







前言
本文一开始是《七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2最终反超GPT4》中4.3节的内容,但考虑到
- 一方面,LongLora的实用性较高
- 二方面,为了把LongLora和LongQLora更好的写清楚,而不至于受篇幅之限制
- 三方面,独立成文可以有更好的排版,而更好的排版可以有更高的可读性(哪怕一个小小的换行都能提高可读性,更何况独立成文带来的可读性的提高)
故把这部分的内容抽取出来独立成本文
第一部分 LongLora:超长上下文大模型的高效微调方法
1.1 从PI、LoRA到LongLora
1.1.1 面对长文本:PI和LoRA在各自角度上的不足
为了更好的扩展模型的长下文长度,很多研究者或团队做了各种改进与探索
- 比如Flash-Attention、Flash-Attention2(详见此文《通透理解FlashAttention与FlashAttention2:全面降低显存读写、加快计算速度》)
- 再比如Position Interpolation (详见此文《大模型上下文扩展之YaRN解析:从直接外推ALiBi、位置插值、NTK-aware插值、YaRN》的2.3节) 其通过修改RoPE,可将llama的上下文程度扩展到32K
但longlora的论文中说,“PI spent 32 A100 GPUs to extend LLaMA models from 2k to 8k context”,可能有读者立马一惊,如果连到8k 便要spent 32块A100,那到32K得多夸张?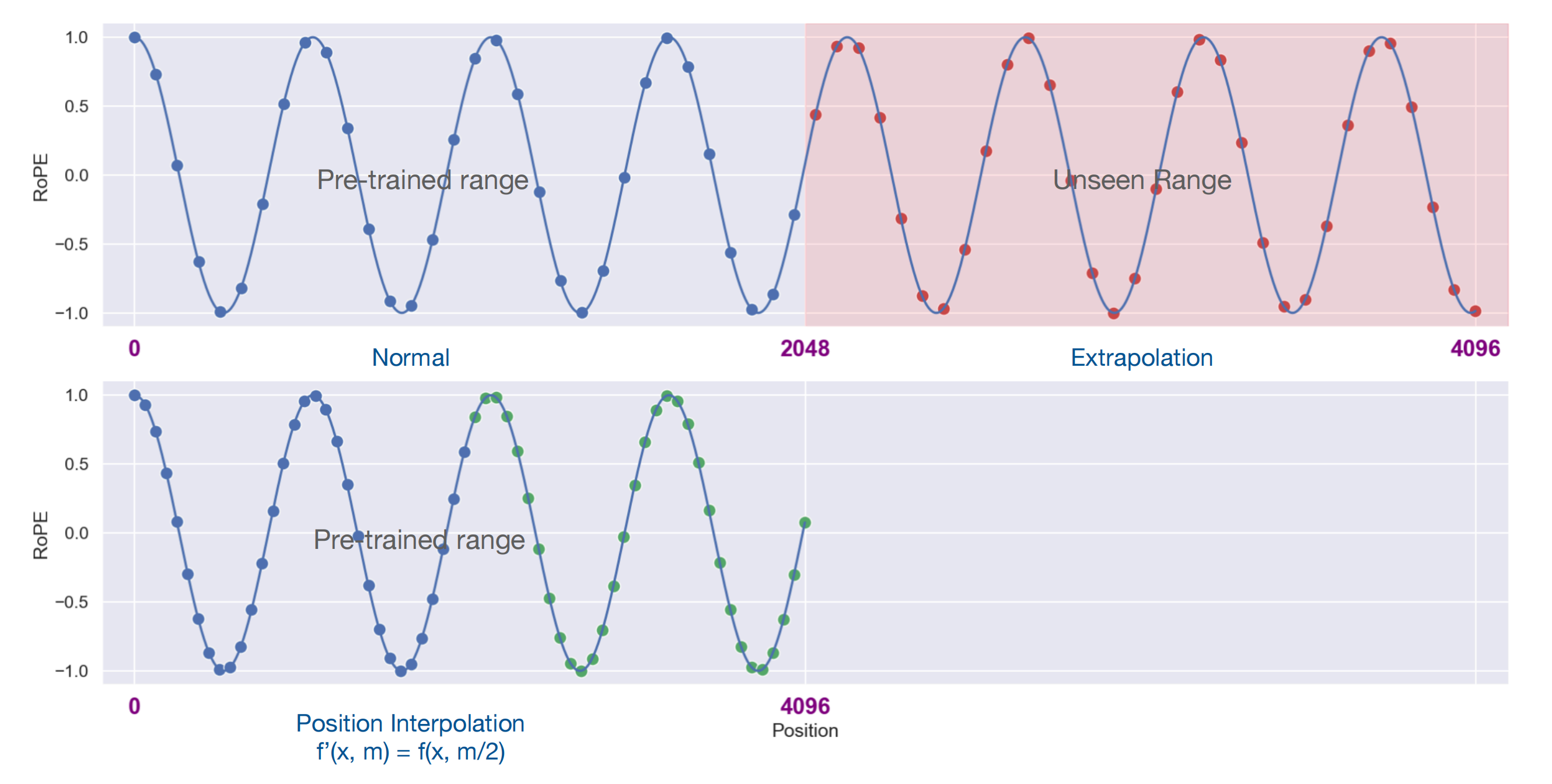
为了严谨起见,我还真翻了下PI原始论文,PI论文中的原话是:“For extending 7B, 13B and 33B models to the 8192 context window size, we use 32 A100 GPUs and 64 global batch size”
总之,上面对PI的描述很容易引发歧义,因为本质是“用了那么多卡通过PI拉长llama”,但并不代表“必须要用这么多卡才行”,而且还得看是多少B,比如按照我司七月审稿项目组的经验,apple就用了一张A100,就让llama3 8B的长度从8K到了12888(详见此文:一文速览Llama 3及其微调:如何通过paper-review数据集微调Llama3 8B)
即PI固有其局限性,但不至于那么不实用
那如何降低资源开销呢?一种直接的方法是通过LoRA对预训练的LLM进行微调
- 对于预训练的权重矩阵
它通过低秩分解(low-rank decomposition):进行更新
其中、
、而秩rank
在训练过程中,W被冻结,没有梯度更新,而A和B是可训练的(关于LoRA的更多说明,详见此文《LLM高效参数微调方法:从Prefix Tuning、Prompt Tuning、P-Tuning V1/V2到LoRA、QLoRA(含对模型量化的解释)》的第4部分) - 且在Transformer结构中,LoRA只关注权重(Wq、Wk、Wv、Wo),而冻结“包括MLP层和归一化层在内的”所有其他层
In the Transformer structure, LoRA only adapts the attention weights (Wq, Wk, Wv, Wo) and freezes all other layers, including MLP and normalization layers
总之,LoRA利用低秩矩阵对自注意块中的线性投影层进行修改,从而减少了可训练参数的数量(LoRA modifies the linear projection layers in self-attention blocks by utilizing low-rank matrices, which are generally efficient and reduce the number of trainable parameters)
然而,LoRA一方面没法扩展模型的上下文长度,二方面,单纯的低秩自适应会导致长上下文扩展的困惑度(perplexityin,简称PPL)很高,如下表所示,且即便将秩增加到一个更高的值,例如rank = 256,也并不能缓解这个问题,那咋办呢?
- 让embedding层和Norm层也添加LoRA训练之后,困惑度PPL可以显著降低

- 在效率方面,无论是否采用LoRA,计算成本都会随着上下文规模的扩大而急剧增加,这主要是由于标准的自注意机制所导致的(Vaswani et al., 2017)。如下图所示,即便使用LoRA,当上下文窗口扩展时,Llama2模型的训练时间也会大大增加
为此,他们提出shifted sparse attention(S2-Attn)以替代标准自注意力机制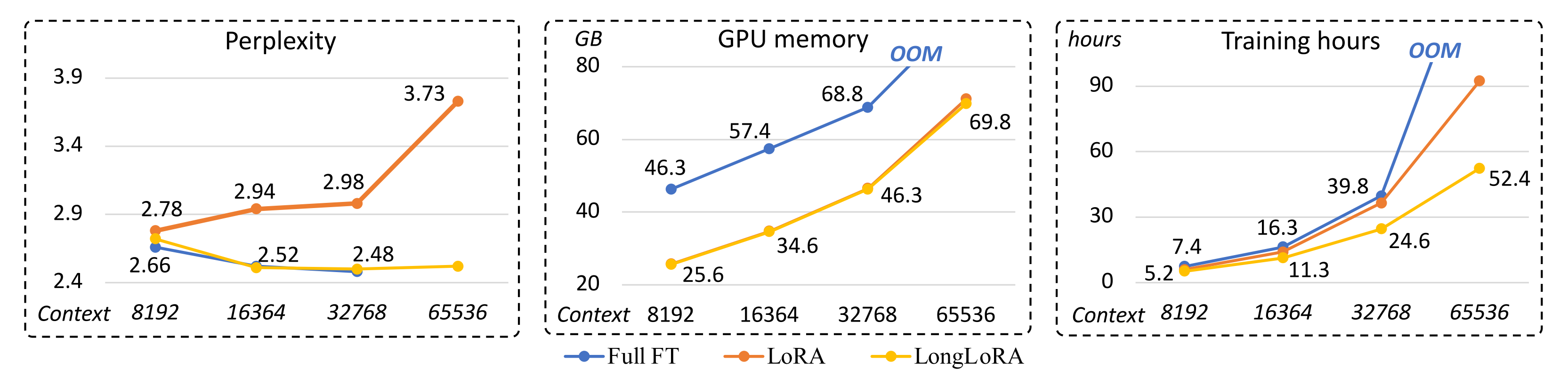
1.1.2 LongLora:训练时S2-attn、推理时再全局
LongLora是港中文和MIT的研究者通过此篇论文《LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models》于23年9月底提出的(这是其GitHub),基于PI但突破了PI原本的局限,其显著特点有三
- 训练时,改造注意力:用S2-Attn
longlora的作者团队认为:尽管在推理过程中需要密集的全局注意力,但通过稀疏的局部注意力(sparse local attention mechanism)也可以高效地完成模型的微调,比如他们提出的移位稀疏注意力(shifted sparse attention,简称S2-Attn)可有效地实现上下文扩展且显著节省计算资源(意味着训练时可以用S2-Attn,推理时又可再用全局注意力,即 fine-tuning pre-trained LLMs on S2-Attn and maintain full attention during inference)
总之,原始transformer的计算复杂度随序列长度的二次方成正比,如果序列的长度太长,那整个注意力的复杂度还是比较高的(比如把长度从2048扩展到8192,复杂度得上升4x4 = 16倍)所以,就把整个输入token序列分成多个组,然后分别计算每个组中的注意力,好减轻计算压力(shifted sparse attention splits input tokens into groups and only computes the attention in each group individually,毕竟,对于每个token而言,真正跟其有一定关联程度的绝大部分都在相近的一定区域内,从而只计算序列中每个元素与其周围一定范围内的元素之间的注意力即可)
这样 就方便拉长数据长度了「毕竟S2 attention可以节省大量GPU内存,且如果将输入token分成g组,计算复杂度可以从O(n2)降低到O((n/g)2)」 - 改造LoRA:给嵌入层、归一化层也都加上LoRA权重
他们发现,LoRA加到embedding matrix以及normalization的子网络上的时候,效果更好
啥意思?
这点在于常规操作是lora一般加到query, key, value等部分上,而这里是加到embedding matrix上,以及normaliztion上了 - 与Flash Attention、Zero3等技术兼容
LongLoRA在保留原始架构的同时扩展了模型的上下文,并且与大多数现有技术(如Flash Attention2、DeepSpeed Zero2/Zero3)兼容
此外,还进一步发布了使用LongLoRA技术的长指令遵循数据集LongAlpaca,以进行监督微调(we further conduct supervised fine-tuning with LongLoRA and our long instruction-following LongAlpaca dataset)
总之,最终使得on a single 8× A100 machine上,做到以下对应长度的扩展
| Llama2 7B | 100k |
| Llama2 13B | 65536 |
| Llama2 70B | 32768 |
然后这些模型的位置编码使用PI进行重新缩放(The maximum extended context window sizes are up to 100k for 7B models, 65536 for 13B models,and 32768 for 70B models. The position indices for these models are rescaled with Position Interpolation)
此外,以下是相关的训练细节
- 训练过程我们遵循位置插值PI中的大多数训练超参数(只是批量大小较小,毕竟只使用了一台单个8×A100 GPU的机器)
比如使用AdamW(Loshchilov& Hutter,2019年),其中 β1= 0.9和 β2= 0.95
在学习率设置上,7B和13B模型为 2 × 10−5,70B模型为 10−5
此外还使用a linear learning rate warmup,另其权重衰减为0
最后,将每个设备的批量大小设置为1,梯度累积步数设置为8,这意味着全局批量大小为64,且训练模型1000个step - 且use Flash Attention2 and DeepSpeed in stage 3 during fine-tuing(By default, we use DeepSpeed (Rasley et al., 2020) in stage 2 and use stage 3 for the maximum context length experiments)
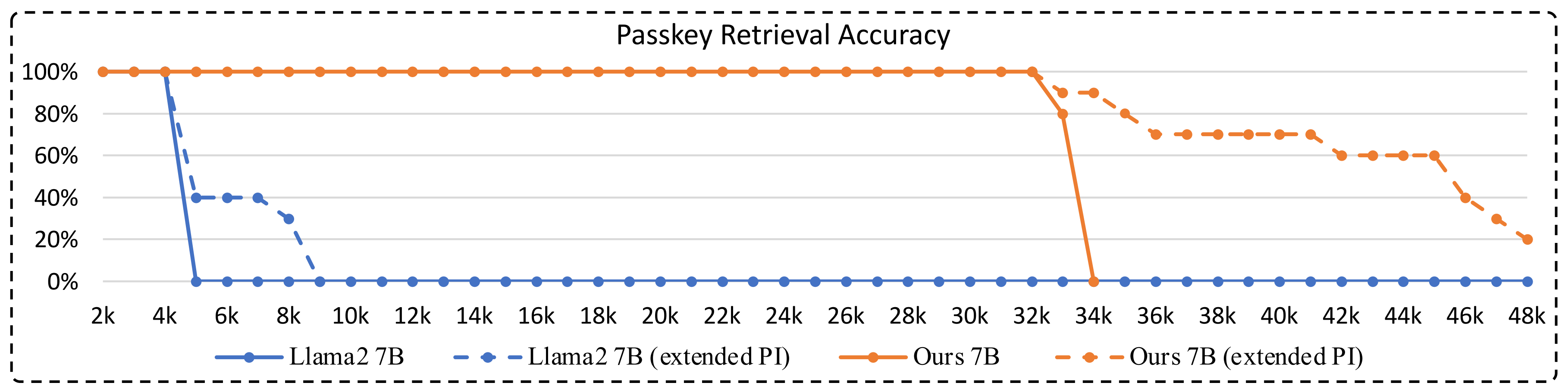
最后,顺带插个题外话,在面对一个「从非常长的对话中(长度从3k、6k、10k、13k到16k不等),检索目标主题」的任务时
- 对于在32768上下文长度上,Llama2 7B和通过longlora微调过后的7B模型准确性如下图所示,通过longlora微调过后的模型在33000或34000之前没有检索准确性下降
且通过简单扩展位置嵌入PI,它可以进一步增强对长序列建模的能力,而无需额外的微调- 至于原生的Llama2 7B,即便通过位置插值扩展了,其在4k上下文长度之后也会出现明显的准确率下降(虚线蓝色线)
1.2 LongLora所用的Shifted Sparse Attention(S2-Attn)
1.2.1 S2-Attn的原理解释
如下图所示
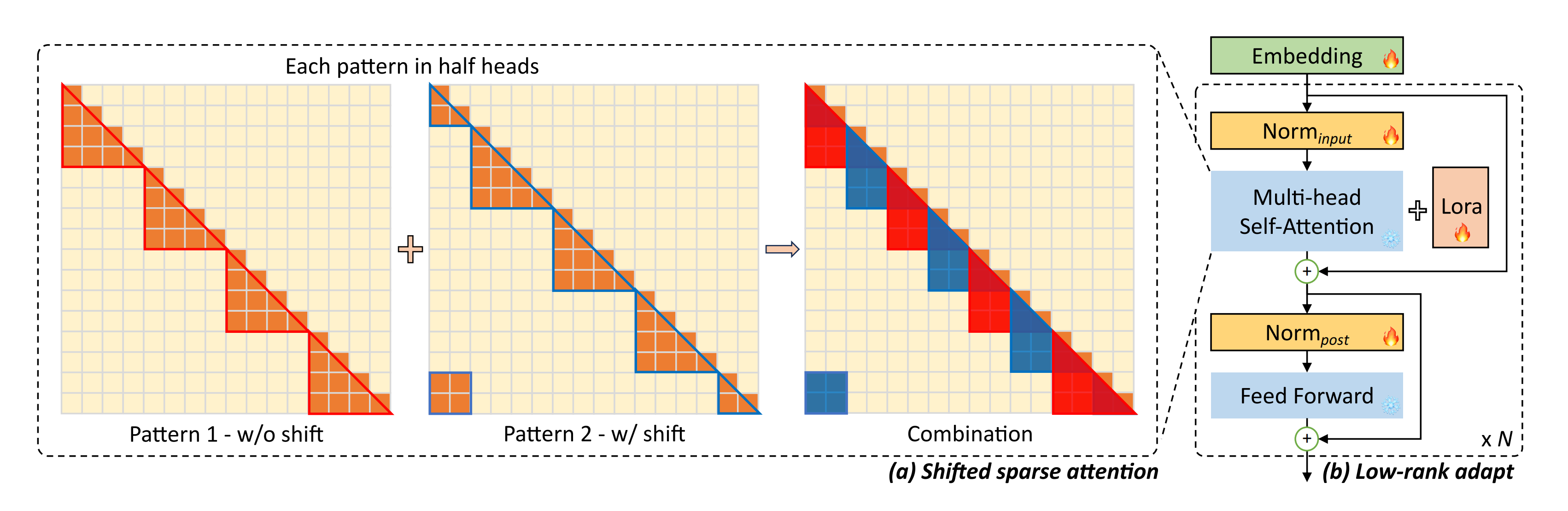
- 将上下文长度分成几个组,并在每个组中单独计算注意力。在半注意力头中,将token按半组大小进行移位,这保证了相邻组之间的信息流动(In half attention heads, we shift the tokens by half group size, which ensures the information flow between neighboring groups)
- 例如,使用组大小为2048的S2-Attn来近似总共8192个上下文长度训练,这与Swin Transformer具有高度的相似(详见此文《AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/Swin transformer》的第五部分)
上面的描述还是不够形象具体,那到底怎么理解这个S2-Attn呢?如下图所示(值得一提的是,这个图是论文v2版的,和论文v1版稍有细微差别,当然 不影响本质)

- 首先,它将沿头部维度的特征分成两大块(即it splits features along the head dimension into two chunks,比如8行4列,8行相当于8个token,4列可以认为是有4个头,然后竖着一切为二)
相当于[L, H, D], L=token num=8, H=head num=4, D=dimension of expression=1(可暂且认为是1了,毕竟一个方块,算是长度为1的一个向量)
执行完操作之后是:[L, H, D] -> [L, H/2, D] and [L, H/2, D],即被竖着切成了左右两个part - 其次,其中一个块中的标记被移动组大小的一半(tokens in one of the chunks are shifted by half of the group size)
如上图step 2的shift所示,shift thepart by half group,相当于
- 第三,将token分组并重塑为批量维度,注意力只在每个组内计算,信息通过移位在不同组之间流动。虽然移位可能会引入潜在的信息泄漏,但这可以通过对注意力掩码进行微调来避免
Third, we split tokens into groups and reshape them into batch dimensions. Attention only computes in each group in ours while the information flows between groups via shifting. Potential information leakage might be introduced by shifting, while this is easy to prevent via a small modification on the attention mask.
相当于把两个part连起来后,然后横着切三刀切成了4个group,每个group有8个小方块
第一个group相当于包含:第一part的前两行,和第二part中更新之后的前两行
然后计算该group内的注意力,类似于做了“cross-over”,正因为只是计算group内部的几个tokens之间的attention,所以称之为short attention
为方便大家更快的理解,特再补充三点
- 在我司的大模型线上营中,有一同学疑问:这里为啥不把所有的头都转动一下,再计算attention?
对于这个问题,我们先来对比下以下三种情况
第一种情况,标准注意力,如下图左侧所示
不移动任何头的话,每个token与所有近处、远处的token都做注意力计算
第二种情况,如下图中侧所示
如果移动所有的头,每个token基本都是与相邻的token在组内做注意力计算
第三种情况,即s2 attn,如下图右侧所示
如果只移动一半的头,每个token除了相邻的token,还能够与稍远点的token也在组内做注意力计算故,s2 attn的本质是从以下两个极端情况取个平衡
1 1 1 1 8 8 8 8 1 1 8 8 2 2 2 2 1 1 1 1 2 2 1 1 3 3 3 3 4 4 4 4 2 2 2 2 3 3 2 2 5 5 5 5 3 3 3 3 4 4 3 3 6 6 6 6 7 7 7 7 4 4 4 4 5 5 4 4 8 8 8 8 5 5 5 5 6 6 5 5 6 6 6 6 7 7 6 6 7 7 7 7 8 8 7 7
对于每个token而言,其近处的token、远处的token都关注,所以计算量大,相当于每个token都在一个大范围内计算注意力
每个token只关注相邻的token,这个的弊病是有时稍远点的token也是有不小关联的
i 前一半(表示) i 后一半(表示) i 前一半 online 后一半:line am 前一半 am 后一半 am 前一半 i 后一半 learning 前一半 learning 后一半 learning 前一半 am 后一半 Machine 前一半 Machine 后一半 Machine 前一半 learning 后一半 Learning 前一半 Learning 后一半 Learning 前一半 Machine 后一半 by 前一半 by 后一半 by 前一半 Learning 后一半 julyedu 前一半 julyedu 后一半 julyedu 前一半 by 后一半 online 前一半 online 后一半 online 前一半:on julyedu 后一半 - 针对上面那个S2-Attn示意图
该图的左边部分 上文已经解释的很清楚了,那右侧的两个图呢?
咋一看,比较抽象,其实仔细琢磨之后,右侧的两个图描述的注意力范围,pattern2相对于pattern1的注意力窗口是“移位”了的具体到某个token来观察会清楚一点
pattern1中q1的注意力范围是[k1],pattern2中q8的注意力范围变成了仅[k8];
pattern1中q2的注意力范围是[k1,k2],pattern2中q1的注意力范围是[k8,k1];
pattern1中q3的注意力范围是仅[k3],pattern2中q2的注意力范围变成了仅[k2];
pattern1中q4的注意力范围是[k3,k4],pattern2中q3的注意力范围变成了[k2,k3];
pattern1中q5的注意力范围是仅[k5],pattern2中q4的注意力范围变成了仅[k4];
pattern1中q6的注意力范围是[k5,k6],pattern2中q5的注意力范围变成了[k4,k5];
pattern1中q7的注意力范围是仅[k7],pattern2中q6的注意力范围变成了仅[k6];
pattern1中q8的注意力范围是[k7,k8],pattern2中q7的注意力范围变成了[k6,k7];
相当于,两个pattern从最开始的token注意力范围就是错位的,所以后续token注意力范围就一直是错开的,这样错开的形式使得两个pattern聚合起来就可以让组外信息有机会产生交互
可能还是会有读者疑问:上面这一段描述每个字都认得,但就是没明白和上面的图是如何一一对应的,其实很简单,你看上图经过step 3之后,左侧的两列是pattern1,右侧的两列是pattern2,不论是哪个pattern,其中的每个数字都代表对应的某个q,对应的q都只能看到它上面的部分
举个例子,比如对于4个组中的第二个组(相当于4个框中的第2个框),pattern1中的q3往上只能看到pattern1中q3的前半段自己q3,pattern2中的q3则可以往上看到q2的后半段和q3的后半段——[k2,k3],注意这个「往上」的方向:↑,你可能就瞬间领悟了..
1.2.2 S2-Attn的伪代码表示
如下图所示

- 第一步,B=batch size, N=sequence length, 3=q,k,v,H=head num,D=每个head的表示维度
例如:qkv=[1, 4, 3, 4, 1]
即batch size=1,一共一个序列;4=4个tokens,3=q,k,v,4=head num,1=dim of a headtoken1-head1 token1-head2 token1-head3 token1-head4 token1-head1 token1-head2 token4-head3 token4-head4 token2-head1 token2-head2 token2-head3 token2-head4 token2-head1 token2-head2 token1-head3 token1-head4 token3-head1 token3-head2 token3-head3 token3-head4 token3-head1 token3-head2 token2-head3 token2-head4 token4-head1 token4-head2 token4-head3 token4-head4 token4-head1 token4-head2 token3-head3 token3-head4 - qkv.chunk(2, 3),得到的是一个tuple,包括两个张量,[1, 4, 3, 2, 1]左边的part,以及[1, 4, 3, 2, 1]是右边的part
qkv.chunk(2, 3)[0],即左边的包括两个heads的part
qkv.chunk(2,3)[1], 即右边的包括两个heads的part,这里是对其shift 1个token了 - 接下来,按照group分别计算group内的tokens的注意力
- 最后,复原
1.2.3 LongAlpaca-13B
在llama 13B上应用longlora技术,便是LongAlpaca-13B
1.3 LongLora的源码剖析
LongLoRA源码的地址为:https://github.com/dvlab-research/LongLoRA
// 待更
第二部分 LongQLora:QLoRA to Attention层且训练时S2推理时全局
2.1 大模型的上下文扩展史
2.1.1 外推/内插PI/LongLLaMA/LongLoRA
众所周知,LLaMA2的上下文长度只有4096,为了增加LLaMA2的上下文长度,最直接的方法是像MPT-7B-8K一样(其并额外训练了500B个token,总共产生了1.5T个token规模的文本和代码,这需要大量的训练资源和数据),用更长的文本进一步预训练LLaMA2。然而,这种方法需要大量的GPU训练,收敛速度较慢
为了更好的扩展其上下文长度,各研究者尝试了各种方法
- 首先是直接外推,然LLaMA系列模型的位置编码为RoPE,其直接外推的效果较弱
且虽然Meta推出了LLaMA 2 Long,但其模型一直没对外发布,只是发了论文 (关于RoPE和LLaMA 2 Long的详解,详见此文《一文通透位置编码:从标准位置编码、旋转位置编码RoPE到ALiBi、LLaMA 2 Long》) - 再之后,Meta提出了位置插值PI「详见此文《大模型上下文扩展之YaRN解析:从直接外推ALiBi、位置插值、NTK-aware插值、YaRN》的2.3节位置内插:基于Positional Interpolation扩大模型的上下文窗口」
它使用32个A100 GPU将LLaMA的上下文长度从2048扩展到8192,它只对LLaMA进行了1000步的微调,并取得了良好的性能 - 另外,Focused Transformer(FOT)在128个TPU上训练了256k上下文长度的LongLLaMA(其GitHub地址为:long_llama)
FOT是一种即插即用的扩展方法,该模型可以很容易地外推到更长的序列。例如,在8k上下文长度上训练的模型可以很容易地外推到256k - 最后,LongLoRA提出了Shifted Sparse Attention(注意,在longqlora的论文中,作者把S2-attention表述为shift short attention,严格意义上来说不是最准确的),将位置插值和LoRA相结合,实现了一种更高效的方法。它通过8个A100 gpu将LLaMA2 7B的上下文长度从4096扩展到了100k
顺带推荐一篇关于「大模型上下文长度扩展」的综述文献
2.1.2 LongQLoRA因何而来:结合位置插值、S2-Attn和QLoRA
然而,位置插值和FOT都需要大量的计算资源,分别需要32个A100 gpu和128个TPU。虽然LongLoRA可以节省大量的培训资源,但它仍然花费8个A100 GPU
能否在能扩展到对应长度的前提下,所耗费的GPU 少一些呢?从而降低普通科研人员在机器上面的负担
好在QLoRA是一个很好的选择(关于什么是QLoRA,详见此文《LLM高效参数微调方法:从Prefix Tuning、Prompt Tuning、P-Tuning V1/V2到LoRA、QLoRA(含对模型量化的解释)》的第五部分),QLoRA冻结预训练的模型,只对LoRA适配器进行微调(QLoRA freezes the pretrained model and only finetunes the LoRA adapters)
具体而言,QLoRA将预训练的模型权重量化到4位,以减少模型的内存占用,然后添加可学习的Low-rank adapter weights,该方法可用于在单个48GB GPU上对LLaMA 65B进行微调(当然 也看数据本身的序列长度,如果是我司超长的paper-review数据集则也不一定够了)
QLoRA的主要贡献包括:4位NormalFloat、双量化和分页优化器
- 其中4位NormalFloa是理论上最优的4位量化数据类型,优于FP4和Int4
- 与之前的模型量化方法相比,双量化可以节省更多的GPU内存。平均每个参数可以节省0.37 bits,对于LLaMA 65B,它可以节省大约3GB的GPU内存
- 分页优化器使用NVIDIA统一内存管理,以避免在处理长序列的mini-batch时出现梯度检查点内存峰值(Paged Optimizers uses NVIDIA unified memory to avoid gradient checkpointing memory spikes when processing long sequences of mini-batches)
最终,使用单个32GB V100 GPU,LongQLoRA可以在1000次微调步骤内将LLaMA2 7B和13B的上下文长度从4096扩展到8192,甚至扩展到12K(With a single 32GB V100 GPU, LongQLoRA can
extend the context length of LLaMA2 7B and 13B from 4096 to 8192 and even to 12k with in 1000 finetuning steps),或将Vicuna13B的上下文长度从4096扩展到8192
2.2 LongQLoRA与LongLoRA的异同
LongQLoRA由来自中山大学的Jianxin Yang于23年11月,通过此篇论文《LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models》提出(这是作者对改论文的解读:LongQLoRA:单卡高效扩展LLaMA2-13B的上下文长度)
其结合了位置插值、QLoRA和LongLoRA的Shift Short Attention的优点(LongQLoRA combines the advantages of Position Interpolation[Chen et al., 2023a], QLoRA[Dettmers et al., 2023] and Shifted Sparse Attention of LongLoRA[Chen et al., 2023b),这是其GitHub:github.com/yangjianxin1/LongQLoRA,具体而言
- 首先,使用位置插值将LLaMA2的上下文长度从4096扩展到目标大小
- 为了节省更多的GPU内存,使用QLoRA将基本模型的权重量化到4位
- 为了进一步节省GPU内存,还使用Shift Short Attention来微调组大小为目标上下文长度的1/4
use Shift Short Attention in fine tuning with group size 1/4 of the target context length
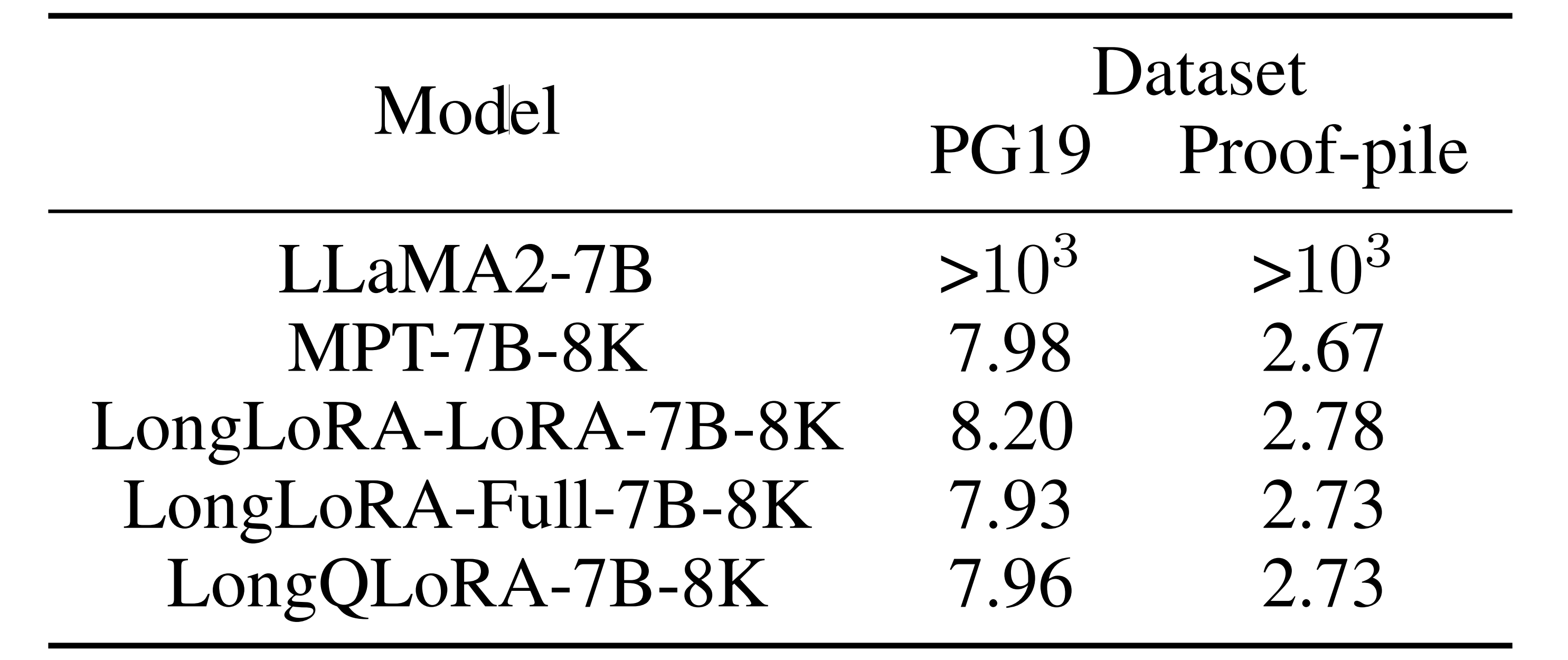
在专门针对评估上下文长度为8192的PG19验证和Proof-pile测试数据集上,相关模型的困惑度如下
其中,所有模型在推理中都被量化为4位
- ‘LongLoRA-Full’和‘LongLoRA-LoRA’分别指的是由LongLoRA发布的LLaMA2-7B模型进行完全微调和LoRA微调得到的
- LLaMA2-7B在预定义的上下文长度之外表现非常差
- LongQLoRA的性能优于LongLoRA-LoRA,并接近LongLoRA-Full和MPT-7B-8K
2.2.1 可训练层(仅Attention层)和LoRA Rank的设置(64)
作者发现在LongQLoRA中即使不放开Norm层和Embedding层来进行训练,也可以通过设置更大的LoRA Rank来实现更好的微调效果(Different from LongLoRA, LongQLoRA can achieve better performance even without training word embeddings and normalization layers[Ba et al., 2016]. This is due to the fact that we add more LoRA adapters and use larger LoRA rank.比如64)
如下图所示,当LoRA rank设置为64时,LongQLoRA的性能优于LongLoRA-LoRA、MPT-7B-8K,接近LongLoRA-Full

以下是训练时的一些具体设置
- 在以下这些层添加LoRA adapters,包括q_proj、k_proj、v_proj、up_proj、down_proj、gate_proj和o_proj (LoRA rank is set as 64 and add LoRA adapters to all layers, including q_proj, k_proj, v_proj, up_proj, down_proj, gate_proj and o_proj)
7B和13B模型的可训练参数数量分别约为150万个和250万个 - 使用分页优化器(page optimizer)
- 7B和13B模型的学习率分别设置为2e-4和1e-4
- 使用恒定学习率并进行warmup,warmup步长为20
- 将每个设备的批处理大小设置为1,梯度累积步骤设置为16,这意味着只有一个GPU的全局批处理大小为16
- 在微调期间使用Deepspeed Zero2策略
- 对LLaMA2-7B进行1000步微调,对Vicuna-13B进行1700步微调
2.2.2 推理所用注意力机制的设置:标准全局注意力
研究团队发现
在LongQLoRA中,即使模型是在Shift Short Attention下训练的,但在推理时使用标准全局注意力(standard global attention)可以获得更好的推理性能(在相应测试数据集上困惑度更低)
这一特性具备不小的意义:由于现有的大部分推理优化策略均是基于标准全局注意力的(例如Flash Attention、vLLM等),因此即使训练时用S2 attention,但推理时仍可以使用标准全局注意力,从而直接兼容现有的大部分推理策略
如下图所示,在PG19验证数据集上进行了perplexity评估后,可知与shift short attention相比,standard global attention在推理中取得了更好的性能

下述表格则总结了LongQLoRA与LongLoRA的异同
| Standard | LongLoRA | LongQLoRA | |
| 位置编码扩展 | -/Position Interpolation/... | Position Interpolation | Position Interpolation |
| 训练所用注意力机制 | Standard Global Attention | Shifted Sparse Attention | Shift Short Attention |
| 训练方式 | Full/LoRA/QLoRA | Full/LoRA | QLoRA |
| LoRA可训练层 (通常情况) | Attention层 | 改造了LoRA:Attention层、Norm层、Embedding层 | 原生LoRA + 量化:Attention层 |
| LoRA Rank | 8/16/32/... | 8/16/... | 16/32/64/... |
| 推理所用注意力机制 | Standard Global Attention | Standard Global Attention | Standard Global Attention |
2.3 如何基于LongQLoRA微调开源模型
在单个 32GB V100 GPU 上,LongQLoRA 可以将 LLaMA2 7B 和 13B 的上下文长度从 4096 扩展到 8192,甚至扩展到 12k,那具体怎么基于LongQLoRA微调某个开源模型呢
2.3.1 训练
训练配置保存在train_args目录下,部分参数如下:
- sft:如果设置为True则执行sft任务,否则执行预训练任务
- model_max_length:目标上下文长度
- max_seq_length:训练时的最大序列长度,应小于或等于model_max_length
- logging_steps:每n步记录训练损失
- save_steps:每n步保存模型
- lora_rank:训练中的LoRA rank
扩展预训练模型 LLaMA2-7B 的上下文长度:
deepspeed train.py --train_args_file ./train_args/llama2-7b-pretrain.yaml延长聊天模型 Vicuna-13B 的上下文长度:
deepspeed train.py --train_args_file ./train_args/vicuna-13b-sft.yaml2.3.2 推理
- 将 lora 权重合并到基础模型中:
cd script python merge_lora.py - 使用预训练模型进行推理:
cd script/inference python inference.py - 与聊天模型聊天:
cd script/inference python chat.py
第四部分 LongQLoRA的源码剖析
由于我司通过高质量的paper-review数据集微调而得到的论文审稿GPT中用到了LongQLoRA(详见此文的《七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2最终反超GPT4》的5.1节),而为给同样在做大模型应用落地的同仁以更多启发,故本部分再对LongQLoRA的源码做下仔细剖析
4.1 train.py
4.1.1 main:5个步骤之分别调用setup_everything、init_components、train等
1 首先,它调用setup_everything()函数来进行一些配置和检查。这个函数会解析命令行参数,读取训练参数配置,创建输出目录,设置随机种子,并返回解析得到的参数
# 进行一些配置和检查
args, training_args = setup_everything()总的来说,setup_everything函数的主要任务是解析命令行参数,读取和保存训练参数,以及设置训练环境
- 首先,它创建了一个 `argparse.ArgumentParser` 对象,用于处理命令行参数
它添加了两个参数:`--train_args_file` 和 `--local_rank`,并为它们设置了默认值然后,它调用 `parse_args` 方法来解析命令行参数def setup_everything(): parser = argparse.ArgumentParser() parser.add_argument("--train_args_file", type=str, default='./train_args/llama2-7b-pretrain.yaml', help="") parser.add_argument("--local_rank", type=int, default=0, help="")args = parser.parse_args() train_args_file = args.train_args_file- 接下来,它创建了一个 `HfArgumentParser` 对象,用于解析训练参数配置文件。这个文件的路径是从命令行参数 `--train_args_file` 中获取的
解析后的参数被存储在 `args` 和 `training_args` 两个变量中# 读取训练的参数配置 parser = HfArgumentParser((LongQLoRAArguments, TrainingArguments))# 解析得到自定义参数,以及自带参数 args, training_args = parser.parse_yaml_file(yaml_file=train_args_file)- 然后,它检查 `training_args.output_dir` 指定的目录是否存在,如果不存在,就创建这个目录。然后,它将日志文件添加到这个目录,并记录训练参数
# 创建输出目录 if not os.path.exists(training_args.output_dir): os.makedirs(training_args.output_dir) logger.add(join(training_args.output_dir, 'train.log')) logger.info("train_args:{}".format(training_args))- 接下来,它打开训练参数配置文件,并使用 `yaml.safe_load` 方法将其内容加载到 `train_args` 变量中
然后,它将这些参数保存到输出目录的 `train_args.yaml` 文件中# 加载训练配置文件 with open(train_args_file, "r") as f: train_args = yaml.safe_load(f)# 保存训练参数到输出目录 with open(join(training_args.output_dir, 'train_args.yaml'), "w") as f: yaml.dump(train_args, f)- 最后,它设置了随机种子,并将 `args.train_embedding` 的值赋给 `training_args.train_embedding`
函数最后返回 `args` 和 `training_args` 两个变量# 设置随机种子 set_seed(training_args.seed) training_args.train_embedding = args.train_embedding return args, training_args
2 然后,它调用init_components()函数来加载各种组件,包括模型、分词器、数据集和训练器。这个函数会根据参数配置来加载模型和分词器,插入适配器,初始化损失函数,加载训练集和验证集,并初始化训练器
# 加载各种组件
trainer = init_components(args, training_args)init_components:包含load_model_and_tokenizer、insert_adapter等
- 首先,函数通过`load_model_and_tokenizer`函数加载模型和分词器。这个函数会根据提供的参数和训练参数,加载预训练模型和对应的分词器
def init_components(args, training_args): """ 初始化各个组件 """ logger.info('Initializing components...') # 务必设为False,否则多卡训练会报错 training_args.ddp_find_unused_parameters = False # 加载model和tokenizer model, tokenizer = load_model_and_tokenizer(args, training_args)- 然后,函数通过`insert_adapter`函数在模型中插入适配器。适配器是一种可以插入到预训练模型中的模块,用于微调模型以适应特定任务
# 插入adapter model = insert_adapter(args, model)- 接着,函数初始化了一个名为 `CausalLMLoss` 的损失函数。这是一种用于因果语言模型的损失函数,它会忽略索引为-100的标签
# 初始化损失函数 loss_func = CausalLMLoss(ignore_index=-100)- 然后,函数根据参数args.sft`的值,选择加载 `VicunaSFTDataset` (详见下文4.4.2 dataset.py:包含VicunaSFTDataset、EvalDataset等的分析 )
或 `PretrainDataset` 作为训练集,并初始化相应的数据整理器`data_collator且注意,其参数args.train_file在train_args/llama2-7b-pretrain.yaml中被定义(说白了,train_file就是你的训练数据集或微调数据集)# 加载训练集和验证集 if args.sft: train_dataset = VicunaSFTDataset(args.train_file, tokenizer, args.max_seq_length) data_collator = SFTCollator(tokenizer, args.max_seq_length, -100) else: train_dataset = PretrainDataset(args.train_file, tokenizer, args.max_seq_length) data_collator = PretrainCollator(tokenizer, args.max_seq_length, -100)
- 最后,函数初始化了一个名为 `LoRATrainer` 的训练器,并将之前加载和初始化的模型、分词器、训练集、数据整理器和损失函数作为参数传入
# 初始化Trainer trainer = LoRATrainer( model=model, args=training_args, train_dataset=train_dataset, tokenizer=tokenizer, data_collator=data_collator, compute_loss=loss_func ) return trainer
3 接下来,它开始训练过程,通过调用训练器的train()方法来进行训练,并将训练结果保存在 train_result中
# 开始训练
logger.info("*** starting training ***")
train_result = trainer.train()4 然后,它从`train_result`中获取训练指标,并使用训练器的 `log_metrics()` 和 `save_metrics()` 方法来记录和保存训练指标
# 保存训练指标
metrics = train_result.metrics
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)5 最后,它调用训练器的 `save_state()` 方法来保存训练器的状态
trainer.save_state()总之,main方法描述了一个典型的训练过程,包括配置、初始化、训练、记录指标和保存状态等步骤
4.1.2 load_model_and_tokenizer:调用replace_llama_attn(args.use_flash_attn),且实现了PI
- 首先,这个函数有调用到replace_llama_attn(args.use_flash_attn)
而这个replace_llama_attn便是longqlora或者说longlora针对llama原注意力的关键修改,下文的此节「4.3 attention之llama_attn_replace_sft.py:replace_llama_attn」会细致分析下def load_model_and_tokenizer(args, training_args): config = AutoConfig.from_pretrained(args.model_name_or_path, trust_remote_code=True) config.use_cache = False model_type = config.model_type assert model_type == 'llama', "Only support llama and gpt-neox for now" replace_llama_attn(args.use_flash_attn) - 此外,这个函数还直接把PI干脆利落的实现了(至于什么是PI,如上文说过的,请参见此文《大模型上下文扩展之YaRN解析:从直接外推ALiBi、位置插值PI、NTK-aware插值、YaRN》的第2.3节)
# 修改RoPE的position最大长度 orig_ctx_len = getattr(config, "max_position_embeddings", None) if orig_ctx_len and args.model_max_length > orig_ctx_len: scaling_factor = float(math.ceil(args.model_max_length / orig_ctx_len)) config.rope_scaling = {"type": "linear", "factor": scaling_factor} logger.info(f'Change model_max_length from {orig_ctx_len} to {args.model_max_length}') - 之后,是其他的一些实现
# 设置device_map,以适配多卡训练 local_rank = int(os.environ.get('LOCAL_RANK', '0')) device_map = {'': local_rank} # 加载模型 logger.info(f'Loading model from: {args.model_name_or_path}') model = AutoModelForCausalLM.from_pretrained( args.model_name_or_path, config=config, device_map=device_map, load_in_4bit=True, torch_dtype=torch.float16, trust_remote_code=True, quantization_config=BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", llm_int8_threshold=6.0, llm_int8_has_fp16_weight=False, ), ) # 加载tokenizer tokenizer = AutoTokenizer.from_pretrained( args.model_name_or_path, model_max_length=args.model_max_length, padding_side="right", # use_fast=True, use_fast=False if config.model_type == 'llama' else True ) assert tokenizer.eos_token_id is not None assert tokenizer.bos_token_id is not None # 部分tokenizer的pad_token_id为None tokenizer.pad_token_id = tokenizer.eos_token_id if tokenizer.pad_token_id is None else tokenizer.pad_token_id # casts all the non int8 modules to full precision (fp32) for stability model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=training_args.gradient_checkpointing) print(f'memory footprint of model: {model.get_memory_footprint() / (1024 * 1024 * 1024)} GB') return model, tokenizer
4.1.2 insert_adapter
def insert_adapter(args, model):
# 找到所有需要插入adapter的位置
if args.target_modules is not None:
target_modules = args.target_modules.split(',')
else:
target_modules = find_all_linear_names(model)
# 初始化lora配置
config = LoraConfig(
r=args.lora_rank,
lora_alpha=args.lora_alpha,
target_modules=target_modules,
lora_dropout=args.lora_dropout,
bias="none",
task_type="CAUSAL_LM",
modules_to_save=None
# modules_to_save=["embed_tokens", "lm_head"] if args.train_embedding else None
)
model = get_peft_model(model, config)
model.print_trainable_parameters()
model.config.torch_dtype = torch.float32
# 根据配置,决定word embedding和norm是否参与训练
for n, p in model.named_parameters():
# 训练word embedding
if args.train_embedding and ("embed_tokens" in n or "lm_head" in n):
p.requires_grad = True
# 训练norm
if args.train_norm and "norm" in n:
p.requires_grad = True
# 查看模型种各种类型的参数的情况
verify_model_dtype(model)
return model// 待更
4.2 train_args
4.2.1 train_args/vicuna-13b-sft.yaml
output_dir: ./output/LongQLoRA-Vicuna-13b-8k
model_name_or_path: lmsys/vicuna-13b-v1.5
train_file: ./data/pretrain/sft_dummy_data.jsonl
deepspeed: ./train_args/deepspeed/deepspeed_config_s2.json
sft: true
num_train_epochs: 1
per_device_train_batch_size: 1
gradient_accumulation_steps: 16
max_seq_length: 8192
model_max_length: 8192
learning_rate: 0.0001
logging_steps: 50
save_steps: 100
save_total_limit: 3
lr_scheduler_type: constant_with_warmup
warmup_steps: 20
lora_rank: 64
lora_alpha: 16
lora_dropout: 0.05
gradient_checkpointing: true
disable_tqdm: false
optim: paged_adamw_32bit
seed: 42
fp16: true
report_to: tensorboard
dataloader_num_workers: 0
save_strategy: steps
weight_decay: 0
max_grad_norm: 0.3
remove_unused_columns: false4.2.2 deepspeed/deepspeed_config_s2
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu"
},
"contiguous_gradients": true,
"overlap_comm": true
},
"fp16": {
"enabled": "auto"
},
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto"
}// 待更
4.3 attention之llama_attn_replace_sft.py:replace_llama_attn
本代码文件下的这个函数replace_llama_attn类似main函数一样,依次调用
- _prepare_decoder_attention_mask_inference
- forward_flashattn_inference
涉及到apply_rotary_pos_emb_inference的调用 - _prepare_decoder_attention_mask
- forward_flashattn_full
- forward_flashattn
- forward_noflashattn
具体而言, `replace_llama_attn` 函数替换 Llama 模型中的注意力机制。函数接收三个参数:`use_flash_attn`、`use_full` 和 `inference`
- 如果 `use_flash_attn` 参数为真,函数首先获取当前 CUDA 设备的主要和次要版本号。如果主要版本号小于 8,函数会发出一个警告,因为 Flash 注意力机制只在 A100 或 H100 GPU 上支持,且仅在训练过程中支持头维度大于 64 的反向传播
- 然后,如果 `inference` 参数为真,函数会将 Llama 模型的 `_prepare_decoder_attention_mask` 方法替换为`_prepare_decoder_attention_mask_inference` 方法
将 `LlamaAttention` 的 `forward` 方法替换为 `forward_flashattn_inference` 方法
否则,函数会将 `_prepare_decoder_attention_mask` 方法替换为 `_prepare_decoder_attention_mask` 方法,将 `LlamaAttention` 的 `forward` 方法替换为 `forward_flashattn_full` 方法(如果 `use_full` 参数为真)或 `forward_flashattn` 方法 - 如果 `use_flash_attn` 参数为假,函数会将 `LlamaAttention` 的 `forward` 方法替换为 `forward_noflashattn` 方法
这个函数的主要作用是根据参数的设置,动态地替换 Llama 模型中的注意力机制,以适应不同的计算环境和需求
def replace_llama_attn(use_flash_attn=True, use_full=False, inference=False):
if use_flash_attn:
cuda_major, cuda_minor = torch.cuda.get_device_capability()
if cuda_major < 8:
warnings.warn(
"Flash attention is only supported on A100 or H100 GPU during training due to head dim > 64 backward."
"ref: https://github.com/HazyResearch/flash-attention/issues/190#issuecomment-1523359593"
)
if inference:
transformers.models.llama.modeling_llama.LlamaModel._prepare_decoder_attention_mask = _prepare_decoder_attention_mask_inference
transformers.models.llama.modeling_llama.LlamaAttention.forward = forward_flashattn_inference
else:
transformers.models.llama.modeling_llama.LlamaModel._prepare_decoder_attention_mask = (
_prepare_decoder_attention_mask
)
transformers.models.llama.modeling_llama.LlamaAttention.forward = forward_flashattn_full if use_full else forward_flashattn
else:
transformers.models.llama.modeling_llama.LlamaAttention.forward = forward_noflashattn4.3.1 forward_flashattn
这段代码定义了一个名为 `forward_flashattn` 的函数,它是一个用于训练的注意力机制函数。这个函数接收一系列参数,包括隐藏状态、注意力掩码、位置ID、过去的键值对、是否输出注意力、是否使用缓存和填充掩码
- 首先,函数检查是否处于训练模式,如果不是,将抛出一个错误
然后,如果 `output_attentions` 参数为真,函数会发出一个警告,因为对于修补过的 `LlamaAttention`,不支持输出注意力def forward_flashattn( self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None, position_ids: Optional[torch.Tensor] = None, past_key_value: Optional[Tuple[torch.Tensor]] = None, output_attentions: bool = False, use_cache: bool = False, padding_mask: Optional[torch.LongTensor] = None, ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]: """Input shape: Batch x Time x Channel attention_mask: [bsz, q_len] """ if not self.training: raise ValueError("This function is only for training. For inference, please use forward_flashattn_inference.") if output_attentions: warnings.warn( "Output attentions is not supported for patched `LlamaAttention`, returning `None` instead." ) - 接下来,函数获取隐藏状态的大小,并将其分解为批次大小、查询长度和其他维度。然后,函数使用 `q_proj`、`k_proj` 和 `v_proj` 对隐藏状态进行投影,得到查询状态、键状态和值状态。这些状态都被重塑并转置,以便在后续的计算中使用
bsz, q_len, _ = hidden_states.size() query_states = ( self.q_proj(hidden_states) .view(bsz, q_len, self.num_heads, self.head_dim) .transpose(1, 2) ) key_states = ( self.k_proj(hidden_states) .view(bsz, q_len, self.num_key_value_heads, self.head_dim) .transpose(1, 2) ) value_states = ( self.v_proj(hidden_states) .view(bsz, q_len, self.num_key_value_heads, self.head_dim) .transpose(1, 2) ) # [bsz, q_len, nh, hd] # [bsz, nh, q_len, hd] - 如果提供了过去的键值对,函数会更新键值序列的长度,并将过去的键值对与当前的键状态和值状态进行连接。如果 `use_cache` 参数为真,函数会更新过去的键值对
kv_seq_len = key_states.shape[-2] if past_key_value is not None: kv_seq_len += past_key_value[0].shape[-2] cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len) query_states, key_states = apply_rotary_pos_emb( query_states, key_states, cos, sin, position_ids ) # Past Key value support if past_key_value is not None: # reuse k, v, self_attention key_states = torch.cat([past_key_value[0], key_states], dim=2) value_states = torch.cat([past_key_value[1], value_states], dim=2) past_key_value = (key_states, value_states) if use_cache else None - 然后,函数将键状态和值状态重复,以匹配头的数量。接着,函数将查询状态、键状态和值状态堆叠起来,并将结果转置,以满足 Flash Attention 的格式要求
# repeat k/v heads if n_kv_heads < n_heads key_states = repeat_kv(key_states, self.num_key_value_groups) value_states = repeat_kv(value_states, self.num_key_value_groups) # Flash attention codes from # https://github.com/HazyResearch/flash-attention/blob/main/flash_attn/flash_attention.py # transform the data into the format required by flash attention qkv = torch.stack( [query_states, key_states, value_states], dim=2 ) # [bsz, nh, 3, q_len, hd] qkv = qkv.transpose(1, 3) # [bsz, q_len, 3, nh, hd] - 函数接着处理注意力掩码,将其重复并用于创建键填充掩码。然后,函数根据查询长度计算组大小,并将 `qkv` 重塑和排列,以满足 Flash Attention 的输入要求
# We have disabled _prepare_decoder_attention_mask in LlamaModel # the attention_mask should be the same as the key_padding_mask key_padding_mask = attention_mask.repeat(2, 1) nheads = qkv.shape[-2] # shift if q_len % 4096 == 0: group_size = int(q_len * group_size_ratio) else: group_size = sft_group_size qkv = qkv.reshape(bsz, q_len, 3, 2, self.num_heads // 2, self.head_dim).permute(0, 3, 1, 2, 4, 5).reshape(bsz * 2, q_len, 3, self.num_heads // 2, self.head_dim) - 接下来,函数使用 `unpad_input` 函数对输入进行处理,并计算出一系列的 `cu_q_lens`。然后,函数使用 `flash_attn_varlen_qkvpacked_func` 函数计算出未填充的输出
x = rearrange(qkv, "b s three h d -> b s (three h d)") x_unpad, indices, cu_q_lens, max_s = unpad_input(x, key_padding_mask) cu_q_len_tmp = torch.arange(0, max_s, group_size, device=key_padding_mask.device, dtype=cu_q_lens.dtype) cu_q_len_tmp2 = cu_q_len_tmp + group_size // 2 cu_q_len_tmp2[cu_q_len_tmp2 >= max_s] = torch.iinfo(cu_q_len_tmp2.dtype).min cu_q_len_tmp = torch.stack([cu_q_len_tmp, cu_q_len_tmp2]).repeat(bsz, 1) + cu_q_lens[:-1].unsqueeze(-1) cu_q_lens = torch.cat([cu_q_len_tmp, cu_q_lens[1:].unsqueeze(-1)], dim=-1).view(-1) cu_q_lens = cu_q_lens[cu_q_lens >= 0] x_unpad = rearrange( x_unpad, "nnz (three h d) -> nnz three h d", three=3, h=nheads // 2 ) output_unpad = flash_attn_varlen_qkvpacked_func( x_unpad, cu_q_lens, group_size, 0.0, softmax_scale=None, causal=True )
4.3.2 forward_flashattn_full
// 待更
4.3.3 forward_noflashattn
这个函数的输入参数包括:
def forward_noflashattn(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: bool = False,
use_cache: bool = False,
padding_mask: Optional[torch.LongTensor] = None,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
bsz, q_len, _ = hidden_states.size()- `hidden_states`:输入的隐藏状态,这是一个三维的张量。
- `attention_mask`:注意力掩码,用于指定哪些位置应该被忽略
- `position_ids`:位置编码,用于指定每个输入的位置信息
- `past_key_value`:过去的键值对,用于注意力机制的计算
- `output_attentions`:一个布尔值,用于指定是否输出注意力权重
- `use_cache`:一个布尔值,用于指定是否使用缓存
- `padding_mask`:填充掩码,用于指定哪些位置是填充的
函数的主要步骤包括:
- 计算组大小和组数量
group_size = int(q_len * group_size_ratio) if q_len % group_size > 0: raise ValueError("q_len %d should be divisible by group size %d."%(q_len, group_size)) num_group = q_len // group_size - 根据配置,对隐藏状态进行线性变换,得到查询、键和值的状态
if self.config.pretraining_tp > 1: key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.config.pretraining_tp query_slices = self.q_proj.weight.split( (self.num_heads * self.head_dim) // self.config.pretraining_tp, dim=0 ) - 对查询、键和值的状态进行重塑和转置
key_slices = self.k_proj.weight.split(key_value_slicing, dim=0) value_slices = self.v_proj.weight.split(key_value_slicing, dim=0) query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.config.pretraining_tp)] query_states = torch.cat(query_states, dim=-1) key_states = [F.linear(hidden_states, key_slices[i]) for i in range(self.config.pretraining_tp)] key_states = torch.cat(key_states, dim=-1) value_states = [F.linear(hidden_states, value_slices[i]) for i in range(self.config.pretraining_tp)] value_states = torch.cat(value_states, dim=-1) else: query_states = self.q_proj(hidden_states) key_states = self.k_proj(hidden_states) value_states = self.v_proj(hidden_states) query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2) key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2) value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2) - 应用旋转位置嵌入
kv_seq_len = key_states.shape[-2] if past_key_value is not None: kv_seq_len += past_key_value[0].shape[-2] cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len) query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids) - 如果存在过去的键值对,将它们与当前的键和值状态进行连接
if past_key_value is not None: # reuse k, v, self_attention key_states = torch.cat([past_key_value[0], key_states], dim=2) value_states = torch.cat([past_key_value[1], value_states], dim=2) past_key_value = (key_states, value_states) if use_cache else None - 重复键值对的头部
# repeat k/v heads if n_kv_heads < n_heads key_states = repeat_kv(key_states, self.num_key_value_groups) value_states = repeat_kv(value_states, self.num_key_value_groups) - 对查询、键和值的状态进行移位操作
# shift def shift(qkv, bsz, q_len, group_size, num_heads, head_dim): qkv[:, num_heads // 2:] = qkv[:, num_heads // 2:].roll(-group_size // 2, dims=2) qkv = qkv.transpose(1, 2).reshape(bsz * (q_len // group_size), group_size, num_heads, head_dim).transpose(1, 2) return qkv query_states = shift(query_states, bsz, q_len, group_size, self.num_heads, self.head_dim) key_states = shift(key_states, bsz, q_len, group_size, self.num_heads, self.head_dim) value_states = shift(value_states, bsz, q_len, group_size, self.num_heads, self.head_dim) - 计算注意力权重
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim) if attn_weights.size() != (bsz * num_group, self.num_heads, group_size, group_size): raise ValueError( f"Attention weights should be of size {(bsz * num_group, self.num_heads, group_size, group_size)}, but is" f" {attn_weights.size()}" ) attention_mask = attention_mask[:, :, :group_size, :group_size].repeat(num_group, 1, 1, 1) if attention_mask is not None: if attention_mask.size() != (bsz * num_group, 1, group_size, group_size): raise ValueError( f"Attention mask should be of size {(bsz * num_group, 1, group_size, group_size)}, but is {attention_mask.size()}" ) attn_weights = attn_weights + attention_mask - 对注意力权重进行softmax操作,并与值状态进行矩阵乘法,得到注意力输出
# upcast attention to fp32 attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype) attn_output = torch.matmul(attn_weights, value_states) if attn_output.size() != (bsz * num_group, self.num_heads, group_size, self.head_dim): raise ValueError( f"`attn_output` should be of size {(bsz * num_group, self.num_heads, group_size, self.head_dim)}, but is" f" {attn_output.size()}" ) attn_output = attn_output.transpose(1, 2).contiguous() - 对注意力输出进行重塑和移位操作
attn_output = attn_output.reshape(bsz, q_len, self.num_heads, self.head_dim) # shift back attn_output[:, :, self.num_heads//2:] = attn_output[:, :, self.num_heads//2:].roll(group_size//2, dims=1) attn_output = attn_output.reshape(bsz, q_len, self.hidden_size) - 对注意力输出进行线性变换
if self.config.pretraining_tp > 1: attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2) o_proj_slices = self.o_proj.weight.split(self.hidden_size // self.config.pretraining_tp, dim=1) attn_output = sum([F.linear(attn_output[i], o_proj_slices[i]) for i in range(self.config.pretraining_tp)]) else: attn_output = self.o_proj(attn_output) - 返回注意力输出、注意力权重和键值对
if not output_attentions: attn_weights = None return attn_output, attn_weights, past_key_value
其中,`shift`函数是用于实现移位操作的,它首先将输入的后半部分进行循环移位,然后将输入进行重塑和转置,具体见上文讲过的
4.3.4 _prepare_decoder_attention_mask
4.3.5 apply_rotary_pos_emb_inference
4.3.6 forward_flashattn_inference:涉及到apply_rotary_pos_emb_inference的调用
4.3.7 _prepare_decoder_attention_mask_inference
// 待更
4.4 component
4.4.1 component/argument.py
from dataclasses import dataclass, field
from typing import Optional
@dataclass
class LongQLoRAArguments:
"""
一些自定义参数
"""
max_seq_length: int = field(metadata={"help": "输入最大长度"})
model_max_length: int = field(metadata={"help": "模型位置编码扩展为该长度"})
train_file: str = field(metadata={"help": "训练数据路径"})
model_name_or_path: str = field(metadata={"help": "预训练权重路径"})
sft: bool = field(metadata={"help": "True为sft,False则进行自回归训练"})
target_modules: str = field(default=None, metadata={
"help": "QLoRA插入adapter的位置,以英文逗号分隔。如果为None,则在自动搜索所有linear,并插入adapter"
})
eval_file: str = field(default=None, metadata={"help": "评测集路径"})
use_flash_attn: bool = field(default=False, metadata={"help": "训练时是否使用flash attention"})
train_embedding: bool = field(default=False, metadata={"help": "词表权重是否参与训练"})
train_norm: bool = field(default=False, metadata={"help": "norm权重是否参与训练"})
lora_rank: Optional[int] = field(default=64, metadata={"help": "lora rank"})
lora_alpha: Optional[int] = field(default=16, metadata={"help": "lora alpha"})
lora_dropout: Optional[float] = field(default=0.05, metadata={"help": "lora dropout"})4.4.2 dataset.py:包含VicunaSFTDataset、EvalDataset等
4.4.2.1 PretrainDataset
4.4.2.2 EvalDataset,用于评测ppl
4.4.2.3 VicunaSFTDataset
这段代码定义了一个名为[`VicunaSFTDataset`]的类,它继承自`Dataset`类。这个类主要用于处理和格式化数据,以便于模型训练
- 在[`__init__`]方法中,首先初始化了一些参数,包括tokenizer(用于文本的编码和解码),最大序列长度,以及忽略的索引值
然后,它打开并读取了一个文件,将文件的每一行作为一个数据项存储在[`data_list`]中def __init__(self, file, tokenizer, max_seq_length, ignore_index=-100): self.tokenizer = tokenizer self.ignore_index = ignore_index self.max_seq_length = max_seq_length self.pad_token_id = tokenizer.pad_token_id self.eos_token_id = tokenizer.eos_token_id logger.info('Loading data: {}'.format(file))
此外,还定义了一个输入模板,用于格式化聊天对话with open(file, 'r', encoding='utf8') as f: data_list = f.readlines() logger.info("there are {} data in dataset".format(len(data_list))) self.data_list = data_list self.input_template = "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.\nUSER: {input}\nASSISTANT: " - [`__len__`]方法返回数据集的长度,即[`data_list`]的长度
def __len__(self): return len(self.data_list) - [`__getitem__`]方法用于获取数据集中的一个元素
首先,它从[`data_list`]中获取一个数据项,并将其从JSON格式转换为Python对象
然后,它将输入和输出部分分别进行处理
对于输入部分,它使用输入模板进行格式化,并使用tokenizer将其转换为id序列def __getitem__(self, index): """ 沿袭Vicuna的的格式。 A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: xxx ASSISTANT: xxx """ data = self.data_list[index] data = json.loads(data) inputs = data['input'].strip() output = data['output'].strip()
对于输出部分,也是将其转换为id序列,并在末尾添加一个结束符的id# 输入部分 input_format = self.input_template.format(input=inputs) input_format_ids = self.tokenizer(input_format, add_special_tokens=False).input_ids
然后,它将输入和输出的id序列合并,并创建一个标签序列,该序列在输入部分的位置上填充了忽略的索引值,在输出部分的位置上则使用了输出的id序列output_ids = self.tokenizer(output, add_special_tokens=False).input_ids + [self.eos_token_id]
接着,它将输入和标签序列的长度截断到最大序列长度,并创建一个注意力掩码input_ids = input_format_ids + output_ids labels = [self.ignore_index] * len(input_format_ids) + output_ids assert len(input_ids) == len(labels)
最后,它进行了填充操作,使得输入、标签和注意力掩码的长度都等于最大序列长度,并将这些数据打包成一个字典返回# 对长度进行截断 input_ids = input_ids[:self.max_seq_length] labels = labels[:self.max_seq_length] attention_mask = [1] * len(input_ids)# padding padding_len = self.max_seq_length - len(input_ids) input_ids += [self.pad_token_id] * padding_len labels += [self.ignore_index] * padding_len attention_mask += [0] * padding_len inputs = { 'input_ids': input_ids, 'attention_mask': attention_mask, 'labels': labels } return inputs
这个类的主要作用是将原始的文本数据转换为模型可以接受的格式,包括将文本转换为id序列,添加必要的特殊符号,以及进行截断和填充等操作


















 705
705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











