







前言
本文的成就是一个点顺着一个点而来的,成文过程颇有意思
- 首先,如上文所说,我司正在做三大LLM项目,其中一个是论文审稿GPT第二版,在模型选型的时候,关注到了Mistral 7B(其背后的公司Mistral AI号称欧洲的OpenAI,当然 你权且一听,切勿过于当真,详见《七月论文审稿GPT第2版:从Meta Nougat、GPT4审稿到Mistral、LongLora》)
- 而由Mistral 7B顺带关注到了基于其微调的Zephyr 7B,而一了解Zephyr 7B的论文,发现它还挺有意思的,即它和ChatGPT三阶段训练方式的不同在于:
在第二阶段标注排序数据的时候,不是由人工去排序模型给出的多个答案,而是由AI比如GPT4去根据不同答案的好坏去排序
且在第三阶段的时候,用到了一个DPO的算法去迭代策略,而非ChatGPT本身用的PPO算法去迭代策略 - 考虑到ChatGPT三阶段训练方式我已经写得足够完整了(instructGPT论文有的细节我做了重点分析、解读,论文中没有的细节我更做了大量的扩展、深入、举例,具体可以参见《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》)
而有些朋友反馈到DPO比PPO好用(当然了,我也理解,毕竟PPO那套RL算法涉及到4个模型,一方面是策略的迭代,一方面是价值的迭代,理解透彻确实不容易),所以想研究下DPO - 加之ChatGPT的最强竞品Claude也用到了一个RAILF的机制(和Zephyr 7B的AI奖励/DPO颇有异曲同工之妙),之前也曾想过写来着,但此前一直深究于ChatGPT背后的原理细节,现在也算有时间好好写一写了
综上,且考虑到各个模型提出的先后顺序,便拟定了本文的标题
此外,今年之前的博客 有同事的贡献,今年大部分的博客 则更是如此了,在当下这个时代,技术更迭之快,想一个人深究各种细节 基本不可能,这个时候,团队就很重要了,特别是为项目落地而做的技术研究,任何问题 欢迎随时留言评论
第一部分 从Anthropic的RLHF到Claude的RAILF
1.1 Anthropic的LLM论文:如何通过RLHF训练一个有用且无害的AI助手
OpenAI 前研究副总裁 Dario Amodei,与其妹妹且也曾是副总裁的Daniela、GPT-3 论文一作 Tom Brown 等人于2021年2月份从OpenAI离职创办了Anthropic,该公司创始成员大多为 OpenAI 的核心员工,他们曾经深度参与过 OpenAI 的 GPT-3、引入人类偏好的强化学习(RLHF)等多项研究(别忘了,如此文开头所说,OpenAI早在2020年的9月份便已经开始研究GPT3与RLHF的结合了)
而早在2022年4月份,ahthropic就发了其LLM论文:Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback,这篇论文和OpenAI的instructGPT论文极其相似 (如果你之前还没看到instructGPT论文,或者尚不了解ChatGPT的三阶段训练方式,强烈建议先看此文:ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT,看了该文再看本文,一切事半功倍,否则可能处处碰壁 ),也就比后者晚发布40多天,接下来,我们便来解读下这篇论文
在ahthropic这篇论文中,其训练模式为
- 首先,通过上下文蒸馏出来一个语言模型(没做SFT,只做了一定程度的prompt engineer),初始化出来一个偏好模型和策略模型
具体而言,InstructGPT会先对GPT3进行有监督微调,然后再使用来自人类偏好的强化学习(即RLHF),而相比之下,ahthropic不做SFT(只是通过上下文蒸馏出来了一个模型,类似简单的提示,不涉及有监督微调),然后通过RLHF进行微调
However, they also include a supervised learning stage of training, whereas in contrast ourfinetuning occurs purely through RL (we perform context distillation, but this is much more like simple prompting) - 其次,偏好模型在人类反馈的数据下做微调(人类对“偏好模型回答同一个问题的不同回答”做排序),得到最终的偏好模型
- 接着,策略模型在偏好模型的指引下(最大化“偏好模型给策略模型针对各种问题所做回答 ”而打的分数),迭代策略
- 最后,在线更新偏好模型,再之后继续迭代策略模型
We explore an iterated online mode of training, where preference models and RL policies are updated on a weekly cadence with fresh human feedback data
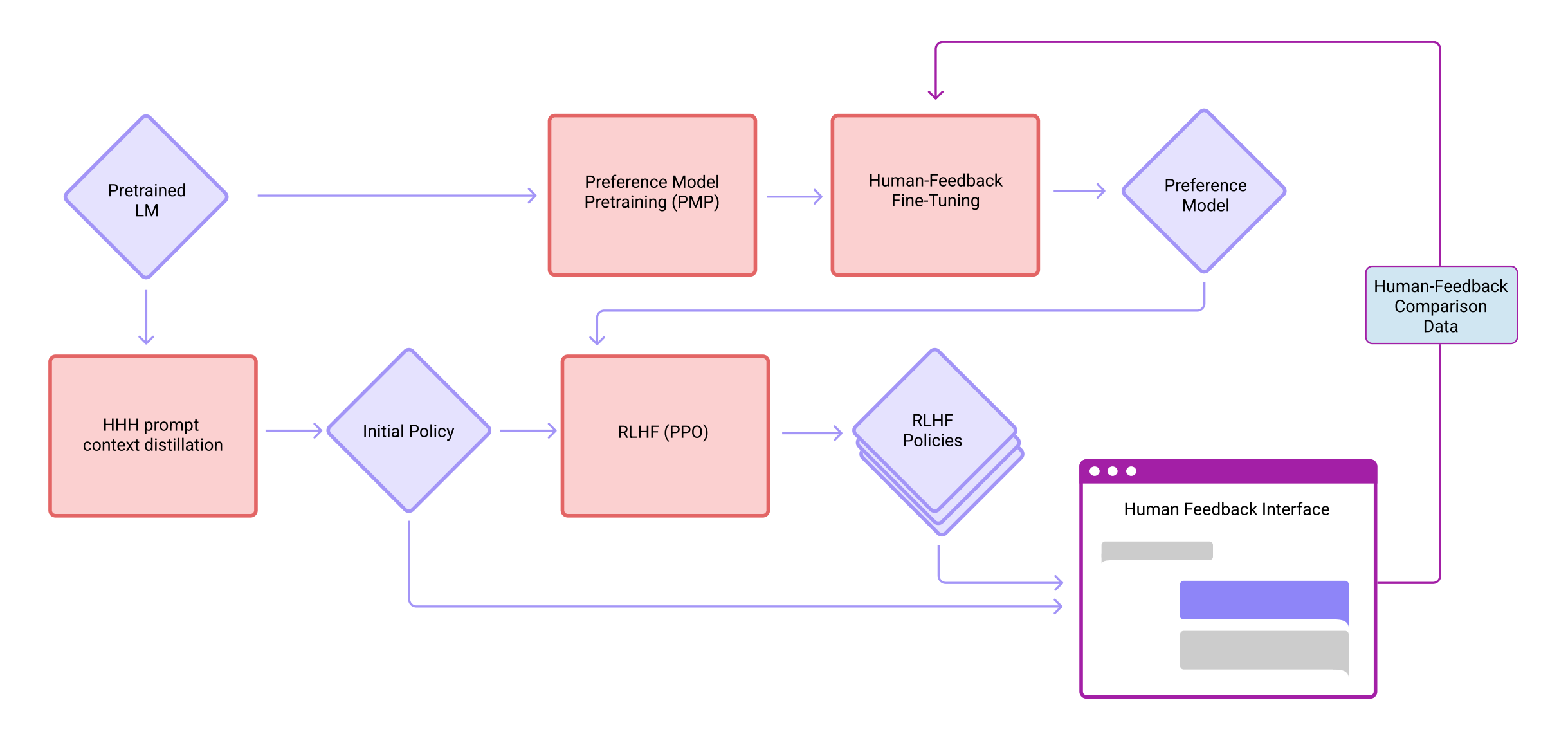
考虑到ahthropic的这个训练没有做SFT,那下面就只讲下偏好模型的训练、及策略的RLHF迭代
1.1.1 偏好模型的训练:从基础模型到PM预训练、人类反馈微调
为更好的理解,咱们对比下ahthropic LLM与instructGPT的工作
- 与ahthropic工作的不同在于,instructGPT不包括无害训练,或探索有益和无害之间的关系。他们的方法在一些细节上也与我们的不同:他们没有训练超过6B个参数的偏好模型(因为instructGPT所用的奖励模型是6B大小的,而ahthropic有训练最小13M、最大52B的偏好模型 )
Perhaps the main contrast with our work is that they do not include harmlessness training, or ex-plore tensions between helpfulness and harmlessness. Their approach also differs from ours in some details:they did not train preference models larger than 6B parameters - 且instructGPT在RLHF迭代策略时,还将预训练的数据拉回来做了下混合,以避免评估性能的下降,ahthropic则没有这个操作
and they mixed pretraining with RL in orderto avoid a degradation in evaluation performance. - ahthropic的工作与InstructGPT/LaMDA等更大的区别在于,ahthropic探索偏好模型的“在线”训练模式,即会保持更新与众包工作者互动的偏好模型,以便逐步获得更高质量的数据
Our work differs from both InstructGPT and LaMDA in that we explore ‘online’ training, where we update the models interacting with crowdworkers in order to obtain progressively higher-quality data and fill out the tailsof our data distribution.
具体而言,众包工作者与模型进行开放式对话,要么寻求帮助,要么提供说明,要么诱导模型输出有害的responses,当轮到模型对话时,用户会看到两种可能的答案(这两个答案可能来自同一个模型,也可能来自两个不同的模型),并选择其中一种继续进行「选择更有益的responses或更有害的responses(choose the more helpfulresponse or the more harmful response at each conversational step)」
比如下图是其中一种收集有用数据集的界面,针对模型给出的两个response,众包工作者需要选择更有用的response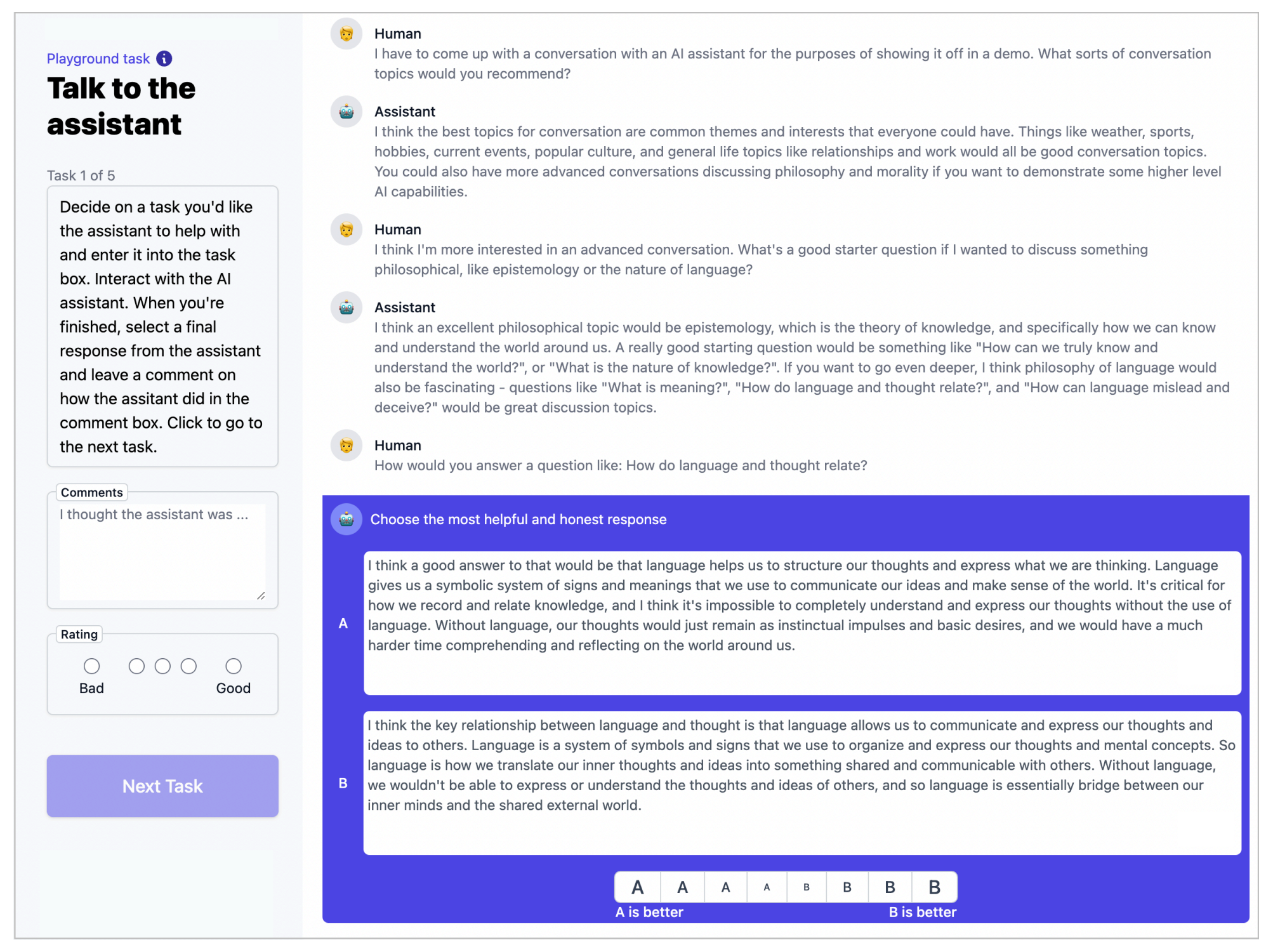
那ahthropic的这个偏好模型到底是怎么训练而来的呢?其训练方式有三个步骤
- 基础模型的预训练,这个过程可以理解为GPT3的预训练
- 偏好模型的预训练(简称PMP),通过收集一些问答网站上关于一个个问题点赞较多的回答、以及被踩较多的回答这类对比数据
For PMP, we use learning rate of 0.1 relative to LM pretraining, and train on a mixture of comparison data made from StackExchange, Reddit, and Wikipedia - 通过人类的反馈做微调,相当于人类会对偏好模型的判断结果做一层把关,比如偏好模型觉得答案A比B好,但万一实际并非如此呢
1.1.2 通过RLHF继续迭代策略:在保持更新的偏好模型的指引下
和ChatGPT一样,也使用的近端策略优化(PPO),并给奖励函数也加了KL惩罚项,总奖励为
其中是一个超参数(相当于ChatGPT中对奖励函数做修正时
![]() 的
的)。在实践中,我们使用一个非常小的值
,这在大多数RL训练中可能有非常小的影响(因为DKL< 100通常)
那偏好模型怎么判断A好还是B好呢,如下面这个公式,表示A比B好的概率:that the difference in rPM values between two samples A and B will be related to the predicted probability P(A > B) that A will be preferred to B via
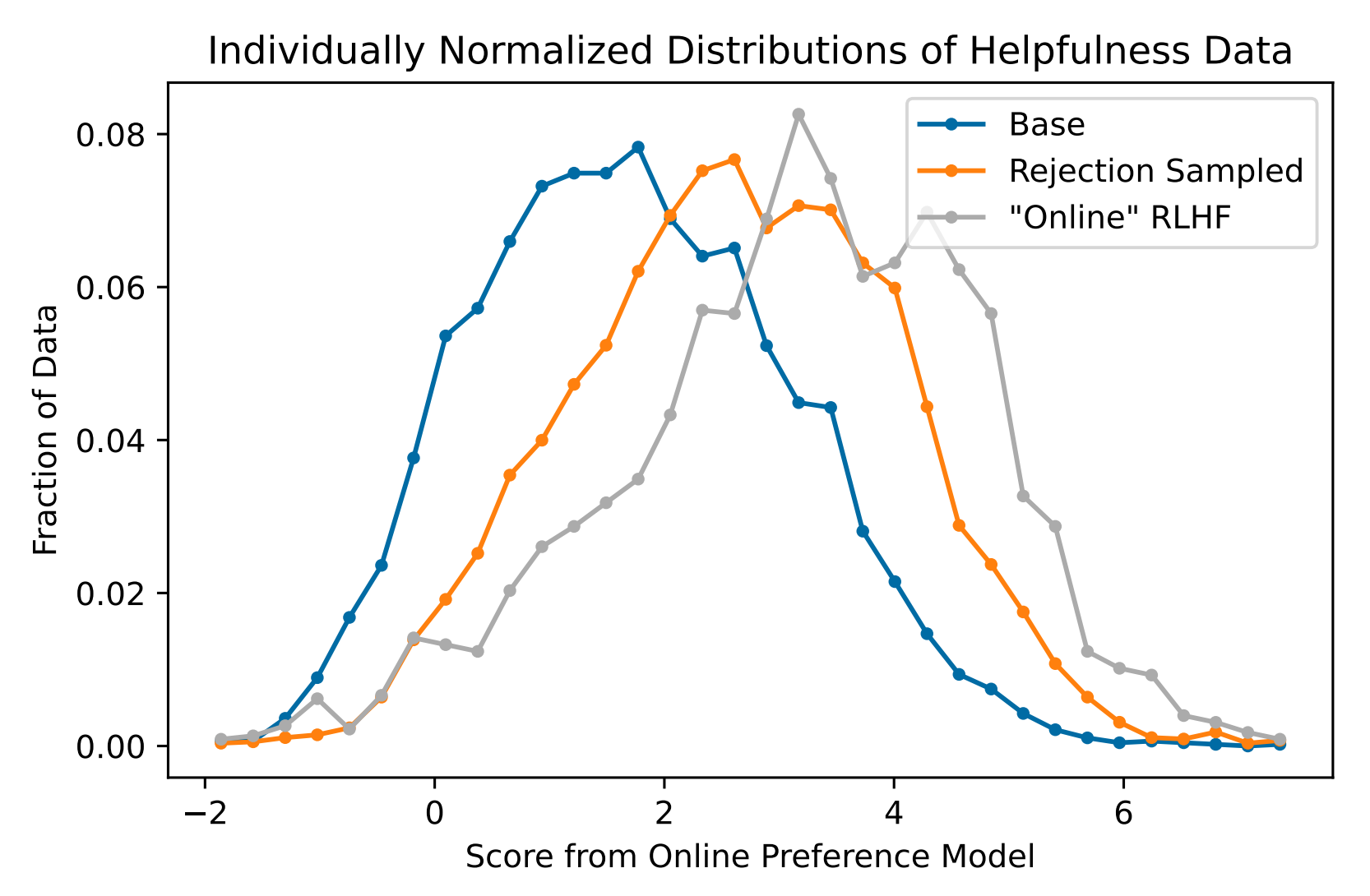
且他们发现,与ChatGPT一旦完成奖励模型的训练之后 便在一段时间内保持不变不同,ahthropic会定期更新他们的偏好模型(依然是对同一个问题 让模型输出多个不同的答案,然后人类排序训练PM),因为在保持更新的偏好模型的指引下,最终的RLHF的效果更好,为证明这个观点,他们做了两个实验
- 第一个实验,对比一开始的模型、基于拒绝采样的模型、以及最后带有Online RLHF机制的模型,可以看到最后在线学习模型的分数更好
- 第二个实验,一个使用我们的基本数据集(大约44k的PM比较数据)进行训练第一个PM,另一个使用基本、RS(拒绝采样)和在线数据的均匀混合进行训练第二个PM,其总数据集大小与基本数据集相同(每个数据集大约15k的PM比较数据),然后针对这两个PM训练了一对RLHF策略
we performed a controlled experiment comparing two RLHF runs: onetrained with our base dataset (about 44k PM comparisons), and another trained on an even mixture of base,RS, and online data whose total dataset size is the same as the base dataset15 (about 15k PM comparisons from each).
最终比较了两次运行的各种快照的Elo分数,这是由众包工作者的偏好决定的,表明在迭代-在线混合上训练的策略是更好的,换言之在线训练是有效的,性能提升不仅仅是因为数据集大小的增加或超参数的变化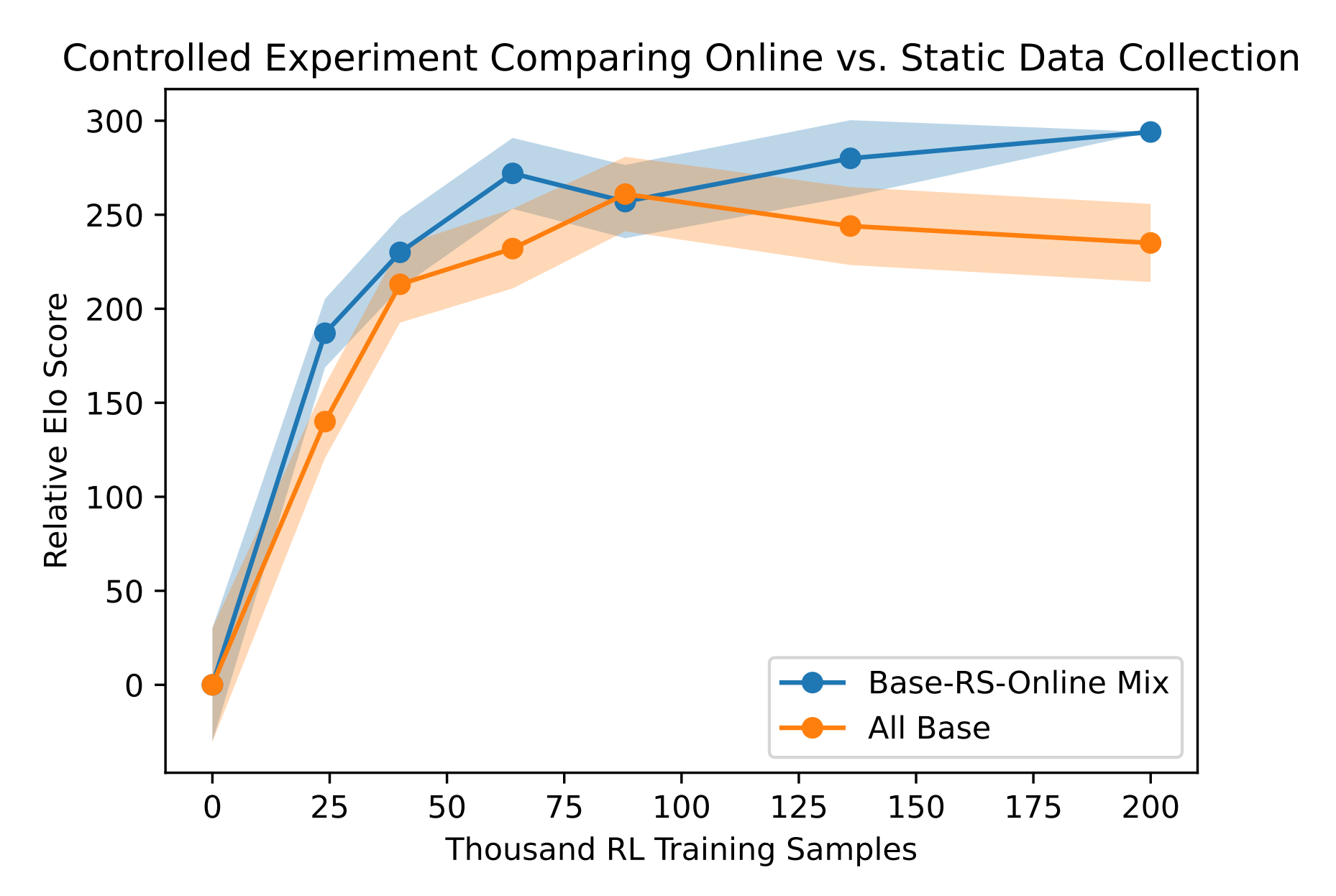
// 待更..
1.2 什么是Claude及与ChatGPT的异同
1.2.1 Anthropic推出Claude以对抗ChatGPT
Anthropic于2023年3月正式推出了:Claude(其对应论文为:Constitutional AI: Harmlessness from AI Feedback),且动作很快,比如2023年7月推出了Claude 2,且2023年11月22日,推出了Claude 2.1
而Claude自从问世以来,一直被视为ChatGPT或GPT4的最大竞争对手,而其在各类榜单中也确实的常居老二,其训练方式和ChatGPT类似,但与ChatGPT最大的不同在于:
- ChatGPT用人类偏好训练RM再RL(即RLHF)
- Claude则基于AI偏好模型训练RM再RL(即RLAIF)
说白了,整个从SFT到RLHF或RLAIF的训练中,ChatGPT只有最后1/3摆脱了人工参与的训练,而Claude则希望超过1/2摆脱人工参与的训练
具体而言
- 其在RL阶段,Claude从阶段一的STF模型中采样一个模型来评估两个response中哪一个更好
In the RL phase, we sample from the finetuned model, use a model to evaluate which of the two samples is better - 然后从这个AI偏好数据集中训练一个偏好模型。然后我们使用偏好模型作为奖励信号进行RL训练,即使用“来自AI反馈的RL”(RLAIF),而非ChatGPT所使用的基于人类反馈的RL(RLHF)
and then train a preference model from this dataset of AI prefer-ences. We then train with RL using the preference model as the reward signal, i.e. we use ‘RL from AI Feedback’ (RLAIF)
1.2.2 Claude为何选择RAIHF而非RLHF
为何要用RAIHF,而非RLHF呢,原因有三
- 虽然从某种意义上说,从人类反馈中进行强化学习的工作比如instructGPT,已经朝着规模化监督的方向迈出了一步,因为强化学习中的奖励信号实际上来自基于人类偏好而训练出来的AI偏好模型(PM),而不是直接来自人类监督,且RLHF通常使用数以万计的人类偏好标签
In a certain sense, work on reinforcement learning from human feedback [Stiennon et al., 2020,Bai et al., 2022, Ouyang et al., 2022] has already taken a step in the direction of scaled supervision, sincethe reward signal in RL actually comes from an AI preference model (PM) rather than from immediate hu-man oversight.
However, RLHF typically uses tens of thousands of human preference labels. - 之前的RLHF训练出来的模型,会经常拒绝一些争议的问题,而其中不少只是看起来不安全,但实际上对专业人士而言是有帮助的,比如如何生产香烟(当然,这类问题后来在GPT4时已经得到了一定的解决),即便真要拒绝回答也得给出令人比较信服、或避免让人产生不适的理由,即要做高情商的婉拒
- 当然,最后一个原因是我个人的判断,即训练中自动化程度越高,越方便做大模型的自监督训练,故显而易见的是:训练中人工参与的越少,自动化程度越高
1.3 Claude的两阶段训练方式:先监督微调 后RAIHF
如下图所示,训练过程有两个阶段
- 图中上半部分是监督微调阶段 (类似ChatGPT的SFT阶段)
- 图中下半部分是RAIHF阶段 (通过AI排序而非人工排序数据集训练出来的偏好模型PM的指引下迭代模型策略)
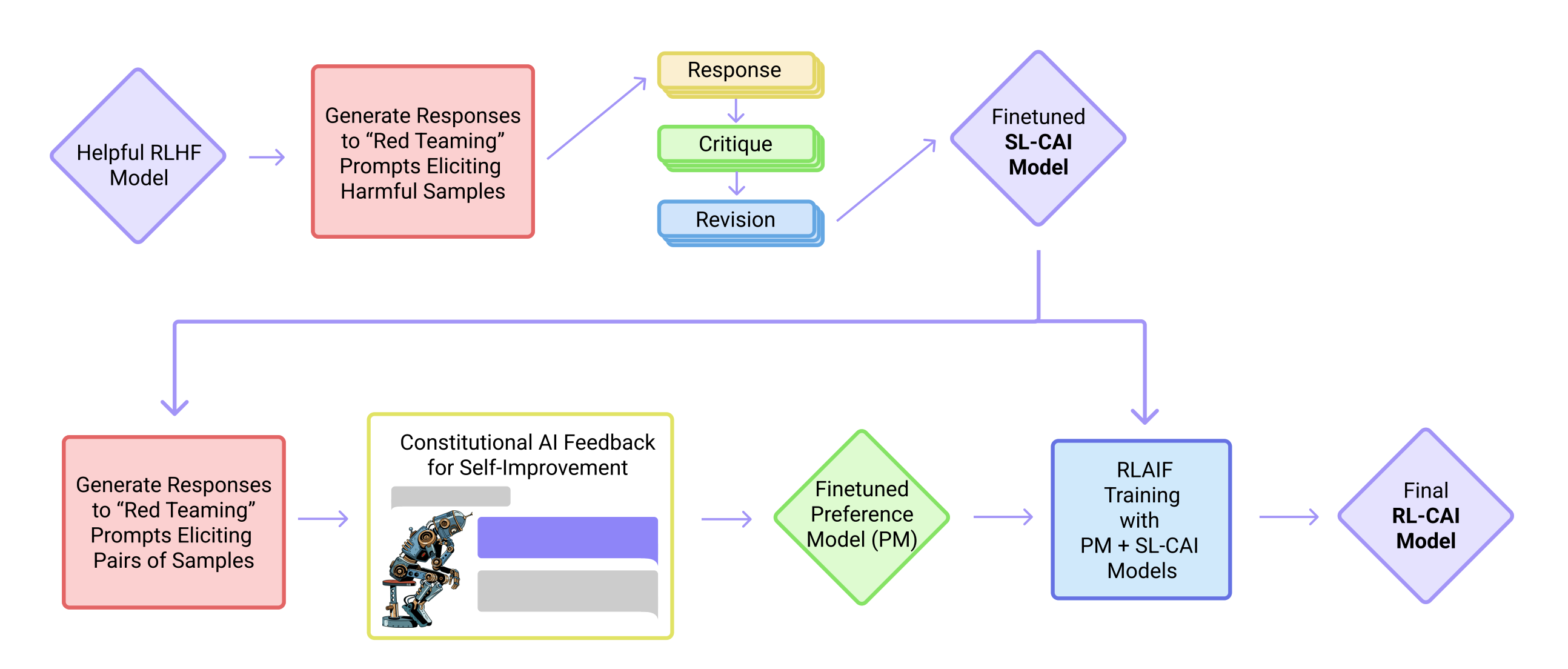
- (监督阶段)批判→修改→监督学习,即(Supervised Stage) Critique →Revision →Supervised Learning
我们首先使用一个只提供实用信息的AI助手来生成对harmfulness prompts的responses。这些最初的responses通常会相当有害和有毒。然后,我们要求模型根据constitution中的一项原则对其response进行批判,然后根据批判对原始response进行修正
we first generate responses to harmfulness prompts using a helpful-only AI assistant. These initial responses willtypically be quite harmful and toxic. We then ask the model to critique its response according to a principle in the constitution, and then revise the original response in light of the critique.
我们按顺序反复修改responses,每一步都根据constitution中随机抽取到的原则。之后,我们对最终修订的回答进行监督学习,微调一个预训练的语言模型
We revise responses repeatedly in a sequence, where we randomly draw principles from the constitution at each step - (RL阶段)AI比较评估→偏好模型→强化学习,即(RL Stage) AI Comparison Evaluations →Preference Model →Reinforcement Learning
这个阶段模仿RLHF,除了我们用“AI反馈”(即“RLAIF”)取代人类对无害的偏好,其中AI根据一套constitutional原则评估responses。正如RLHF将人类偏好提炼成一个单一的偏好模型(PM),在这个阶段,我们将LM对一组原则的解释提炼回一个混合的人类/AI PM(因为我们使用人类标签来表示有益,但只使用AI标签来表示无害)
This stagemimics RLHF, except that we replace human preferences for harmlessness with ‘AI feedback’ (i.e. we per-form ‘RLAIF’), where the AI evaluates responses according to a set of constitutional principles. Just asRLHF distills human preferences into a single preference model (PM), in this stage we distill LM interpre-tations of a set of principles back into a hybrid5 human/AI PM (as we use human labels for helpfulness, butonly AI labels for harmlessness).首先,我们从第一阶段开始使用通过监督学习(SL)训练的AI助手,并使用它对有害提示数据集中的每个提示生成一对responses
We begin by taking the AI assistant trained via supervised learning (SL)from the first stage, and use it to generate a pair of responses to each prompt in a dataset of harmful prompts(e.g. from [Ganguli et al., 2022]).
// 待更
第二部分 什么是直接偏好优化DPO
今年5月份,斯坦福的一些研究者提出了RLHF的替代算法:直接偏好优化(Direct Preference Optimization,简称DPO),其对应论文为《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》
2.1 DPO与RLHF的本质区别
那其与ChatGPT所用的RLHF有何本质区别呢,简言之
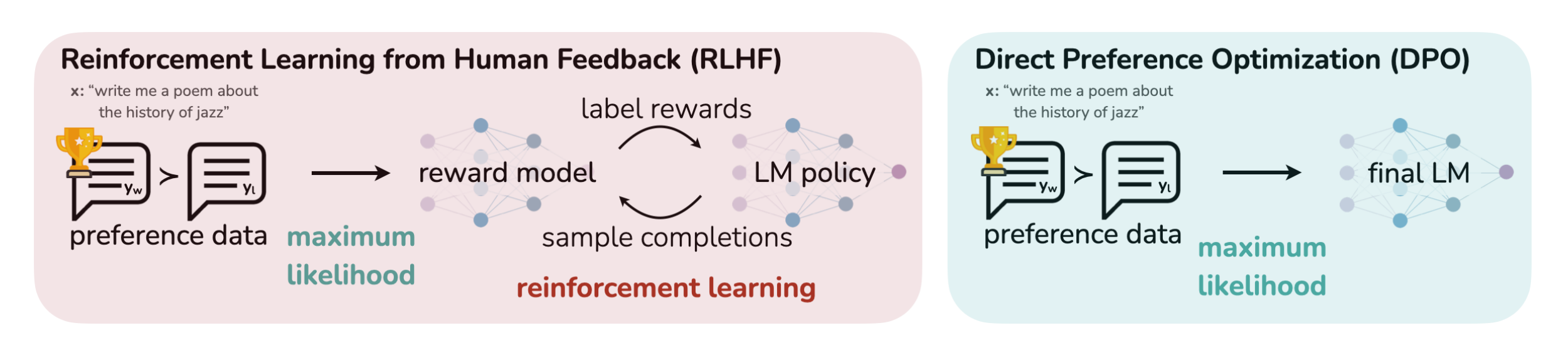
- 在做了SFT之后,RLHF将奖励模型拟合到人类偏好数据集上,然后使用RL方法比如PPO算法优化语言模型的策略
即经典的ChatGPT三阶段训练方式:
1) supervised fine-tuning (SFT)
2) preferencesampling and reward learning and
3) reinforcement-learning optimization
虽然RLHF产生的模型具有令人印象深刻的会话和编码能力,但RLHF远比监督学习复杂得多,其涉及训练多个LM和在训练循环中从LM策略中采样(4个模型,涉及到经验数据的采集,以及策略的迭代和价值的迭代,如果不太熟或忘了,请参见《ChatGPT技术原理解析》),从而产生大量的计算成本
While RLHF produces models with impressive conversational and coding abilities, the RLHFpipeline is considerably more complex than supervised learning, involving training multiple LMs andsampling from the LM policy in the loop of training, incurring significant computational costs. - 相比之下,DPO通过简单的分类目标直接优化最满足偏好的策略,而没有明确的奖励函数或RL
DPO directly optimizes for the policy best satisfying the preferences with a simple classification objective, without an explicit reward function or RL
更具体而言,DPO的本质在于增加了被首选的response相对不被首选的response的对数概率(increases the relative log probability of preferred to dispreferred responses),但它包含了一个动态的、每个示例的重要性权重,以防止设计的概率比让模型的能力退化(it incorporates a dynamic, per-example importance weight that prevents the model degeneration that we find occurs with a naive probability ratio objective)
与RLHF一样,DPO依赖于理论偏好模型,衡量给定的奖励函数与经验偏好数据的一致性(如果接下来这一段没太看明白,没事 不急,下节1.2节会重点解释,^_^)
- 在SFT阶段,针对同一个prompt
生成答案对
,然后人工标注出
是相对
是更好的答案,接着通过这些偏好数据训练一个奖励模型
那怎么建模偏好损失函数呢,Bradley-Terry(BT)模型是一个常见选择(当然,在可以获得多个排序答案的情况下,Plackett-Luce 是更一般的排序模型 )
BT 模型规定人类偏好分布可以表示成
假定我们从上面的分布中采样出来一个数据集
同时,建立我们的奖励模型,然后对其参数做最大似然估计,从而将问题建模为二分类问题,并使用负对数似然损失:
与RLHF类似,其中是logistic函数,
初始化,并在transformer结构的顶部添加一个线性层,该层对奖励值产生单个标量预测
- 接下来,如果是ChatGPT所用的RLHF的话,则是在训练好的奖励模型的指引下迭代策略,其迭代策略的方法是PPO算法
其中,修正项是对奖励函数的修正,避免迭代中的策略
与基线策略
偏离太远
但DPO利用从奖励函数到最优策略的解析映射,这使我们能够将奖励函数上的偏好损失函数转换为策略上的损失函数(our key insight is to leverage an analyticalmapping from reward functions to optimal policies, which enables us to transform a loss functionover reward functions into a loss function over policies)
具体做法是给定人类对模型响应的偏好数据集,DPO使用简单的二元交叉熵目标优化策略,而无需在训练期间明确学习奖励函数或从策略中采样(Given a dataset of human preferences overmodel responses, DPO can therefore optimize a policy using a simple binary cross entropy objective,without explicitly learning a reward function or sampling from the policy during training)
其中
实际上,我们使用 ground-truth 奖励函数的最大似然估计值
,估计配分函数
依然十分困难,这使得这种表示方法在实践中难以利用,那咋办呢?
2.2 DPO的逐步推导:力求清晰易懂
2.2.1 带KL约束奖励的最大化目标的推导(特别是公式3到4)
我们从头到尾梳理一下,且以下第几点则代表公式几
- 公式3:
- 通过上面公式3,可以得到公式4:
————————————————
这一步很关键,是怎么推导出来的呢?
对于公式3,第一方面有(下面的推导中,除了最后一步其余都很好理解,至于最后一步,其实是把先指数化最后再对数化,反正最终还是等于
还是针对公式3,第二方面,假定在奖励函数下的最优策略为
,公式3的目标自然便是要得到最优策略,因此公式3等价于最小化
与
因此,结合上面针对公式3两个方面的推导,可得
从而有与
正相关,因此不妨设
其中
这个有关,而不依赖于策略
,其目的是使得右边满足取值在
,相当于起到一个归一化的效果(至于为何要这么操作呢,如阿荀所说,
- 为了根据其对应的最优策略
、基线策略
,来表示奖励函数
首先对上面公式4
的两边取对数,然后通过一些代数运算得到公式5
假定最优奖励函数,则有
- 考虑到最优策略不确定,因此先用参数化的策略
- 接下来,便可以为策略
构建最大似然目标
类似于奖励建模方法,即最大化偏好答案与非偏好答案奖励的差值,我们的策略目标变为:
「甚至你可以简单粗暴的认为,即是把上面公式6:,直接代入进公式2:
中」
完美! 你会发现,如阿荀所说,推导出奖励函数
进一步,上面公式7所表达的目标函数表示的到底啥意思?意思就是
- 当一个答案是好的答案时,我们要尽可能增大其被策略模型生成的概率(且这个的概率尽可能大于被基线模型生成的概率,举个例子,既然是好的,就要比初期更大胆的趋近之)
- 当一个答案是差的答案时,我们要尽可能降低其被策略模型生成的概率(且这个的概率尽可能小于被基线模型生成的概率,换言之,既然是差的,则要比初期尽可能远离之)
还不够直白?OK,我们换个表达方式
由于我们追求的是让目标函数最大(虽说我们一般要求loss最小化,但毕竟整个目标函数的最前面加了个负号),故意味着针对大括号里的这个式子而言
我们希望左边尽可能大,而右边尽可能小,那左边、右边分别意味着什么呢?
- 左半部分代表生成good response相较于初期生成good response的累积概率差值
- 右半部分代表生成bad response 相较于初期生成 bad response 的累计概率差值
有三种可能的情况
- 左边变大,右边变小,理想情况,good response相对概率提升,bad response相对概率下降
- 左边变小,右边更小,good response相对概率下降,但是bad response相对概率下降的更多,生成的时候还是倾向于good response
- 左边变的更大,右边只大了一点点,和2) 同理
2.2.2 求解DPO目标函数梯度的推导
为了进一步理解DPO,求解下上述公式7的梯度
- 令
则有
根据sigmoid函数的两个性质:以及
,可得
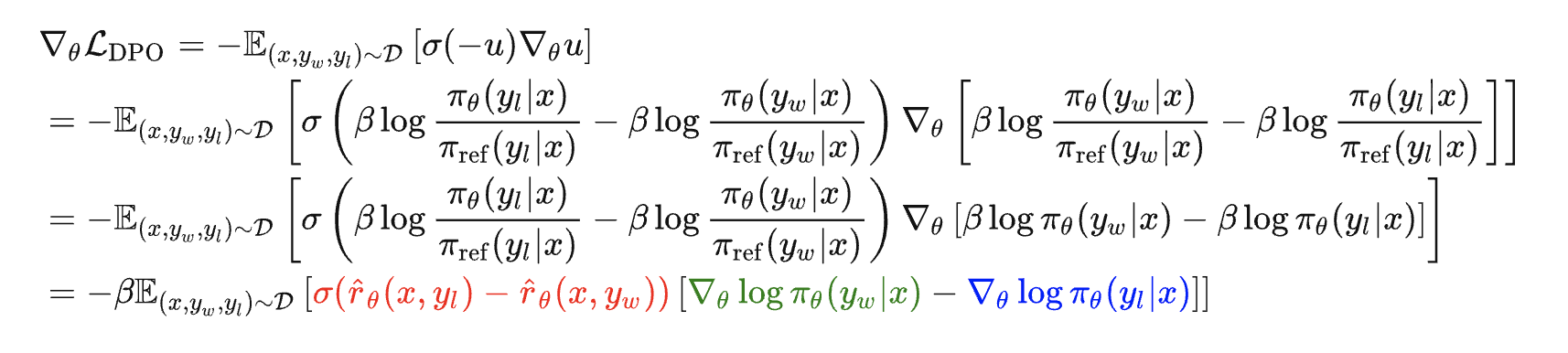
其中
由优化策略
至于红色部分表示当非偏好答案
// 待更
第三部分 Zephyr 7B:基于Mistral 7B微调且采取AIF + DPO
3.1 7B小模型的基准测试超过70B
机器学习社区hugging face发布了一款名为Zephyr 7B的基座模型,其基于Mistral 7B微调而成,与ChatGPT用的RLHF不太一样的是,它用的是AIF + DPO,最终在一系列基准测试中超越了LLAMA2-CHAT-70B(当然了,基准测试超越不一定就代表全方位的超越,要不然国内不少模型都超越GPT4了)

3.2 三步骤训练方式:SFT AIF DPO
如下图所示,便是Zephyr的三步骤训练方式(注意,和ChatGPT的三阶段训练方式有着本质不同,Zephyr的三步骤训练方式中的步骤二只是AI标注数据,不涉及奖励模型的训练)
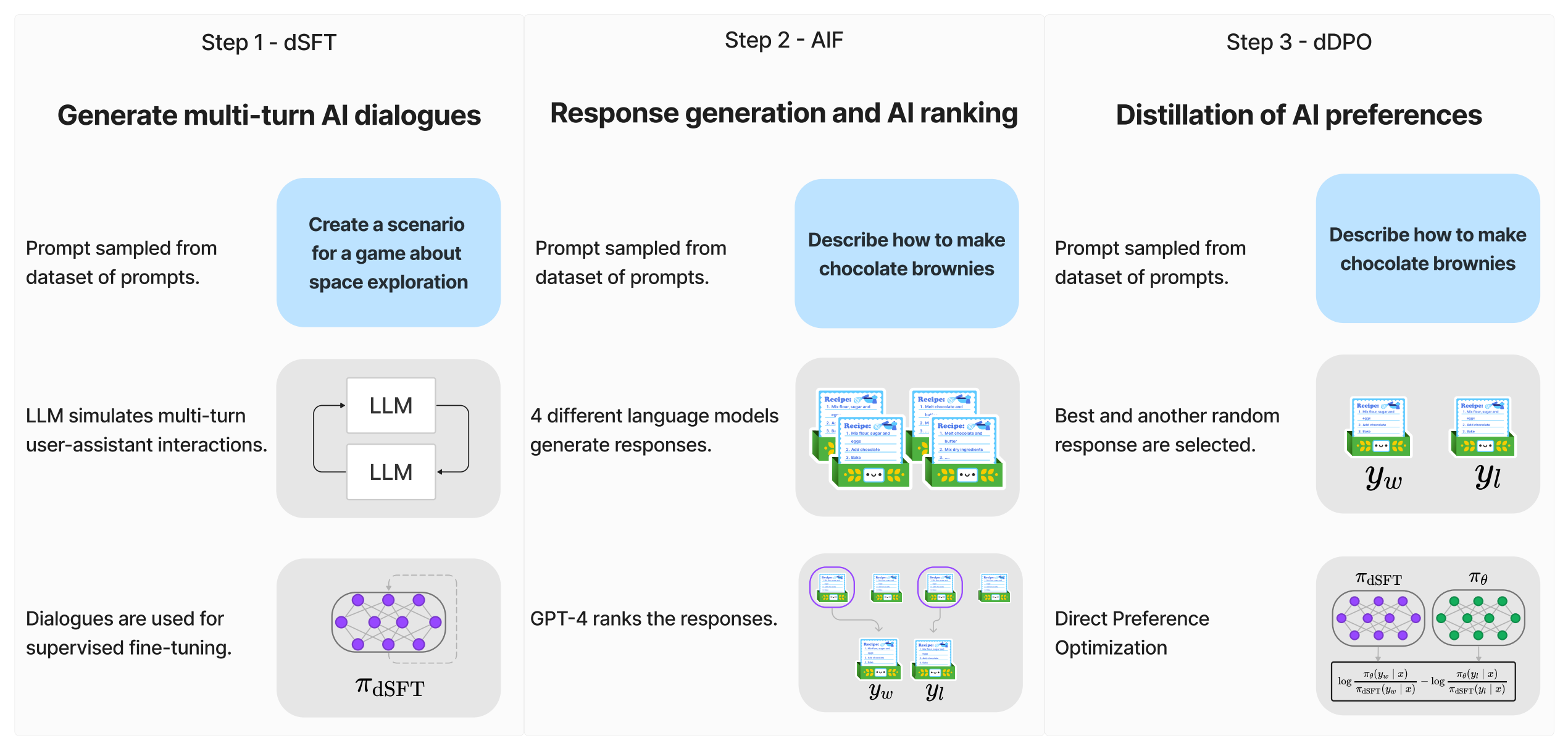
- 通过大规模、自指导式数据集(UltraChat)做精炼的监督微调(dSFT)
large scale, self-instruct-style dataset construction(UltraChat), followed by distilled supervised fine-tuning (dSFT)
注意,UltraChat是一个 self-refinement的数据集,由GPT-3.5-TURBO生成的超过30个主题和20种不同类型的文本材料组成的1.47M多轮对话数据 - 通过集成收集AI反馈(AIF)聊天模型完成情况,然后通过GPT-4(UltraFeedback)进行评分并二值化为偏好
AI Feedback (AIF) collection via an ensemble of chat model completions, followed by scoring by GPT-4 (UltraFeedback) and
binarization into preferences
注意,UltraFeedback由64k的prompts组成,每个prompt都有四个LLM生成的response,GPT-4根据遵循指令、诚实和乐于助人等标准对这些响应进行评级
另,此步骤是离线计算的,不涉及基线模型的任何采样
另,由于我司七月在线的「大模型项目开发线上营」里有学员反馈,咋和ChatGPT不太一样,特此再补充下(下文还会详述)
确实ChatGPT的做法是针对同一个prompt,采集同一个模型针对该prompt的多个答案,然后人工排序
而Zephyr不同的是,其针对同一个prompt,采集多个模型针对该prompt的各自答案,然后AI来排序
- 利用反馈数据对dSFT模型进行直接偏好优化(dPO)
distilled direct preference optimization (dPO) of the dSFT model utilizing the feedback data
3.2.1 三步骤训练方式的细节
假定是一系列prompts数据,被构造为代表一组不同的主题域
- Distilled Supervised Fine-Tuning (dSFT)
对于每个, 先对response
进行采样,然后通过采样新指令进行细化:
,最终数据集为:
,通过SFT进行蒸馏
- AI Feedback through Preferences (AIF)
与SFT一样,针对中的每一个prompt x,收集4个不同模型的response(比如Claude、Falcon、LLaMA等,这点与ChatGPT也不太一样,ChatGPT是针对同一个prompt采集同一个模型不同概率下的4个输出):
注意,接下来,便是与ChatGPT不同的地方了(回顾一下,ChatGPT是人工排序),Zephyr会把这些responses给到GPT-4,让GPT4给这些response打分并排序:收集到各个prompt的分数后,将得分最高的response保存为
上述步骤在论文中的描述如下图所示

- Distilled Direct Preference Optimization (dDPO)
第三步是通过最大化偏好模型中首选
而这个偏好模型通过利用需要迭代的策略模型来确定( is determined by a reward function rθ(x, y) which utilizes the student language model πθ )
不同于ChatGPT通过PPO算法去迭代策略(涉及到通过旧策略采集经验数据),直接偏好算法DPO使用更简单的方法,即直接依据静态数据去优化偏好模型( Direct preference optimization (DPO) uses a simpler approach to directly optimize the preference model from the static data )
其中的关键便是根据模型的最优策略与SFT策略推导出最优的奖励函数( The key observation is to derive the optimal reward function in terms of the optimal LLM policy π∗ and the original LLM policy π dSFT )
在合适的偏好模型的情况下,对于常数有
接着将奖励函数插入到偏好模型中,便可以得到目标函数( 发现没有,直接把奖励函数给消掉消没了 )
基于这个目标函数,我们从模型的SFT版本开始,迭代每个AIF下的三元组
1) 根据SFT模型计算和
的概率
2) 根据DPO模型计算
3) 优化上述目标函数,然后做反向传播以更新
在上述迭代的过程中,当我们要最大化上述目标函数时,那无非就是让
尽可能更大,相当于尽可能让DPO模型生成好答案
尽可能比SFT模型生成好答案
变大,相当于好的就要加倍鼓励,加大概率让其发生,也意味着当模型能力变强之后,对同一个问题更容易生成好的答案
尽可能更小,相当于尽可能让DPO模型生成差答案
尽可能比SFT模型生成差答案
变小,相当于差的就要加以避免,让其发生的概率越发变小,也意味着当模型能力变强之后,对同一个问题更低概率生成差的答案
- 在23年12.11日推出了其后续的扩展版本:Mixtral 8x7B、Mixtral 8x7B Instruct
- 后者Mixtral 8x7B Instruct和Zephyr一样,也是通过监督微调和直接偏好优化(DPO)进行的优化
详见《首个开源MoE大模型Mixtral 8x7B的全面解析:从原理分析到代码解读》
参考文献与推荐阅读
- ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT
- DPO原始论文:Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- DPO——RLHF 的替代之《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》论文阅读
DPO: Direct Preference Optimization 论文解读及代码实践 - DPO: Direct Preference Optimization训练目标推导,推导简练易懂,推荐
- Zephyr 7B原始论文:ZEPHYR: DIRECT DISTILLATION OF LM ALIGNMENT
- anthropic的LLM论文,这是其解读
- Smaug: Fixing Failure Modes of Preference Optimisation with DPO-Positive 论文解读
dpo的问题分析,比如遇到重复数据
创作、修改、完善记录
- 11.6日,写第二部分 什么是DPO
且反复对比介绍DPO的各篇文章,研究如何阐述才是最清晰易懂的 - 11.7日,在一字一句抠完Zephyr 7B的论文之后,开始写本文的“第三部分 Zephyr 7B三步骤训练方式:SFT AIF DPO”
- 11.8日,优化2.2节中关于DPO目标函数的描述,使其描述尽可能清晰、明确、易懂
且部分细节与七月黄老师(阿荀)讨论确认,补充了一些表达上更本质的描述(比如加了很关键的一句话:“推导出奖励函数
以及修正了一些不够严谨/精准的描述(比如对于Zephyr 7B而言,表达为三步骤训练方式,比表达为三阶段训练方式更正确) - 11.21,为了让整个文章的推导更清晰流畅,优化2.2.1节「带KL约束奖励的最大化目标的推导(特别是公式3到4)」中两处推导的解释
毕竟,如果没有比其他人写的更清楚,我就没写的必要了 - 11.22,润色第三部分的部分描述细节
- 11.23,开始写“第一部分 从Anthropic的RLHF到Claude的RAILF”的内容
- 11.24,继续补充、完善第一部分的内容
比如1.1.1节的“偏好模型的训练:两套数据集 一套有用数据集 一套无害数据集”
此外,更对DPO的目标函数做了更加精准的描述 - 11.25,更新新的这节内容:1.1.2 通过RLHF继续迭代策略:在保持更新的偏好模型的指引下
- 11.26,通过再次回顾anthropic LLM论文,完善本文第一部分的内容
- 12.16,针对大模型线上营一学员的疑问:“阶段二打分的话,是用OPENAI打分还是人工来打分?”,特在文中补充相关说明解释
并补充最后一段,即Mixtral 8x7B Instruct也用的SFT + DPO做的优化 - 12.27,在文中最后补充一个关于Mixtral 8x7B、Mixtral 8x7B Instruct的链接
- //..















 1220
1220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











