







回归分析(Regression)
定义: 回归分析是描述变量间关系的一种统计分析方法,描述因变量Y 和自变量X之间的关系, 一个例子比如说西瓜的甜度(Y) 和自变量 (瓜的颜色/拍的声音/藤曼的长度等),有时候也叫做拟合(modelling)。
1. 线性回归(Linear regression)
回归分析(Regression)
定义: 回归分析是描述变量间关系的一种统计分析方法,描述因变量Y 和自变量X之间的关系, 一个例子比如说西瓜的甜度(Y) 和自变量 (瓜的颜色/拍的声音/藤曼的长度等),有时候也叫做拟合(modelling)。
1. 线性回归(Linear regression)

所谓线性回归就是自变量和因变量呈线性关系,上面的例子就是一个线性的关系,其中红框的是每个自变量的权重w蓝色框是截距b。简单的来说就是 y = wx + b。
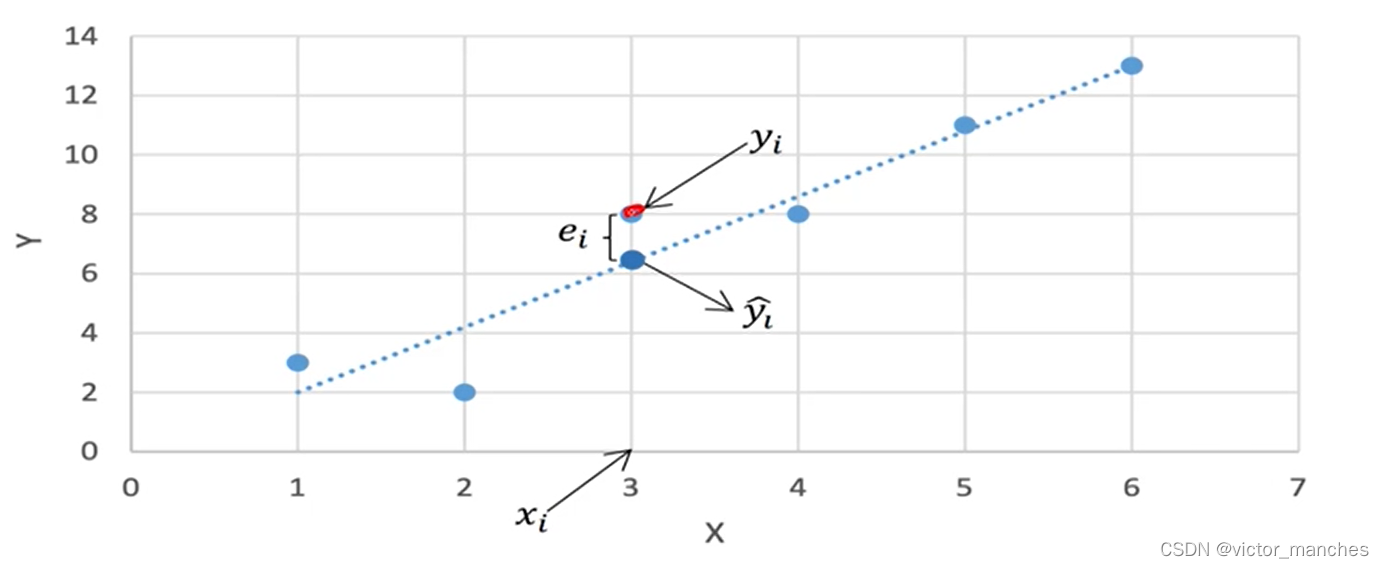
但是在实际过程中大部分数据呈现的都不是呈现完美的线性关系,所以这里我们引入了残差项e, 定义为目标真实值y 与预测值y’之间的距离(这里计算距离的方式有很多后面会单独列一章解释)。所以我们真实的目标是使得所有的训练样例的残差项尽可能小。
基于线性回归需要基于以下4个假设才能成立:
- 自变量和因变量存在线性关系
- 数据点之间相互独立
- 自变量之间无共线性,相互独立
- 残差独立,等方差且呈正态分布
2. 损失函数(Loss function)
有几种常见的损失函数:
- 所有误差项加和的损失函数
- 缺点: 如果残差方向相反大小相等时,二者的loss项目抵消。
- 所有误差绝对值加和的损失函数L1(MAE)
- 缺点: 在0处不可导
- 所有误差平方和的损失函数L2 (MSE)
- 缺点: 对噪声不鲁棒, 对方向的预测是等价的(大于真实值和小于真实值带来的影响是等价的)
3 最小二乘法(Least Square LS)
这里定义的残差项为e = (y - y’)² , 为了使得所有数据点的Σ(ei)的和最小,就直接求参数偏导就行了,由于因变量X可能有多个所以我们采用矩阵方式Y = X β + ∊ , 其中β0 是截距 , β1 - βk 对应的是权重, 所以整个参数向量β一个k维的向量,而残差项∊ 属于n维的向量与y的维度有关:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VuOSseG5-1680854254691)(image/Regression/1680852456906.png)]](https://i-blog.csdnimg.cn/blog_migrate/efcbc54202e93755f47a909461bb88cf.png)
同样对β求导, 损失函数为残差项∊的平方和求解得到β的值(X’ 表示的是X矩阵的转置):
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-09I9To2q-1680854254692)(image/Regression/1680852946645.png)]](https://i-blog.csdnimg.cn/blog_migrate/f304153a1546b7e8e652e0aae3e4e017.png)
4 梯度下降法(Gradient Descent GD)
这个方法也是目前深度学习用来求得极值点的方法,但是后面会在介绍深度学习的时候着重介绍。其大致的流程如下:
- 随机初始化参数θ
- 计算参数的梯度θ’
- 更新新的参数θnew = θold - α θ’ (α是学习率,控制每次更新参数的步长)
- 重复步骤23直至收敛
我们可以发现由于参数是随机初始化的所以这里有时候会陷入local minimal 。
线性相关系数
相关系数r:
描述两个变量X 和Y 的线性相关程度, 其值域[-1 , 1]之间正负代表正相关和负相关,绝对值越接近1线性相关系数越高,公式如下其中Sx代表的是x的标准差:

决定系数R²:
描述了模型的数据的解释程度:
- 因变量的波动有多少百分比能被自变量的波动所描述
- R² 越接近1.表示回归分析中的自变量对因变量的解释越好
- R² ≠ r²

示例代码
数据来源:World University Rankings | Kaggle
自实现的最小二乘法
# B: 利用最小二乘法的实现
def addones(i):
"""给X特征添加一列1"""
ones = np.ones(i.shape[0]).reshape((i.shape[0],1))
return np.hstack((ones,i))
x_train_lse , x_test_lse = addones(x_train) ,addones(x_test)
## 对于非方针算逆矩阵,利用np.linalg.pinv()
regression = np.dot(np.dot(np.linalg.pinv(np.dot(x_train_lse.T,x_train_lse)),x_train_lse.T),y_train) #标准方程计算
pred_lse = np.dot(x_test_lse,regression)
rmse_lse = np.sqrt(MSE(y_test,pred_lse)) # RMSE
r2_lse = r2(y_test,pred_lse)
print(f"最小二乘法的RMSE:{rmse_lse:.3f}")
print(f"最小二乘法的R2:{r2_lse:.3f}")
利用sklearn自带的线性回归实现
# A : 利用sklearn自带的线性回归库实现,
from sklearn.linear_model import LinearRegression as LR
from sklearn.metrics import mean_squared_error as MSE
from sklearn.metrics import r2_score as r2
reg = LR()
reg.fit(x_train , y_train)
y_pred = reg.predict(x_test)
rmse_sklr = np.sqrt(MSE(y_test,y_pred)) # RMSE
r2_sklr = r2(y_test,y_pred)
print(f"python自带的RMSE:{rmse_sklr:.3f}")
print(f"python自带的R2:{r2_sklr:.3f}")
梯度下降法的自实现:
# C:梯度下降法
class Graddesent:
def __init__(self):
'''初始化梯度下降的参数'''
self.weight = np.random.randn(8)
self.bias = np.random.random((1))
def updataTheta(self,data,lr):
'''#定义一个batch的梯度下降函数
data:[:,:-1] 是x特征 , [:,-1]是y
lr:学习率
w = w - lr * (gradient_w::2*(y - (wx + b))x)
b = b - lr * (gradient_b::2*(y - (wx + b))
'''
batchsize = len(data) #样本个树
#初始化batah的梯度
batch_gradient_b = 0
batch_gradient_w = 0
for sample in data:
sample_x = np.array(sample[:-1]) # x
sample_y = sample[-1]
#print(sample_x.shape, type(sample_y) , self.weight.shape)
#计算每个batch里w的梯度均值
y = (np.dot(sample_x,self.weight) + self.bias)
# #计算每个batch里bw的梯度
sample_gradient_b = 2 * (y - sample_y)
sample_gradient_w = 2 * np.dot((y - sample_y),sample_x.reshape(1,sample_x.shape[0]))
batch_gradient_w += sample_gradient_w
batch_gradient_b += sample_gradient_b
# print(batch_gradient_w.shape , batch_gradient_b.shape)
# #更新参数值
self.weight = self.weight - lr * batch_gradient_w / batchsize
self.bias = self.bias - lr * batch_gradient_b / batchsize
# #print(self.weight , self.bias )
def fit(self, x_train, y_train, batchsize = 0 , lr = 0 , epoch = 0):
#完成每次epoch需要看多少次batch
turn = (x_train.shape[0])//batchsize
data = np.hstack((x_train, y_train.values.reshape((y_train.shape[0],1)))) #将feature和label合并
data = data.tolist()
for i in range(epoch):
random.shuffle(data) #每次随机洗牌
for x in range(turn):
batch_data = data[x * batchsize : (x + 1)* batchsize ]
self.updataTheta(batch_data, lr)
#print(f"In {i+1} times epoch, RMSE is :{np.sqrt(MSE(y_train,self.predict(x_train))):.3f}")
def predict(self,x_test):
"""预测函数"""
y = (np.dot(x_test,self.weight) + self.bias)
y = y.reshape(y.shape[0],1)
return y
c = Graddesent()
c.fit(x_train, y_train, batchsize = 100, lr = 0.1 , epoch = 1000)
y_predict = c.predict(x_test)
rmse_mbgd = np.sqrt(MSE(y_test,y_predict))
r2_mbgd = r2(y_test, y_predict)
print(f"梯度下降的rmse:{rmse_mbgd:.3f}")
print(f"梯度下降的r2:{r2_mbgd:.3f}")
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











