







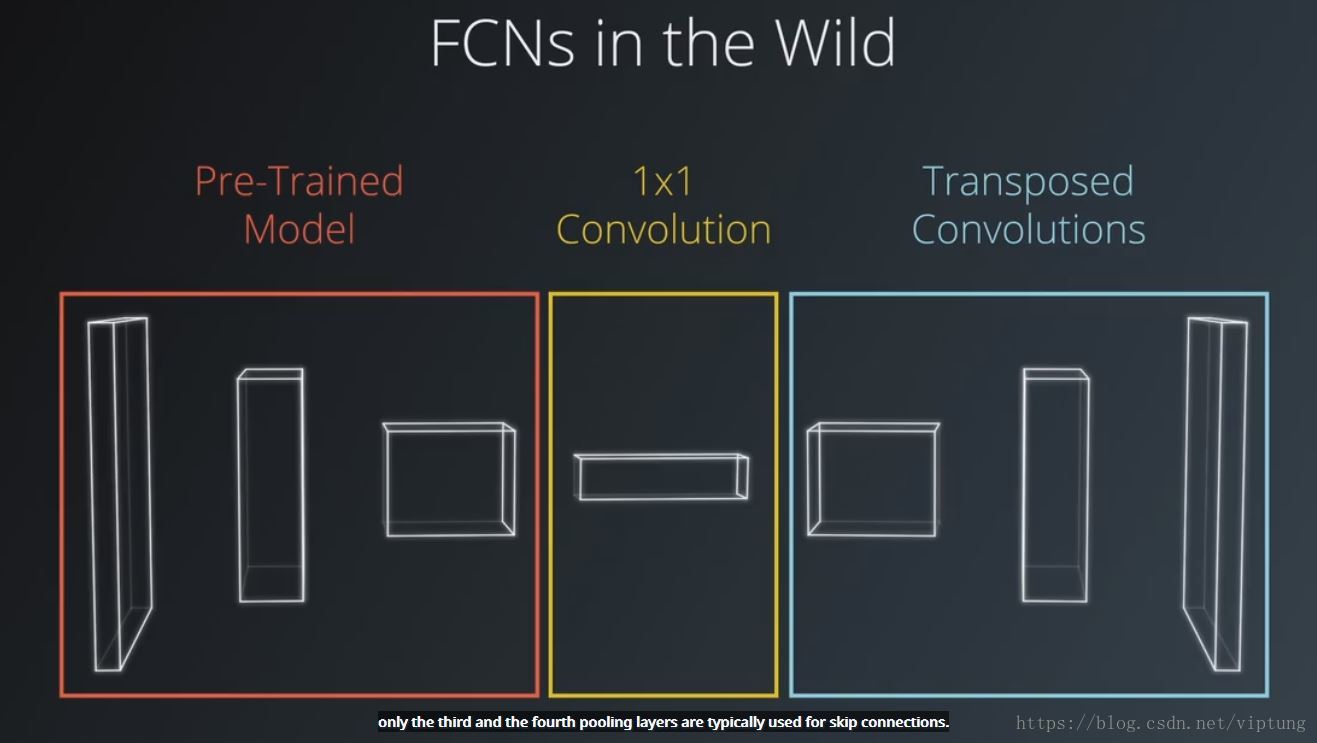
标题 FCNs:Fully Convolutional Networks
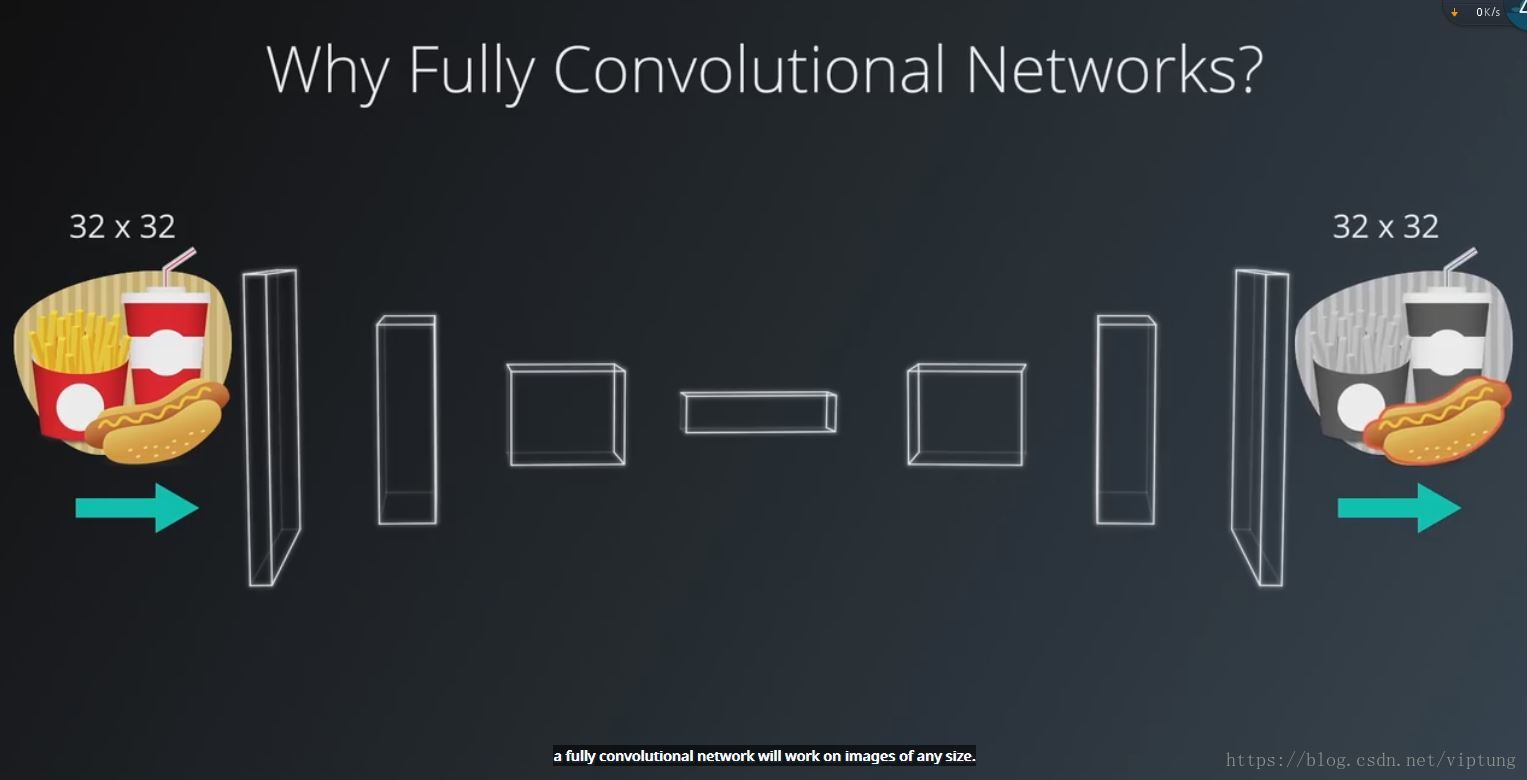
全卷积网络可用来做语义级别的图像分割以及对象检测,由encoder(vgg,resnet,预训练模型提取特征),decoder(实现每个像素的分割或预测)组成
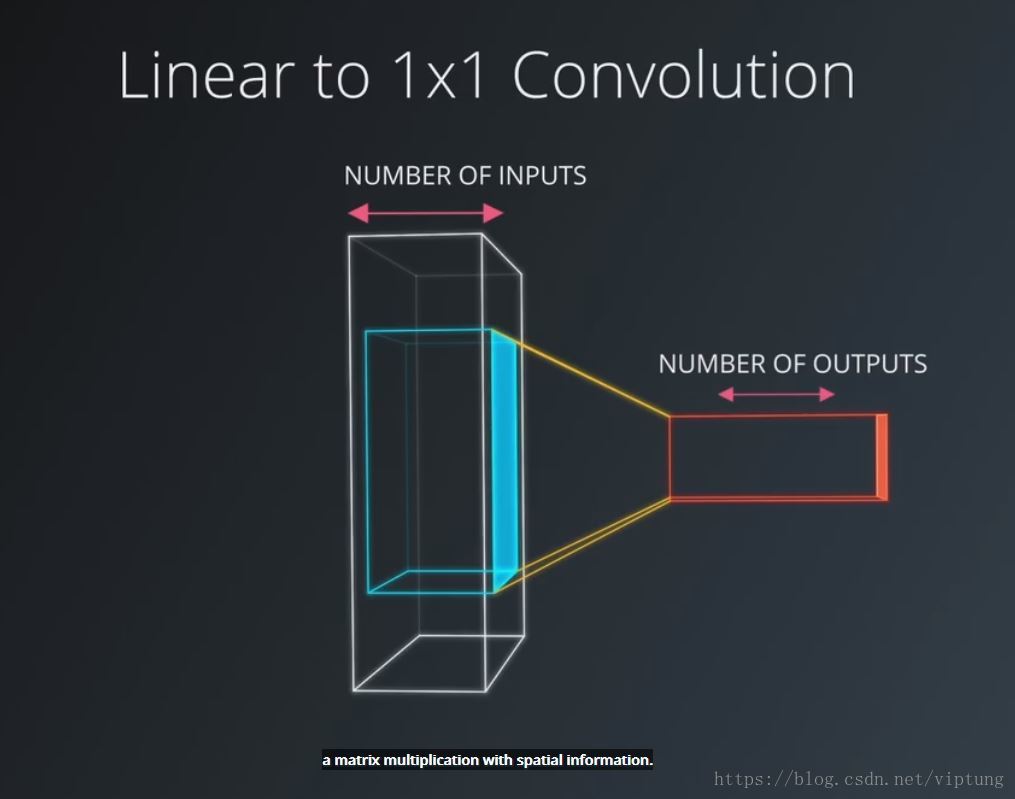
1x1 Convolution
保留空间信息
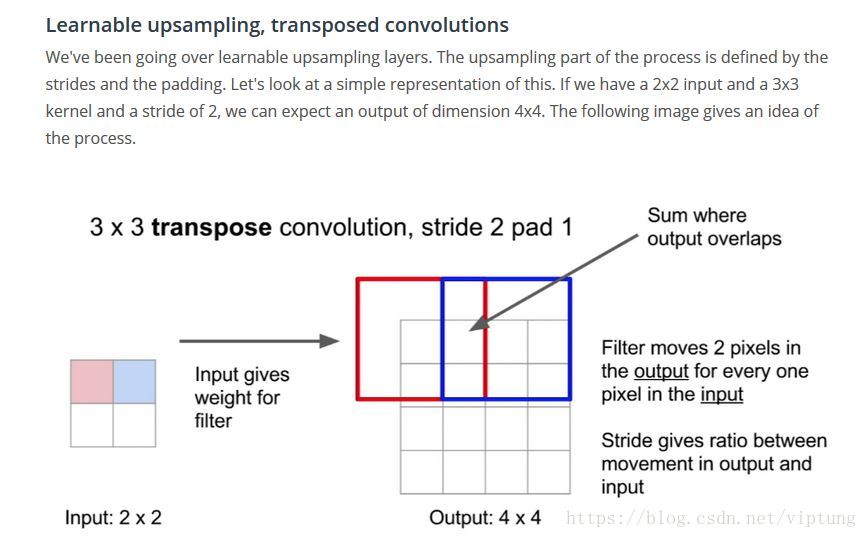
Transposed Convolutions
在decoder阶段调换前向传播和反向传播,保留了可微性Torch 模型文档

Methods of upsampling:Max “unpooling”

Learnable upsampling, transposed convolutions
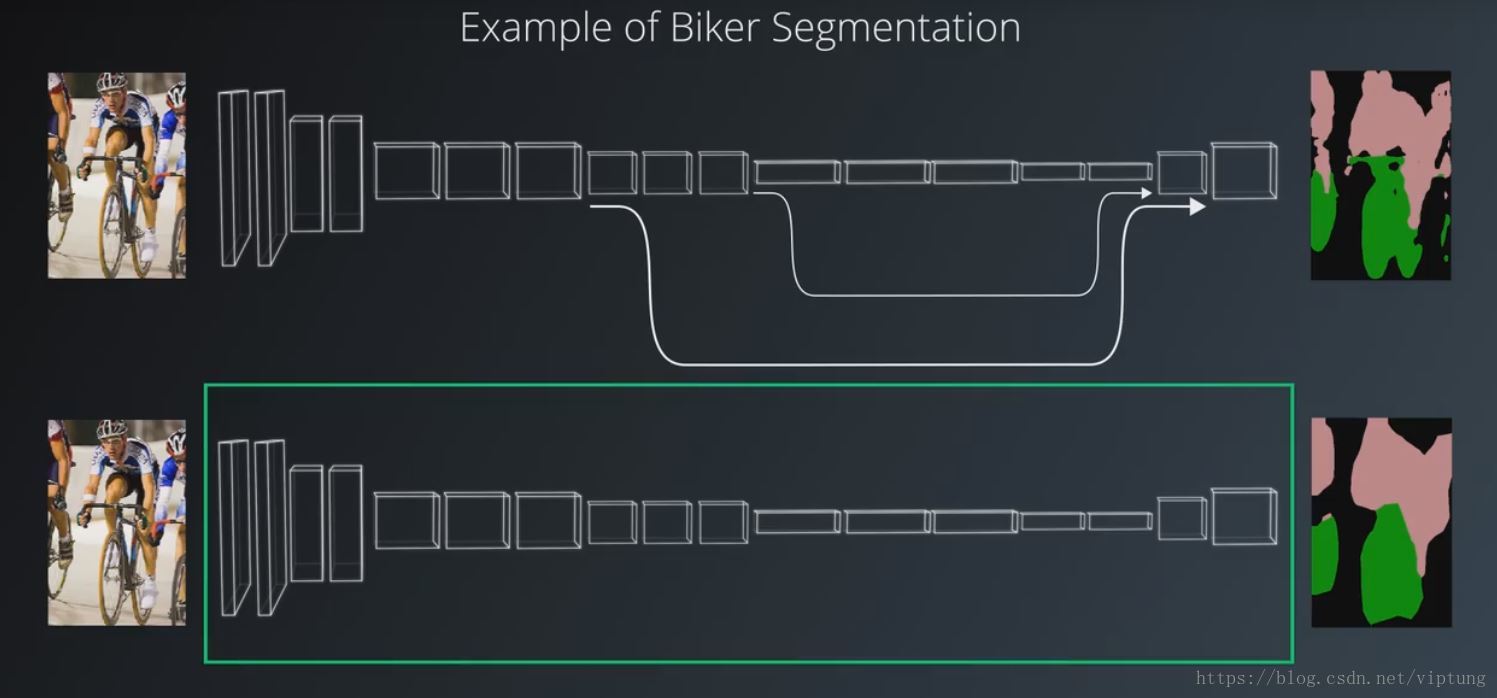
Skip Connect
从编码器中获得信息添加到解码器中作为输出,保证信息完备,但不可过度使用
完整模型:
下采样和上采样

对象检测:
一般使用SSD和Yolo即可检测并的边界位置,可适用于高FPS和多类别
但也有不能使用boundingbox的情况,就要用到语义分割了

语义分割:
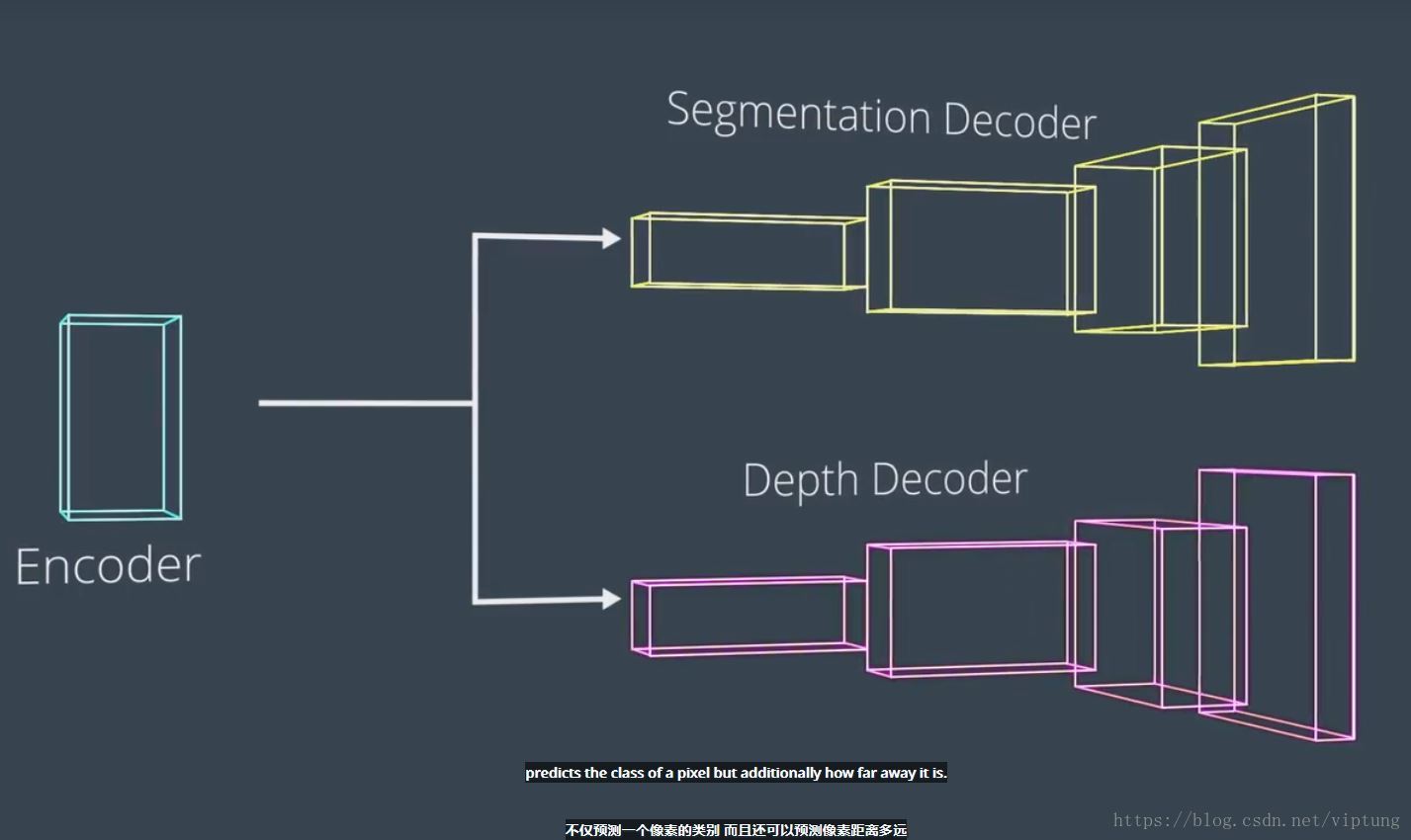
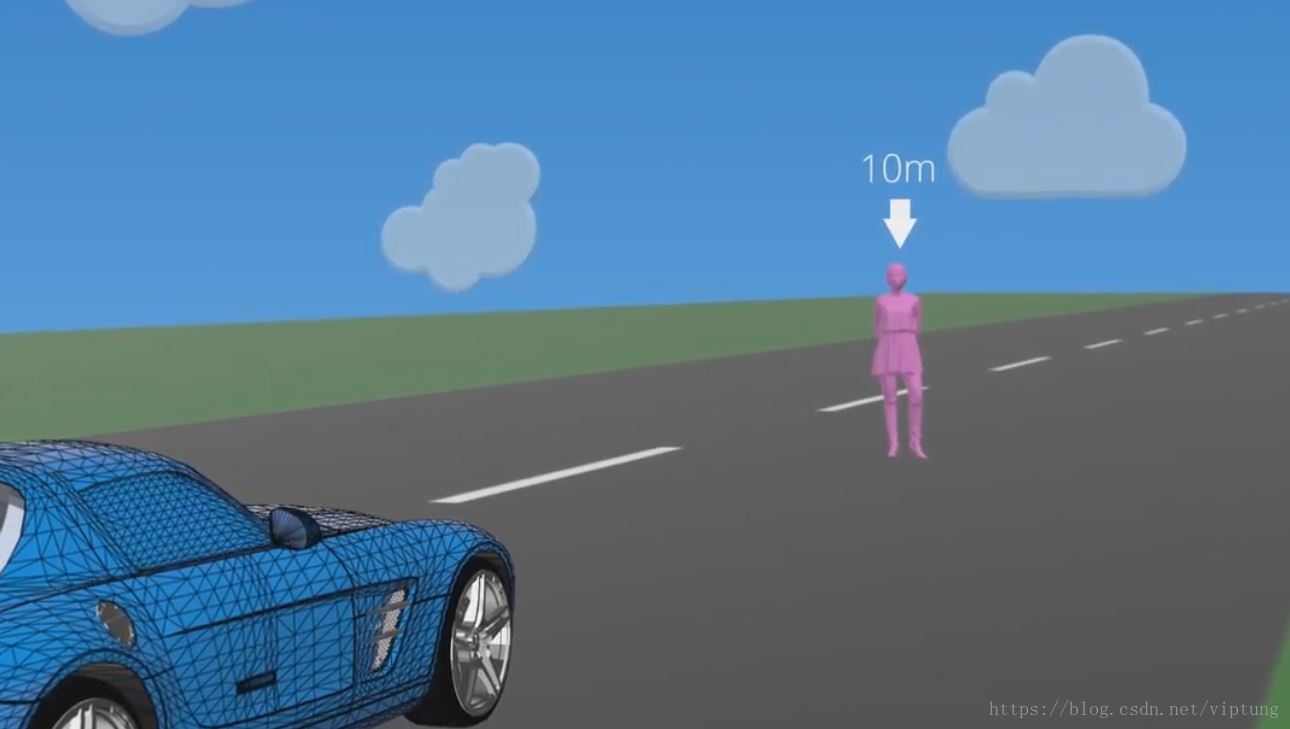
做到每一个像素的信息进行正确归类,有助于全场景理解,广泛应用于无人驾驶

同时结合深度的感知,实现3D场景的分割
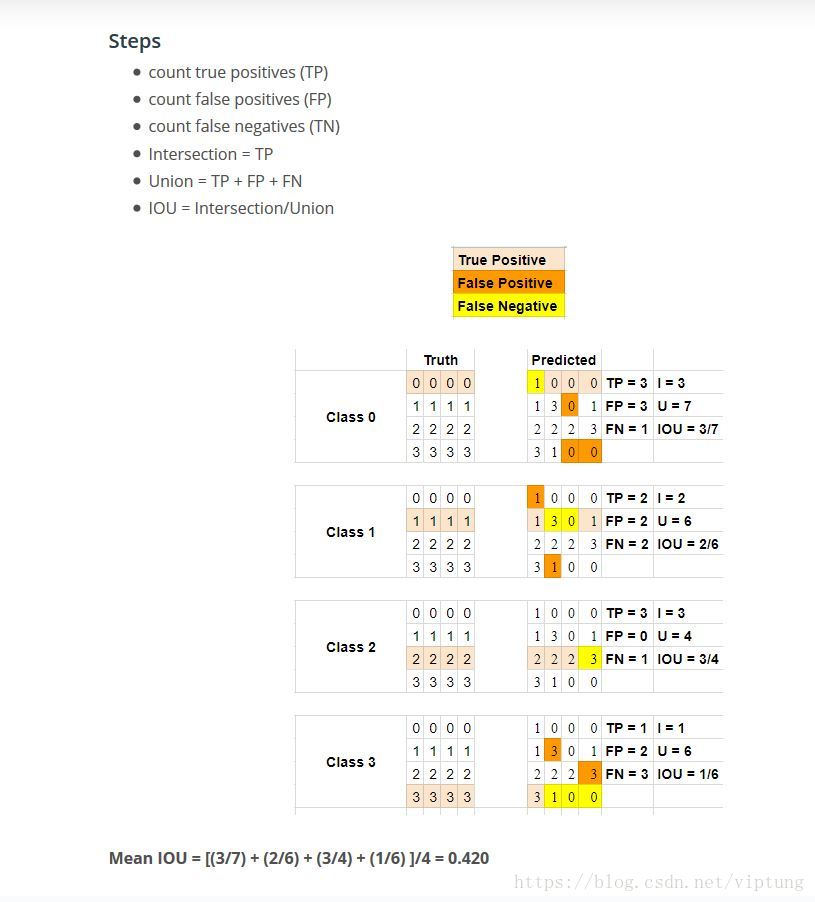
IoU
评价模型在语义分割任务上的性能
参考论文:
Fully Convolutional Networks for Semantic Segmentation














 461
461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









