





我一直说一句话:“智能体不是写出来的,是调出来的”。如果你做过大规模分布式系统,你以为已经见过足够多的鬼;但当你开始调试一个多智能体系统,才会发现: 那些 bug 的出现方式,已经超出了你对软件工程的认知边界。为什么?因为传统系统是 确定性的,而智能体系统是 概率驱动 + 状态依赖 + 上下文敏感 + 多轮演化 的组合怪物。
今天我想把最近一年在智能体系统里的踩坑,总结成 7 个最管用的调试技巧。每一个都可以直接落地。
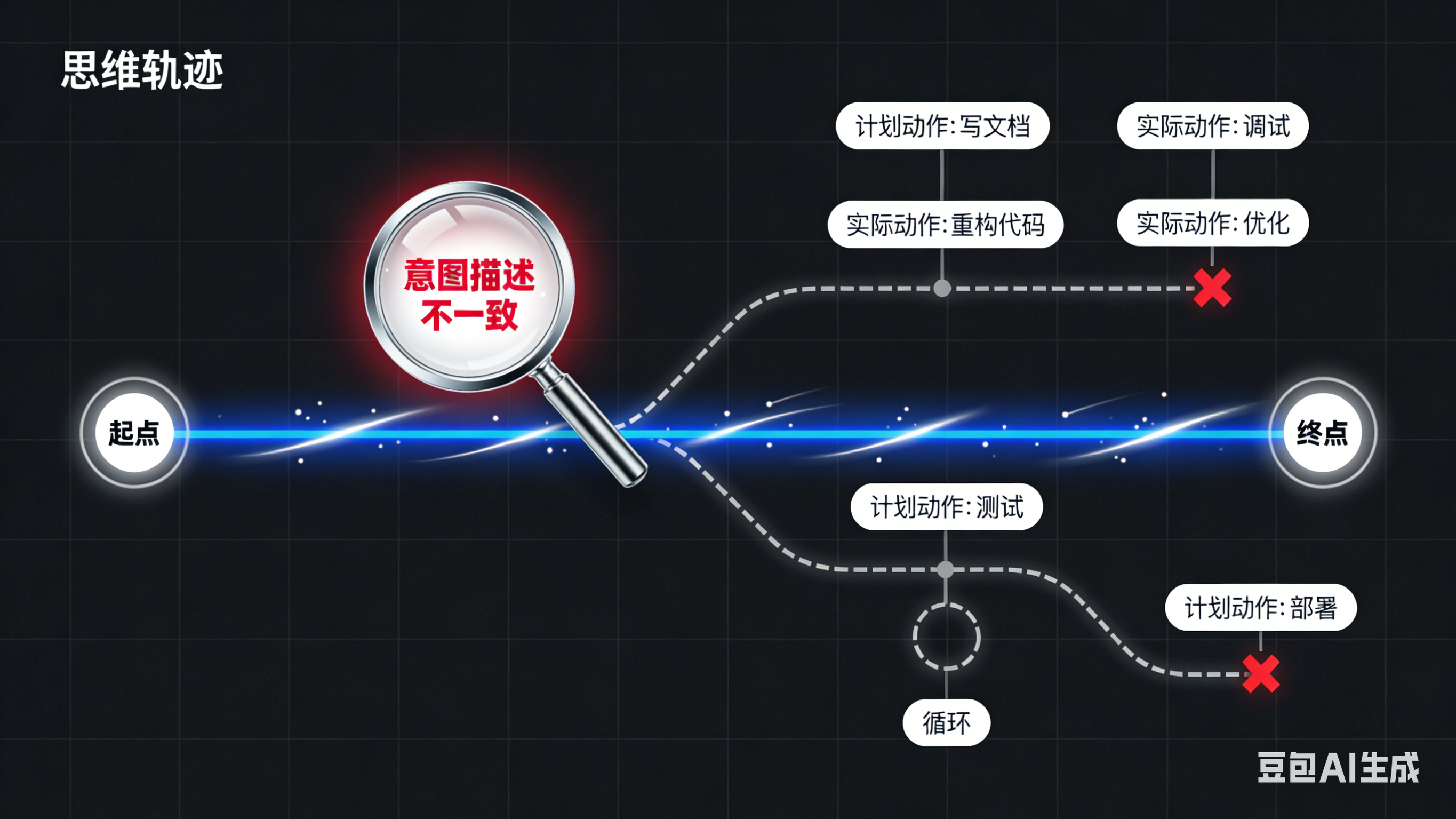
Debug 智能体,不要看结果,要看“意图轨迹”
传统系统你看日志;智能体系统你看的是 思维链(Chain of Thought)轨迹。
大部分智能体看似“发疯”,其实是在中间某一轮的 意图偏移:
-
本来要写接口文档 → 变成重构代码
-
本来要优化 prompt → 变成设计架构
-
本来要解一个约束问题 → 跑去胡编一个答案
技巧:记录每步的 Intent(意图)与 Action(动作)映射。
要点:
-
为每个 agent 加上一句: “你现在正在执行的子任务是什么?请显式写出来。”
-
将每轮的 planned_action 和 executed_action 自动对齐
细节最重要,这也是为什么我提倡智能体工程化可观测性,这是最能查出“跑偏”的第一步。
给每个智能体加“状态机护栏”,不要相信它能自我控制
程序最可靠的地方,就是它最“蠢”的地方。智能体最不可靠的地方,就是它“以为自己很聪明”。我发现:没有显式状态机的智能体系统,99% 的问题都来自隐式状态爆炸。
技巧:
-
不让 Agent 自己决定流程,而是提前定义状态图
-
所有行为必须满足:(state, input) → next_state
-
超出状态范围,直接打回:“动作非法,返回工作流”
只有记录,没有状态万万不行,我以前文章讲过很多次了,这比任何“优化 prompt”都有效。
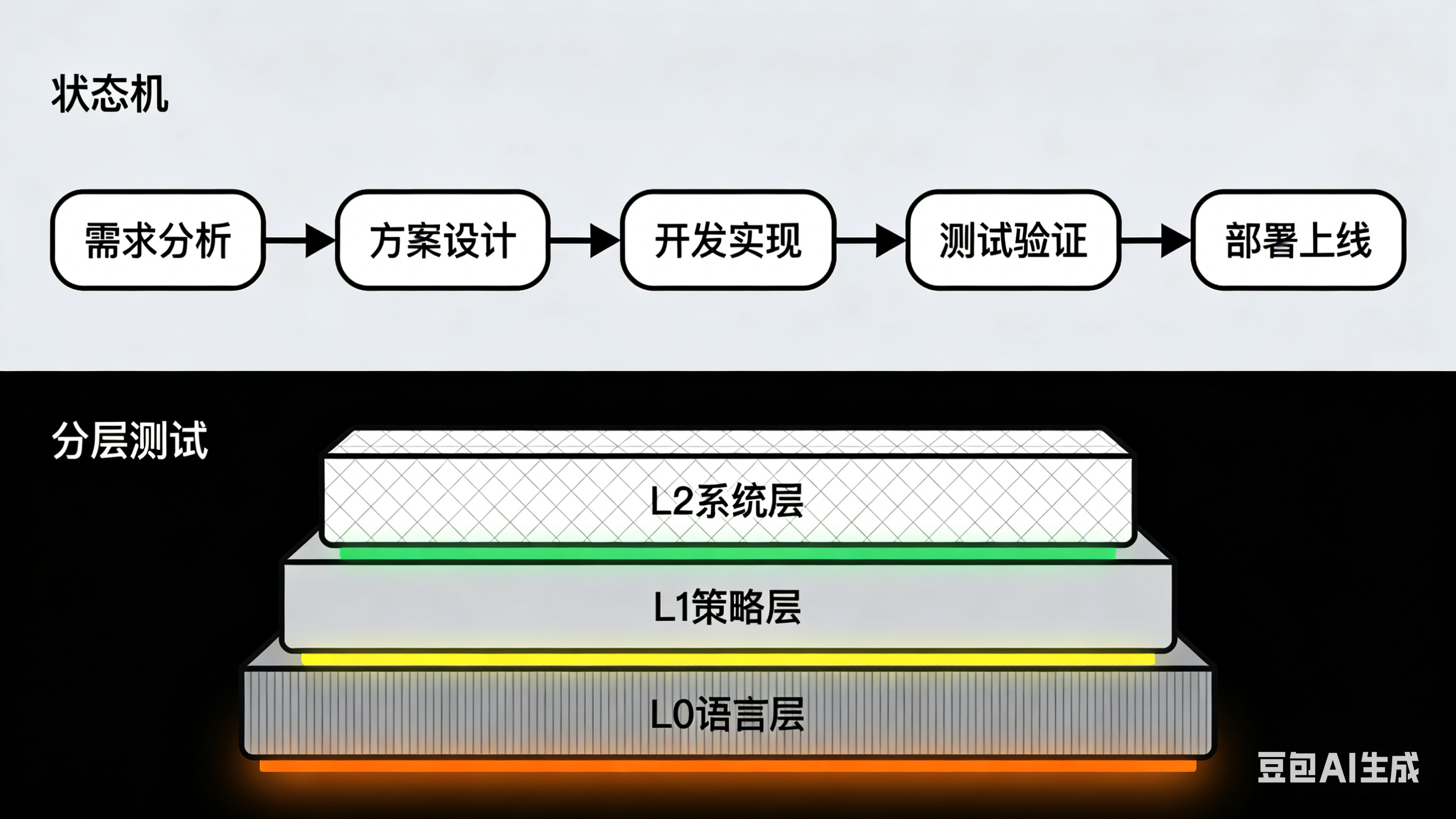
Debug 智能体系统要像 Debug 网络协议一样:逐层隔离,单位测试
智能体实际上有三个隐性层级:
-
语言层(LLM 内部推理)
-
策略层(Prompt + 工具路由)
-
系统层(消息编排、任务分配、上下文管理)
很多人调不出 bug,因为他把问题混在一起看。
正确方法:逐层隔离。
像 HTTP 那样:
-
测 L0:把 Agent 的工具全关掉,只让它用自然语言
-
测 L1:只开工具,不开多 Agent
-
测 L2:只开 workflow,不开长记忆
-
最后再合并
传统软件测试也是这么设计的,我调过的所有棘手问题几乎都在分层后瞬间定位。
多智能体问题 80% 都是“长上下文污染”导致的
典型症状:
-
Agent 1 的目标被 Agent 3 的历史对话污染
-
任务中后期开始“人格混乱”
-
多轮后开始出现幻觉、自我修改指令、重复执行
这不是模型坏了,是上下文脏了。本质的问题是:在多轮、多智能体的协作中,所有智能体的输入、思考、输出都被无差别地拼接进同一个线性增长的上下文里,形成了一个“信息沼泽”。每个智能体在行动时,都不得不在这个沼泽中打捞信息,极易错误地抓取到属于其他智能体、其他阶段或已被推翻的中间结论。
技巧:使用 3 种上下文隔离区:
-
任务上下文(Task Memory) 当前任务的真相源。工程实现建议:
-
独立存储,只读引用:将其存储在系统最外层,绝不作为普通消息推入对话历史。
-
每次关键决策前强制注入:在每个智能体做出关键决策(如规划、审核)的动作节点前,将任务上下文作为最高优先级的系统指令,重新、完整地注入到该次模型调用的提示词开头。
-
版本化:如果任务目标在运行中被合法更新(如经人类确认),应生成新的“任务上下文”版本,并明确通知所有智能体,废弃旧版本。
-
-
过程上下文(Scratchpad) 使用结构化存储,可随写随删。工程实现建议:
{ "consensus_facts": ["用户需要支持PDF导出的报表"], "current_step": "step_3_design_database_schema", "completed_steps": ["step_1", "step_2"], "open_issues": ["如何优化百万级数据的查询速度?"] }- 结构化存储,而非自然语言堆砌:强烈建议使用一种可解析的结构(如JSON、YAML或特定的状态机对象)来存储。例如:
-
增删改查的API化:为智能体提供明确的函数调用,来更新共识、推进步骤、登记问题,而不是让它们自己用自然语言说“我同意,我们下一步...”。
-
任务结束时清空:此区域与任务强绑定,任务结束(成功或失败)后应立即清空,为下一个任务准备干净的白板。
-
长期记忆(Long-term Memory) 这是智能体或团队的跨任务经验、领域知识和历史档案。它用于塑造基础能力,但不应直接参与具体任务的逻辑推理流。不参与短任务的推理,只用于基础认知。工程实现建议:
-
检索化,非注入化:长期记忆绝不应被完整注入上下文。只能通过精准检索(如基于向量数据库或关键词),提取与当前任务高度相关的片段,并以“参考知识”的形式,在需要时提供给特定智能体。
-
严格的元数据过滤:检索时必须附带严格的元数据过滤条件,如任务类型、相关领域、创建时间等,确保提取的知识是普适性经验,而非上次任务的具体流水账。
-
任何智能体,在长任务中都会“中途降智”——要用心跳(Heartbeat)机制检查健康状态
这是真实现象:推理到后半段,模型会感知疲劳,开始重复、缩句、产生幻觉。类似网络连接的流量劣化。
解决方法:对每一轮输出跑一个健康检查:
-
是否重复?
-
是否偏题?
-
是否逻辑断裂?
-
是否出现自我矛盾?
这是大模型底层机制决定的,太长上下文导致注意力下降。只要触发任一规则,自动:“重置思维链,保留任务目标,重新推理”。这比重新发 prompt 更有效。
多智能体系统最难的是消息风暴,必须加 Rate-limit 和 Backpressure
智能体之间互相发消息,很容易出现“指数级爆炸”。典型崩溃方式:
-
A 提醒 B → B 又提醒 A
-
任务未结束但 agent 互相催促
-
一个工具调用失败,反复重试导致无限循环
你以为只是 prompt 写得不好?这是 “系统工程问题”。
解决方法:
-
每个 agent 加消息配额: 比如每 10 秒最多 3 条消息
-
每轮执行后强制进入 Idle 状态
-
禁止非必要的 agent-to-agent ping
多智能体通讯协议,共享上下文会带来好处,但是副作用也不小,为了解决这些副作用,必须确保上下文不污染,只有这样系统才能立刻安静稳定下来。
最强技巧:给每个智能体加一个“裁判 Agent”做元认知调试
我试过最有效的调试方法叫:Meta-Agent Debugging 让另一个 Agent 来审查当前智能体的行为是否合理。它的职责:
-
验证目标是否被正确执行
-
检查推理链是否连贯
-
检查工具调用是否合理
-
强制纠偏偏离的计划
-
必要时重写 command
用智能体调试智能体,这是多智能体系统非常自然的演进方式。

最后:调试智能体,是未来工程师的核心能力
我越来越相信:未来的软件工程,将从“写代码”变成“调行为”。智能体系统的调试,已经具备明确的工程学:
-
状态机
-
隔离区
-
心跳
-
流控
-
元调试 Agent
-
意图轨迹
-
行为验证
这些都是传统系统工程的能力在智能体时代的升级。如果你准备构建真正可控、可预测、可复现的 Agent 系统,上面这 7 条 Debug 原则 会是你最好的武器。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









