







分类
要尝试分类,一种方法是使用线性回归,并将所有大于0.5的预测值映射成1,小于0.5的所有预测值映射成0,但是这种方法效果不佳,因为分类实际上不是线性函数。所以我们在接下来的要研究的算法就叫做逻辑回归算法,这个算法的性质是:它的输出值永远在0到 1 之间。
逻辑回归分类
前面提到线性回归分类模型是个线性函数,它的预测值可能会超过[0,1]的范围,不适合用于二分类或者多分类模型。
逻辑回归:该模型的输出变量范围始终在 0 和 1 之间,它的模型的输出函数表达式以及函数示意图如下图:
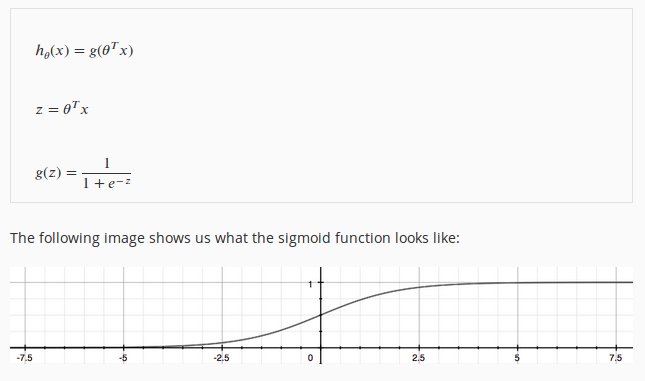
从上图,可以看出逻辑回归其实是线性回归的基础上套用了一个逻辑函数[逻辑函数来源参考:https://chenrudan.github.io/blog/2016/01/09/logisticregression.html,也就是将线性回归输出的 h(x) (也就是逻辑函数的输入量 z)映射为相应的概率(0~1之间),从而线性回归模型与概率论知识就结合在一起了。因此这里有一个特性需要记住,所有分类的的输出值 h(x) 的和为 1。
由于函数图像很像一个“S”型,所以逻辑回归函数也称为 sigmoid 函数。
决策边界
为了得到 y = 0 和 y = 1 的两个分类,我们希望我们的模型输出函数满足:
h(x) ≥ 0.5 —>> y = 1;
h(x) < 0.5 —>> y = 0;
通过逻辑回归函数,我们只需要:
z ≥ 0 —>> y = 1;
因为 g(z) ≥ 0.5 存在的条件是 z ≥ 0,这个不难理解。
而这里 z = θTX,故而只需要:
θTX ≥ 0 —>> y = 1;
θTX < 0 —>> y = 0;
假设参数 θ 已经训练好,代入上式,其中 θTX = 0 就是我们的关心的决策边界线。具体看下面两张ppt:
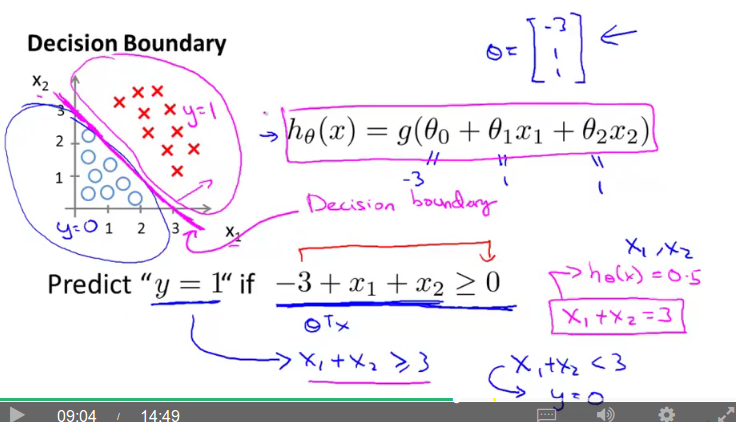

逻辑回归模型
代价函数
跟线性回归模型一样,我们的目的一样是要拟合逻辑回归模型的参数 θ。跟以往一样,使用代价函数 J(θ) 来拟合我们的参数 θ。
如果使用以往的:
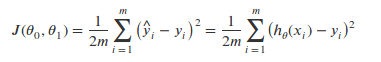
最终会发现 J(θ) 是一个非凸函数,也就是说存在很多局部最小值,会影响梯度下降法寻找全局最小值。如下图:
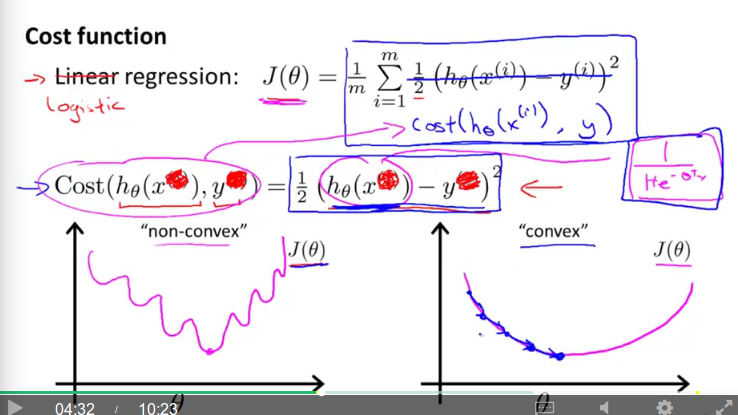
上图左边是一个非凸函数图,主要原因是 h(x) 是一个复杂的非线性函数,右边是一个凸函数,我们希望 J(θ) 长右边这样子,这样可以保证梯度下降能收敛到全局最小值。因此我们需要另外找一个代价函数 J(θ) 。再提出新的代价函数 J(θ) 前,先阅读下图:

对于逻辑回归模型来说,我们选用对数似然损失函数作为逻辑回归的Cost Function。如下图:
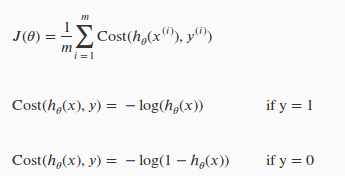
y = 1 的 cost function 如下图:
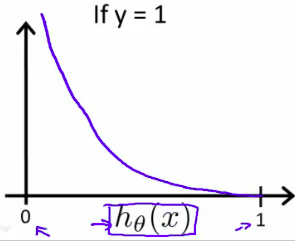
y = 0 的 cost function 如下图:
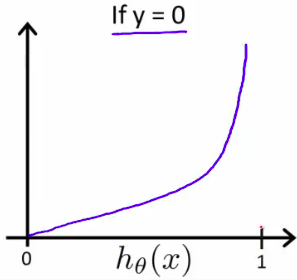
不难发现有如下的特性:
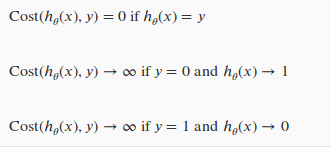
简化版的 cost function 及梯度下降法
考虑到 y 不是 1 就是 0 ,因此上图的 Cost(hθ(x),y)可以用下面一个式子来代替:
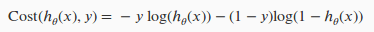
故而损失函数 J(θ) 可以表示成:
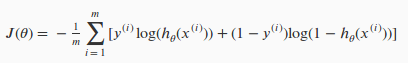
跟线性回归模型一样,我们的目的就是要找到一组 θn,使得 J 函数最小,那就是要对各个 θi 求偏导, 梯度下降算法:
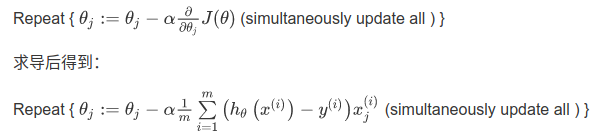
其推导过程如下图:
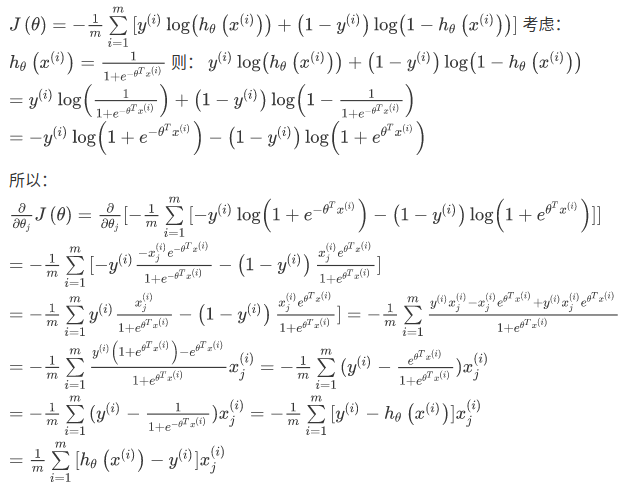
虽然得到的梯度下降算法表面上看上去与线性回归的梯度下降算法一样,但是这里的 h(θ) = g(θTX) 与线性回归中不同,所以实际上是不一样的。
高级优化
除了梯度下降求 θ 外,我们有更高级的更复杂的算法:共轭下降法、BFGS、L-BFGS,这些算法能够通过梯度下降,是逻辑回归模型更快的收敛 θ。
这三种算法的优缺点:
- 不需要手动的调节学习率,在梯度下降法中我们可以知道,当学习率设置不恰当时会导致收敛速度很慢或者不能收敛,而上述三种方法,不需要手动设置,可以自动的寻找最适合的学习率。
- 收敛速度相对于梯度下降法快了很多。
- 但是以上三种方法的复杂度相对于梯度下降法复杂很多,对于现在来说,我们只需要会用。
不过有一种高级优化方法就是使用 octave 的 fminuc 函数。
如何使用:
首先我们需要提供一个函数计算 J(θ) 和它的偏导,伪代码如下。
% costFunction.m
function [jVal, gradient] = costFunction(theta)
jVal = [...code to compute J(theta)...];
gradient = [...code to compute derivative of J(theta)...];
end其次,我们使用 octave 或 matlab 的 fminunc()。关于 fminuc 的使用参考:Matlab函数fminunc/fminbnd/fmincon求解工程优化问题
伪代码如下:
options = optimset('GradObj', 'on', 'MaxIter', 100);
initialTheta = zeros(2,1);
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options);
fminunc 会使用众多高级优化算法中的一个,当然你也可以把它当成梯度下降,只不过它能自动选择学习速率 α,你不需要自己来做。然后它会尝试使用这些高级的优化算法,就像加强版的梯度下降法,为你找到最佳的 θ 值。
多类别分类
采用的是一对多方法,具体预测流程如下:

例子:
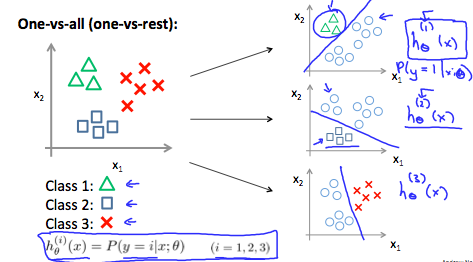
首先我们选择 class 1,然后把所有其他课程都集中到另一个单一的 class 中去,求出它的 h(1)(θ)。 然后依次选择 class 2 和 class 3,重复刚才的步骤,对每个案例应用二元逻辑回归,然后使用返回最高值的假设作为我们的预测。
拟合问题
过拟合问题
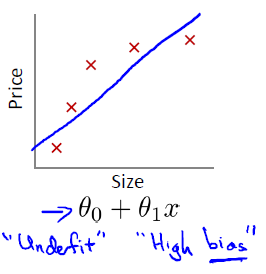
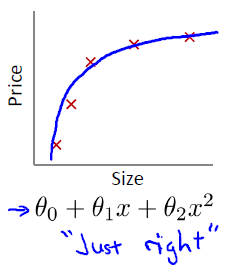
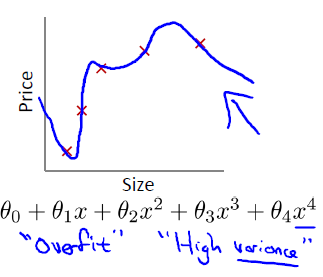
第一张图拟合函数跟训练集误差较大,欠拟合。
第二张图拟合函数跟训练集误差较小,合适拟合。
第三张图拟合函数完美匹配训练集数据,过拟合。
两种拟合问题分析:
- 欠拟合问题,根本的原因是特征维度过少,导致拟合的函数无法满足训练集,误差较大。欠拟合问题可以通过增加特征维度来解决
- 过拟合问题,根本的原因则是特征维度过多,导致拟合的函数完美的经过训练集,但是对新数据的预测结果则较差,也就是泛化能力较差。
解决过拟合问题,则有2个途径:
- 减少特征维度:可以人工选择保留的特征,或者模型选择算法
- 正则化:保留所有的特征,通过降低参数 θ 的值,来影响模型
含正则化的cost function
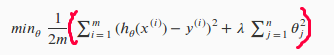
上图的 λ ( 称为:lambda)就是我们说的正则化参数,需要注意的是我们不对 θ0 进行惩罚。如果我们选择的 λ 过大,最终 θ 会过小,导致模型变成 h(x) = θ0,很明显会出现欠拟合的情况;反之如果 λ 选得过小,就失去惩罚 θ 的功能,使得模型过拟合;因此选择合适的 λ ,才能更好的正则化。
线性回归模型的正则化梯度下降
在机器学习第二周中我们可以通过梯度下降或者正规方程来求 cost function 的极值。这里只讲梯度下降法,对含有正则项的 const function J(θ) 求偏导,我们要分为两种情况,一种是 θ0,一种是 θj(j=1,2…m);如下图
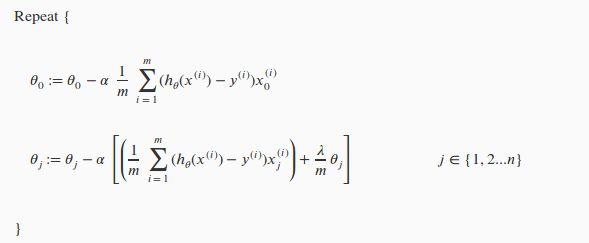
其中 θj 调整可以得到下面公式:
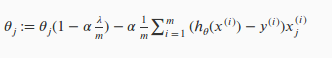
上式中因为 α、λ 都是大于 0,因此 (1 - αλ/m) 是一个小于 1 的值,故而每一次更新,θj也会得到减少一个值,这里是跟机器学习第二周所提到的不一样的地方。
逻辑回归模型的正则化梯度下降
前面第二章讲了逻辑回归模型,跟线性回归模型一样,也可以在 const function J(θ) 加上一个正则化项,如下图:
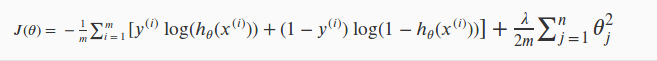
参考:















 1425
1425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









