









论文名:APPLYING DEEP LEARNING TO ANSWER SELECTION:
A STUDY AND AN OPEN TASK
作者来自IBM Watson 团队
思路
将QA问题转换为 Text matching和text selection 的问题。该模型中,存在问题q,和候选答案集合A,目标是对与问题q,从集合A中选择最合适的答案a。
问题q会和集合A中的每个答案a进行相关性计算,最后得分最高的答案a会被选中。
模型不能够对需要推理的问题进行回答。
模型结构
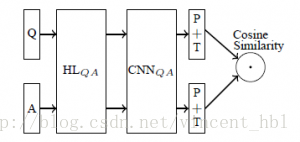
HL是一个非线性变换g(W*x+b),P是maxpooling,T是tanh激活函数。问题Q和答案A分别通过模型,得到两个向量。最后计算两个向量的余弦距离。
模型中,Q与A共用HL变化和CNN网络模型参数。
模型训练:
训练过程最小化ranking loss。具体做法是:
训练模型时每个样本包括问题Q,正确回答A+和错误回答A-。分别计算余弦距离cos(Q,A+)与cos(Q,A-)。当满足cos(Q,A+)- cos(Q,A-) < m 时,m为一阈值,说明模型不能够将A+ 答案排在足够靠前,那么进行权重更新。如果cos(Q,A+)- cos(Q,A-) >= m,不需要更新模型,更换A-回答,直到cos(Q,A+)- cos(Q,A-) < m。
为了减少运算时间,需要设置最大重选A-次数,论文中设置为50。
模型实现
参见52NLP文章















 681
681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









