







前言
本文一开始属于此文《机器人大小脑的整合——从微调VLM起步的VLA发展史:详解RoboFlamingo、Octo、TinyVLA》的第四部分,由于我们准备挑战下折叠衣服这个任务
- 之前我司『七月在线』各地团队 都做的工业场景,此前没考虑过这类家庭场景
如也想挑战的,欢迎私我简介(比如在哪个公司做什么,或在哪个高校的什么专业),邀你进:七月具身智能:VLA交流大群 - 故除了π0「π0详见《通用VLA π0:复现与二次开发》」之外,还关注到了这个DexVLA,加之还准备解读下其源码,从而把DexVLA这部分独立成本文
且会一下子让你掌握DexVLA的关键点,比如「如果下面两句暂不理解,没事,看完全文就理解了」
- 其第一阶段(左)仅对扩散(动作)专家进行预训练,不依赖于VLM『Stage 1 (left) trainsthe Diffusion Expert independently, without the VLM』
- 既然不依赖VLM,那动作专家的预训练过程中,如何针对性的处理图像和语言呢,简单,让ResNet-50+Distilbert 来打辅助
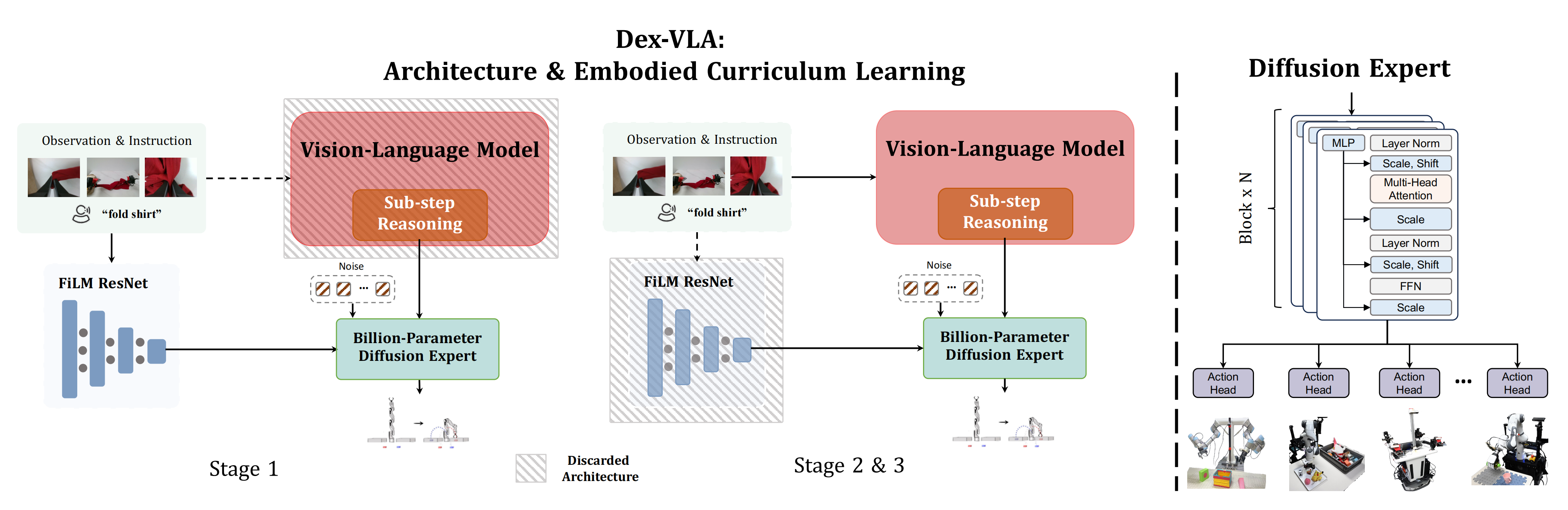
第一部分 DexVLA:在VLM上插上1B大小的扩散动作专家,类似24年12月发布的Diffusion VLA
1.1 发布于25年2月的DexVLA的提出背景与相关工作
1.1.1 DexVLA:号称15小时数据搞定衣物折叠收纳
25年2月,来自美的集团、华东师范大学、上海大学的研究者们提出了DexVLA
- 其对应的论文为《DexVLA: Vision-Language Model with Plug-In Diffusion Expert for General Robot Control》
- 其项目地址为:dex-vla.github.io/
其GitHub地址为:github.com/juruobenruo/DexVLA
他们指出,使机器人能够在多样化的环境中执行各种任务是机器人学中的一个核心挑战。实现多功能性——即在适应语言指令、环境限制和意外中断的同时,能够在多样化的环境中解决多种任务的能力,更是一个更高的要求

模仿学习[26, 40, 24, 59, 58,35],特别是通过视觉-语言-动作VLA模型(例如,[5, 7, 23, 20]),在实现可推广技能方面显示出了潜力
然而,实现全能机器人基础模型的愿景面临着持续的挑战。进展的两个关键瓶颈是:
- 数据稀缺:如OpenVLA [23]/Octo[30],依赖于大量数据集
如Open-XEmbodiment数据集(4000小时)[31],甚至更大的语料库
而通过人类演示收集这些数据极为昂贵且劳动密集 [13-Humanplus, 18-Umi on legs, 51-Tidybot, 53-Sapien] - 架构不平衡:当前的VLA模型通常优先扩展视觉-语言模型(VLM)组件,例如OpenVLA使用7B VLM,而π0使用3B VLM。尽管通过互联网规模的数据预训练增强了视觉和语言理解,VLM组件仍与机器人动作的具身传感器运动上下文脱节
本文提出了一种用于视觉-语言-动作模型的插件式扩散专家,即DexVLA,这是一种旨在增强VLA在跨多种机器人具身情况下处理复杂长时任务的效率和泛化能力的新框架
其通过两项关键创新实现这一目标
首先,高达1B的参数扩散专家:鉴于传统动作专家在处理跨形体数据方面的局限性,他们提出了一种新的基于扩散的动作专家。该扩散专家采用多头架构,每个头对应一个特定的具身,从而能够在多样的形态中有效学习
此外,将扩散专家的模型规模扩大到十亿参数,远高于传统的数百万参数规模。这种扩展显著增强了模型从多样且大量的数据中学习复杂运动技能和控制策略的能力
其次,具身课程学习(Embodied Curriculum Learning):一种三阶段训练策略,逐步学习更难的任务。这在概念上类似于人类的学习方式,先从简单任务开始,然后逐渐引入复杂性,以避免对学习者一上来就造成过度负担
- 阶段1:跨体态(cross-embodiment)预训练阶段,侧重于学习低级别、与embodiment无关的运动技能
在此阶段,仅使用跨主体数据预训练扩散专家,而不涉及VLM模型 - 阶段2:主体特定的对齐(embodiment-specific alignment)阶段,类似于“适应你的身体”
具体来说,它将抽象的视觉-语言表示与特定机器人的物理约束相结合。值得注意的是,仅此阶段就使模型能够完成多种任务,例如对领域内物体进行折叠衣服,和拾取箱子等任务 - 阶段3:任务特定的适应旨在使机器人掌握复杂任务
这些任务包括完成长时间任务并推广到新颖的物体。虽然该模型已经从多样的机器人行为中学习,并逐步发展出应对复杂任务的灵巧技能,但在诸如叠放皱褶衬衫或连续执行分拣操作等超长时域、接触丰富的场景中仍面临局限性
以前的方法通常依赖于高层策略模型;例如,π0使用SayCan每两秒更新一次指令。相比之下,他们建议利用VLA模型的内在推理能力直接指导机器人动作
即通过使用带有子步骤推理注释的演示数据训练模型
We train the model using demonstrations annotated with sub step reasoning
例如,将“折叠衬衫”分解为:“抚平皱褶”、“对齐袖子”和“固定折叠”——使其学习解耦的动作表示,将语言子指令映射到精确的运动原语
他们在各种主体中评估了DexVLA,包括单臂、双臂、灵巧手和移动双臂机器人,展示了其在多种任务中的有效性。DexVLA在许多任务中无需任务特定的适应就能实现高成功率
- 例如,它在折叠平整的衬衫任务中取得了接近满分(0.92)
- 它还可以在少于100次演示的情况下学习新主体的灵巧技能,例如用灵巧手倒饮料和在双臂UR5e上进行包装
- 此外,他们的方法可以仅使用直接指令完成复杂的长时间任务,例如折叠衣物,消除了需要SayCan之类的高层次策略模型的分解任务的需求
且他们号称模型仅在100小时的演示数据上进行了预训练,并在单个Nvidia A6000 GPU上以60Hz的速度运行,从而实现了成本高效的训练和快速的推理
1.1.2 相关工作
相关的工作,一方面,包括视觉-语言-动作模型用于机器人控制
近年来的研究集中在开发通用的机器人策略,这些策略基于不断扩展的机器人学习数据集进行训练[12, 15,13, 18, 17, 24, 36, 9-UMI, 14]
视觉-语言-动作模型VLA [23-Openvla, 5-π0, 33-Fast_π0, 50-Tinyvla, 7, 62-3d VLA, 60-Grape, 16-Improving Vision-Language-Action Model with Online Reinforcement Learning,详见此文《RL微调VLA模型——从通过RLAIF微调的GRAPE,到通过在线RL改进的Re-VLA》的第二部分, 2]代表了一种有前景的方法,用于训练此类通用策略
VLA通过调整预训练在大规模互联网图像和文本数据上的视觉-语言模型,用于机器人控制[55]。这种方法提供了几个优势:
- 利用拥有数十亿参数的大型视觉-语言模型主干网络,为拟合大规模机器人数据集提供了所需的容量
- 此外,复用在互联网级规模数据上预训练的权重,增强了VLA对多样化语言指令的理解能力,并提升了其对新颖物体和环境的泛化能力
然而,目前的VLA模型并未专注于通过利用底层VLM模型的参数来学习灵巧的机器人技能。尽管一些工作,如π0[5]和TinyVLA[50],引入了外部动作专家来促进动作学习,但它们的训练流程仍然依赖于整个模型
另一个挑战是,即使是像π0这样的先进方法,虽然能够完成高度灵巧和长时间跨度的任务,但仍需借助高层策略:如SayCan[1]的协助,将任务分解为子目标——这使得VLA能够按顺序依次完成各个子任务
DexVLA的目标是通过在网络的每个组件上以子步骤级别标注的数据进行训练,将这种高层规划能力直接集成到模型本身。因此,DexVLA的方法能够在无需外部高层策略的情况下完成如叠衣服等复杂任务,使整个框架更加端到端,并展现出显著的潜力
二方面,相关的工作还包括扩散模型
扩散模型 [11-Diffusion forcing, 32-Scalable diffusion models with transformers, 19-DDPM] 已成为视觉生成领域的主流方法
- 扩散策略 [8-diffusion policy] 成功地将扩散模型应用于机器人学习,展示了其对多模态动作分布建模的能力
- 后续研究进一步发展了扩散策略
61-Aloha unleashed,
48-Sparse diffusion policy
34-Consistency policy
38-Multimodal diffusion transformer
41-Fine-tuning of continuous-time diffusion models as entropy-regularized control
42-Feedback efficient online fine-tuning of diffusion models
3-Training diffusion models with reinforcement learning
4-Zero-shot robotic manipulation with pretrained image-editing diffusion models
10-The ingredients for robotic diffusion transformers
25-Data scaling laws in imitation learning for robotic manipulation
37-Diffusion policy policy optimization
47-Inferencetime policy steering through human interactions
29-Compositional visual generation with composable diffusion models
比如将其应用于 3D 环境
22-3d diffuser actor
57-3d diffusion policy
56-Generalizable humanoid manipulation with improved 3d diffusion policies
54-Dnact:Diffusion guided multi-task 3d policy learning
扩展其能力
63-Scaling diffusion policy in transformer to 1 billion parameters for robotic manipulation
提高其效率
21-Mail: Improving imitation learning with selective state space models
34-Consistency policy
并结合架构创新
总之,有许多工作研究了扩散 VLA 的使用 [50-Tinyvla, 5-π0, 49-Diffusion-vla,发布于25年12月,作者分别来自1East China Normal University, 2 Midea Group, 3 Shanghai University]
尽管现有模型在多样化任务上表现出色且具有良好的泛化能力,但它们主要依赖于预训练的视觉语言模型的能力
本文提出了一种以扩散模块为核心的范式转变,表明新设计的基于扩散的动作专家结合新颖的训练策略,使得VLA 模型能够更高效、更有效地从数据中学习
1.1.3 模型架构:VLM Qwen2-VL + 扩散动作专家ScaleDP「ResNet-50+Distilbert做辅助」
第一,针对VLM的部分,通过两个MLP 层(每层后接 LayerNorm),将VLM与动作专家连接
DexVLA模型主要基于一个Transformer语言模型骨干——具体而言是Qwen2-VL 2B。遵循VLM模型的通用框架,使用图像编码器将机器人的图像观测投影到与语言token相同的嵌入空间中
如下图所示
第一阶段(左)仅对扩散(动作)专家进行预训练,不依赖于VLM『Stage 1 (left) trainsthe Diffusion Expert independently, without the VLM』,既然不依赖VLM,那动作专家的预训练过程中,如何针对性的处理图像和语言呢,简单,让ResNet-50+Distilbert 来打辅助
- 对于图像,采用随机初始化的 ResNet-50 处理图像——每张图像都独立输入到一个 ResNet-50
- 对于语言,使用现成的Distilbert [39]来编码语言指令
During Stage 1, we only pre-train the diffusion expert with random initialized ResNet-50 to process images andoff-the-shelf Distilbert [39] to encode language instructions.
第二和第三阶段(中)将扩散专家与视觉语言模型VLM 比如Qwen2-VL 集成「关于Qwen2-VL,详见此文《一文通透Qwen多模态大模型:从Qwen-VL、Qwen2-VL到Qwen2.5-VL(含我司提问VLM项目的实现思路)》的第二部分」
同时冻结专家内部的视觉和语言组件
Stages 2 and 3 (middle) integrate the Diffusion Expert with a VLM, discarding the visual and language components within the expert
对于多个摄像头视角——利用了最多三个摄像机视角「使用 320×240 的图像分辨率」,这些视觉token被连接起来。VLM组件生成两个输出:推理token和动作token
- 动作token通过一个投影模块,该模块由两个带有LayerNorm的线性层组成
The action tokensare passed through a projection module, consisting of twolinear layers with LayerNorm
这个模块类似于像LLaVA 『28-详见此文《多模态LLaVA系列与Eagle 2——从组合CLIP ViT和Vicuna的LLaVA,到英伟达开源的VLM Eagle 2(用于人形VLA GR00T N1中)》的第一部分』这样的VLM模型中设计的连接器,旨在将VLM的嵌入空间转换为与动作专家的输入需求对齐 - 推理token通过FiLM层(采用了RT-1 [6]中的策略来初始化FiLM层),注入到策略模型中,这些FiLM层对策略中投影层的参数进行缩放和偏移
因此,该模型可以自主生成推理,并在扩散专家中利用该推理来指导动作生成
即使用 FiLM 将VLM的最终嵌入注入到扩散专家中,并应用于两个 MLP
遵循标准的后期融合VLM方法[27, 28],图像编码器将机器人获取的图像观测嵌入到:与语言token相同的嵌入空间中。且进一步通过机器人学特定的输入和输出(即本体状态和机器人动作)对该骨干网络进行了增强
第二,构建扩散专家
由于动作专家主导了机器人的动作学习过程,因此设计良好的神经网络架构对于更好的视觉-运动策略学习至关重要
- 他们使用了Scale Diffusion Policy『ScaleDP [63]』,这是一种基于Transformer架构的扩散策略的变体,其中最大规模的ScaleDP参数量可达10亿,且使用了32层,隐藏层为1280,并且有16个头
- 然而,原始的ScaleDP并未针对跨形态预训练进行设计——由于原始扩散策略模型不支持跨 embodiment 训练,故他们设计了多头输出『类似 Octo [30] 的多头结构,每个embodiment 分配一个唯一的 MLP 头』,以实现对不同机器人配置的ScaleDP预训练
简而言之,扩散专家(上图最右)使用多个头部进行跨体现学习
The Diffusion Expert (right) uses multiple heads for cross-embodiment learning
具体而言,其包含两个 MLP 层,每个层后接 LayerNorm,将VLM连接到动作专家
第三,看训练目标
给定一批输入序列,总体训练损失定义为扩散损失(),和下一个token预测(NTP)损失(
) 的加权组合
其中, 是控制NTP 损失项
相对权重的超参数
- 根据经验,如果没有阶段1 的训练,
的量级始终比
小一个数量级
- 然而,在他们采用阶段1 训练以预热扩散专家的策略学习能力后,发现
因此,他们在所有实验中设置。这一调整确保了扩散目标和下一token预测目标在训练过程中具有可比的权重,从而使模型能够有效地从动作预测和语言理解任务中学习
1.2 三阶段训练方式——课程学习让模型从简单到复杂逐步学习数据
课程学习是一种训练策略,其中系统按照从简单到复杂的顺序学习任务,类似于人类习得技能的方式。他们的三阶段训练策略实现了一种embodied curriculum,其中agent
- 首先,智能体通过跨具身数据学习可泛化的运动技能(阶段1-仅训练扩散专家)
- 其次,适应其特定的物理形态(阶段2)
- 最后优化特定任务的行为(阶段3)
这类似于人类技能的习得,其中基础能力(例如抓取)先于专业技能(例如叠衣服)
通过将“与具身无关的学习”与“具身特定的学习”解耦,最终相比端到端训练减少了60%的数据需求
设计良好的训练策略对于优化深度神经网络至关重要。与网络固有训练动态相契合的方法能够确保数据的更高效和有效利用「Approaches that align with a net-work’s inherent training dynamics ensure more efficient andeffective data utilization」
DexVLA通过将视觉-语言模型VLM与扩散专家相结合,实现通用机器人控制。依托其模块化架构——结合了两个不同的组件——他们提出了一种三阶段训练策略,系统性地解决以下问题:
- 学习灵巧的操作技能,使模型能够完成复杂任务
- 跨形态学习(cross-embodiment learning),使模型能够适应多样化的机器人平台
第一阶段训练使用他们自己收集的数据集。第二阶段训练仅限于具有相同体现的数据。后训练仅选择性地在明确提及的任务上进行
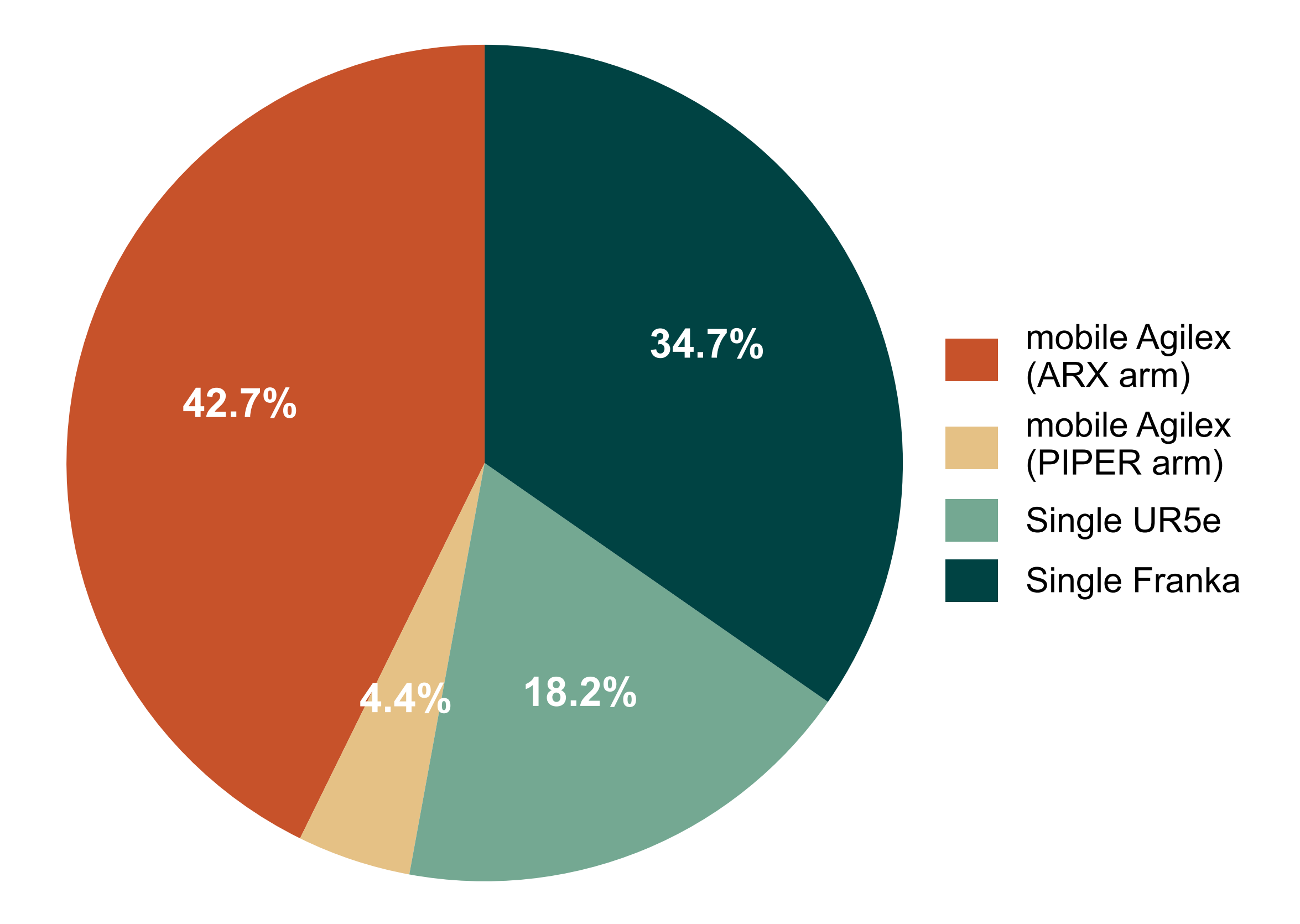
- 他们的预训练数据集总计包含 100 小时数据,涵盖 91 个不同任务
- 详细的数据分配见图6
为便于理解,以小时而非轨迹报告数据量,因为不同任务持续时间差异较大(例如,叠衣服所需时间远长于其他任务)。这种数据量化方式与π0所采用的方法一致
详细的超参数设置见表 I,具体实现细节可参见附录
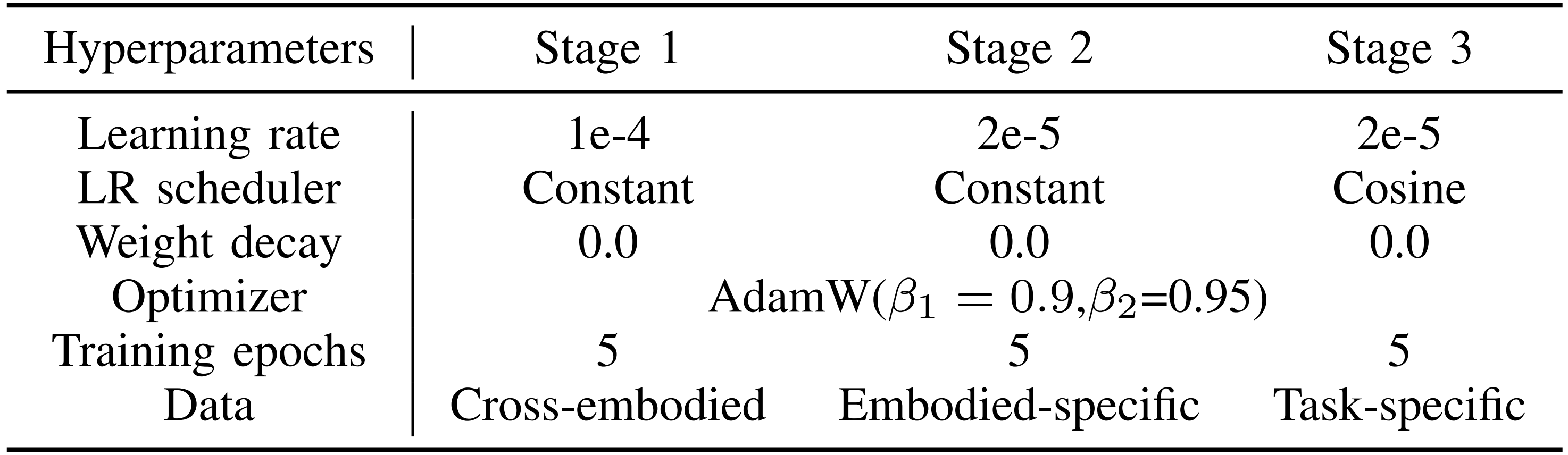
1.2.1 阶段 1:撇开VLM,独立训练1B的扩散动作专家
阶段1:跨形态(Cross-Embodiment)预训练:视觉-语言-动作模型可以视为两个不同组件的组合
- 架构的顶层是视觉-语言模型(VLM),它处理视觉输入和语言指令,并将它们映射到一个共享的嵌入空间。这个共享空间通过互联网规模的数据进行预训练,从而具备广泛的能力,包括语言理解、多模态理解以及各种其他视觉-文本任务
- 然而,尽管经过了大量的训练,VLM仍然缺乏在现实环境中与多样化物体进行物理交互的能力
为了有效地对动作专家进行预训练,他们利用所有可用数据,同时暂时将其与VLM的组件脱钩,这使他们能够专注于开发独立于语言基础的强大的动作生成能力
To effectively pre-train the action expert, we leverageall available data while temporarily decoupling it from the VLM component
他们之所以如此操作,是因为他们发现从头开始训练整个VLA模型几乎在所有任务中都会失败。因此,本节比较了阶段1(仅训练扩散专家)的训练成本与训练整个VLA模型的成本。测试报告了每小时完成的训练周期数。模型在8个Nvidia H100 GPU上训练
对于DexVLA而言
- 尽管像ResNet这样的CNN架构通常用作视觉编码器,但VLM模型中的视觉编码器通常采用Transformer架构。因此,为了便于后续阶段的对齐,他们使用ViT架构进行视觉编码
- 对于语言嵌入提取,使用DistilBERT [39],所得的语言嵌入随后通过FiLM层集成到模型中,这与以往的工作一致
对于扩散专家的预训练,一个关键的见解是需要将长时间任务(例如,清理桌子、折叠衣物)分解为子任务
- 这些任务通常超过2分钟,对于扩散专家来说,仅从单一语言指令中学习效果不佳
因此,他们在这些长时任务中标注了子步骤指令,以提供更有结构的学习信号。使用子步骤进行预训练对强性能至关重要 - 比如他们在消融研究中展示了子步骤推理的重要性。他们的实验证明,未经过这种预训练的VLA在非常长的任务中经常跳过关键步骤。子步骤注释通常每五秒提供一次演示
此外,在扩散基础的动作专家上预训练大规模机器人数据,而不是在整个VLA上预训练的优势在于扩散专家的参数数量显著小于VLA(10亿对比30亿),因此训练速度快得多
此外,在基于扩散的动作专家上对大规模机器人数据进行预训练,而不是在整个VLA上进行预训练,有几个优势
- 首先,我们的扩散专家参数量明显少于VLA(10亿对比30亿),因此训练速度大大加快
- 定量来看,在扩散专家上进行预训练的速度是全量VLA模型预训练的五倍
1.2.2 阶段2:将VLM与具身的特定对齐Embodied-Specific Alignment
虽然第一阶段通过跨具身数据学习了基本运动技能,但这种跨具身学习可能会削弱在目标具身上的表现,从而不适合实际部署
接下来的第二阶段通过使用具身特定的数据对模型进行训练,解决了这一问题,将VLM的抽象表示与扩散专家对齐。因此,他们对数据集进行筛选,仅保留具身特定数据,确保每个样本仅涉及一种具身
- 借鉴 LLaVA 等视觉语言模型中使用的镜像技术[28, 27],此阶段着重于将目标实体的动作空间与其对应的摄像头视角以及配套的语言指令进行对齐
「this stage focuseson aligning the target embodiment’s action space with its corresponding camera views and accompanying language in-structions」 - 具体而言,他们在具身特定数据上联合训练VLM模型、投影层和扩散专家,同时冻结 VLM 的视觉编码器。这种联合训练使得扩散专家能够有效地将 VLM 中的高层视觉-语言理解能力落实到目标机器人的具体运动控制空间中
Specifically, we jointly train the VLM model, theprojection layer, and the diffusion expert on this embodiment-specific data, while freezing the VLM’s visual encoder. Thisjoint training allows the diffusion expert to effectively groundthe high-level vision-language understanding from the VLMin the specific motor control space of the target robot
在阶段2训练之后,他们观察到该模型在目标实体上能够熟练地执行一系列任务,例如叠衬衫,这表明针对实体的特定训练是有效的
比如下图图7,便是无需任务特定适配的任务示例。在第二阶段训练后,通过三个任务评估了模型的性能:简单的抓取任务(上图)、折叠衬衫(中图)和简单的清理桌面任务(下图)。成功执行这些任务需要结合灵巧的操作技能

1.2.3 阶段3:任务特定适配——即微调(含子步骤推理数据的大模型标注)
此阶段优化模型执行下游任务的能力,使其更加熟练和流畅,类似于大型语言模型的后训练阶段,在该阶段模型针对领域特定数据进行微调
- 对于诸如折叠衬衫、清理桌子或使用训练过的物体进行垃圾分类等简单、对泛化要求较低的任务,任务特定训练并非必要,因为模型已经表现良好
- 然而,复杂且需要灵巧操作的任务则要求模型学习细致入微、依赖上下文的动作
因此,高效的后训练依赖于高质量的专家示范数据集,这些示范展现了连贯流畅的任务执行策略,并聚焦于能够促进任务成功完成的行为
值得注意的是,在第二阶段和第三阶段,他们均使用了带有子步骤注释的语言数据。然而,并非直接将这些子步骤推理作为指令性输入,而是将其作为中间语言输出,促使模型学习并生成这些子步骤的语言描述
- 这种方法被证明非常有效,使他们的模型能够执行复杂的、长时间跨度的任务,例如折叠衣物。虽然其他VLA(如π0 [5])也能完成此类任务,但它们依赖于像SayCan [1] 这样的高层策略模型来识别任务状态并提供下一步指令
- 相比之下,他们的框架利用VLM 主干作为隐式高层策略模型。这使得模型能够在内部解释任务状态,并将这种理解注入到用于指导动作生成的策略,消除了对外部高级策略模块的需求
且无需后期训练
怎么获取需要训练的子步骤推理数据呢?
- 对于潜在的子步骤推理,他们专注于每个持续至少五秒的主要步骤,以避免过度细分
然后他们使用了Google Gemini 2.0,将子步骤列表提供给它,用于分割视频并从列表中选择相应的推理。这被证明在标注方面是有效且高效的- 且他们仅对阶段3的训练数据进行了人工检查,因为该阶段需要更高质量的注释。这种注释策略使他们的方法可行
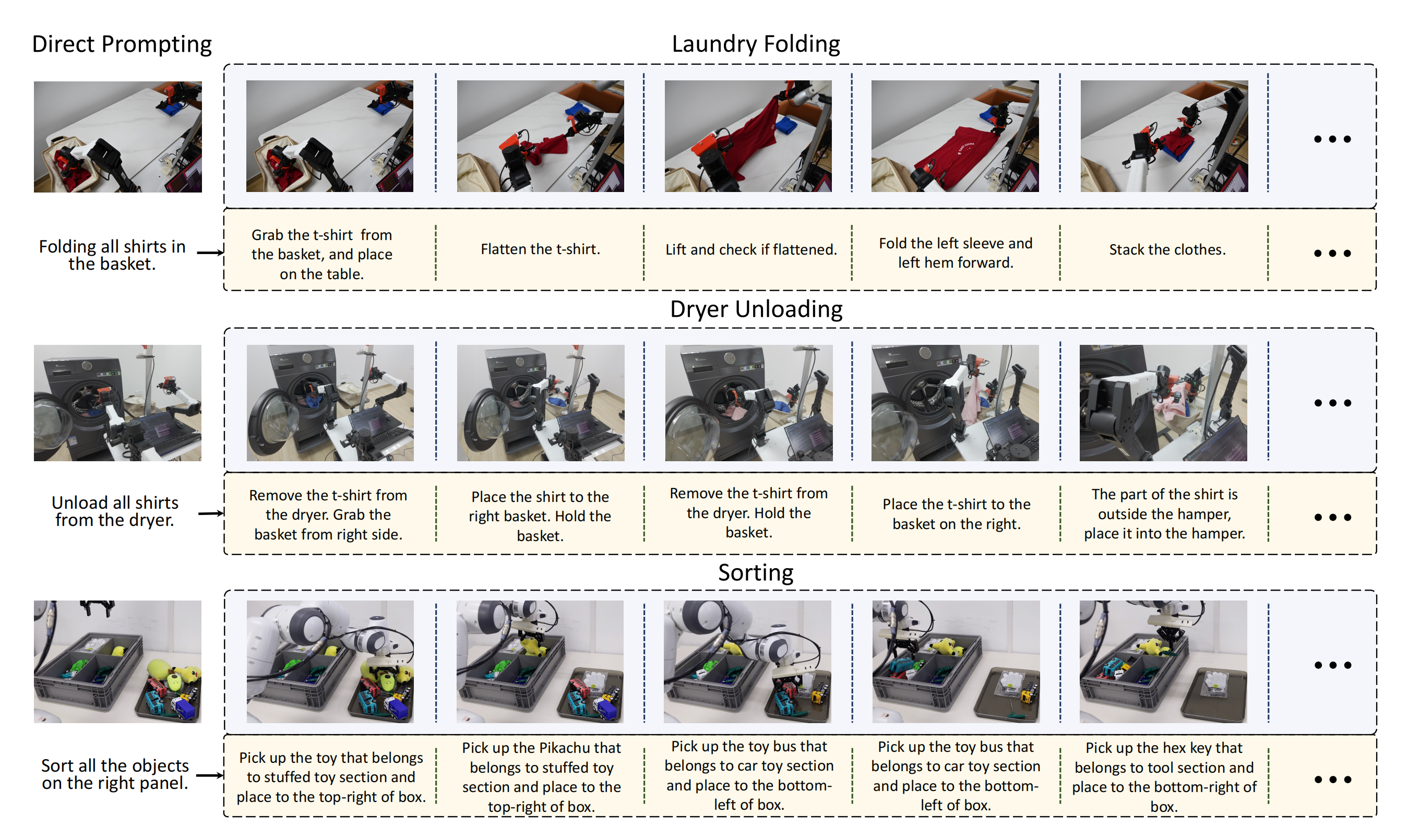
比如下图是长时间任务直接提示的示例。图中展示了三个任务:洗衣折叠(顶部),烘干机卸载(中间),排序(底部)。DexVLA可以自动将原始指令分解为子步骤。这些任务的成功不仅需要灵巧性,还需要将直接提示分解为隐含的多步推理的能力,并理解视觉上下文
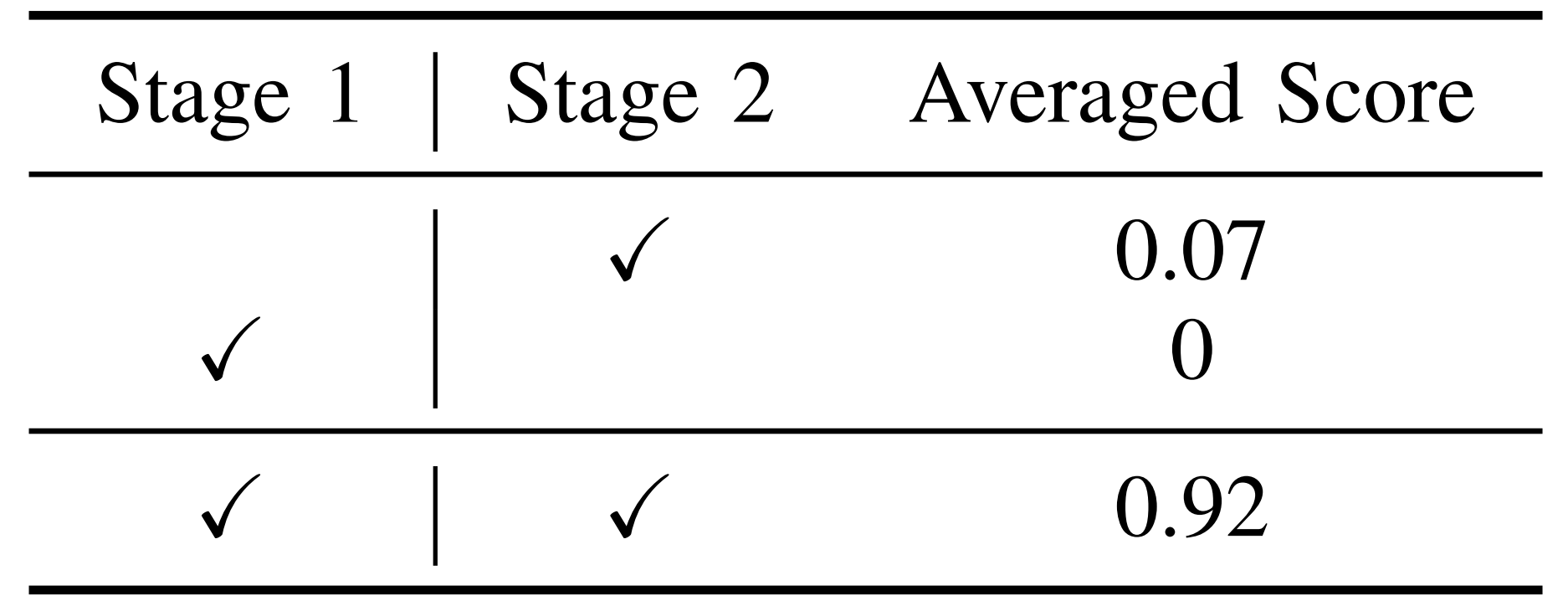
为了证明子步骤推理有帮助,他们进行了一个消融研究,包含两个设置:
- 扩散专家使用直接提示进行训练(每个任务只有一个语言指令),而VLA扩散专家使用子步骤推理进行训练
- 阶段1和阶段2均使用直接提示数据进行训练。结果如表V所示
即使是相对简单的任务,例如衬衫折叠,使用直接提示训练扩散专家也会将平均分数从0.92降至0.07
此外,从两个阶段中移除子步骤推理会导致完全失败(得分为0)。这是一个显著的观察结果。它表明,在共享参数空间中学习长时间任务有时会导致冲突- 他们假设子步骤推理使模型能够学习更解耦的动作空间,类似于将连续动作空间映射到离散动作空间[52]。这有效地对共享参数空间进行分段,为每个子步骤分配更小的参数集合[43, 45, 44]。这样可以避免参数冲突,从而提升性能和泛化能力
最后,对于局限性与未来工作,DexVLA的方法存在若干局限性和改进空间
- 首先,没有观察到从其他实体收集的数据向特定目标实体的学习迁移有显著效果
- 其次发现,诸如叠衣服等复杂任务在很大程度上依赖于准确的动作恢复以及在图像中识别正确物体状态的能力
先前的工作π0 通过使用SayCan 解决了这一问题,其中高层策略模型会频繁评估物体状态,并为低层视觉-语言-动作模型提供更新的语言指令
DexVLA当前的方法仅依赖于视觉-语言组件,在这一方面表现不佳
一个潜在的解决方案是设计一种用于显式状态检查的机制,并将其集成到DexVLA的端到端模型中,这也是我们计划在未来工作中探讨的方向 - 与π0 中报告的观察类似,作者还发现,通过阶段3训练的模型相比于仅通过阶段1 和阶段2 训练的模型,其跨任务泛化能力有所降低
然而,像叠衣服这样的复杂任务需要阶段3 的训练,才能有效学习完成任务所需的动作和物体状态
故,解决任务特定学习与泛化能力之间的权衡,对于使模型能够有效完成复杂任务而无需依赖训练后处理至关重要
第二部分 DexVLA的源码解析
// 待更


















 2180
2180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











