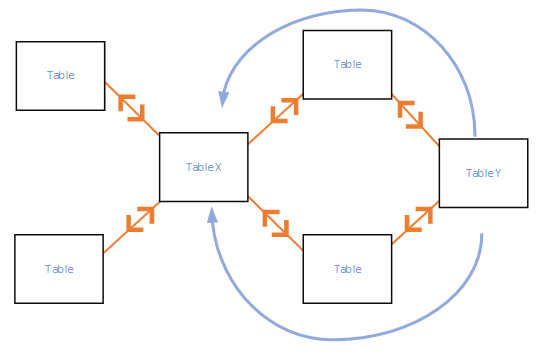
如果双向筛选导致数据关系的多义性,那么,可以导入表格两次(第二次使用其他名称)以消除循环。 这会产生类似于星型架构的关系模式,借助星型架构,所有关系均可设置为“双向”。
二,创建间接关系
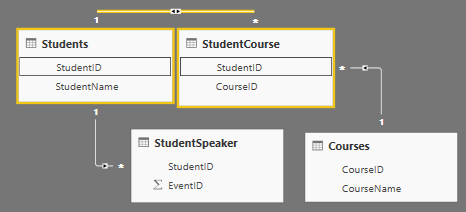
在PowerBI报表的关系中,直接关系是指关系的两个表直接接触,间接关系是指通过中间表建立关系的两个数据表,间接关系关联的两个数据表不直接接触,如下图,数据表Students和StudentCourse之间的关系是直接关系,数据表Course和StudentCourse之间的关系是直接关系,而数据表Students和Courses之间通过StudentCourse建立间接关系。间接关系通过一系列有直接关系的数据表,能够实现数据的交互,这是PowerBI自动实现的,为创建复杂的数据模型提供了支持,但是,在数据建模中使用间接关系时,务必谨慎,PowerBI对Filter选项的全选和不选的处理是有区别的。
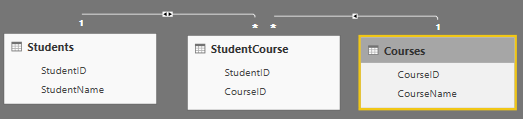
1,使用以下脚本创建具有多层关系的数据表
脚本创建了四个表,分别是用于表示学生,课程,学生选课,学生演讲,学生和课程之间的关系是1:N,学生和演讲活动之间的关系是1:N
create table dbo.Courses
(
CourseID int not null primary key clustered,
CourseName varchar(32) not null
)
create table dbo.Students
(
StudentID int not null primary key clustered,
StudentName varchar(64) not null
)
create table dbo.StudentCourse
(
StudentID int not null,
CourseID int not null,
constraint PK__StudentCourse primary key clustered(StudentID,CourseID)
)
create table dbo.StudentSpeaker
(
StudentID int not null,
EventID int not null
)
insert into dbo.Courses(CourseID,CourseName)
values(1,'English'),(2,'Chinese')
insert into dbo.Students(StudentID,StudentName)
values(1,'stu_a'),(2,'stu_b'),(3,'stu_c'),(4,'stu_d')
insert into dbo.StudentCourse(StudentID,CourseID)
values(1,1),(2,1),(3,2)
insert into dbo.StudentSpeaker(StudentID,EventID)
values(1,101),(4,102)

2,在Relationships视图中,创建表之间的关系
基数关系(Cardinality)根据数据之间的关系创建,筛选方向根据过滤的逻辑设置。默认情况下,PowerBI会自动检查(AutoDetect)数据之间的关系,根据检查的结果(列名和列值的唯一性)自动创建关系,在Relationships视图中,关系是一条有方向的折线,折线的两端是数字,表示基数(Cardinality)关系,折线中间的有向箭头表示筛选方向(Direction)。
PowerBI不会智能到尽善尽美,用户需要根据数据内在的关系对PowerBI自动创建的关系进行修正,或者,例如,把数据表Students和StudentCourse之间的关系修改为:1:N和双向筛选,双击关系(折线),弹出编辑关系(Edit Relationship)的窗体:
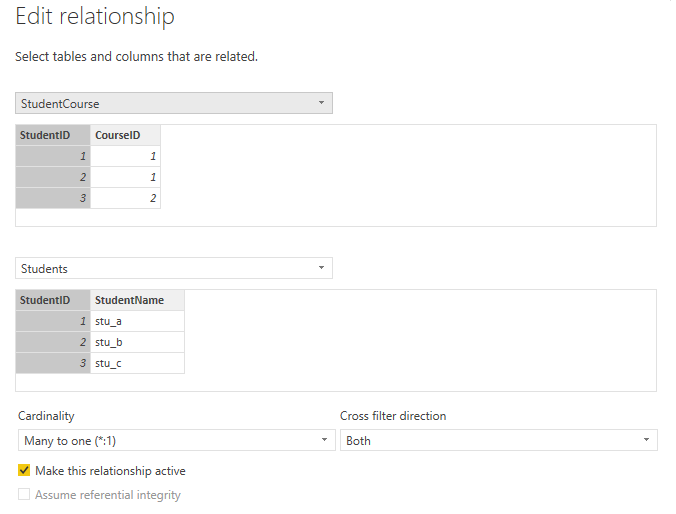
在每个表下方面板中,会显示列名和示例数据。基数(Cardinality)关系是Many to one,其表达式是:*:1,表达式左边的表位于上面,右边的表位于下面,用于建立关系的数据列是灰色选中状态。交叉筛选方向(Cross filter direction)选择Both,勾选“Make this relationship active”,点击OK,完成关系的创建,如下图,点击关系(折线),用于建立关系的数据列处于选中状态。
三,利用间接关系实现业务需求
报表需要实现的业务需求是:根据课程(Course)统计作为演讲者(Speaker)的学生数量
在做报表时,必须熟悉数据和数据之间的关系,在数据表StudentCourse中,共有3个学生选课,学号分别是1、2和3,存在不选课的学生,而在数据表StudentSpeaker中,只有学号1的学生满足条件,因此,根据课程(Course)统计作为演讲者(Speaker)的学生数量的结果应该是:
- 选修English的学生数量是0;
- 修改Chinese的学生数量是1;
- 对所有课程做统计,学生数量是选修English和选修Chinese的数量之和,1(=0+1);
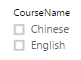
1,设置课程Filter
数据表Course是查找表,由于StudentCourse中的课程(CourseID)都存在于Course表中,所有,Slicer图表中不存在Blank选项。
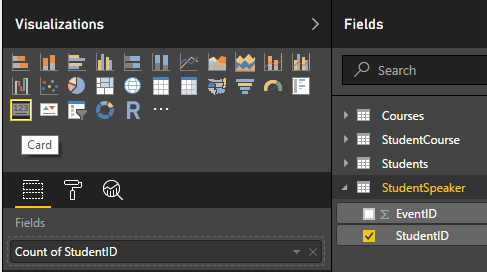
2,添加Card图表,显示统计数量
在Page中添加Card图表(Visualizations),在图表的Fields属性中,选择数据表SutdentSpeaker的StudentID字段,属性值自动变成:聚合函数+ of +字段值。
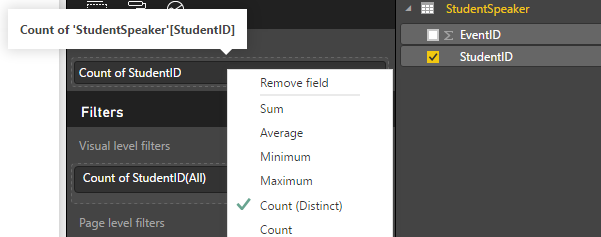
3,设置聚合函数
由于一个学生,可能在多个活动(Event)中担当演讲者(Speaker),因此,必须对StudentID进行去重,在图表的Fields属性值“Count of StudentID” 中右击,选择聚合函数选择Count(Distinct)
4,设置图表的显示属性
切换到“刷子”Icon,禁用Category lable,启用Title,修改Title Text、Font color,Alignment和Text Size,
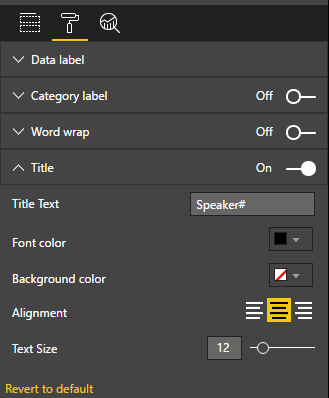
5,分析报表数据
课程选择Chinese,数量是Blank
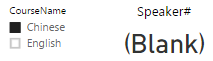
课程选择English,数量是1

选择所有课程,数量是1

6,清洗数据
默认情况下,图表不选择任何课程(Course),数量是2,这个结果在逻辑上是“错误”的,对于没有选择任何选项的Filter,PowerBI不会做任何筛选关联。

导致错误的原因是由于数据表StudentSpeaker出现脏数据,没有选修任何课程的学生(本例是学号为4的学生)出现在StudentSpeaker数据表中,要修正查询的结果,必须清洗脏数据。
四,编辑交互行为
选择不同的CourseName,度量值Speaker#自动根据Filter做相应的数据过滤,重新统计数据,这种过滤的流向是单向的,由数据关系中的交叉过滤方向(Cross Filter Direction)决定,PowerBI允许在不修改关系的情况下,编辑Filter和度量值的交互行为,使报表中的不同图表(Visiualization)选择性地响应或不响应过滤条件(Filter)。
1,选择Filter,切换到Format菜单,选择“Edit Interactions”
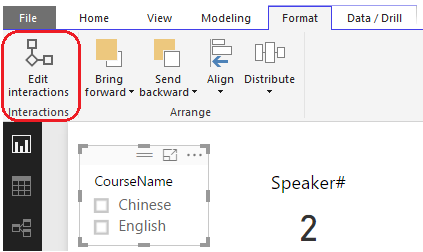
2,编辑交互行为
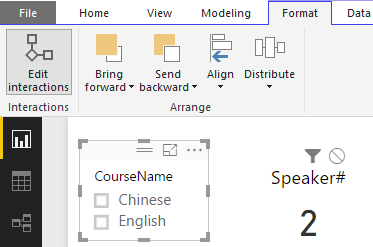
默认情况下,Card图表的Filter
 是选中,将其切换到禁止
是选中,将其切换到禁止
 ,这样,选择Course过滤器中的任何一个选项,都不会影响Card图表显示的数据值。
,这样,选择Course过滤器中的任何一个选项,都不会影响Card图表显示的数据值。
五,在数据建模中,要遵守一定的设计原则
在数据建模中,不仅需要属性业务需求,而且需要熟悉数据及其关系,遵守一定的设计原则,能够避免出现一些显而易见的错误:
- 要根据业务需求,设计报表的过滤条件(Filer)和度量值;
- 过滤器是数据建模的出发点,根据过滤条件和数据之间内在的关系设计数据模型;
- 根据数据之间内在的关系,加载数据,保证数据表中不出现脏数据。
参考文档:















 461
461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











