









NLP-大语言模型学习系列目录
一、注意力机制基础——RNN,Seq2Seq等基础知识
二、注意力机制【Self-Attention,自注意力模型】
在自然语言处理领域,注意力机制(Attention Mechanism)已经成为提升模型性能的重要工具。传统的Encoder-Decoder结构在处理长序列时,常常因为统一语义特征向量的长度限制而导致性能瓶颈。然而,注意力机制通过引入动态上下文向量,成功解决了这一问题,使得模型能够在每个时间步选择与当前输出最相关的信息。
本篇博客将详细介绍注意力机制的基本原理、一般形式以及自注意力模型,并通过具体例子和图示来更好地理解这些关键概念。
一、语言模型实例
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码:
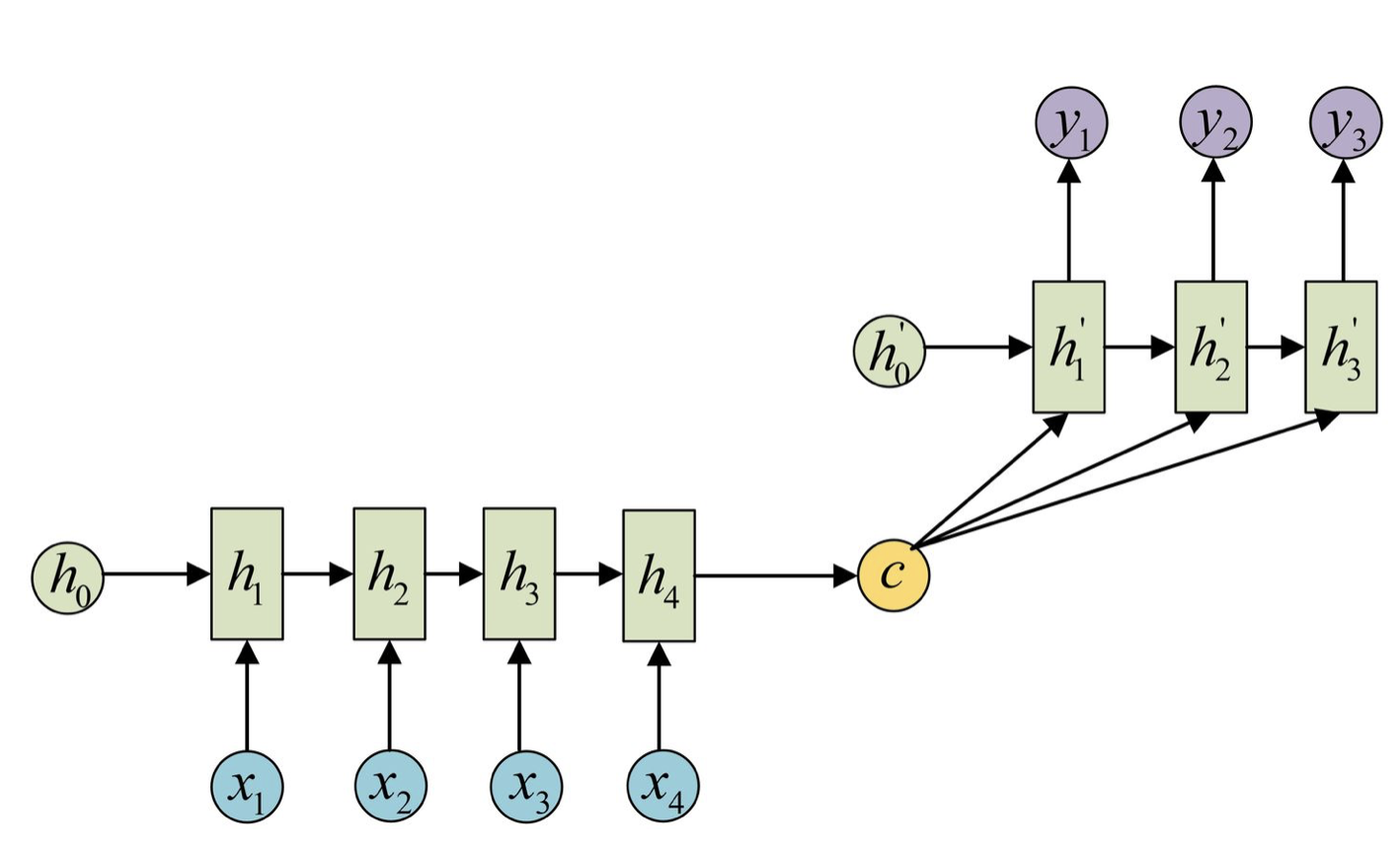
因此, c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个c可能存不下那么多信息,就会造成翻译精度的下降。
Attention机制通过在每个时间输入不同的c来解决这个问题,下图是带有Attention机制的Decoder:
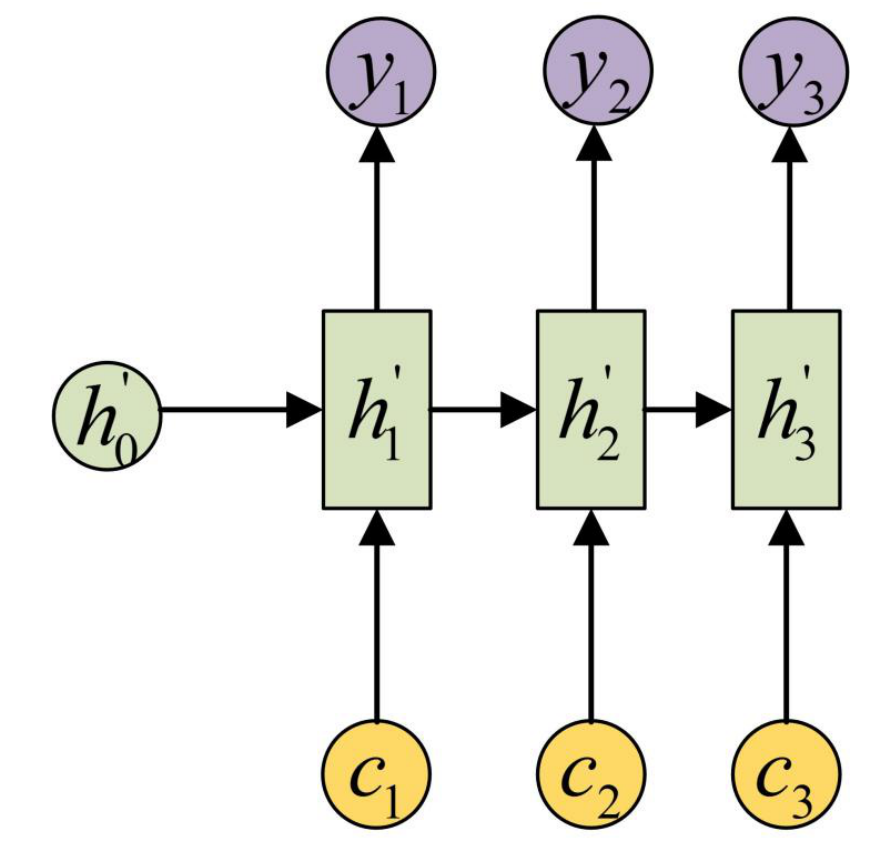
每一个c会自动去选取与当前所要输出的y最合适的上下文信息。具体来说:
- 用 a i j a_{i j} aij 衡量 Encoder中第j阶段的 h j h_j hj和解码时第i阶段的相关性;
- 最终Decoder中第i阶段的输入的上下文信息 c i c_{i} ci 就来自于所有 h j h_{j} hj 对 a i j a_{i j} aij 的加权和。
以机器翻译为例(将中文翻译成英文):
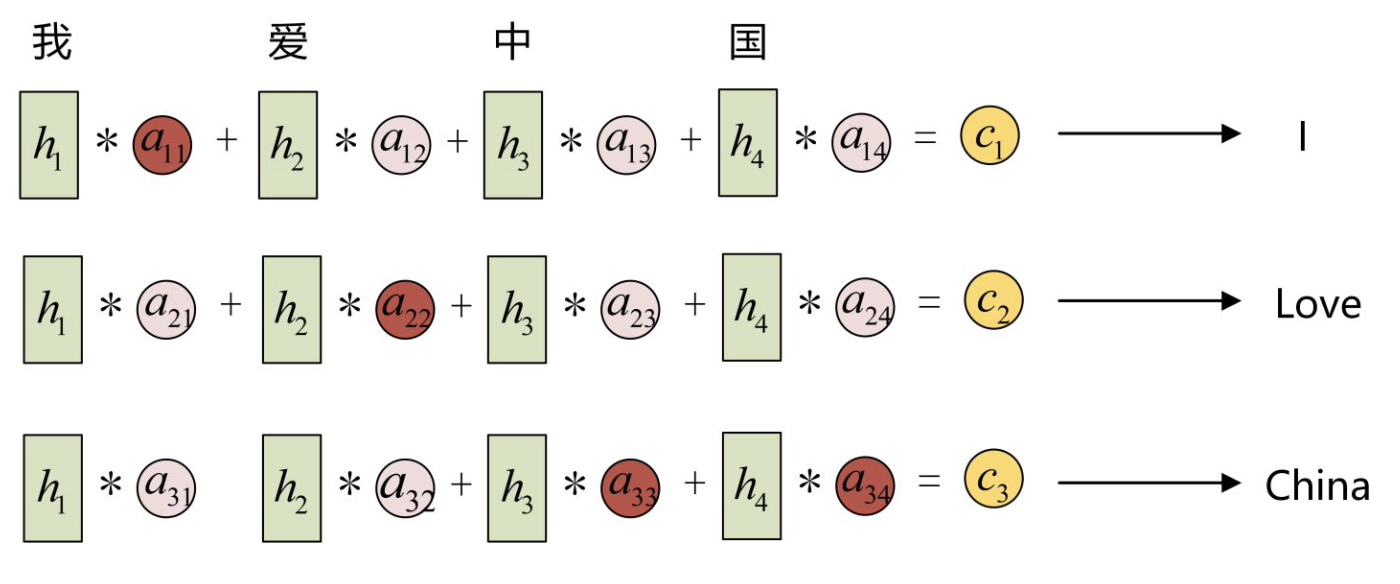
输入的序列是“我爱中国”:
- 因此, Encoder中的 h 1 、 h 2 、 h 3 、 h 4 h_1、h_2、h_3、h_4 h1、h2、h3、h4就可以分别看做是“我”、 “爱”、“中”、“国”所代表的信息;
- 在翻译成英语时, 第一个上下文 c 1 c_1 c1应该和“我”这个字最相关, 因此对应的 a 11 a_{11} a11 就比较大, 而相应的 a 12 、 a 13 、 a 14 a_{12} 、 a_{13} 、 a_{14} a12、a13、a14 就比较小;
- c2应该和“爱”最相关, 因此对应的 a 22 a_{22} a22 就比较大;
- 最后的 c 3 c_3 c3和 h 3 、 h 4 h_3、h_4 h3、h4最相关, 因此 a 33 、 a 34 a_{33} 、 a_{34} a33、a34 的值就比较大。
这些权重 a i j a_{i j} aij 是怎么来的?事实上, a i j a_{i j} aij 同样是从模型中学出的, 它实际和Decoder的第i阶段的隐状态、Encoder第j个阶段的隐状态有关,在下面一小节我们会介绍 a i j a_{ij} aij如何计算.
- 这里的 c 1 , c 2 , c 3 c_1,c_2,c_3 c1,c2,c3就是attention值;
二、注意力机制一般形式
刚刚我们是基于Encoder-Decoder模型来介绍attention机制的,下面我们更一般的来介绍注意力机制.
用 X = [ x 1 , ⋯ , x N ] ∈ R D × N X=[x_1,\cdots,x_N]\in\mathbb{R}^{D\times N} X=[x1,⋯,xN]∈RD×N 表示 N N N组输入信息,其中 D D D 维向量 x n ∈ \boldsymbol{x}_n\in xn∈ R D , n ∈ [ 1 , N ] \mathbb{R}^D,n\in[1,N] RD,n∈[1,N]表示一组输入信息.为了节省计算资源,不需要将所有信息都输入神经网络,只需要从 X \boldsymbol X X 中选择一些和任务相关的信息.注意力机制的计算可以分为两步:
- 一是在所有输入信息上计算注意力分布;
- 二是根据注意力分布来计算输入信息的加权平均.
为了从
N
N
N个输入向量
[
x
1
,
⋅
⋅
⋅
,
x
N
]
[\boldsymbol x_1,\cdotp\cdotp\cdotp,\boldsymbol x_N]
[x1,⋅⋅⋅,xN]中选择出和某个特定任务相关的信息,我们需要引入一个和任务相关的表示,称为查询向量(Query Vector), 并通过一个打分函数来衡量每个输入向量和查询向量之间的相关性.
给定一个和任务相关的查询向量
q
\boldsymbol q
q,我们用注意力变量
z
∈
[
1
,
N
]
z\in[1,N]
z∈[1,N]来表示被选择信息的索引位置,即
z
=
n
z=n
z=n 表示选择了第
n
n
n 个输入向量.为了方便计算,我们采用一种“软性”的信息选择机制.首先计算在给定
q
q
q和
X
X
X下,选择第
n
n
n个输入向量的概率
α
n
\alpha_n
αn,
α
n
=
p
(
z
=
n
∣
X
,
q
)
=
softmax
(
s
(
x
n
,
q
)
)
=
exp
(
s
(
x
n
,
q
)
)
∑
j
=
1
N
exp
(
s
(
x
j
,
q
)
)
,
\begin{aligned}\alpha_{n}&=p(z=n|X,\boldsymbol{q})\\&=\operatorname{softmax}\left(s(\boldsymbol{x}_n,\boldsymbol{q})\right)\\&=\frac{\exp\left(s(\boldsymbol{x}_n,\boldsymbol{q})\right)}{\sum_{j=1}^N\exp\left(s(\boldsymbol{x}_j,\boldsymbol{q})\right)},\end{aligned}
αn=p(z=n∣X,q)=softmax(s(xn,q))=∑j=1Nexp(s(xj,q))exp(s(xn,q)),
其中
α
n
\alpha_n
αn 称为注意力分布( Attention Distribution),
s
(
x
,
q
)
s(\boldsymbol x,\boldsymbol{q})
s(x,q) 为注意力打分函数.
注意力打分函数 s ( x , q ) \mathbf{s}(\mathbf{x},\mathbf{q}) s(x,q):计算输入向量和查询向量之间的相关性,常用如下模型
∙ 加性模型: s ( x , q ) = v T t a n h ( W x + U q ) . ∙ 点积模型: s ( x , q ) = x T q . ∙ 缩放点积模型: s ( x , q ) = x T q D . ∙ 双线性模型: s ( x , q ) = x T W q . \begin{aligned}&\bullet\text{ 加性模型: }\mathbf{s}(\mathbf{x},\mathbf{q})=\mathbf{v}^{T}\mathrm{tanh}(\mathbf{W}\mathbf{x}+\mathbf{U}\mathbf{q}).\\&\bullet\text{ 点积模型: }\mathbf{s}(\mathbf{x},\mathbf{q})=\mathbf{x}^{T}\mathbf{q}.\\&\bullet\text{ 缩放点积模型: }\mathbf{s}(\mathbf{x},\mathbf{q})=\frac{\mathbf{x}^{T}\mathbf{q}}{\sqrt{D}}.\\&\bullet\text{ 双线性模型: }\mathbf{s}(\mathbf{x},\mathbf{q})=\mathbf{x}^{T}\mathbf{W}\mathbf{q}.\end{aligned} ∙ 加性模型: s(x,q)=vTtanh(Wx+Uq).∙ 点积模型: s(x,q)=xTq.∙ 缩放点积模型: s(x,q)=DxTq.∙ 双线性模型: s(x,q)=xTWq.
这里 W , U , v \mathbf{W},\mathbf{U},\mathbf{v} W,U,v为可学习的参数, D D D为输入向量的维度.
Note:
- 在前面的例子中, h 1 , h 2 , h 3 , h 4 h_1,h_2,h_3,h_4 h1,h2,h3,h4就是输入向量 X X X;
- h 1 ′ , h 2 ′ , h 3 ′ h'_1,h'_2,h'_3 h1′,h2′,h3′就是查询向量 q q q;
- a i j a_{ij} aij就是注意力分布,这里我们给出了注意力分布怎么计算的.
得到注意力分布后,对输入向量加权平均可以得到attention值:
att
(
X
,
q
)
=
∑
n
=
1
N
α
n
x
n
,
=
E
z
∼
p
(
z
∣
X
,
q
)
[
x
z
]
.
\begin{aligned}\operatorname{att}(X,\boldsymbol{q})&=\sum_{n=1}^N\alpha_nx_n,\\&=\mathbb{E}_{z\sim p(z|X,\boldsymbol{q})}[x_z].\end{aligned}
att(X,q)=n=1∑Nαnxn,=Ez∼p(z∣X,q)[xz].
下图(a)清晰的描述了attention的计算过程.
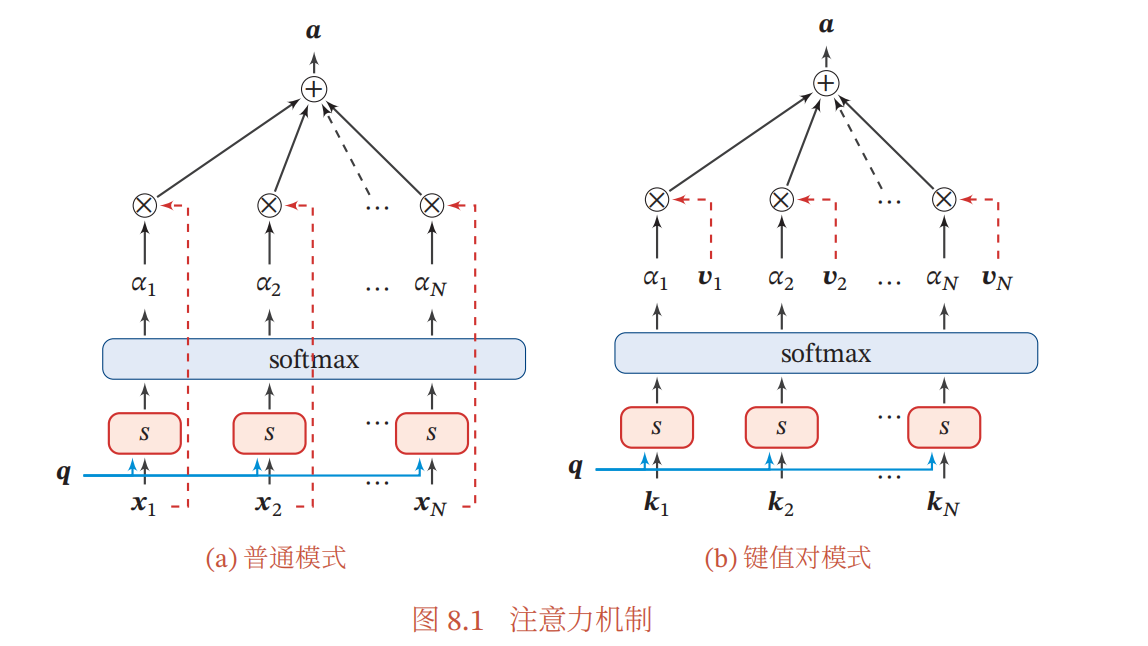
更一般地,我们可以用键值对( key-value pair)格式来表示输入信息,其中“键”用来计算注意力分布
α
n
\alpha_n
αn,“值”用来计算聚合信息.用
(
K
,
V
)
=
[
(
k
1
,
υ
1
)
,
⋯
,
(
k
N
,
υ
N
)
]
\left(\boldsymbol{K},\boldsymbol{V}\right)=\left[\left(\boldsymbol{k}_1,\boldsymbol{\upsilon}_1\right),\cdots,\left(\boldsymbol{k}_N,\boldsymbol{\upsilon}_N\right)\right]
(K,V)=[(k1,υ1),⋯,(kN,υN)]表示
N
N
N组输入信息,给定任务相关的查询向量
q
q
q时,注意力函数为
att
(
(
K
,
V
)
,
q
)
=
∑
n
=
1
N
α
n
v
n
,
=
∑
n
=
1
N
exp
(
s
(
k
n
,
q
)
)
∑
j
exp
(
s
(
k
j
,
q
)
)
v
n
,
\begin{aligned}\operatorname{att}\Big((\boldsymbol{K},\boldsymbol{V}),\boldsymbol{q}\Big)&=\sum_{n=1}^N\alpha_n\boldsymbol{v}_n,\\&=\sum_{n=1}^N\frac{\exp\left(s(\boldsymbol{k}_n,\boldsymbol{q})\right)}{\sum_j\exp\left(s(\boldsymbol{k}_j,\boldsymbol{q})\right)}\boldsymbol{v}_n,\end{aligned}
att((K,V),q)=n=1∑Nαnvn,=n=1∑N∑jexp(s(kj,q))exp(s(kn,q))vn,
其中
s
(
k
n
,
q
)
s(\boldsymbol{k}_n,\boldsymbol{q})
s(kn,q) 为打分函数.图8.1给出键值对注意力机制的示例.当
K
=
V
K=V
K=V时,键值对模式就等价于普通的注意力机制.
三、自注意力模型
由键值对注意力模式我们可以进一步引出自注意力模型的概念,该模型通过注意力机制可以建立输入序列长距离依赖关系。注意力模型计算过程如下图所示:
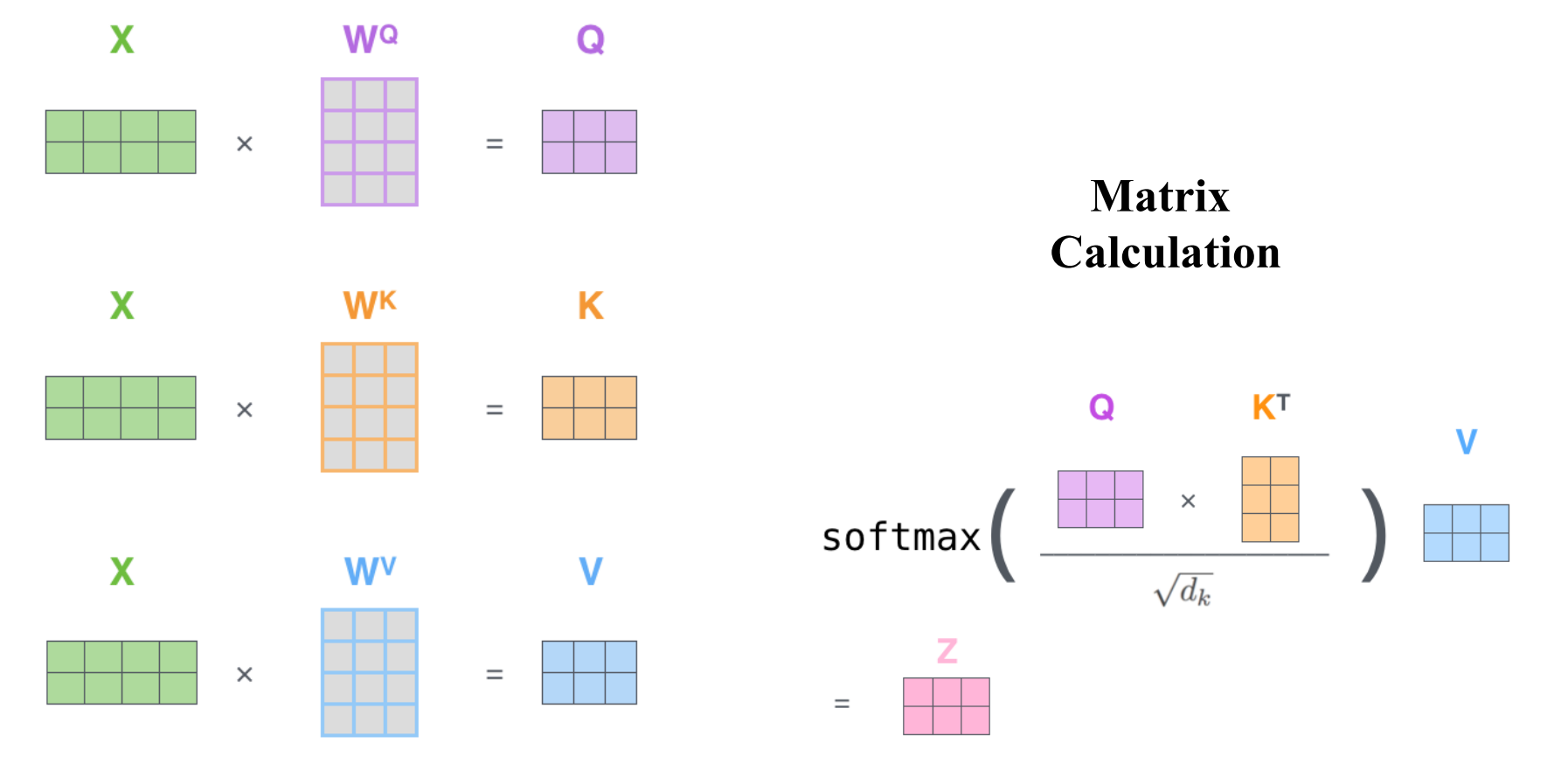
🔥Note:
- X X X为输入矩阵;
- W Q 、 W K 、 W V W^Q、W^K、W^V WQ、WK、WV是可学习的参数矩阵;
- 最后得到的 Z Z Z为attention值矩阵;
- 为什么叫自注意力模型呢?因为我们可以看到这里Q、K、V都是由 X X X通过一个线性变换投影得到的,而矩阵 W W W是可学习的,所以由 X X X到 Z Z Z的映射权重是可学习的,是动态调整的。
如下图所示,红色表示当前的词,蓝色阴影表示与红色词的相关程度,通过自注意力模型,我们可以自动学到每个词与前面词的相关关系。

参考资料
- 深度学习500问
- 邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









