







强化学习(Reinforcement Learning, RL)是机器学习的一种重要分支,它不同于传统的监督学习和无监督学习,而是通过让智能体(Agent)与环境(Environment)交互来学习一个策略,以最大化长期的回报。近年来,强化学习的应用越来越广泛,特别是在机器人控制、自动驾驶、游戏智能体和推荐系统等领域中。本文将深入介绍强化学习的理论背景、建模注意事项、调参方法、训练技巧,并给出一个完整的强化学习案例,帮助读者理解如何在实践中应用强化学习。
一、强化学习理论基础
1.1 强化学习的基本概念
强化学习涉及三个主要组成部分:
环境(Environment):系统的外部世界,智能体与环境交互并受到环境的反馈。
智能体(Agent):能够感知环境并做出决策的实体,目标是通过与环境的交互来最大化长期回报。
状态(State):环境在某一时刻的表现,智能体基于当前的状态作出决策。
动作(Action):智能体在某一状态下可以选择的行为。
奖励(Reward):环境对智能体的行为给予的反馈,智能体通过奖励信号来优化其策略。
策略(Policy):智能体选择动作的方式,通常是一个从状态到动作的映射。
价值函数(Value Function):用于评估某一状态或某一状态-动作对的价值,帮助智能体选择最佳策略。
回报(Return):智能体在一个时间步后累计的总奖励,通常用于衡量智能体的表现。
强化学习的目标是通过智能体不断与环境交互,找到一个最优策略,最大化长期的累计奖励。
1.2 马尔科夫决策过程(MDP)
强化学习通常假设环境能够通过马尔科夫决策过程(Markov Decision Process, MDP)来描述。MDP是一个五元组:(S,A,P,R,γ),其中:
S是状态空间(所有可能的状态的集合)。
A 是动作空间(所有可能的动作的集合)。
P 是状态转移概率,表示智能体执行某一动作后从一个状态转移到另一个状态的概率。
R 是奖励函数,表示智能体在某一状态-动作对下获得的即时奖励。
γ是折扣因子,用于权衡未来奖励与当前奖励的重要性。
通过这种方式,强化学习的目标是最大化智能体从当前状态开始,经过多个时间步的行动所获得的累计折扣奖励:
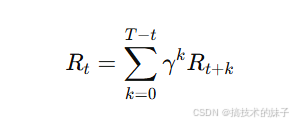
其中,Rt是从时间步 t开始的累计奖励,γ 是折扣因子,T是任务的最大时间步。
1.3 强化学习的核心任务
强化学习的核心任务是解决以下问题:
策略优化:通过与环境的交互,智能体学习到一个策略,使得在任意状态下采取的动作最大化期望回报。
价值评估:通过评估每个状态的价值或每个状态-动作对的价值,指导智能体的行为选择。
探索与利用的平衡:智能体在执行任务时需要平衡“探索”(尝试新的动作)和“利用”(选择已知的最佳动作)之间的权衡。
1.4 强化学习的算法分类
强化学习的算法主要可以分为以下几类:
值迭代方法(Value Iteration Methods):通过计算每个状态的价值,帮助智能体选择最优的动作。包括 Q-learning 和 SARSA。
策略梯度方法(Policy Gradient Methods):通过直接优化策略的参数来更新策略。包括 REINFORCE 和 Actor-Critic。
模型基方法(Model-Based Methods):构建环境模型,通过模拟环境来做决策,减少实际交互的需求。
深度强化学习(Deep Reinforcement Learning):结合深度学习和强化学习,使用神经网络来逼近复杂的价值函数或策略。
二、强化学习建模注意事项
在进行强化学习建模时,有几个关键注意事项需要特别关注:
2.1 状态和动作空间的设计
状态空间和动作空间的设计直接决定了问题的复杂度和模型的效果。对于大规模的任务,状态和动作的空间往往是巨大的,需要通过适当的设计来简化问题。以下是一些设计技巧:
**离散化:**对于连续的状态空间或动作空间,可以考虑通过离散化方法将其转化为离散的空间,方便处理。
**特征提取:**有时候原始状态空间过于庞大,需要通过特征提取来提取重要的特征,减少维度。
**动作限制:**为了减少动作空间的复杂度,可以设置一些动作的限制或约束条件。
2.2 奖励设计
奖励设计是强化学习建模中的一个挑战,奖励信号需要能够准确反映任务目标。以下是一些设计技巧:
**稀疏奖励:**对于许多任务,奖励信号可能非常稀疏,智能体可能很难获得即时反馈。可以通过设计合适的奖励函数,或使用技术如奖励塑造(Reward Shaping)来解决这个问题。
**延迟奖励:**在一些任务中,智能体的行为可能对最终结果产生延迟影响。需要设计长期奖励的计算方法,例如使用折扣因子(γ\gammaγ)来调整未来奖励的权重。
**负奖励:**通过对不良行为给予负奖励,来引导智能体避免错误行为。
2.3 探索与利用的平衡
在训练过程中,智能体需要平衡“探索”和“利用”之间的关系。常见的策略包括:
ε-贪婪策略(ε-greedy):以概率 ϵ随机选择一个动作,以概率 1−ϵ1 选择当前最优的动作。
软max策略:通过计算动作的概率分布来选择动作,而不是选择最优动作。
三、强化学习调参方法
在强化学习中,调参是训练过程中的重要步骤。以下是一些常见的调参技巧:
3.1 学习率(Learning Rate)
学习率决定了模型每次更新时的步长大小。过小的学习率会导致收敛速度过慢,而过大的学习率则可能导致训练不稳定或无法收敛。常见的做法是采用逐步衰减的学习率,以便在训练后期进行更精细的更新。
3.2 折扣因子(Discount Factor, γ)
折扣因子 γ\gammaγ 决定了未来奖励的权重。在短期任务中,通常选择较大的 γ\gammaγ,而在长期任务中,选择较小的 γ\gammaγ 可以使得模型更多考虑近期的奖励。
3.3 探索参数(Exploration Parameters)
探索策略(如ε-贪婪策略)的参数也需要进行调节。通常,在训练初期,增加探索(例如设置较大的 ϵ\epsilonϵ)可以帮助智能体更全面地了解环境,而在训练后期,减少探索(例如设置较小的 ϵ\epsilonϵ)可以帮助智能体利用已学到的知识。
四、强化学习训练方法
强化学习的训练通常采用以下几种方法:
4.1 基本的 Q-learning 训练方法
Q-learning 是一种无模型的值迭代方法。智能体通过学习 Q 值函数 Q(s,a)Q(s, a)Q(s,a) 来更新策略。训练过程通过以下公式来更新 Q 值:
Q(st,at)=Q(st,at)+α[rt+γmaxa′Q(st+1,a′)−Q(st,at)]Q(s_t, a_t) =
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3341
3341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











