







迁移学习的出发点:
1.希望能在一个任务上学习一个模型然后可以用来解决一个相关的别的任务。
2.迁移学习的出圈是在深度学习上,因为我们在深度学习里面训练很多的深层的神经网络,这些神经网络需要很多的数据,并且训练的代价也是很大的。意味着我们对一个任务很难去做一个很大的训练集,如果我们在一个任务上训练好的模型能在别的任务上能用是最好的了。
迁移学习在途径上的几种方法:
1.最简单的,训练好一个模型做成一个特征提取的模块(比如说:在文本上训练一个单层的神经网络然后每一个次会对应一个特征,然后用这个特征去做别的事情。训练好的ResNet模型,可以用来第一个图片做特征,得到这个特征之后作为另一个模型的输入,假设这个模型的特征非常的好,就可以替代人工抽取特征的一些步骤。I3D是用来做视频的特征)
2.在一个相关的任务上训练一个模型直接在另外的一个任务上使用,这一块也是在gpt上比较流行的一点。(之后的单元会讲)
3.我们训练好一个模型,在新的任务上会对这个模型做一些微调,使得能够更好的运用到新的模型上面去。(本节课的重点)
迁移学习相关的领域:
1.半监督学习:是说有一些特征是没有标号的,我怎么用没有标号的数据去帮助有标号的数据,让其变得更好。
2.在极端的情况下可以做zero-shot,few-shot 学习,就是给一个新的任务我可能任何东西都不告诉你,任何的样本都不知道的情况下将图片进行分类。few-shot是说给一个新的任务就知道几张的样本,然后根据这很少的样本将图片的真实内容识别出来。
3.Multi-task learning 就是多任务学习,每一个任务都有一个自己的数据,但是这些数据不一定很足够,但是这些任务有事相关联的,可以把这些所有的数据放在一起同时训练出多个任务来。希望每个任务能在别的任务那里获益。
微调在计算机视觉里面的应用
计算机视觉里面存在一些大规模标记好的数据集,特别是在图片分类问题上面,因为分类问题是最好标记的。
在计算机视觉的迁移学习,我们希望存在很多的数据的一些应上比较好的模型,能将他的知识拓展到自己的任务上去。
简单举例:
在计算机视觉上有名的数据集之一叫做IamgeNet他有120万张图片,有1000类,但是他还有一个更大的数据集大概有1000万张图片,10万类。用的最简单的数据集是mnist数据集就有六万张样本,有10类但是每张图片是比较简单的。自己的数据集的数目和类别大约在这两者之间。

预训练模型
有多种转移知识的办法用的最多的方法是用的预训练好的模型。
具体看是怎么回事:
一般来说一个神经网络的话,大概分成两块,一块是编码器,第二块是解码器。
编码器就是一个特征提取器,给你的原始图片里面的是原始的像素,编码器就是讲原始的像素转换成在一个语义空间里面可以线性分解的一些特征或者叫做(浅表示或者是特征表示)。当得到这些特征之后,解码器就是一个简单的线性分类器,就是把编码器的表示直接映射成我要的标号就行了或者是做一些决策。如下图:

输入一张猫的图片,然后经过很多的层,最后得到的输出层就是一个线性层,输出一个标记好的猫。在这张图中可以抽象成两块,第一块就是所有的卷积层可以认为是一个特征提取器或者是编码器,最后一层就是把这一块的语义特征直接做一个线性投影放到我需要的语义空间当中就行了(标号空间)。
预训练模型
在一个比较大的模型上面训练好的一个模型,因为这个模型在比较大的数据集上训练,所以认为这个模型有一定的泛化能力的。(泛化能力:我放到一个别的任务上或者是新的数据集上,我的这个模型多多少少是能帮忙的) 比如说在imageNet上训练好的神经网络他的特征提取器也能够帮助别的数据集(在医学上或者是在卫星图片上)。另外,虽然我在图片上做的是分类的任务,换到别的任务上我的模型也是能够起到帮助的作用。综上,在大的数据集上训练好的模型叫做预训练模型。

Fine-Tuning techniques
怎么把预训练好的模型用在我的新的任务上——微调的方法,在深度学习当中微调是带来的最好的结果。
微调是怎么做的:
1.在新的任务上面再构建一个新的模型,这个新的模型的结构要和预训练的模型的架构是一样的。
2.找到合适的模型之后,初始化这个模型,具体的初始化是:我的新模型的特征提取器除了最后一层,所有的卷积层和全连接层权重初始的时候不是用的随机的,而是直接把预训练好的模型的权重直接复制过来。最后一层(输出层)解码器还是用的随机的。这是因为我的任务的那些标号和预训练任务的标号空间可能不是一样的。
具体的例子:
假设有在imageNet上预训练好的模型,在目标数据(真正自己做的模型的数据集上)两者的架构是一样的,除了最后一层随机初始化之外,剩下的全部是从imageNet上预训练好的模型上面复制过来的。所以新的模型在构建好的时候,圈出来的部分就可以提取比较好的特征了,只要学习好最后的一层输出层怎么去做决策就好,根据误差大概的调整一下卷积层和全连接层。
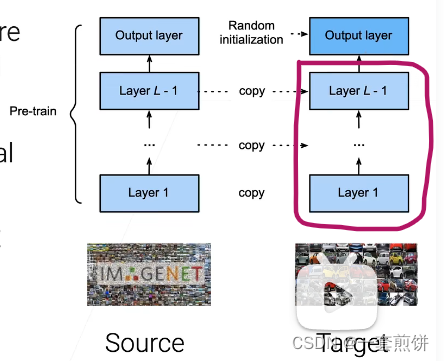
初始好之后就可以开始学习了,跟正常的学习是没有特别大的区别的。因为我们的初始话后的结果比较好了,已经在想要的结果的附近了,限制学习率可以使我们可以不用走的很远,可以用一个比较小的学习率正常的用0.1,在这种情况下可以用0.001.另外,训练的时间不要太长。上面的这两种方法都是让搜索空间小一点,不要太大。
为什么让搜索空间小一点:
对一个优化算法来讲,怎么样随机都没有关系。如果不做特别的限制的话,随机的结果和微调的结果都不会达到最后想要的结果,最后的结果不一定使自己想要的。因为泛化误差和训练误差不是一样的,假设我的数据集在不大,模型够复杂的话,我的模型是能够记住整个数据集的。虽然我的训练误差是最低的,但是泛化能力不一定是最好的。
限制搜索空间的方法
把最底层的那些层固定住,神经网络是有一个层次化的学习过程,比如说在最底层学到什么东西呢?通常学到的是底层的一些特征的表示。随着层数越来越高的时候,多多少少学到的一些更大的更全局语义上的东西。下面层学到的是最底层的像素是跟上面层没有什么太大的关系的。上层更加符合语义。所以,假设限制搜索的空间,最后一层还是随机初始化学习,下面的层可以是对某一个层进行改动,最最下面的层在微调的时候选择是不动的(认为此时的学习率是0)。有时候也不必这么麻烦,可以是将下面的一些层固定住,具体固定住多少层这个时候是需要去根据实际的应用去调的,假设我的应用跟预训练的模型之间的差距比较大的话可能要多训练一些层。甚至在极端的情况下,固定住下面所有层,只调最后一层也是可以的。固定一些层是不错的选择这可以使的训练更加的快一点。

在微调的过程中怎么找到预训练的模型
首先是有没有这个预训练的模型,其次是他是在多大的数据集上预训练好的
提到的两个途径:一个是tensorflow hub(允许用户提交模型),另一个是TIMM(把pytorch上能够找到的各种代码实现弄过来)
使用TIMM的例子:

微调的应用
1.在比较大的数据集上使用预训练好的模型在微调到自己的应用上是在计算机视觉上主流的方法。
新的任务比如说:做检测,做分割(图片一样的但是任务不一样)
任务相同但是图片不一样,卫星或者是医疗
2.微调加速了收敛,是因为微调让初始点不是一个随机的点,而是一个一个跟最终的目标靠的比较近的点,这个点比较的平滑一点。(越靠近最终的点,真个损失就越平滑,训练九就越简单)
3.微调不一定会提升精度, 用了预训练模型的话训练的精度会上升,但是微调不会让精度降低,因为改变的知识初始值而已。

总结
1.通常会在比较大的数据集上训练预训练好的模型,在CV上通常是图片的分类 (CNN,transformer模型)
2.有了预训练模型之后,在新的任务上把自己的模型的权重初始成预训练好模型的权重
3.微调一般用一个小一点的学习率进行细微的调整,这样会加速收敛,有时候会提升精度但不会变差。














 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









