









NLP-大语言模型学习系列目录
一、注意力机制基础——RNN,Seq2Seq等基础知识
二、注意力机制【Self-Attention,自注意力模型】
🔥 在自然语言处理(NLP)领域,理解和生成自然语言的能力对于构建智能系统至关重要。从文本分类、机器翻译到对话系统,底层技术的不断进步推动了NLP的发展。在这些技术中,循环神经网络(RNN)及其变种如长短期记忆网络(LSTM)、Seq2Seq模型和注意力机制(Attention Mechanism)扮演了重要角色。
📚 本系列博客将从基础知识开始,逐步深入探讨大语言模型在NLP中的应用。我们将从RNN的经典结构出发,介绍其工作原理和局限性,接着探讨Seq2Seq模型及其在机器翻译中的应用,最后深入解读注意力机制及其在现代深度学习模型中的重要性。
文章目录
循环神经网络(Recurrent Neural Network, RNN)是一类以序列数据为输入,在序列的演进方向进行递归且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)。对循环神经网络的研究始于二十世纪 80-90 年代,并在二十一世纪初发展为深度学习算法之一,其中双向循环神经网络和长短期记忆网络(Long Short-Term Memory networks,LSTM)是常见的循环神经网络。
一、RNN经典结构
经典循环神经网络的单个神经元如下图所示,它由输入层、一个隐藏层和一个输出层组成:
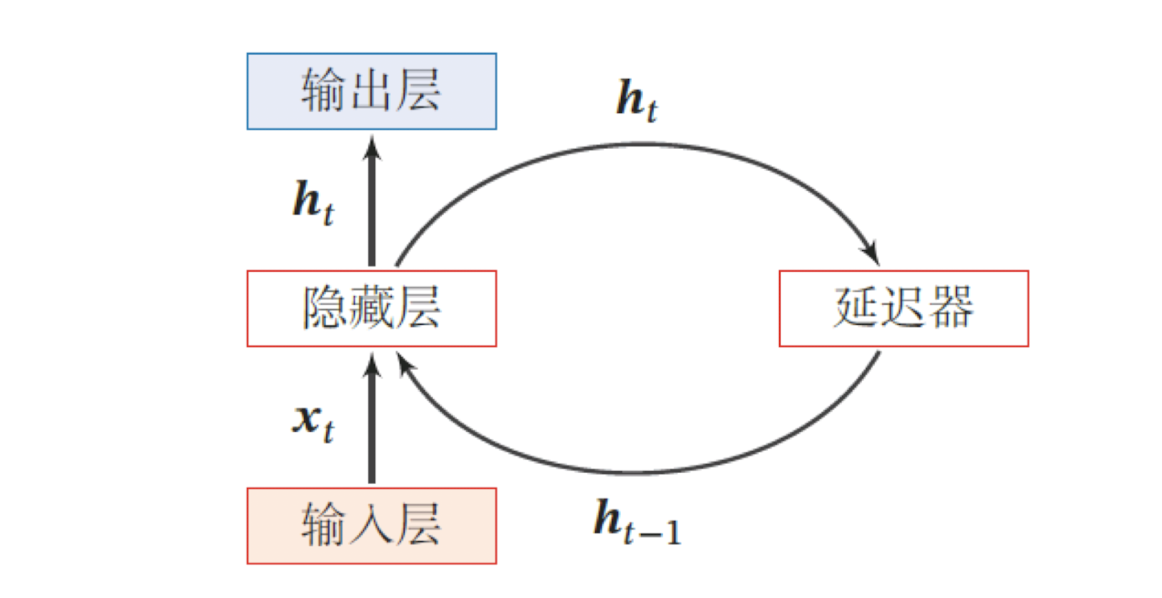
- x t x_t xt 是一个向量,它表示t时刻输入层的值;
- h t − 1 , h t h_{t-1},h_t ht−1,ht 分别表示t-1时刻和t时刻隐藏层的值.
其中
h
t
h_t
ht的计算如下:
h
t
=
f
(
U
h
t
−
1
+
W
x
t
+
b
)
,
h_t=f(Uh_{t-1}+Wx_t+b),
ht=f(Uht−1+Wxt+b),
其中
x
t
∈
R
M
\mathbf{x}_t\in\mathbb{R}^M
xt∈RM 为
t
t
t时刻网络的输入,
U
∈
R
D
×
D
\mathbf{U}\in\mathbb{R}^{D\times D}
U∈RD×D 为状态-状态权重矩阵,
W
∈
R
D
×
M
\mathbf{W}\in\mathbb{R}^{D\times M}
W∈RD×M为状态-输入权重矩阵,
b
∈
R
D
\mathbf{b}\in\mathbb{R}^D
b∈RD 为偏置向量,
f
f
f为激活函数.上面是RNN网络中的单个结点,下面给出长度为
T
T
T的RNN网络,我们可以更清晰的看到前一时刻对后一时刻的影响.
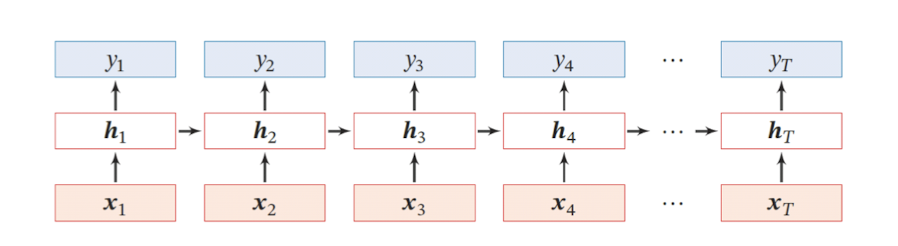
现在看上去就比较清楚了, 这个网络在
t
\mathrm{t}
t 时刻接收到输入
x
t
\mathrm{x}_{t}
xt 之后, 隐藏层的值是
h
t
h_t
ht, 输出值是
y
t
\mathrm{y}_{t}
yt 。关键一点是,
h
t
h_t
ht 的值不仅仅取决于
x
t
\mathrm{x}_{t}
xt, 还取决于
h
t
−
1
\mathrm{h}_{t-1}
ht−1 。可以用下面的公式来表示循环神经网络的计算方法:
y
t
=
V
h
t
(
1
)
\mathrm{y}_{t}=V \mathrm{h}_{t}\quad (1)
yt=Vht(1)
h
t
=
f
(
W
x
t
+
U
h
t
−
1
)
(
2
)
\mathrm{h}_{t}=f\left(W \mathrm{x}_{t}+U \mathrm{h}_{t-1}\right)\quad(2)
ht=f(Wxt+Uht−1)(2)
- 式 1 是输出层的计算公式, 输出层是一个全连接层, 也就是它的每个节点都和隐藏层的每个节点相连, V \mathrm{V} V 是输出层的权重矩阵.
- 式 2 是隐藏层的计算公式, 它是循环层。 U \mathrm{U} U 是输入 x x x 的权重矩阵, W \mathrm{W} W 是上一次的值 h t − 1 \mathrm{h}_{t-1} ht−1 作为这一次的输入的权重矩阵, f f f 是激活函数.(这里我们省略 b b b)
从上面的公式可以看出, 循环层和全连接层的区别就是循环层多了一个权重矩阵
W
\mathrm{W}
W 。如果反复把式 2 带入到式 1 , 将得到:
y
t
=
V
h
t
=
V
f
(
W
x
t
+
U
h
t
−
1
)
=
V
f
(
W
x
t
+
U
f
(
W
x
t
−
1
+
U
h
t
−
2
)
)
=
V
f
(
W
x
t
+
U
f
(
W
x
t
−
1
+
U
f
(
W
x
t
−
2
+
U
h
t
−
3
)
)
)
=
V
f
(
W
x
t
+
U
f
(
W
x
t
−
1
+
U
f
(
W
x
t
−
2
+
U
f
(
W
x
t
−
3
+
…
)
)
)
)
\begin{aligned} \mathrm{y}_{t} &=V \mathrm{h}_{t} \\ &=V f\left(W \mathrm{x}_{t}+U \mathrm{h}_{t-1}\right) \\ &=V f\left(W \mathrm{x}_{t}+U f\left(W \mathrm{x}_{t-1}+U \mathrm{h}_{t-2}\right) \right)\\ &=V f\left(W \mathrm{x}_{t}+U f\left(W \mathrm{x}_{t-1}+U f\left(W \mathrm{x}_{t-2}+U \mathrm{h}_{t-3}\right)\right)\right) \\ &=V f\left(W \mathrm{x}_{t}+U f\left(W \mathrm{x}_{t-1}+U f\left(W \mathrm{x}_{t-2}+U f\left(W \mathrm{x}_{t-3}+\ldots\right)\right)\right)\right) \end{aligned}
yt=Vht=Vf(Wxt+Uht−1)=Vf(Wxt+Uf(Wxt−1+Uht−2))=Vf(Wxt+Uf(Wxt−1+Uf(Wxt−2+Uht−3)))=Vf(Wxt+Uf(Wxt−1+Uf(Wxt−2+Uf(Wxt−3+…))))
从上面可以看出, 循环神经网络的输出值
y
t
\mathrm{y}_t
yt, 是受前面历次输入值 $ x_{t}, x_{t-1}, \cdots,x_1$影响的, 这就是为什么循环神经网络可以往前看任意多个输入值的原因。
Note:
- 从以上结构可看出,传统的RNN结构的输⼊和输出等⻓.
- 我们可以看到每个节点会共用参数 W , U , V W,U,V W,U,V.
二、vector-to-sequence结构
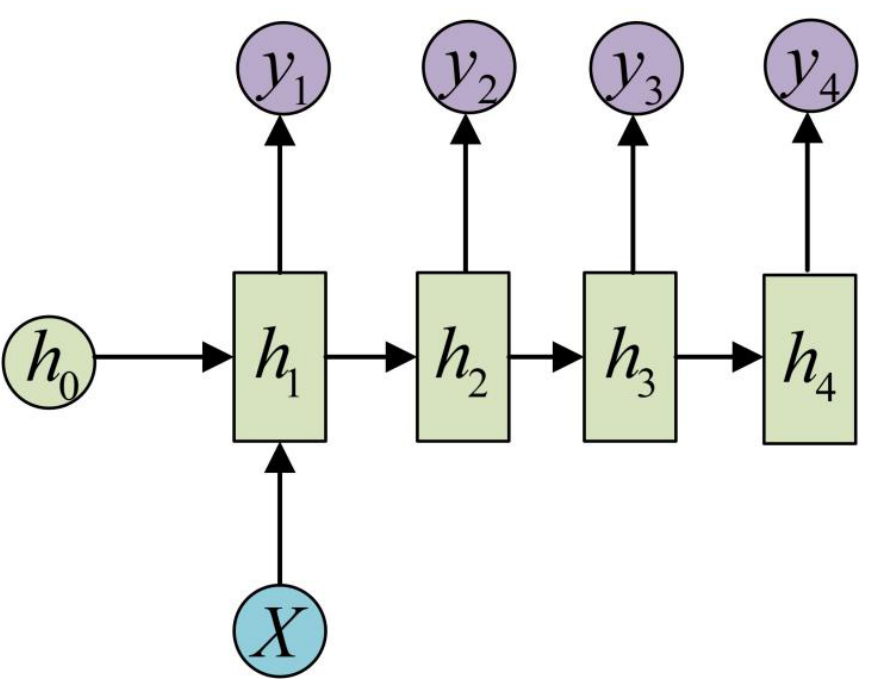
有时我们要处理的问题输⼊是⼀个单独的值,输出是⼀个序列。
此时,有两种主要建模⽅式:
- ⽅式⼀:可只在其中的某⼀个序列进⾏计算,⽐如序列第⼀个进⾏输⼊计算,其建模⽅式如下:
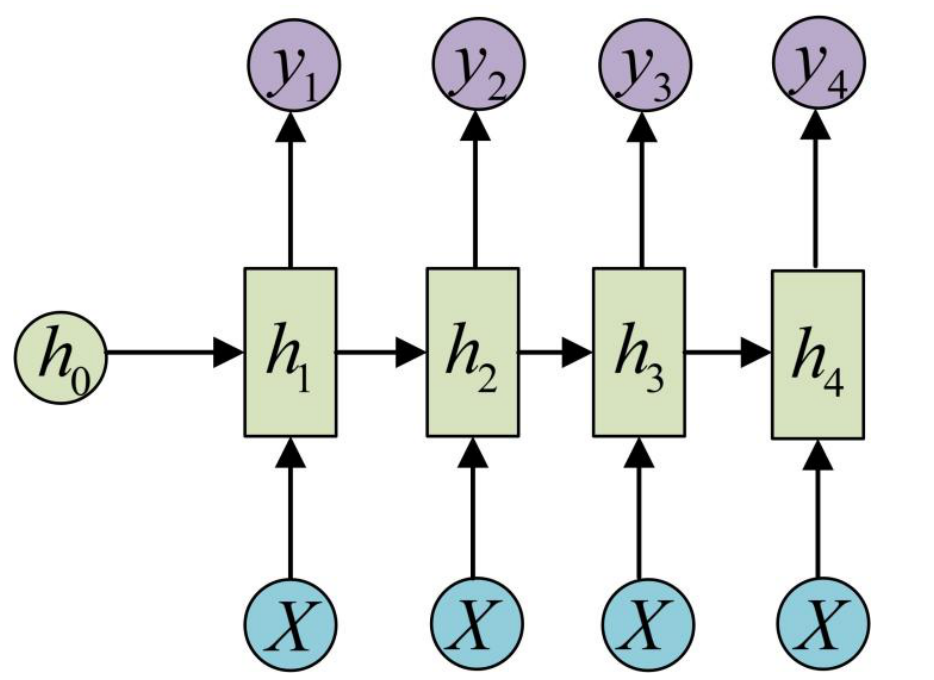
- 把输⼊信息X作为每个阶段的输⼊,其建模⽅式如下:
三、sequence-to-vector结构
有时我们要处理的问题输⼊是⼀个序列,输出是⼀个单独的值,此时通常在最后的⼀个序列上进⾏输出变换,其建模如下所⽰:
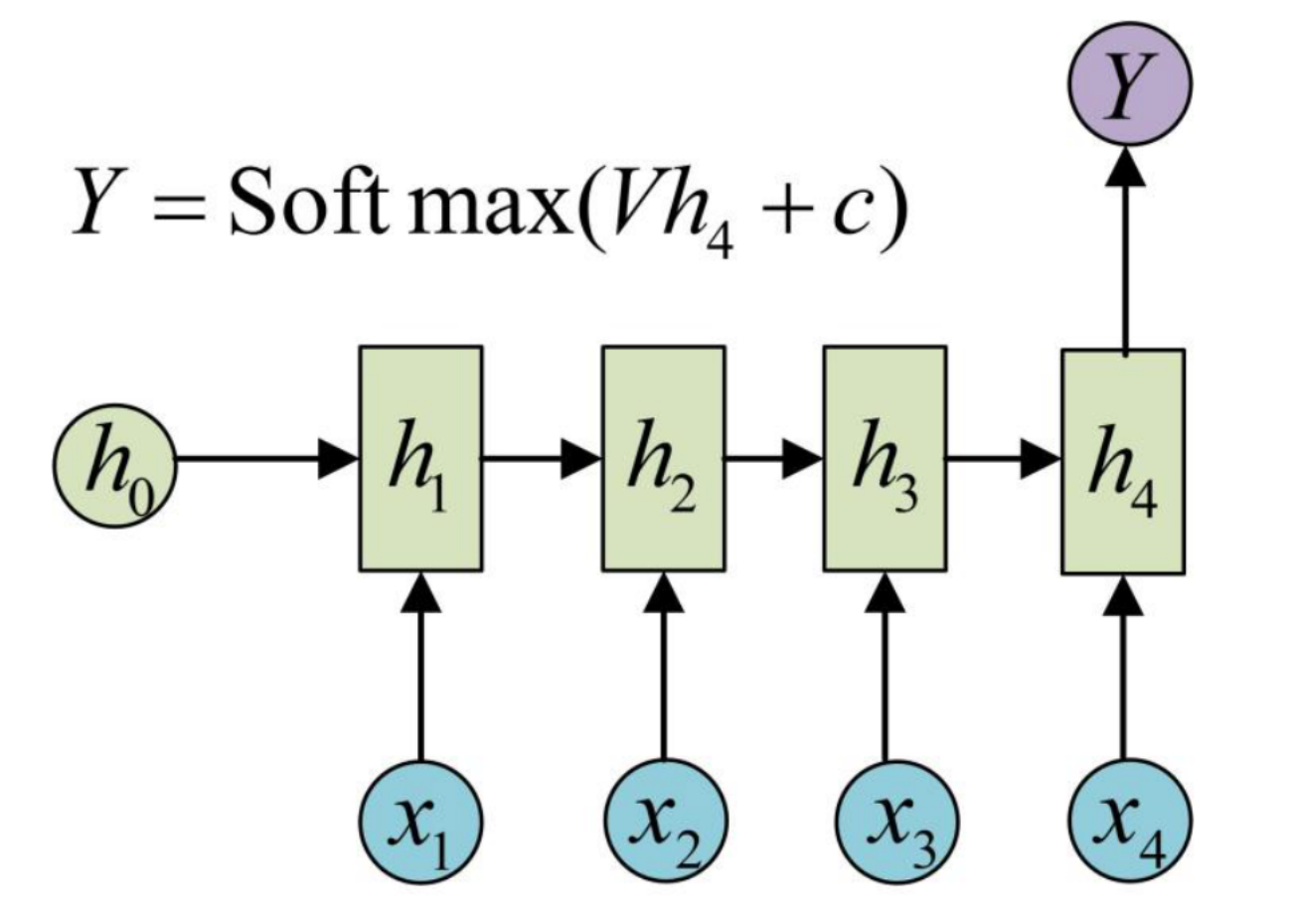
四、Seq2Seq模型
RNN最重要的一个变种:Seq2Seq,这种结构又叫Encoder-Decoder模型。
原始的sequence-to-sequence结构的RNN要求序列等长,然⽽我们遇到的⼤部分问题序列都是不等长的,如机器翻译中,源语⾔和⽬标语⾔的句⼦往往并没有相同的长度。
1 Encoder
将输⼊数据编码成⼀个上下⽂向量 c,这部分称为Encoder,其⽰意如下所⽰:
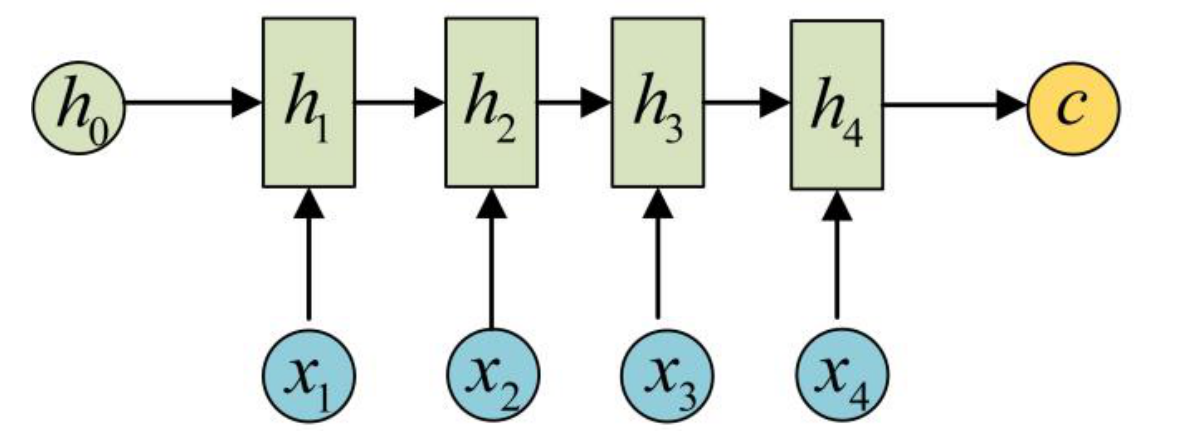
得到c有多种⽅式:
- 最简单的⽅法就是把Encoder的最后⼀个隐状态赋值给c : c = h 4 c=h_4 c=h4
- 还可以对最后的隐状态做⼀个变换得到 : c = q ( h 4 ) c=q(h_4) c=q(h4)
- 也可以对所有的隐状态做变换: c = q ( h 1 + h 2 + h 3 + h 4 ) c=q(h_1+h_2+h_3+h_4) c=q(h1+h2+h3+h4)
2 Decoder
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做初始状态输入到Decoder中:
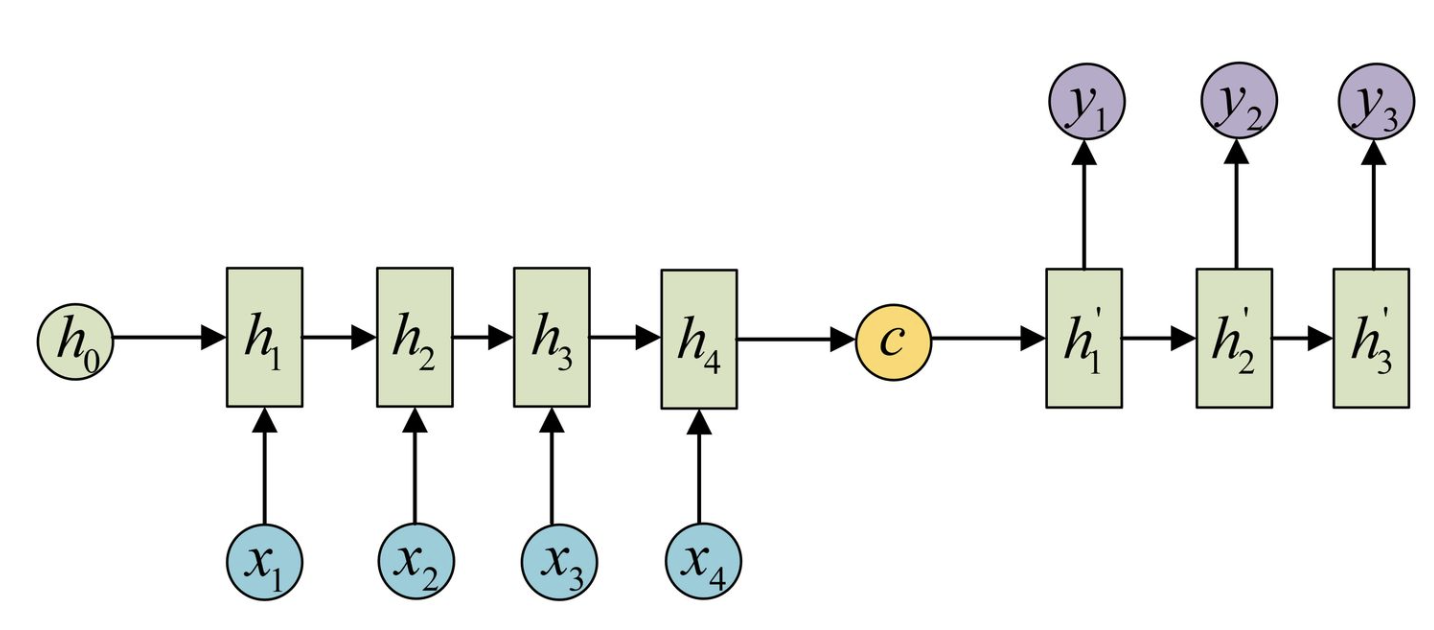
还可以将c作为Decoder的每⼀步输⼊,⽰意图如下所⽰:
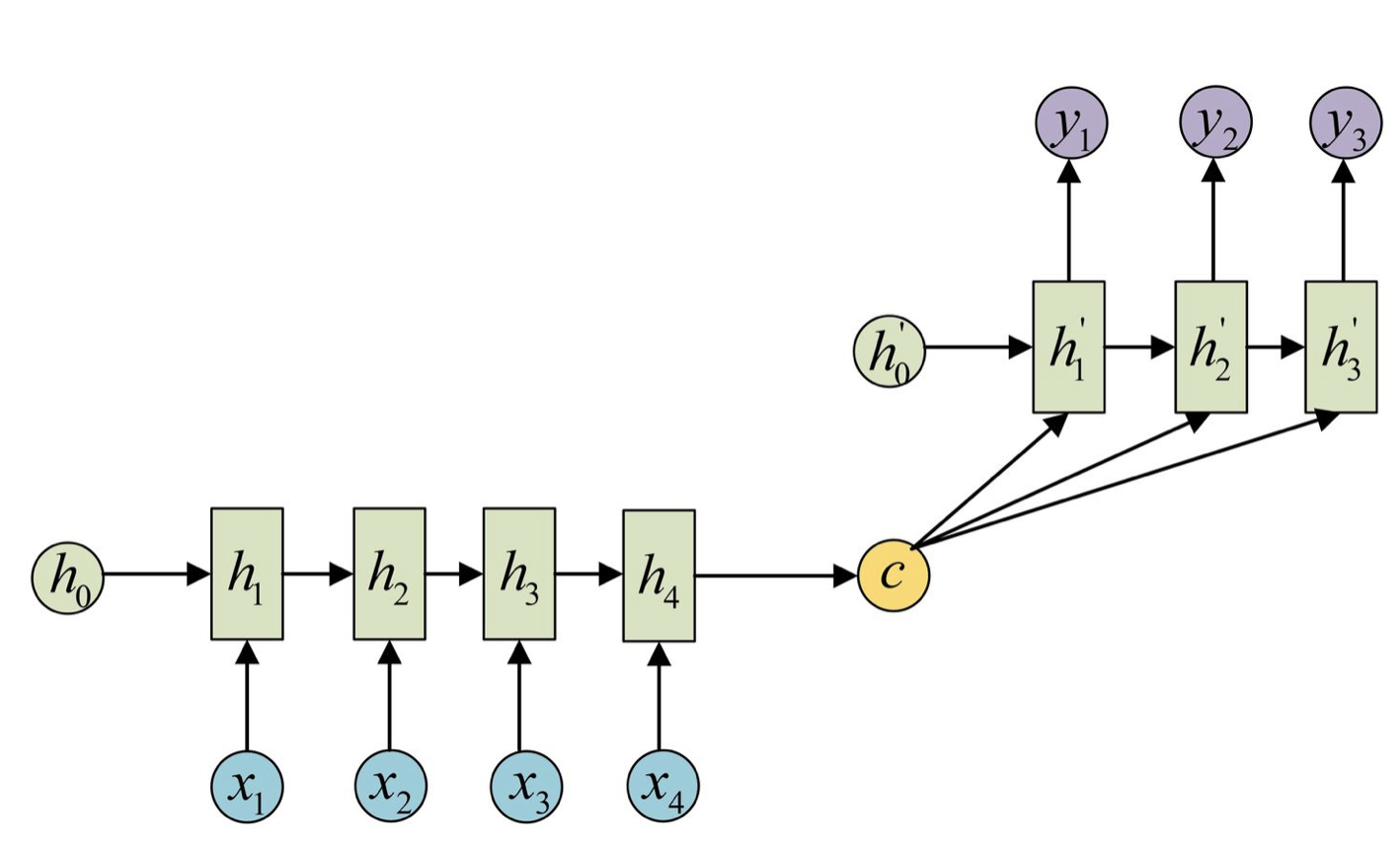
由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛,比如:
- 机器翻译,Encoder-Decoder的最经典应用,事实上这一结构就是在机器翻译领域最先提出的;
- 文本摘要,输入是一段文本序列,输出是这段文本序列的摘要序列;
- 阅读理解,将输入的文章和问题分别编码,再对其进行解码得到问题的答案;
- 语音识别,输入是语音信号序列,输出是文字序列。
五、Embedding
1 什么是 Embedding?
Embedding 是一种将离散的、高维的输入数据(如单词或符号)转换为连续的、低维的向量表示的方法。其目的是捕捉输入数据中的语义和结构信息,使其在向量空间中具有有意义的分布。
2 为什么需要 Embedding?
在 NLP 中,原始的文本数据通常由单词、子词或字符组成,这些元素本质上是离散的符号。传统的处理方法(如 one-hot 编码)会将每个单词表示为一个高维的稀疏向量,缺点如下:
- 维度过高:词汇表中的每个单词都需要一个独立的维度,对于大型词汇表,这会导致向量的维度非常高。
- 稀疏性:大多数维度都是 0,只有一个维度是 1,这导致向量非常稀疏。
- 缺乏语义信息:one-hot 向量无法捕捉单词之间的语义关系,如“国王”与“王后”之间的关系。
Embedding 方法通过学习一个低维的、连续的向量表示来解决这些问题。每个单词或符号都被表示为一个实数向量,这些向量在训练过程中被优化,以捕捉单词之间的语义和语法关系。
3 Embedding 的实现
在深度学习模型(如 Transformer)中,embedding 通常通过一个可训练的查找表实现。查找表的每一行对应一个词汇表中的单词,行中的值是该单词的嵌入向量。这些嵌入向量在模型训练过程中不断调整,以优化模型的性能。
具体步骤如下:
- 初始化:将每个单词初始化为一个随机的或预训练的向量。
- 训练:在训练过程中,模型根据任务目标不断调整这些向量,使得它们能够更好地表示单词的语义和语法信息。
- 使用:训练完成后,这些向量就可以用于各种 NLP 任务,如文本分类、情感分析、机器翻译等。
4 例子
假设我们有一个简单的词汇表:[“猫”, “狗”, “鱼”]。通过 embedding 层,这些单词会被转换为低维的向量,如:
- “猫” -> [0.2, -1.3, 0.5]
- “狗” -> [0.3, -1.2, 0.4]
- “鱼” -> [-0.5, 0.8, -0.1]
这些向量的维度通常比原始 one-hot 向量的维度小得多(如 300 维,而不是数万维),并且这些向量可以捕捉到单词之间的语义相似性。例如,“猫”与“狗”的向量可能比较接近,而“鱼”的向量则相对远一些。
5 实例:机器翻译
神经机器翻译(Neural Machine Translation, NMT)是一种基于深度学习技术的机器翻译方法。与传统的统计机器翻译(Statistical Machine Translation, SMT)不同,NMT 使用神经网络模型来直接建模源语言到目标语言之间的翻译过程。下图是Encoder编码的过程:
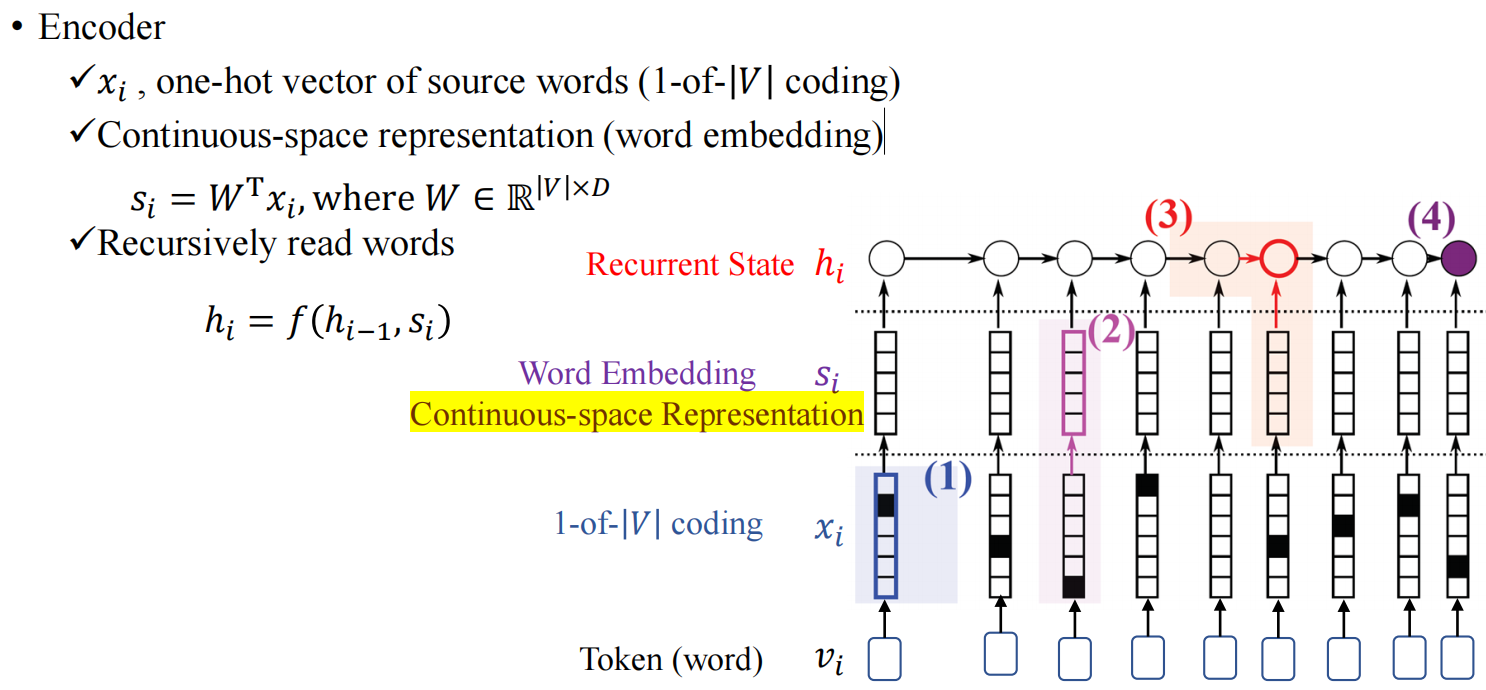
Note:
- 在翻译的时候,我们需要对词进行Embedding,将其变成一个连续的向量表达.
- v i v_i vi表示每个输入的词,通过embedding变成向量 s i s_i si,方便后续的处理, W W W是embedding过程中可学习的参数矩阵.
- 得到 s i s_i si后,我们就可以按照前面介绍的方法进行Encoding.
Decoder的过程如下图所示:
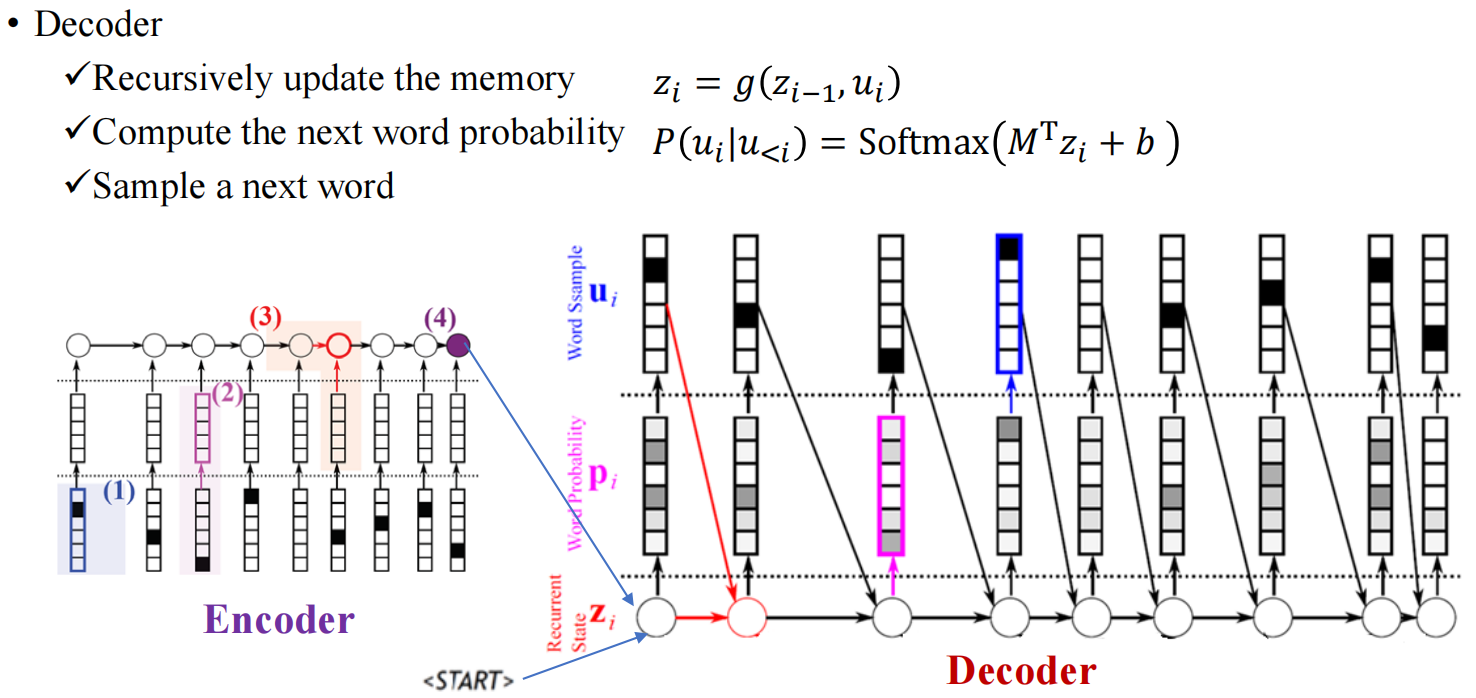
Note:
- z i − 1 \mathbf{z}_{i-1} zi−1为上一个节点的隐藏值, u i u_i ui为上一个节点的输出;
- 用Softmax来得到预测的每个词的概率,概率最大的作为当前预测词.
6 总结
Embedding 是一种将离散的输入数据转换为连续的、低维向量表示的方法,广泛应用于自然语言处理任务中。它能够有效地捕捉单词之间的语义和语法关系,提高模型的处理能力和表现。在 Transformer 等深度学习模型中,embedding 层是关键组成部分,负责将输入序列转换为模型可以处理的向量形式。
参考资料
- 深度学习500问
- 邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.















 4973
4973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









