







项目来源:WebServer
上一篇:Reactor高并发模型
本文介绍以下功能的代码实现
- 利用标准库容器封装char,实现自动增长的缓冲区;
- 利用正则与状态机解析HTTP请求报文,实现处理静态资源的请求;
一、自动增长的缓存区
定义Buffer类
class Buffer {
public:
Buffer(int initBuffSize = 1024);
~Buffer() = default;
size_t WritableBytes() const;//可写的字节数
size_t ReadableBytes() const ;//可读的字节数
size_t PrependableBytes() const;//可以扩展的字节数
const char* Peek() const;
void EnsureWriteable(size_t len);//整理或申请出足够的空间
void HasWritten(size_t len);
void Retrieve(size_t len);
void RetrieveUntil(const char* end);
void RetrieveAll() ;
std::string RetrieveAllToStr();
const char* BeginWriteConst() const;
char* BeginWrite();
void Append(const std::string& str);
void Append(const char* str, size_t len);
void Append(const void* data, size_t len);
void Append(const Buffer& buff);
ssize_t ReadFd(int fd, int* Errno);
ssize_t WriteFd(int fd, int* Errno);
private:
char* BeginPtr_();
const char* BeginPtr_() const;
void MakeSpace_(size_t len);//创建新的空间
std::vector<char> buffer_;//具体装数据的缓存
std::atomic<std::size_t> readPos_;//读的位置
std::atomic<std::size_t> writePos_;//写的位置
};
读数据函数主体
Buffer::ReadFd
ssize_t Buffer::ReadFd(int fd, int* saveErrno) {
char buff[65535];
struct iovec iov[2];
const size_t writable = WritableBytes();
/* 分散读, 保证数据全部读完 */
iov[0].iov_base = BeginPtr_() + writePos_;//内存,从哪读到哪,BeginPtr_()返回buffer_首地址
iov[0].iov_len = writable;//内存大小
iov[1].iov_base = buff;
iov[1].iov_len = sizeof(buff);
const ssize_t len = readv(fd, iov, 2);//调用分散读函数,存在buff和buffer_,返回读取长度
if(len < 0) {
*saveErrno = errno;
}
else if(static_cast<size_t>(len) <= writable) {//读取的数据在内存中能放下
writePos_ += len;//移动写指针
}
else {//读取的数据在内存中能放不下,需要把buff中的内容搬过来
writePos_ = buffer_.size();//写指针移动到末尾
Append(buff, len - writable);
}
return len;//返回此次读数据的长度
}
- 创建缓存区 buff

- 定义结构体数组 iov
struct iovec
{
void *iov_base; /* Pointer to data. 首地址 */
size_t iov_len; /* Length of data. 长度*/
};
iov[0]对应buffer_,iov[1]对应buff。
- 可写的空间
size_t Buffer::WritableBytes() const {
return buffer_.size() - writePos_;
}

- 调用分散读函数readv,存在buff和buffer_,返回读取长度
#include <sys/uio.h>
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);

readv 函数则将读入的数据按上述同样顺序散布到缓冲区中。readv 总是先填满一个缓冲区,然后再填写下一个。
- 如果读取的数据在内存中能放下,便移动写指针

- 读取的数据在内存中能放不下,需要把buff中的内容搬过来
void Buffer::Append(const char* str, size_t len) {
assert(str);
EnsureWriteable(len);//创造出len长度可以用的空间
std::copy(str, str + len, BeginWrite());
//把暂存在buff中的数据取过来
HasWritten(len);//移动写指针
}
void Buffer::EnsureWriteable(size_t len) {
if(WritableBytes() < len) {
MakeSpace_(len);//腾出来len长度
}
assert(WritableBytes() >= len);
}
这里的len是上面读取数据的长度减去剩余可写的空间
void Buffer::MakeSpace_(size_t len) {
if(WritableBytes() + PrependableBytes() < len) {
//内存的空间不足,需要申请新空间
buffer_.resize(writePos_ + len + 1);
}
else {//内存的空间充足,不需要申请新空间
size_t readable = ReadableBytes();
std::copy(BeginPtr_() + readPos_, BeginPtr_() + writePos_, BeginPtr_());
readPos_ = 0;
writePos_ = readPos_ + readable;
//把读写指针以及之间的内容平移到buffer_开头
assert(readable == ReadableBytes());
}
}
这里分两种情况
第一种:buffer_剩余的空间充足,不需要额外申请空间



第二种:buffer_剩余的空间不足,需要额外申请空间


二、HTTP协议
1、简介
超文本传输协议(Hypertext Transfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII形式给出;而消息内容则具有一个类似MIME的格式。HTTP是万维网的数据通信的基础。
HTTP的发展是由蒂姆·伯纳斯-李于1989年在欧洲核子研究组织(CERN)所发起。HTTP的标准制定由万维网协会(World Wide webConsortium,W3C)和互联网工程任务组(Internet Engineering Task Force,IETF)进行协调,最终发布了一系列的RFC,其中最著名的是1999年6月公布的RFC 2616,定义了HTTP协议中现今广泛使用的一个版本——HTTP1.1。
2、工作原理
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
以下是HTTP请求/响应的步骤:
-
客户端连接到Web 服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80 ) 建立一个TCP套接字连接。例如,http:.//www.baidu.com。统一资源定位系统(uniform resource locator;URL) -
发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。 -
服务器接受请求并返回HTTP响应
Web 服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。 -
释放连接TCP连接
若connection模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection模式为 keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求; -
客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据 HTML的语法对其进行格式化,并在浏览器窗口中显示。
例如:在浏览器地址栏键入URL,按下回车之后会经历以下流程:
- 浏览器向DNS服务器请求解析该URL中的域名所对应的IP地址;
- 解析出IP地址后,根据该IP地址和默认端口80,和服务器建立TCP连接;
- 浏览器发出读取文件(URL中域名后面部分对应的文件)的HTTP请求,该请求报文作为TCP三次握手的第三个报文的数据发送给服务器;
- 服务器对浏览器请求作出响应,并把对应的HTML文本发送给浏览器;
- 释放TCP连接;
- 浏览器将该HTML文本并显示内容。

HTTP协议是基于TCP/IP协议之上的应用层协议,基于请求-响应的模式。HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收到请求之前不会发送响应。
HTTP请求报文格式
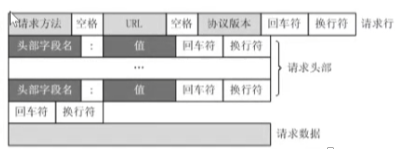
GET / HTTP/1.1
Host: www. baidu.comconnection: keep-alive
sec-ch-ua: " Not A;Brand" ;v="99","Chromium" ; v="98","Google Chrome" ; v="98"sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "windows"upgrade-Insecure-Requests: 1
User-Agent:Mozill1a/5.0(Windows NT 10.0;Min64;x64)ApplelebKit/537.36(KHTML,1ike Gecko) Ch-ome/98.0.4758.102 Sofari/537.36
Acept:text/html,application/xhtnl-+xnl application/xml};g=0. 9 ,image/avif , image /uebp,image/apng ,*1*,q=0.8,aplication/signed-exchange;v=b3;q=0.9
Sec-Fetch-site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip,deflate, br
Accept-Language: zh-CM,zh;q=0.9,en-US; q=0.8,en;q=0.7
HTTP响应报文格式
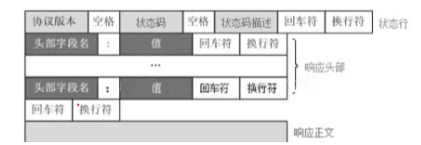
HTTP/1.1 200 oK
Bdpagetype: 2
Bdqid: oxaadc3f2000ocec6b
Cache-Control: privateconnection: keep-alive
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
Date: sun, 03 Apr 202207:41: 38 GMT
Expires : Sun, 03 Apr 202207:41:38 GMTServer: BwS/1.1
Set-Cookie: BDSVRTM=322; path=/
Set-Cookie: BD_HOME=1; path=/
Sset-cokie: H_PS_PSS10=35835_36175_31254_3605_35087_35167_34584_36142_36121_36075_36126_35863_36233_26358_36115_35868_36102_36061; path=/ ; domain=.baidu .com
Strict-Transport-Security: max-age=172800
Traceid: 1648971698043918593012311784887996443755
X-Frame-Options: sameorigin
X-Ua-Compatible: IE=Edge,chrome=1
Transfer-Encoding: chunked
HTTP请求方法
HTTP/1.1协议中共定义了八种方法(也叫"“动作””)来以不同方式操作指定的资源:
- GET:向指定的资源发出"显示"请求。使用GET方法应该只用在读取数据,而不应当被用于产生′副作用的操作中,例如在 Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问。
- HEAD:与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中"关于该资源的信息”(元信息或称元数据)。
- POST:向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
- PUT:向指定资源位置上传其最新内容。
- DELETE:请求服务器删除 Request-URI所标识的资源。
- TRACE:回显服务器收到的请求,主要用于测试或诊断。
- OPTIONS:这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用’*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
- CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的链接(经由非加密的HTTP代理服务器)。
HTTP状态码
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。
状态代码的第一个数字代表当前响应的类型;
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功―—请求已成功被服务器接收、理解、并接受。
- 3xx重定向——需要后续操作才能完成这─请求
- 4×x请求错误―—请求含有词法错误或者无法被执行
- 5xx服务器错误―—服务器在处理某个正确请求时发生错误
虽然RFC 2616中已经推荐了描述状态的短语,例如"200 oK"; “404 Not Found”,但是WEB开发者仍然能够自行决定采用何种短语,用以显示本地化的状态描述或者自定义信息。

三、处理HTTP请求
程序执行的主体
bool HttpConn::process() {
request_.Init();//封装成request_
if(readBuff_.ReadableBytes() <= 0) {
return false;
}
else if(request_.parse(readBuff_)) {//解析成功
LOG_DEBUG("%s", request_.path().c_str());
response_.Init(srcDir, request_.path(), request_.IsKeepAlive(), 200);//初始化响应
} else {
response_.Init(srcDir, request_.path(), false, 400);
}
response_.MakeResponse(writeBuff_);
/* 响应头 */
iov_[0].iov_base = const_cast<char*>(writeBuff_.Peek());
iov_[0].iov_len = writeBuff_.ReadableBytes();
iovCnt_ = 1;
/* (正文)文件 分散写*/
if(response_.FileLen() > 0 && response_.File()) {
iov_[1].iov_base = response_.File();
iov_[1].iov_len = response_.FileLen();
iovCnt_ = 2;
}
LOG_DEBUG("filesize:%d, %d to %d", response_.FileLen() , iovCnt_, ToWriteBytes());
return true;
}
1. 初始化请求request_.Init();
void HttpRequest::Init() {
method_ = path_ = version_ = body_ = "";
state_ = REQUEST_LINE;
header_.clear();
post_.clear();
}
将当前的处理状态设置为REQUEST_LINE,处理请求行
2. 解析请求request_.parse(readBuff_)
bool HttpRequest::parse(Buffer& buff) {
const char CRLF[] = "\r\n";
if(buff.ReadableBytes() <= 0) {
return false;
}
while(buff.ReadableBytes() && state_ != FINISH) {
//获取一行数据,根据\r\n为结束标志
const char* lineEnd = search(buff.Peek(), buff.BeginWriteConst(), CRLF, CRLF + 2);
std::string line(buff.Peek(), lineEnd);
switch(state_)//state_每次循环都会改变
{
case REQUEST_LINE:
if(!ParseRequestLine_(line)) {//解析请求行
return false;
}
ParsePath_();//成功后继续解析路径资源
break;
case HEADERS:
ParseHeader_(line);
if(buff.ReadableBytes() <= 2) {
state_ = FINISH;
}
break;
case BODY:
ParseBody_(line);
break;
default:
break;
}
if(lineEnd == buff.BeginWrite()) { break; }//如果读到最后
buff.RetrieveUntil(lineEnd + 2);
}
LOG_DEBUG("[%s], [%s], [%s]", method_.c_str(), path_.c_str(), version_.c_str());
return true;
}
循环读取数据,直到缓存区数据读取完成且状态为FINISH
const char* lineEnd = search(buff.Peek(), buff.BeginWriteConst(), CRLF, CRLF + 2);
std::string line(buff.Peek(), lineEnd);
在读指针和写指针之间的区域寻找换行符"\r\n"。之后把从读指针到换行符之间的内容作为一行存储在字符串line中
这里生成了一个有限状态机,状态类型
enum PARSE_STATE {
REQUEST_LINE,//正在解析请求首行
HEADERS, //头
BODY, //体
FINISH, //完成
};
当前的状态为REQUEST_LINE,执行ParseRequestLine_(line)
bool HttpRequest::ParseRequestLine_(const string& line) {
regex patten("^([^ ]*) ([^ ]*) HTTP/([^ ]*)$");
//正则表达式
smatch subMatch;
if(regex_match(line, subMatch, patten)) { //如果匹配成功
method_ = subMatch[1];
path_ = subMatch[2];
version_ = subMatch[3];
state_ = HEADERS;//状态改变
return true;
}
LOG_ERROR("RequestLine Error");
return false;
}
使用正则表达式进行匹配,匹配成功之后改变当前状态 HEADERS,执行ParsePath_();解析路径资源,给path加上后缀名
void HttpRequest::ParsePath_() {
if(path_ == "/") {
path_ = "/index.html";
}
else {
for(auto &item: DEFAULT_HTML) {
if(item == path_) {
path_ += ".html";
break;
}
}
}
}
DEFAULT_HTML{
"/index", "/register", "/login",
"/welcome", "/video", "/picture", };
path_的值即资源路径。当前状态 HEADERS,执行ParseHeader_(line);
void HttpRequest::ParseHeader_(const string& line) {
regex patten("^([^:]*): ?(.*)$");
smatch subMatch;
if(regex_match(line, subMatch, patten)) {
header_[subMatch[1]] = subMatch[2];
}
else {
state_ = BODY;
}
}
依旧是正则匹配,满足键:值对应的结构便是请求结构头。将键和值存在header_这个表中。匹配失败时说明已经读完了请求头部,将当前的状态改为BODY
如果当前缓存区可读的内容少于两个字节,说明没有请求体,将状态改为FINISH
可读的内容大于两个字节,继续执行 ParseBody_(line);
void HttpRequest::ParseBody_(const string& line) {
body_ = line;
ParsePost_();
state_ = FINISH;
LOG_DEBUG("Body:%s, len:%d", line.c_str(), line.size());
}
void HttpRequest::ParsePost_() {
if(method_ == "POST" && header_["Content-Type"] == "application/x-www-form-urlencoded") {
ParseFromUrlencoded_();
if(DEFAULT_HTML_TAG.count(path_)) {
int tag = DEFAULT_HTML_TAG.find(path_)->second;
LOG_DEBUG("Tag:%d", tag);
if(tag == 0 || tag == 1) {
bool isLogin = (tag == 1);
if(UserVerify(post_["username"], post_["password"], isLogin)) {
path_ = "/welcome.html";
}
else {
path_ = "/error.html";
}
}
}
}
}
处理请求主体结构
if(lineEnd == buff.BeginWrite()) { break; }//如果读到最后
buff.RetrieveUntil(lineEnd + 2);
如果读到了结尾,退出循环。每循环一次,读指针位置往后移动一行。
3. 解析成功之后初始化响应报文
response_.Init(srcDir, request_.path(), request_.IsKeepAlive(), 200);//初始化响应
void HttpResponse::Init(const string& srcDir, string& path, bool isKeepAlive, int code){
assert(srcDir != "");
if(mmFile_) { UnmapFile(); }
code_ = code;
isKeepAlive_ = isKeepAlive;
path_ = path;
srcDir_ = srcDir;
mmFile_ = nullptr;
mmFileStat_ = { 0 };//文件状态
}
4. 创建响应报文
response_.MakeResponse(writeBuff_);
void HttpResponse::MakeResponse(Buffer& buff) {
/* 判断请求的资源文件 */
if(stat((srcDir_ + path_).data(), &mmFileStat_) < 0 || S_ISDIR(mmFileStat_.st_mode)) {
code_ = 404;
}
else if(!(mmFileStat_.st_mode & S_IROTH)) {
code_ = 403;
}
else if(code_ == -1) { //默认值-1
code_ = 200;
}
ErrorHtml_();
AddStateLine_(buff);
AddHeader_(buff);
AddContent_(buff);
}
stat函数的用法
定义函数: int stat(const char *file_name, struct stat *buf);
函数说明: 通过文件名filename获取文件信息,并保存在buf所指的结构体stat中
返回值: 执行成功则返回0,失败返回-1,错误代码存于errno
| S_ISDIR | 是否目录格式 |
|---|---|
| 404 | 服务器找不到所请求的资源 |
| S_IROTH | 其他用户具可读取权限 |
| 403 | 客户端没有权利访问所请求内容,服务器拒绝本次请求. |
| 200 | 请求成功.成功的意义根据请求所使用的方法不同而不同. GET: 资源已被提取,并作为响应体传回客户端. HEAD: 实体头已作为响应头传回客户端 POST: 经过服务器处理客户端传来的数据,适合的资源作为响应体传回客户端. TRACE: 服务器收到请求消息作为响应体传回客户端. PUT, DELETE, 和 OPTIONS 方法永远不会返回 200 状态码. |
ErrorHtml_()存储错误网址url
void HttpResponse::ErrorHtml_() {
if(CODE_PATH.count(code_) == 1) {
path_ = CODE_PATH.find(code_)->second;
stat((srcDir_ + path_).data(), &mmFileStat_);
}
}
const unordered_map<int, string> HttpResponse::CODE_PATH = {
{ 400, "/400.html" },
{ 403, "/403.html" },
{ 404, "/404.html" },
};
AddStateLine_(buff);添加响应状态行
void HttpResponse::AddStateLine_(Buffer& buff) {
string status;
if(CODE_STATUS.count(code_) == 1) {//如果在map中找到了
status = CODE_STATUS.find(code_)->second; //码对应的字符
}
else {
code_ = 400;
status = CODE_STATUS.find(400)->second;
}
buff.Append("HTTP/1.1 " + to_string(code_) + " " + status + "\r\n");//响应信息
}
const unordered_map<int, string> HttpResponse::CODE_STATUS = {
{ 200, "OK" },
{ 400, "Bad Request" },
{ 403, "Forbidden" },
{ 404, "Not Found" },
};
AddHeader_(buff);添加响应头部
void HttpResponse::AddHeader_(Buffer& buff) {
buff.Append("Connection: ");
if(isKeepAlive_) {
buff.Append("keep-alive\r\n");
buff.Append("keep-alive: max=6, timeout=120\r\n");
} else{
buff.Append("close\r\n");
}
buff.Append("Content-type: " + GetFileType_() + "\r\n");//添加文件类型
}
string HttpResponse::GetFileType_() {
/* 判断文件类型 */
string::size_type idx = path_.find_last_of('.');
if(idx == string::npos) {
return "text/plain";
}
string suffix = path_.substr(idx);
if(SUFFIX_TYPE.count(suffix) == 1) {
return SUFFIX_TYPE.find(suffix)->second;
}
return "text/plain";
}
const unordered_map<string, string> HttpResponse::SUFFIX_TYPE = {
{ ".html", "text/html" },
{ ".xml", "text/xml" },
{ ".xhtml", "application/xhtml+xml" },
{ ".txt", "text/plain" },
{ ".rtf", "application/rtf" },
{ ".pdf", "application/pdf" },
{ ".word", "application/nsword" },
{ ".png", "image/png" },
{ ".gif", "image/gif" },
{ ".jpg", "image/jpeg" },
{ ".jpeg", "image/jpeg" },
{ ".au", "audio/basic" },
{ ".mpeg", "video/mpeg" },
{ ".mpg", "video/mpeg" },
{ ".avi", "video/x-msvideo" },
{ ".gz", "application/x-gzip" },
{ ".tar", "application/x-tar" },
{ ".css", "text/css "},
{ ".js", "text/javascript "},
};
AddContent_(buff);添加响应正文
void HttpResponse::AddContent_(Buffer& buff) {
int srcFd = open((srcDir_ + path_).data(), O_RDONLY);
if(srcFd < 0) {
ErrorContent(buff, "File NotFound!");
return;
}
/* 将文件映射到内存提高文件的访问速度
MAP_PRIVATE 建立一个写入时拷贝的私有映射*/
LOG_DEBUG("file path %s", (srcDir_ + path_).data());
int* mmRet = (int*)mmap(0, mmFileStat_.st_size, PROT_READ, MAP_PRIVATE, srcFd, 0);
if(*mmRet == -1) {
ErrorContent(buff, "File NotFound!");
return;
}//响应正文映射到内存中
mmFile_ = (char*)mmRet;
close(srcFd);
buff.Append("Content-length: " + to_string(mmFileStat_.st_size) + "\r\n\r\n");
}
5. 分散写(状态行、头部)和正文
/* 响应头 */
iov_[0].iov_base = const_cast<char*>(writeBuff_.Peek());
iov_[0].iov_len = writeBuff_.ReadableBytes();
iovCnt_ = 1;
/* (正文)文件 分散写*/
if(response_.FileLen() > 0 && response_.File()) {
iov_[1].iov_base = response_.File();
iov_[1].iov_len = response_.FileLen();
iovCnt_ = 2;
}















 1923
1923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









