






有幸参加了阿里云举办的零基础入门金融风控-贷款违约预测训练营。收获颇多。
每天记录一些自己之前的知识盲点,需经常温习。
第二次的学习任务,是EDA。即Exploratory Data Analysis,探索性数据分析。
一、数据集基本情况分析
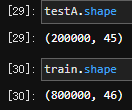
数据集分为训练集和测试集。第一次任务时已经将训练集和测试集中重复的列进行了删除,最终形状如下:
通过train.info()可以查看训练集的基本信息(非空值数量、数据类型、行列数等):

通过train.describe()可以查看训练集的一些基本统计量:

(注:为了防止列数过多导致显示不全,此处使用了.T进行了转置,算是一个小小的trick。)
二、查看数据集缺失值及唯一值
1、缺失值
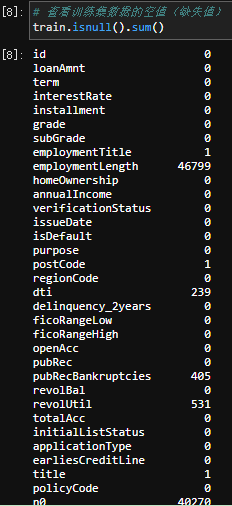
通过train.isnull().sum()查看缺失值详细信息,包括都有哪些列是缺失值,以及具体缺失值的数量:
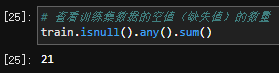
通过train.isnull().any().sum()查看缺失值列数的个数,发现共有21列(教程上没有删除重复列,写成了22列,其实是不对的hhh~):
缺失值可视化(这里的代码实现方式和教程上不一样,二者皆可):

2、唯一值
通过如下代码查看训练集的唯一值:

测试集代码相同,发现都是'policyCode'这一列,该列值全为1,没有实际区分意义,可以考虑在做特征工程阶段将其删除。
三、数据可视化
一图胜千言,数据可视化的魅力我想大家都有所体会吧!
变量类型可以大体上分为类别型变量和数值型变量,其中数值型变量可分为离散型数值变量和连续型数值变量。
而数据可视化,主要指的是数值型变量的可视化。通过生动形象的图形可以做出统计学相关的分析,如是数据集否服从正态分布、偏态、峰度等等。
从之前的train.info()中得知,训练集的数据类型有三种:object、int64和float64,object类型即为类别型变量,int64和float64为数值型变量。故可用如下代码获得类别型变量和数值型变量(这里的代码实现方式和教程上不一样,二者皆可):


由于数值型变量可分为离散型数值变量和连续型数值变量,故可进行进一步划分。
未完待续。。。















 6345
6345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









