







keras model.compile(loss='目标函数 ', optimizer='adam', metrics=['accuracy'])
深度学习笔记
目标函数的总结与整理
目标函数,或称损失函数,是网络中的性能函数,也是编译一个模型必须的两个参数之一。由于损失函数种类众多,下面以keras官网手册的为例。
在官方keras.io里面,有如下资料:
mean_squared_error或msemean_absolute_error或maemean_absolute_percentage_error或mapemean_squared_logarithmic_error或mslesquared_hingehingebinary_crossentropy(亦称作对数损失,logloss)categorical_crossentropy:亦称作多类的对数损失,注意使用该目标函数时,需要将标签转化为形如(nb_samples, nb_classes)的二值序列sparse_categorical_crossentrop:如上,但接受稀疏标签。注意,使用该函数时仍然需要你的标签与输出值的维度相同,你可能需要在标签数据上增加一个维度:np.expand_dims(y,-1)kullback_leibler_divergence:从预测值概率分布Q到真值概率分布P的信息增益,用以度量两个分布的差异.cosine_proximity:即预测值与真实标签的余弦距离平均值的相反数
mean_squared_error
顾名思义,意为均方误差,也称标准差,缩写为MSE,可以反映一个数据集的离散程度。
标准误差定义为各测量值误差的平方和的平均值的平方根,故又称为均方误差。
公式:
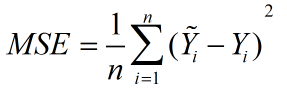
公式意义:可以理解为一个从n维空间的一个点到一条直线的距离的函数。(此为在图形上的理解,关键看个人怎么理解了)
mean_absolute_error
译为平均绝对误差,缩写MAE。
平均绝对误差是所有单个观测值与算术平均值的偏差的绝对值的平均。
公式:(fi是预测值,yi是实际值)
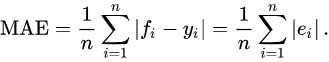
mean_absolute_percentage_error
译为平均绝对百分比误差 ,缩写MAPE。
公式:(At表示实际值,Ft表示预测值)
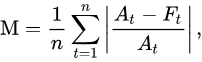
mean_squared_logarithmic_error
译为均方对数误差,缩写MSLE。
公式:(n是整个数据集的观测值,pi为预测值,ai为真实值)
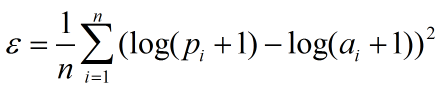
squared_hinge
公式为max(0,1-y_true*y_pred)^2.mean(axis=-1),取1减去预测值与实际值的乘积的结果与0比相对大的值的平方的累加均值。
hinge
公式为为max(0,1-y_true*y_pred).mean(axis=-1),取1减去预测值与实际值的乘积的结果与0比相对大的值的累加均值。
Hinge Loss
最常用在 SVM 中的最大化间隔分类中,
对可能的输出 t = ±1 和分类器分数 y,预测值 y 的 hinge loss 定义如下:
L(y) = max(0,1-ty)
看到 y 应当是分类器决策函数的“原始”输出,而不是最终的类标。例如,在线性的 SVM 中
y = wx+b
可以看出当 t 和 y 有相同的符号时(意味着 y 预测出正确的分类)
|y|>=1
此时的 hinge loss
L(y) = 0
但是如果它们的符号相反
L(y)则会根据 y 线性增加 one-sided error。(译自wiki)
binary_crossentropy
即对数损失函数,log loss,与sigmoid相对应的损失函数。
公式:L(Y,P(Y|X)) = -logP(Y|X)
该函数主要用来做极大似然估计的,这样做会方便计算。因为极大似然估计用来求导会非常的麻烦,一般是求对数然后求导再求极值点。
损失函数一般是每条数据的损失之和,恰好取了对数,就可以把每个损失相加起来。负号的意思是极大似然估计对应最小损失。
categorical_crossentropy
多分类的对数损失函数,与softmax分类器相对应的损失函数,理同上。
tip:此损失函数与上一类同属对数损失函数,sigmoid和softmax的区别主要是,sigmoid用于二分类,softmax用于多分类。
一种解释:
softmax公式:
logistic regression的目标函数是根据最大似然来做的.也就是假设x属于类y,预测出概率为oy,那么需要最大化oy.
softmax_loss的计算包含2步:
(1)计算softmax归一化概率
归一化概率
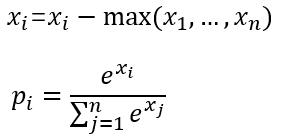
(2)计算损失
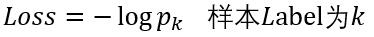
这里以batchsize=1的2分类为例:
设最后一层的输出为[1.2, 0.8],减去最大值后为[0, -0.4],
然后计算归一化概率得到[0.5987 0.4013],
假如该图片的label为1,则Loss=-log(0.4013)=0.9130
学习了,原文链接原文















 9820
9820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









