






什么是激活函数
激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容。
在人工神经网络中,一个节点的激活函数定义了该节点在给定的输入或输入集合下的输出。标准的计算机芯片电路可以看作是根据输入得到开(1)或关(0)输出的数字电路激活函数。因此,激活函数是确定神经网络输出的数学方程式,
为什么引入非线性激励函数?
深度学习的前提是神经网络的隐层加上了非线性激活函数,提升了模型的非线性表达能力,使得神经网络可以逼近任意复杂的函数。假如有一个100层的全连接神经网络,其隐层的激活函数都是线性的,则从输入层到输出层实际上可以用一层全连接来等价替换,这样就无法实现真正的深度学习。举个简单的例子,线性函数 f(x)=2x+3 对 x 经过三次相同的线性变换等价于对 x 只进行一次线性变换:f(f(f(x)))=2(2(2x+3)+3)+3=8x+21。
常见的激活函数
Sigmoid 激活函数
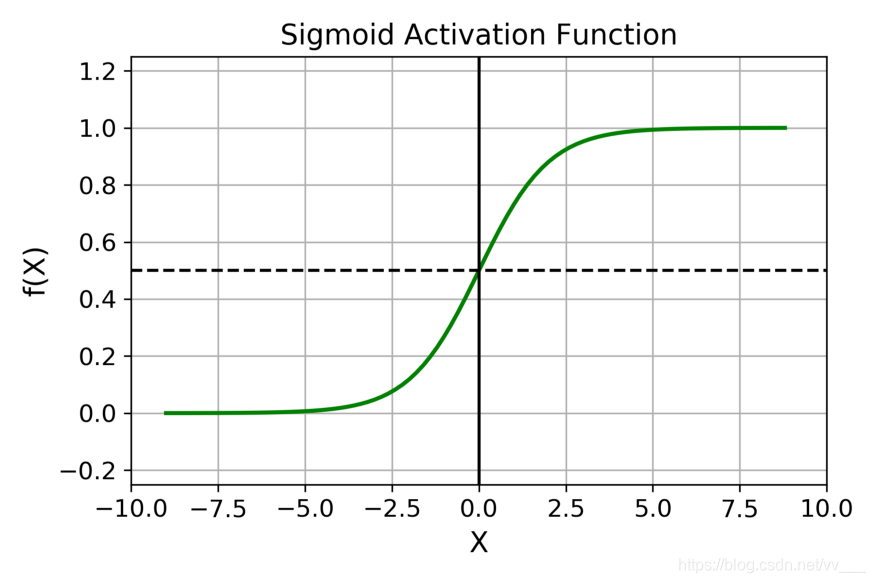
函数表达式为: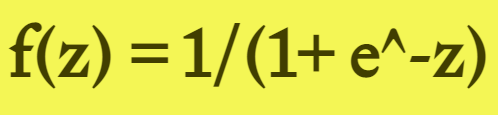
在什么情况下适合使用 Sigmoid 激活函数呢?
- Sigmoid 函数的输出范围是 0 到 1。由于输出值限定在 0 到 1,因此它对每个神经元的输出进行了归一化;
- 用于将预测概率作为输出的模型。由于概率的取值范围是 0 到 1,因此 Sigmoid 函数非常合适; 梯度平滑,避免「跳跃」的输出值;
- 函数是可微的。这意味着可以找到任意两个点的 sigmoid 曲线的斜率; 明确的预测,即非常接近 1 或 0。
Sigmoid 激活函数有哪些缺点?
- 倾向于梯度消失;
- 函数输出不是以 0 为中心的,这会降低权重更新的效率;
- Sigmoid 函数执行指数运算,计算机运行得较慢。
Tanh / 双曲正切激活函数
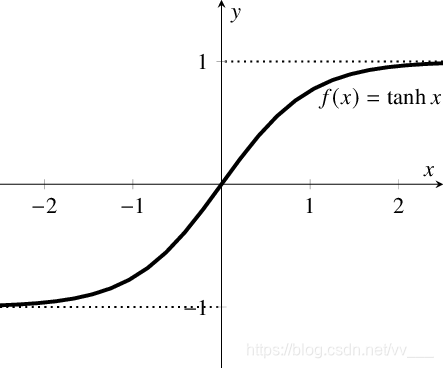

tanh 是一个双曲正切函数。tanh 函数和 sigmoid 函数的曲线相对相似。但是它比 sigmoid 函数更有一些优势。
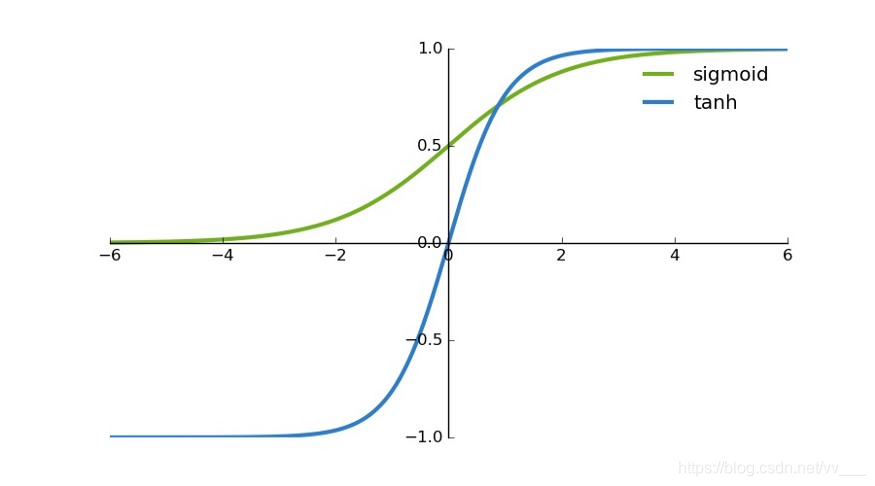
- 首先,当输入较大或较小时,输出几乎是平滑的并且梯度较小,这不利于权重更新。二者的区别在于输出间隔,tanh 的输出间隔为1,并且整个函数以 0 为中心,比 sigmoid 函数更好;
- 在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。
注意:在一般的二元分类问题中,tanh 函数用于隐藏层,而 sigmoid 函数用于输出层,但这并不是固定的,需要根据特定问题进行调整。
ReLU 激活函数
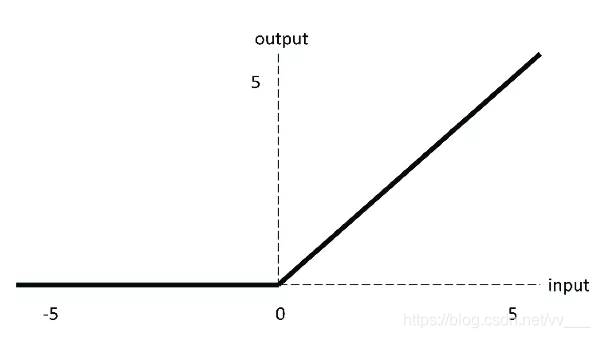
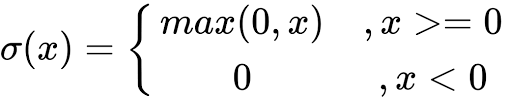
ReLU 函数是深度学习中较为流行的一种激活函数,相比于 sigmoid 函数和 tanh 函数,它具有如下优点:
当输入为正时,不存在梯度饱和问题。
计算速度快得多。ReLU 函数中只存在线性关系,因此它的计算速度比 sigmoid 和 tanh 更快。
当然,它也有缺点:
Dead ReLU 问题。当输入为负时,ReLU 完全失效,在正向传播过程中,这不是问题。有些区域很敏感,有些则不敏感。但是在反向传播过程中,如果输入负数,则梯度将完全为零,sigmoid 函数和 tanh 函数也具有相同的问题;
我们发现 ReLU 函数的输出为 0 或正数,这意味着 ReLU 函数不是以 0 为中心的函数。
Leaky ReLU
它是一种专门设计用于解决 Dead ReLU 问题的激活函数:
ReLU vs Leaky ReLU
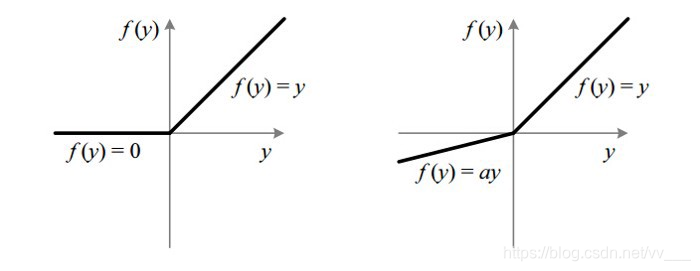
为什么 Leaky ReLU 比 ReLU 更好?
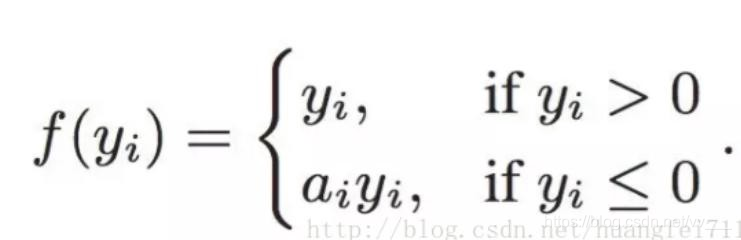
Leaky ReLU 通过把 x 的非常小的线性分量给予负输入(0.01x)来调整负值的零梯度(zero gradients)问题;
leak 有助于扩大 ReLU 函数的范围,通常 a 的值为 0.01 左右;
Leaky ReLU 的函数范围是(负无穷到正无穷)。
注意:从理论上讲,Leaky ReLU 具有 ReLU 的所有优点,而且 Dead ReLU 不会有任何问题,但在实际操作中,尚未完全证明 Leaky ReLU 总是比 ReLU 更好。
什么是梯度消失
在反向传播过程中需要对激活函数进行求导,如果导数大于1,那么随着网络层数的增加梯度更新将会朝着指数爆炸的方式增加这就是梯度爆炸。同样如果导数小于1,那么随着网络层数的增加梯度更新信息会朝着指数衰减的方式减少这就是梯度消失。因此,梯度消失、爆炸,其根本原因在于反向传播训练法则,属于先天不足。
刚有提到sigmoid激活函数可能出现的梯度消失,就是因为其输出范围属于0-1的范围内,因此很容易就会出现梯度消失现象。
如何解决梯度消失or梯度爆炸
- 预训练加微调
- 梯度剪切
- relu、leakrelu、elu等激活函数
- batch normalization
- 残差结构
参考文献:














 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









