










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:
Python语言、Flask框架、数据分析、LSTM预测算法、Echarts可视化、HTML、requests爬虫、雪球网数据、股价预测、keras、深度学习、神经网络
2、项目界面
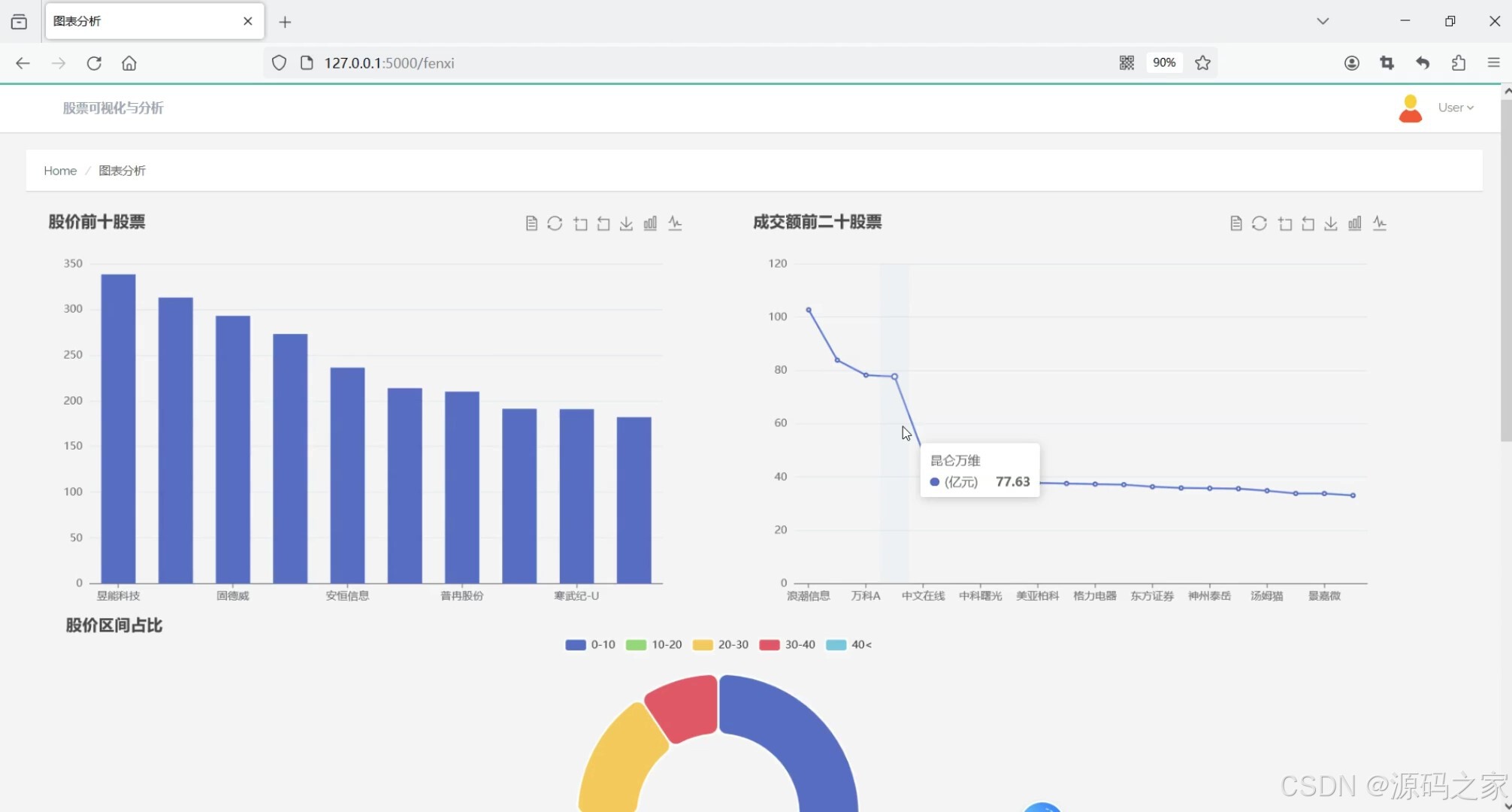
(1)股票数据可视化分析—股价前10、成交额前20、股价区间占比分析
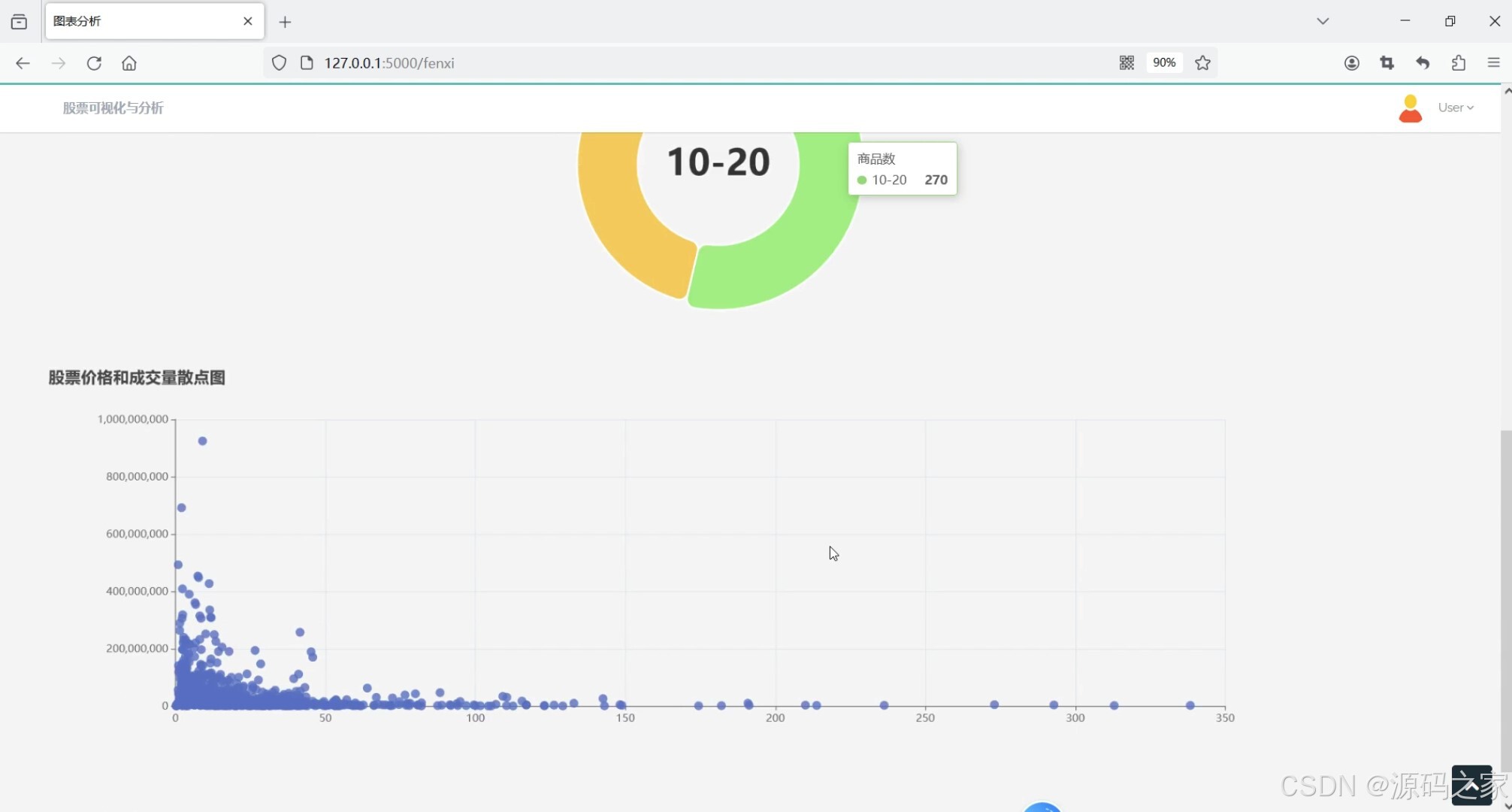
(2)股票数据可视化分析—股价和成交量散点图
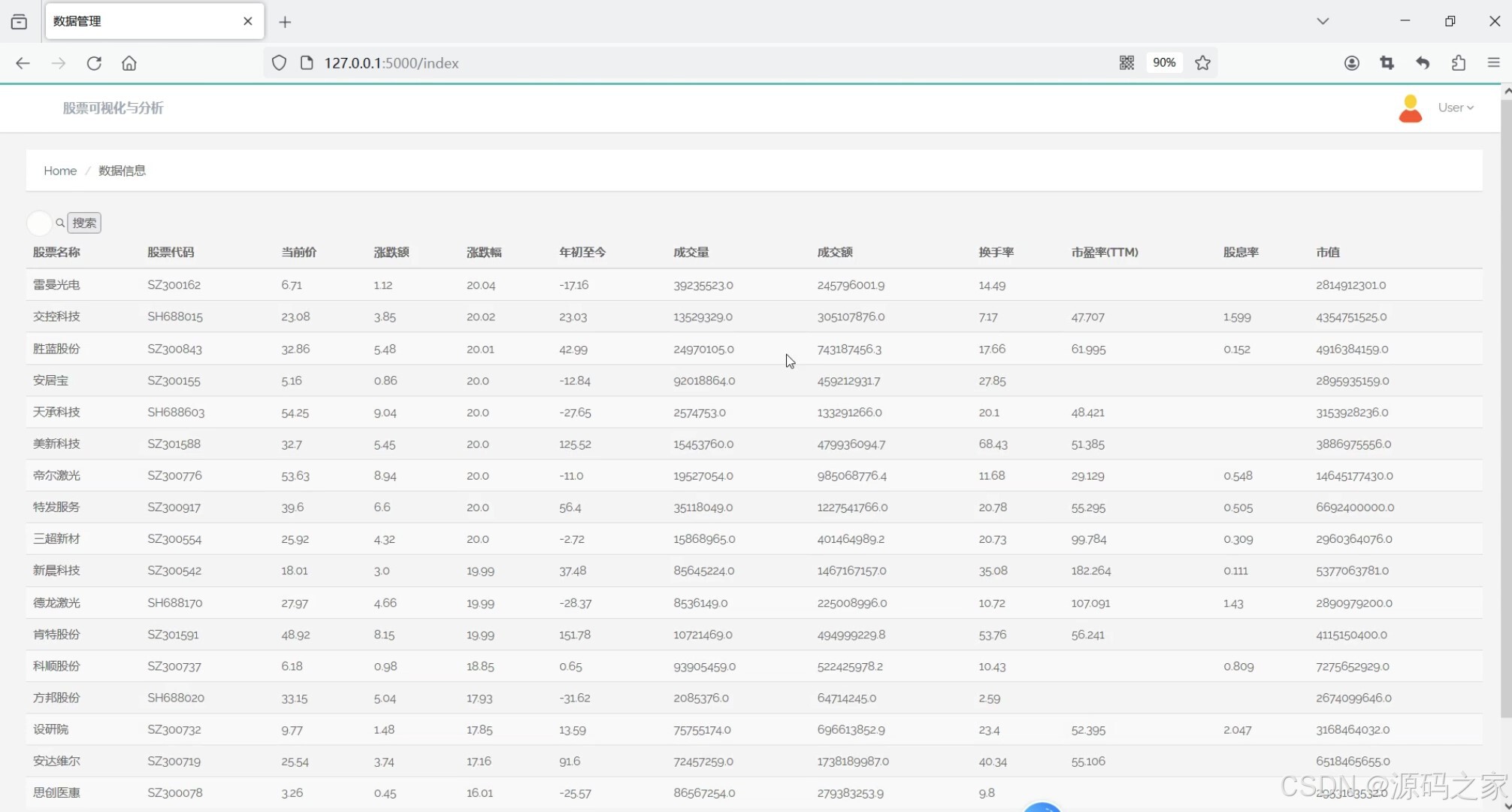
(3)股票数据中心
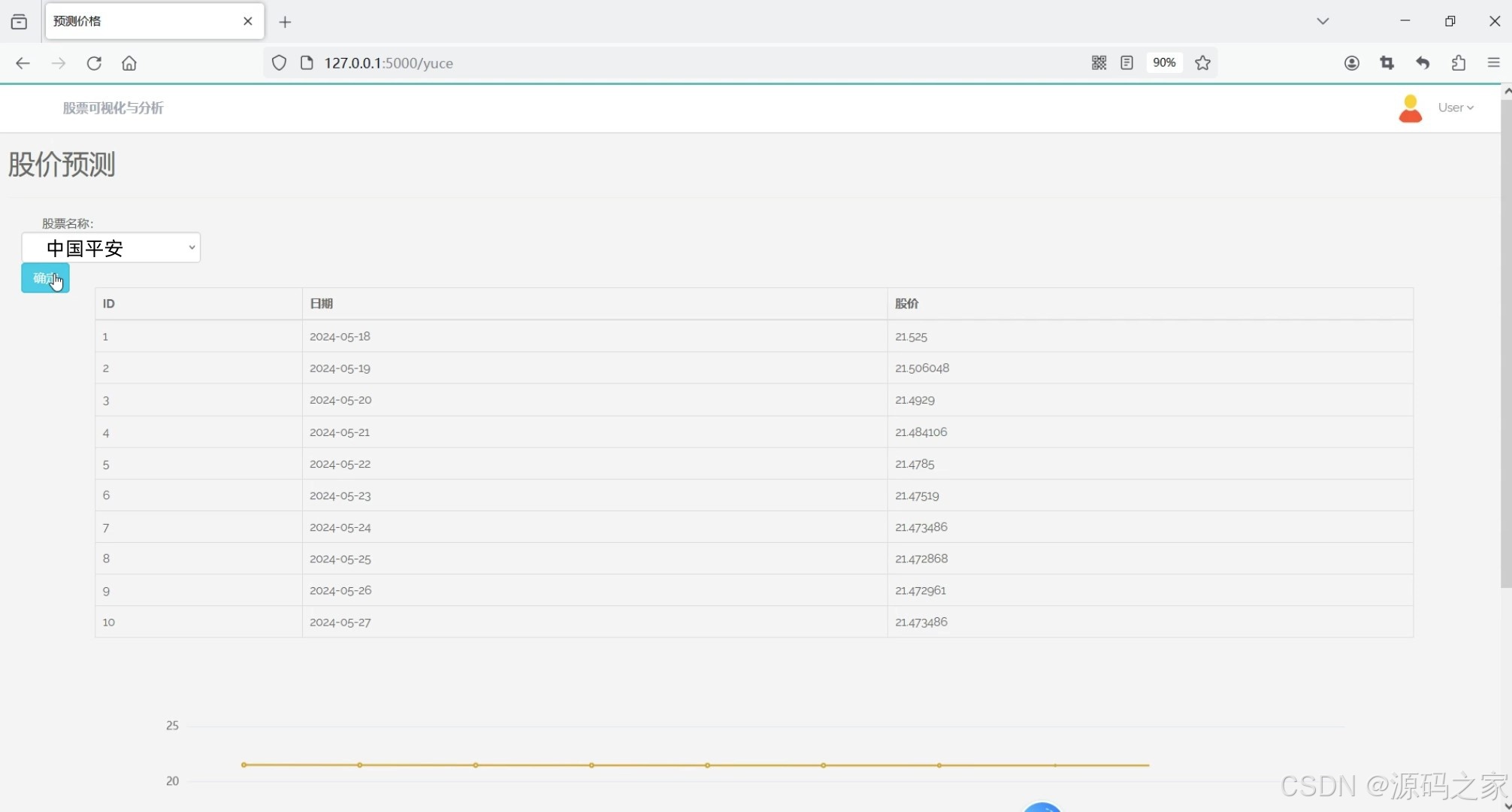
(4)股票价格预测—LSTM预测算法
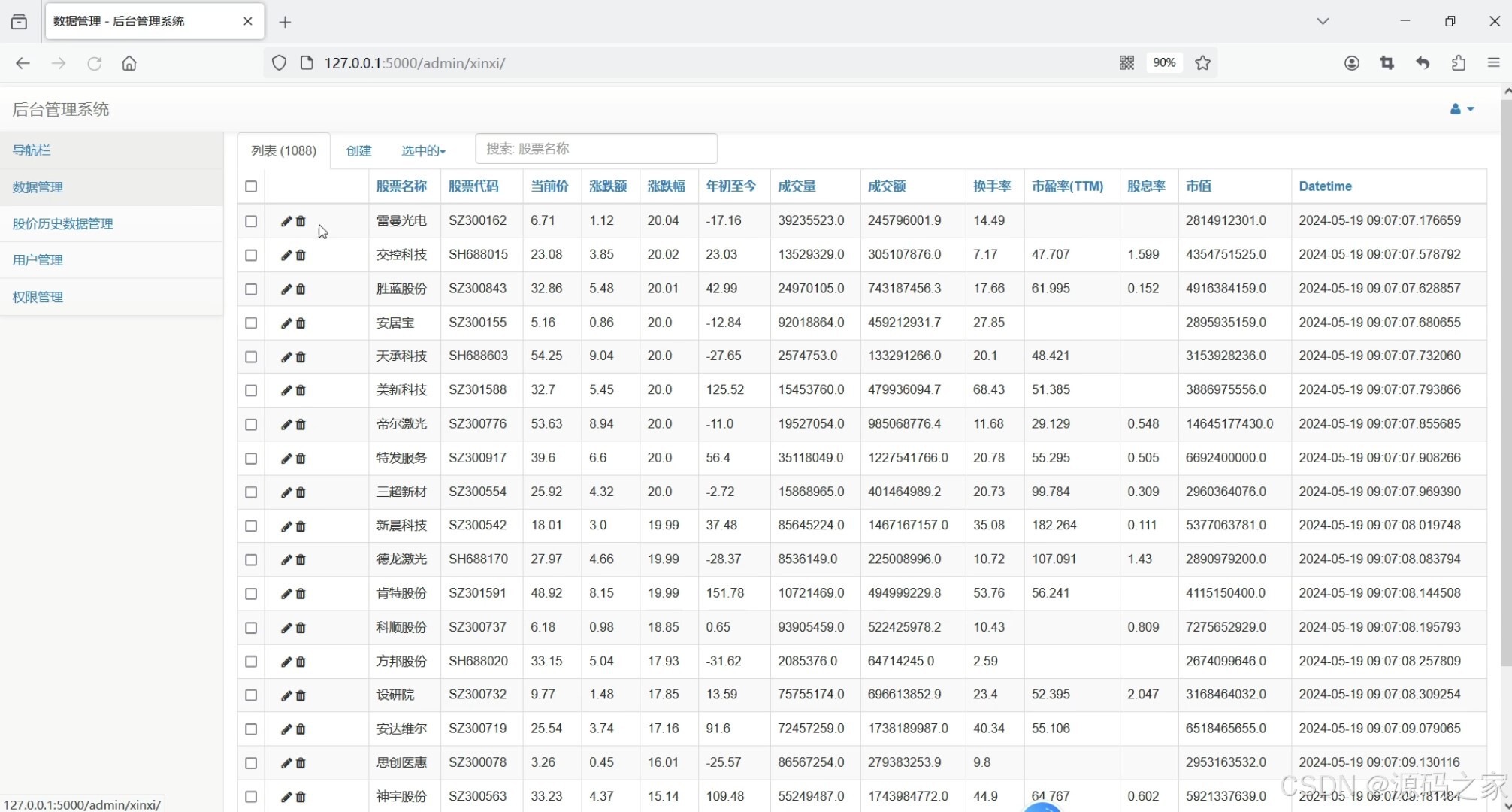
(5)后台数据管理
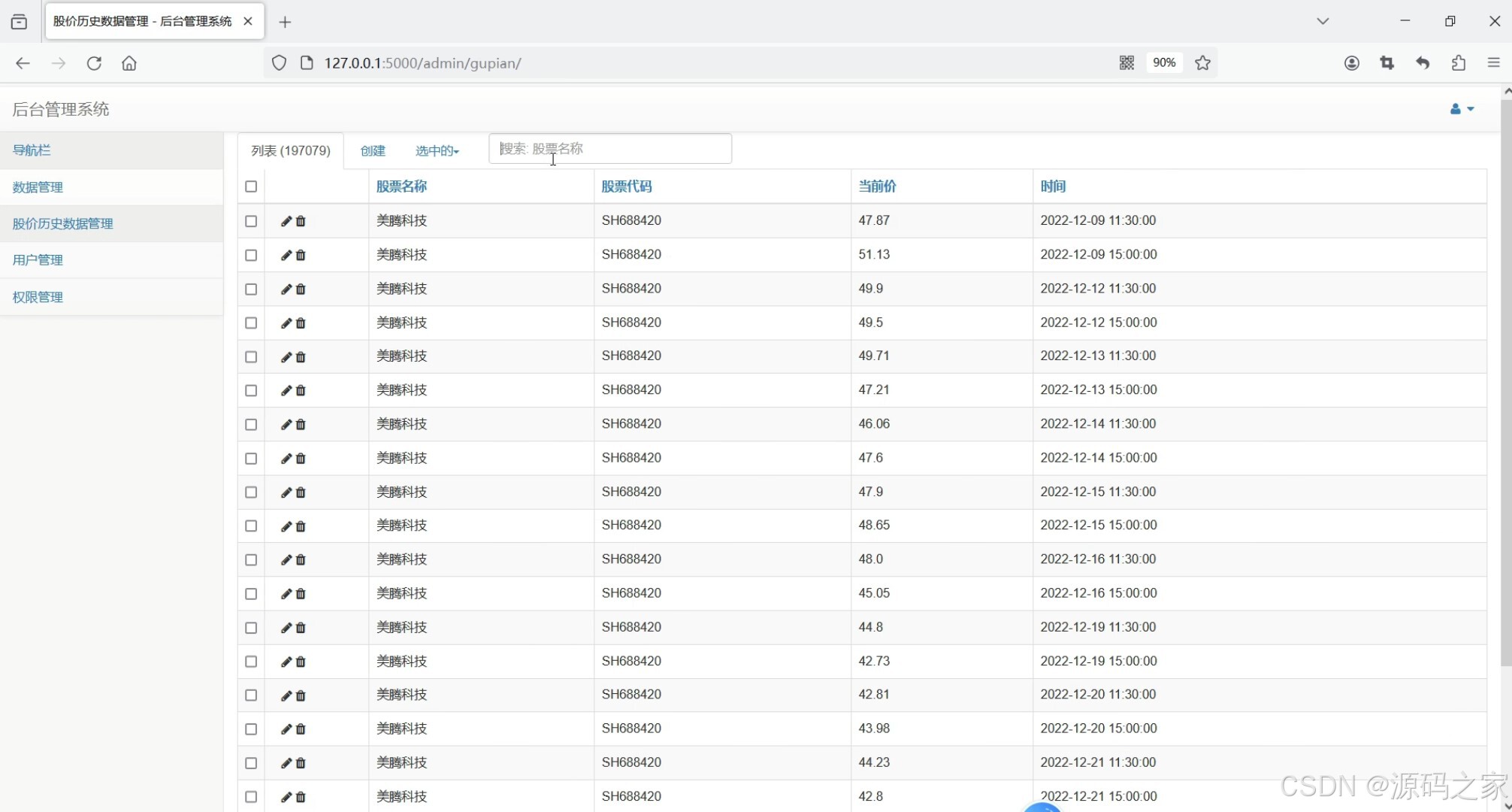
(6)股价历史数据管理(19万数据)
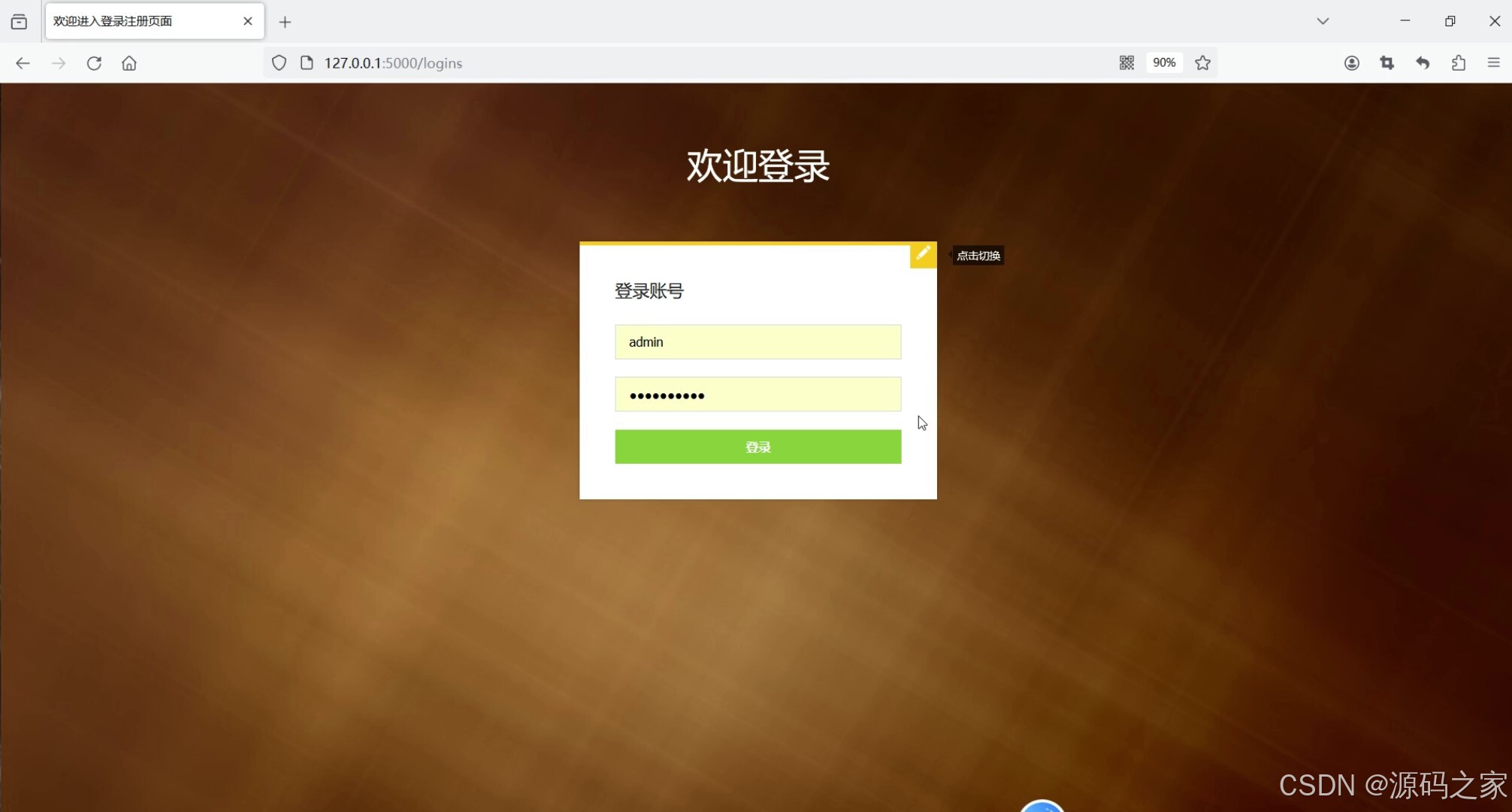
(7)注册登录
3、项目说明
1. 股票数据可视化分析——股价前10、成交额前20、股价区间占比分析
- 功能描述:通过可视化图表展示股票的关键数据指标。
- 特点:
- 股价前10:展示当前股价最高的前10支股票。
- 成交额前20:展示成交额最高的前20支股票。
- 股价区间占比分析:通过饼图展示不同股价区间的股票占比。
- 使用Echarts实现动态交互式图表,提升用户体验。
2. 股票数据可视化分析——股价和成交量散点图
- 功能描述:通过散点图展示股票的股价与成交量的关系。
- 特点:
- 使用散点图直观展示股价与成交量的分布关系。
- 支持按时间段筛选数据,以观察不同时间段的变化趋势。
- 提供回归分析功能,帮助用户理解股价与成交量的相关性。
3. 股票数据中心
- 功能描述:提供股票数据的详细查询和管理功能。
- 特点:
- 整合了股票的详细信息,如股票代码、名称、当前价格、成交额、涨跌幅等。
- 支持按条件筛选数据,如股票代码、行业、价格区间等。
- 提供数据导出功能,方便用户进行进一步分析。
4. 股票价格预测——LSTM预测算法
- 功能描述:使用LSTM(长短期记忆网络)算法预测股票价格。
- 特点:
- 数据采集:通过
requests爬虫技术从雪球网等金融数据源获取历史数据。 - 模型训练:使用LSTM模型对历史数据进行拟合和训练。
- 预测功能:预测未来几天的股票价格。
- 可视化展示:以折线图形式展示预测结果与历史数据的对比。
- 数据采集:通过
5. 后台数据管理
- 功能描述:提供数据的管理功能,包括数据的增删改查。
- 特点:
- 支持管理员对股票数据进行管理。
- 提供数据导入和导出功能,方便数据备份和更新。
- 支持用户权限管理,确保数据安全。
6. 股价历史数据管理(19万数据)
- 功能描述:管理股票的历史数据,支持大数据量的存储和查询。
- 特点:
- 支持存储和管理大量的历史数据(如19万条数据)。
- 提供高效的数据查询功能,支持按时间段、股票代码等条件筛选数据。
- 提供数据统计功能,如计算历史平均价格、最大值、最小值等。
7. 注册登录
- 功能描述:提供用户注册和登录功能。
- 特点:
- 支持用户通过用户名和密码进行登录。
- 注册时需要填写必要的用户信息,如用户名、密码、邮箱等。
- 提供用户信息管理功能,方便用户修改个人信息。
4、核心代码
#!/usr/bin/env python
# coding: utf-8
import numpy as np # 导入库numpy用于数据格式化操作
import pandas as pd # 导入数据分析库pandas
import models
import datetime
def yuce(name='美腾科技'):
# 1.1读取源数据
df = models.GuPian.query.filter(models.GuPian.name=='美腾科技').order_by(models.GuPian.datetime).all()
# 2.训练模型前的准备:数据预处理
# 2.1格式转换为pandas的DataFrame
list1 = []
current = 0
new_data = pd.DataFrame(index=range(0, len(df)+10), columns=['Date','Close'])
for i in range(0, len(df)):
new_data['Date'][i] = df[i].datetime.strftime('%Y-%m-%d')
new_data['Close'][i] = df[i].current
start_date = df[i].datetime
current = df[i].current
count = 1
for i in range(len(df),len(df)+10):
new_data['Date'][i] = (start_date + datetime.timedelta(days=count)).strftime('%Y-%m-%d')
new_data['Close'][i] = current
list1.append((start_date + datetime.timedelta(days=count)).strftime('%Y-%m-%d'))
count += 1
print(new_data)
# 2.2为其设置索引
new_data.index = new_data.Date
# 2.3删除Date数据(只使用Close数据)
new_data.drop('Date', axis=1, inplace=True)
# 2.4创建训练和验证集(数据集的划分)
dataset = new_data.values
train = dataset[0:len(df), :] # 将最开始的数据作为训练集
valid = dataset[len(df):, :] # 之后的所有数据设置为验证集
# 2.5使用MinMaxScaler将数据的范围压缩至0到1之间,这么做的目的是为了防止数值爆炸
# (LSTM模型的计算中,时间步长越大,结果所迭代的次数就越多;如1.1的100次方为13 780.61233982,所以使用scaler()函数是必要的)
from sklearn.preprocessing import MinMaxScaler # 从sklearn.preprocessing库中导入MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(dataset) # 传入dataset,将其用scaler()函数正则化后命名为scaled_data
#2.6 用数组表现数据的时间序列特性,步长设置为60
x_train, y_train = [], [] # 创建x_train, y_train
for i in range(60, len(train)): # 循环结构,i的值分别为60,61,……直至train的长度(1500)
x_train.append(scaled_data[i - 60:i, 0]) # 将scaled_data中的数据传递到x_train中(60个为一组)
y_train.append(scaled_data[i, 0]) # 将scaled_data中的数据传递到y_train中(从第60开始,每1个数据为一组)
x_train, y_train = np.array(x_train), np.array(y_train) # 使用numpy库中的array()函数将列表x_train和y_train格式化为数组(可以理解为矩阵)
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1)) # 使用numpy库中的reshape()函数改变数组x_train的形状
# 上述的步骤将训练集的格式从列表(list)变成时间步长为60的时间序列(表现为数组)
# 3.模型的参数设置
# 3.1导入神经网络需要的包
from keras.models import Sequential # 从keras.models库中导入时间序列模型Sequential
from keras.layers import Dense, LSTM # 从keras.layers库中导入Dense, Dropout, LSTM用于构建神经网络
# 3.2创建LSTM神经网络
model = Sequential()
# 第一层网络设置
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1], 1)))
# unit 决定了一层里面 LSTM 单元的数量。这些单元是并列的,一个时间步长里,输入这个层的信号,会被所有 unit 同时并行处理,形成若干个 unit 个输出。这个设置50个单元
# return_sequence参数表示是否返回LSTM的中间状态,这里设置为TRUE,返回的状态是最后计算后的状态
# input_shape参数包含两个元素的,第一个代表每个输入的样本序列长度,这里是x_train.shape[1],表示x_train数组中每一个元素的长度即时间步长,这里先前设置为了60
# 第二个元素代表每个序列里面的1个元素具有多少个输入数据(这里是1表示只有1个数据:时间)
# 第二层神经网络,设置50个LSTM单元
model.add(LSTM(units=50))
# 第三层为全连接层
model.add(Dense(1))
# 4.模型训练
model.compile(loss='mean_squared_error', optimizer='adam') # 设置损失函数compile()参数
# loss参数指标使用MSE(均方根误差) ,optimizer参数设置优化器为AdamOptimizer(自适应矩估计,梯度下降的一种变形)
model.fit(x_train, y_train, epochs=1, batch_size=1, verbose=2) # 传入数据开始训练模型
# 5.预测
#用过去的每60个数据预测接下来的数据(时间步长为60)
#5.1获取测试集数据,该步骤思路一样,这里不再赘述
inputs = new_data[len(new_data) - len(valid) - 60:].values
inputs = inputs.reshape(-1, 1)
inputs = scaler.transform(inputs)
X_test = []
for i in range(60, inputs.shape[0]):
X_test.append(inputs[i - 60:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
#5.2获取模型给出的预测值
closing_price = model.predict(X_test)
# 用scaler.inverse()函数将数据重新放大(因为之前使用了scaler()函数对数据进行了压缩)
closing_price = scaler.inverse_transform(closing_price)
# print(closing_price)
dicts = []
for i,resu in enumerate(closing_price):
dicts1 = {}
dicts1['riqi'] = list1[i]
dicts1['shuju'] = resu[0]
dicts.append(dicts1)
return dicts
# print(yuce())
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









