




假设函数 损失函数 代价函数 目标函数 与线性回归
摘要:机器学习是计算机领域中的重要技术,它使人类能够“教”机器如何学习,让人类和机器的联系更为紧密。机器通过处理合适的训练集来学习,这些训练集包含优化一个算法所需的各种特征。这个算法使机器能够执行特定的任务,例如对电子邮件进行分类,对之后情况进行预测。本文将介绍机器学习中最经典的预测算法——线性回归算法,并借由机器学习中的三种函数损失函数,代价函数,目标函数,结合具体的实例详细介绍函数在线性回归算法中的作用和意义。最后给出了线性回归模型的形式化定义。
关键词:机器学习;损失函数;代价函数;目标函数;线性回归
1 前言
人工智能成为当前计算机领域最炙手可热的方向,在这一点上机器学习功不可没。机器学习用计算机程序模拟人的学习能力,从实际例子中学习得到知识和经验,是一门综合学科涉及到统计学,应用数学,经济学和计算机科学它们之间的联系可以表示成下图1-1。机器学习是人工智能的一个分支,也是人工智能的一种实现方法。它已经走完了近40年的道路,各种优秀的算法被人类研究出来,这些算法的诞生时间可以大致表示如图1-2所示。线性回归就是其中最为经典的算法。它从样本数据中学习得到知识和规律,然后用于实际的决策和推断。
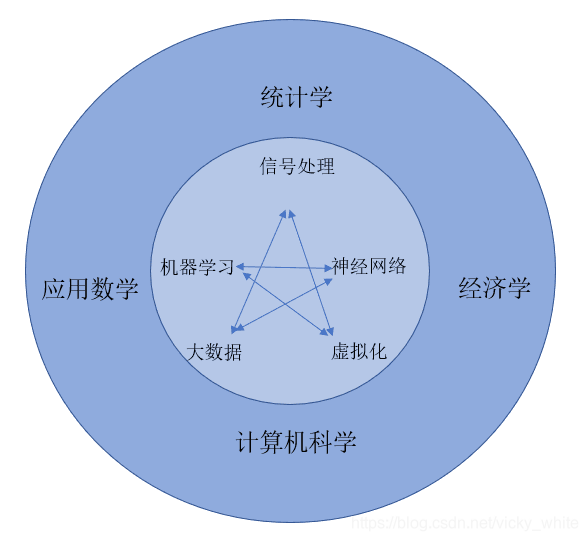
图1-1:学科之间的关
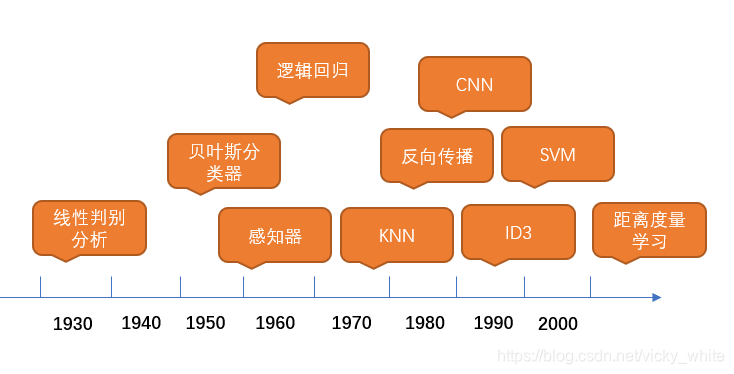
图1-2:算法发展时间
2 简单线性回归
在统计学中,线性回归是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。本文将结合具体的实例来讲解线性回归算法在机器学习中的应用。
2.1三种函数的定义和表示
线性回归是机器学习中基础的一种预测算法,要想准确的对数据做出预测,要先
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









