










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:
python语言、Flask框架、SQLite数据库、Echarts可视化、深度学习 tensorflow框架 lstm模型
股票市场行情分析与预测是数据分析领域里面的重头戏,其符合大数据的四大特征:交易量大、频率高、数据种类多、价值高。
本项目基于 Python 利用网络爬虫技术从某财经网站采集上证指数、创业板指数等大盘指数数据,以及个股数据,
同时抓取股票公司的简介、财务指标和机构预测等数据,并进行 KDJ、BOLL等技术指标的计算,构建股票数据分析系统,前端利用echarts进行可视化。 基于深度学习算法实现股票价格预测,为投资提供可能的趋势分析。
功能模块:
一、用户模块
1.用户注册
2.用户登录
3.用户找回密码
4.基本信息修改
二、股票系统模块
1.股票数据实时获取
2.股票预测LSTM
3.多种股票对比分析
4.行情可视化
5.股票组合投资建议
6.历史股票走势可视化
2、项目界面
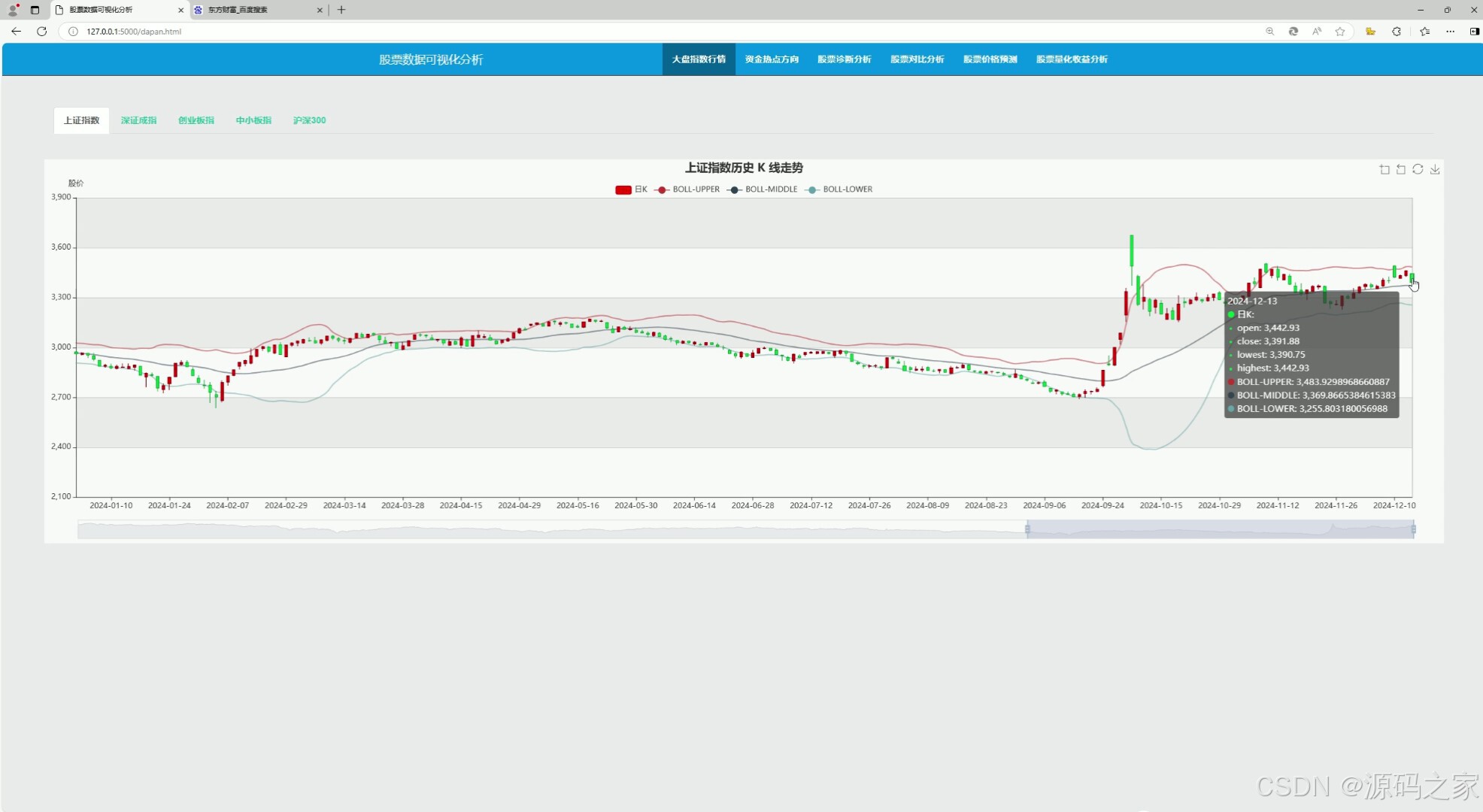
(1)大盘行情分析
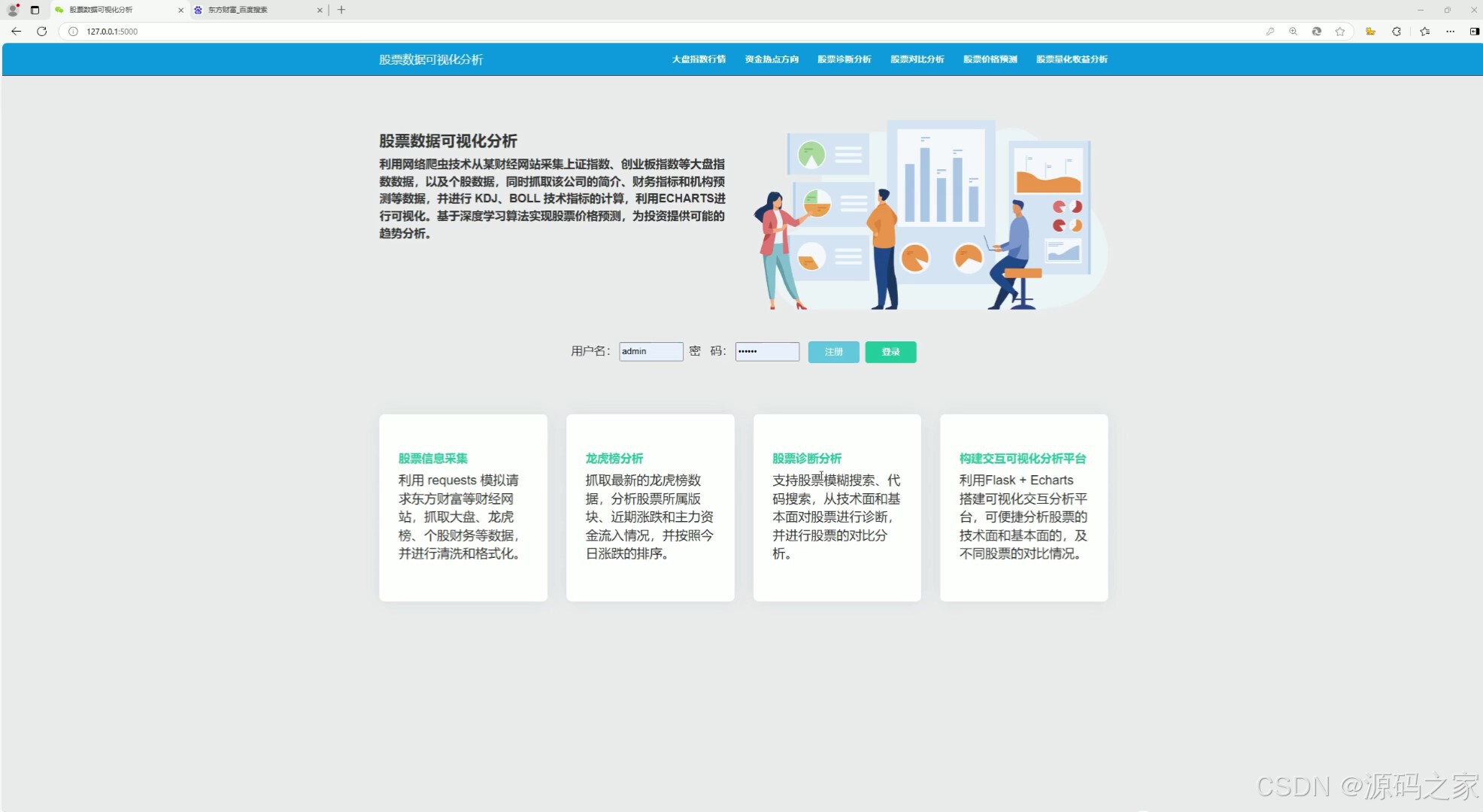
(2)注册登录界面
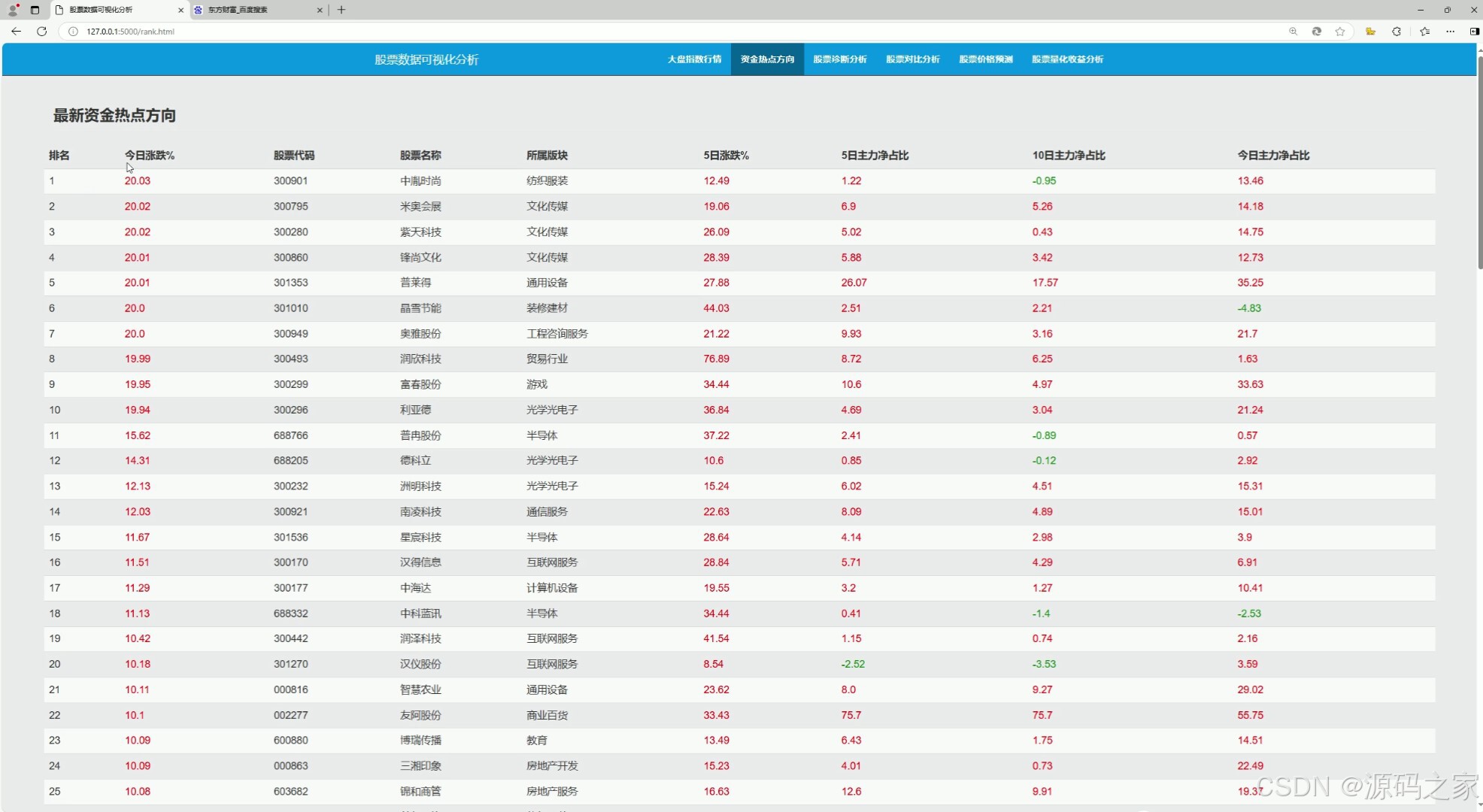
(3)资金热点方向
(4)资金诊断分析----技术面和基本面

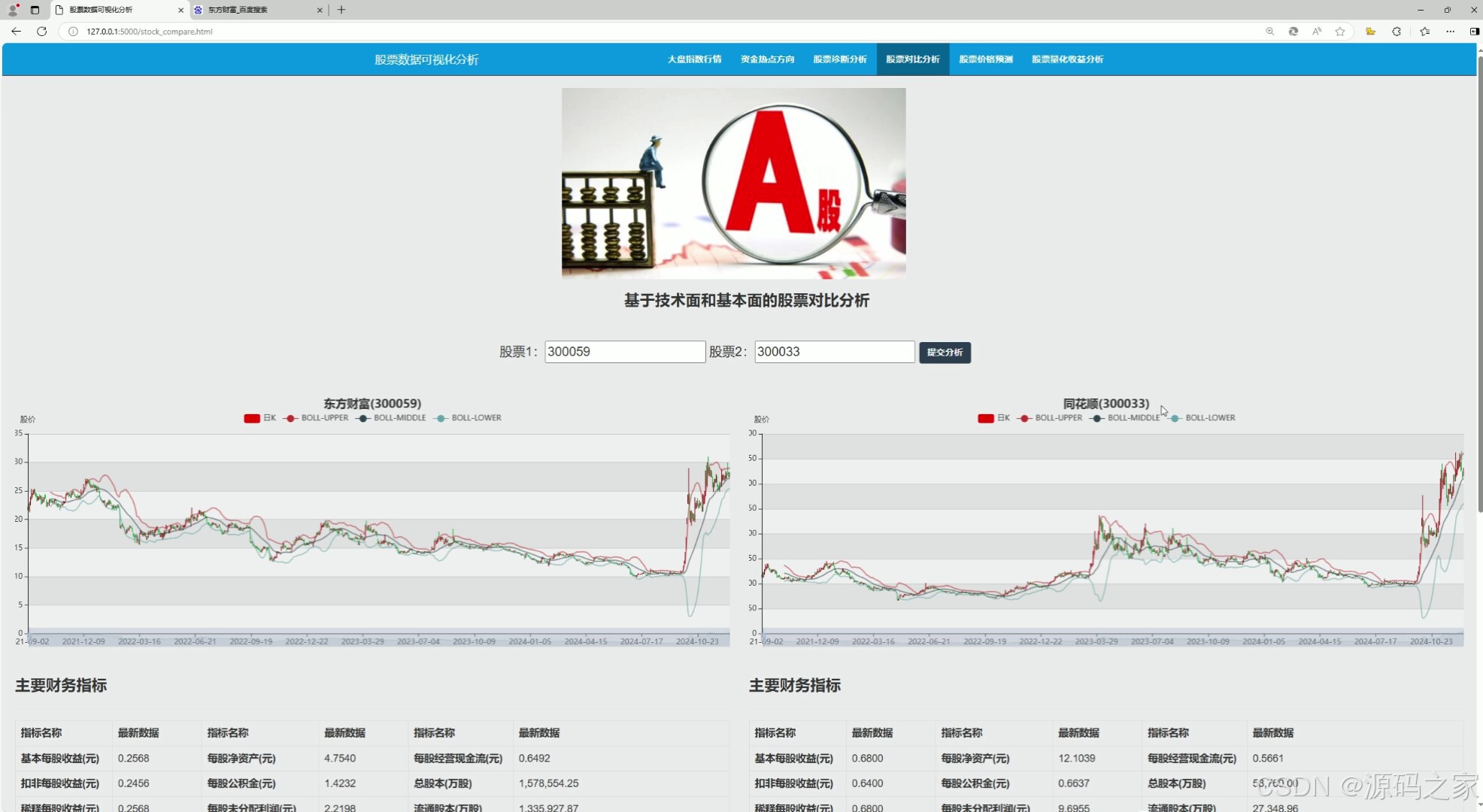
(5)股票对比分析----技术面和基本面对比
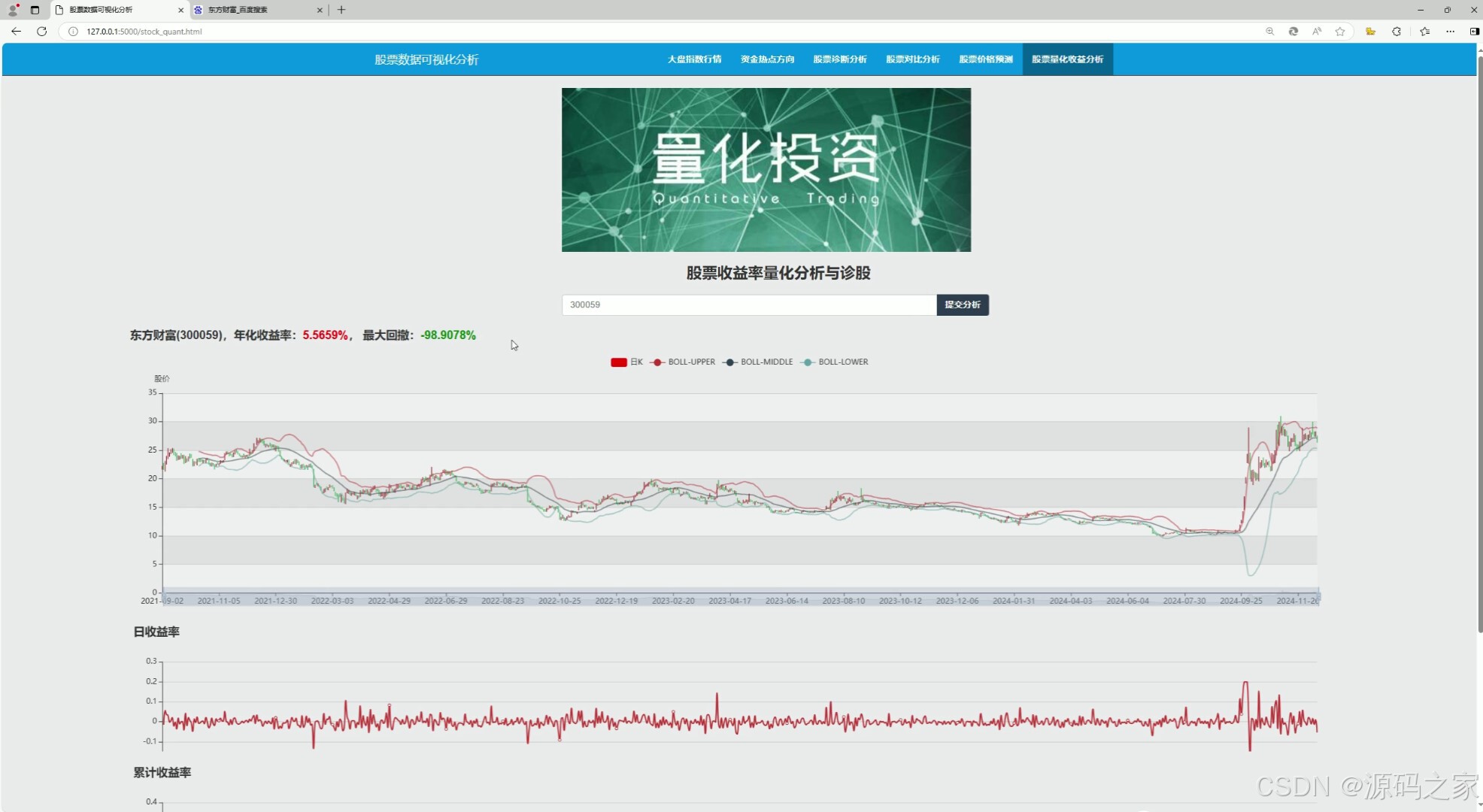
(6)股票量化收益分析----股票收益率量化分析与诊股
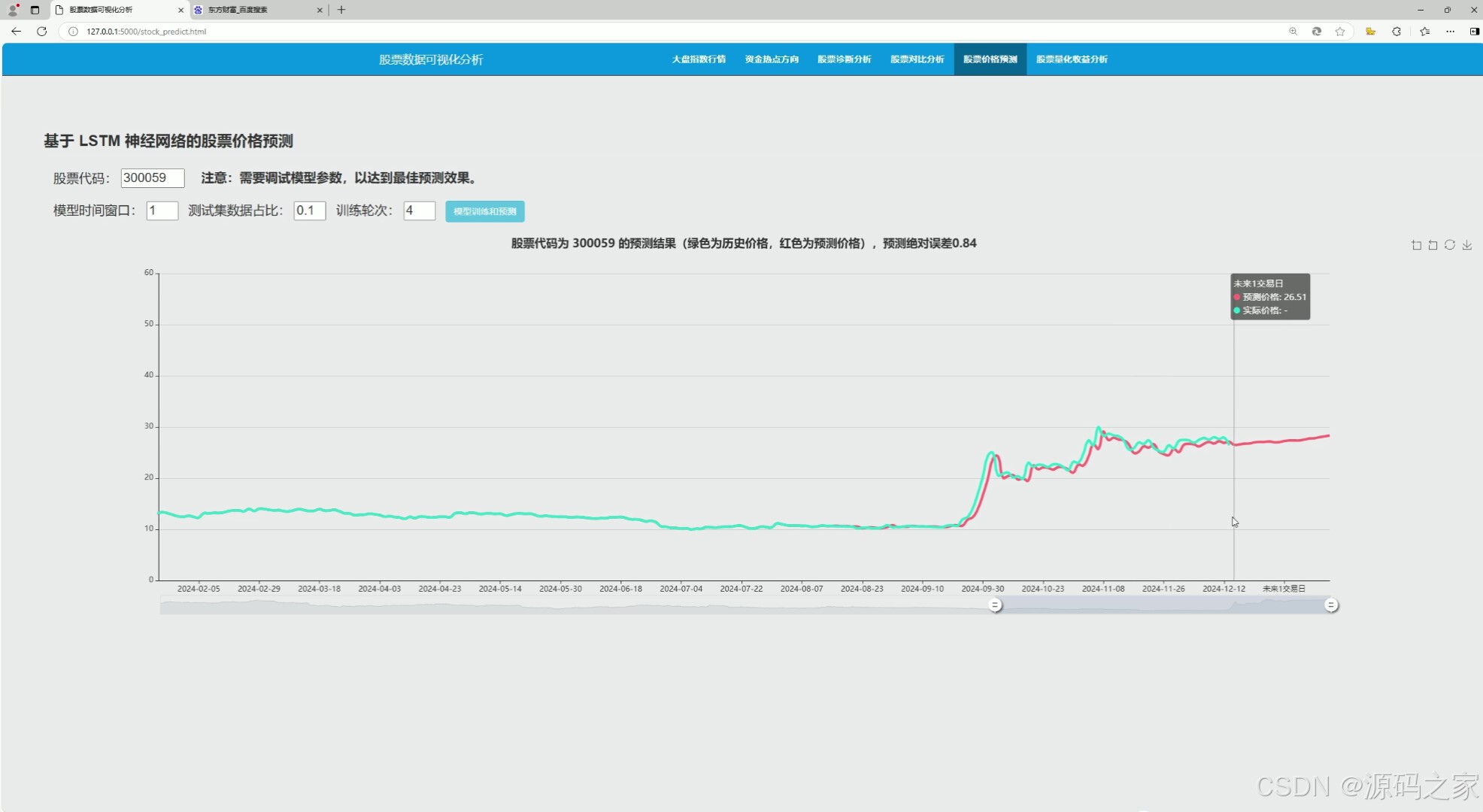
(7)股票价格预测----LSTM神经网络预测(输入模型时间窗口、测试集数据占比、训练轮次)
3、项目说明
(1)大盘行情分析
大盘行情分析模块通常用于展示股票市场的整体走势和趋势。它可能包括以下内容:
- 指数走势:显示主要股票指数(如上证指数、深成指、创业板指等)的实时走势和历史走势。
- 市场情绪指标:如涨跌停家数、涨跌比、换手率等,帮助投资者了解市场的活跃度和投资者情绪。
- 板块表现:展示不同行业板块的涨跌情况,帮助投资者发现热点板块。
- 资金流向:分析大盘资金的流入流出情况,判断市场的资金动向。
(2)注册登录界面
这是用户进入系统或平台的入口模块,主要功能包括:
- 用户注册:允许新用户输入基本信息(如用户名、密码、邮箱等)进行注册。
- 用户登录:已注册用户通过输入用户名和密码等方式登录系统。
- 安全验证:可能包括验证码、二次验证(如短信验证码、邮箱验证)等功能,以确保用户身份的合法性。
(3)资金热点方向
该模块用于分析市场资金的流向和热点板块,帮助投资者发现当前市场中最受资金关注的领域。可能包括以下内容:
- 资金流入流出排名:展示哪些板块或个股在近期获得资金大量流入,哪些板块或个股资金流出较多。
- 热点板块分析:通过数据分析,找出当前市场中最热门的行业板块,如新能源、人工智能、生物医药等。
- 资金流向趋势图:以图表形式展示资金流向的变化趋势,帮助投资者判断市场的资金偏好。
(4)资金诊断分析——技术面和基本面
该模块结合技术分析和基本面分析,对股票或市场进行综合诊断。可能包括以下内容:
- 技术面分析:通过图表和技术指标(如均线、MACD、KDJ等)分析股票的短期走势和交易信号。
- 基本面分析:分析公司的财务状况(如营业收入、净利润、资产负债率等)、行业地位、竞争优势等基本面因素。
- 综合诊断报告:结合技术面和基本面的分析结果,给出股票或市场的综合评价和投资建议。
(5)股票对比分析——技术面和基本面对比
该模块用于对比分析不同股票之间的技术面和基本面差异,帮助投资者选择更具投资价值的股票。可能包括以下内容:
- 技术指标对比:对比不同股票的均线走势、MACD指标、成交量等技术指标,分析其短期走势的强弱。
- 基本面数据对比:对比不同股票的财务数据(如市盈率、市净率、股息率等)、行业前景、公司治理等基本面因素。
- 综合评分:根据技术面和基本面的对比结果,对不同股票进行综合评分,帮助投资者快速筛选出优质股票。
(6)股票量化收益分析——股票收益率量化分析与诊股
该模块通过量化分析方法,对股票的收益率进行分析和预测,帮助投资者评估股票的投资价值。可能包括以下内容:
- 历史收益率分析:分析股票在不同时间周期(如日、月、年)内的收益率表现,计算其平均收益率、波动率等指标。
- 量化模型诊断:运用量化模型(如CAPM模型、多因子模型等)对股票的收益率进行预测和诊断,评估其风险和收益特征。
- 投资建议:根据量化分析结果,给出股票的投资建议,如买入、持有或卖出。
(7)股票价格预测——LSTM神经网络预测
该模块利用LSTM(长短期记忆网络)神经网络模型,对股票价格进行预测。可能包括以下内容:
- 模型参数设置:用户可以输入模型的时间窗口(如过去多少天的数据用于训练)、测试集数据占比、训练轮次等参数,以调整模型的训练效果。
- 数据预处理:对股票的历史价格数据进行清洗、归一化等预处理操作,以提高模型的训练效果。
- 模型训练与预测:通过LSTM神经网络模型对股票价格进行训练和预测,输出未来一段时间内股票价格的预测值。
- 预测结果评估:通过对比预测值和实际值,评估模型的预测准确率和误差,帮助投资者了解模型的可靠性。
4、核心代码
# 定义路由,预测股票价格
@app.route('/predict_stock_price/<code>/<look_back>/<test_ratio>/<train_epochs>')
def predict_stock_price(code, look_back, test_ratio, train_epochs):
# 获取股票历史数据
prices_df = spider.get_stock_kline_factor_datas(security_code=code, period='day', market_type=None)
prices_df = prices_df.sort_values(by='date', ascending=True)
prices_df.to_excel('stock_data.xlsx', index=False)#保存数据
print(prices_df.head())
test_count = int(float(test_ratio) * prices_df.shape[0]) # 计算测试集数量
train = prices_df['close'].values.tolist()[:-test_count] # 获取训练集数据
test = prices_df['close'].values.tolist()[-test_count:] # 获取测试集数据
# 创建数据集
def create_dataset(prehistory, dataset, look_back):
dataX = []
dataY = []
history = prehistory
for i in range(len(dataset)):
x = history[i:(i + look_back)]
y = dataset[i]
dataX.append(x)
dataY.append(y)
history.append(y)
return np.array(dataX), np.array(dataY)
look_back = int(look_back)
trainX, trainY = create_dataset([train[0]] * look_back, train, look_back) # 创建训练集
testX, testY = create_dataset(train[-look_back:], test, look_back) # 创建测试集
# 根据参数构建lstm模型
def create_lstm_model():
model = Sequential()
model.add(Dense(6, input_dim=look_back, activation='relu'))
model.add(Dropout(0.01))
model.add(Dense(4, input_dim=look_back, activation='relu'))
model.add(Dense(1))
model.compile(loss='mean_absolute_error', optimizer='adam')
return model
model = create_lstm_model() # 创建lstm模型
train_epochs = int(train_epochs)
model.fit(trainX, trainY, epochs=train_epochs, batch_size=4, verbose=1) # 训练模型
# 计算模型的准确率
train_score = model.evaluate(trainX, trainY, verbose=0)
print('模型的准确率: %.2f' % (1 - train_score))
# 预测
lstm_predictions = model.predict(testX)
lstm_predictions = [float(r[0]) for r in lstm_predictions]
lstm_error = mean_absolute_error(testY, lstm_predictions) # 计算预测误差
print('Test MSE: %.3f' % lstm_error)
lstm_predictions = train + lstm_predictions # 将预测结果添加到训练集数据后面
all_time = prices_df['date'].values.tolist() # 获取所有日期数据
future_x = [] # 初始化未来预测数据列表
pred_price = testY[-1] # 获取最后一个测试集数据的预测价格
future_count = 20 # 设置未来预测天数
for future in range(future_count):
ratio = random.random() / 100 if random.random() > 0.1 else -random.random() / 100 # 随机生成涨跌比例
pred_price *= (1 + ratio) # 计算未来预测价格
future_x.append(pred_price) # 将未来预测价格添加到列表中
all_time.append('未来1交易日') # 将未来预测日期添加到列表中
print(future_x)
all_data = prices_df['close'].values.tolist() # 获取所有收盘价数据
all_data += [None] * 5 # 添加空值
lstm_predictions = lstm_predictions + future_x # 将未来预测价格添加到预测结果中
return jsonify({'all_time': all_time, # 返回所有日期数据
'all_data': all_data, # 返回所有收盘价数据
'add_predict': lstm_predictions, # 返回预测结果
'test_count': future_count, # 返回未来预测天数
'error': lstm_error}) # 返回预测误差
# 定义路由,股票量化分析与诊股
@app.route('/stock_quant_analysis/<stock_input>')
def stock_quant_analysis(stock_input):
"""
股票收益率量化分析与诊股
"""
market_type = None
if stock_input == '上证指数':
stock = {'code': '000001', 'name': '上证指数'}
market_type = 1
elif stock_input == '深证成指':
stock = {'code': '399001', 'name': '深证成指'}
elif stock_input == '中小板指':
stock = {'code': '399005', 'name': '中小板指'}
elif stock_input == '创业板指':
stock = {'code': '399006', 'name': '创业板指'}
elif stock_input == '沪深300':
stock = {'code': '399300', 'name': '沪深300'}
elif stock_input == '北证50':
stock = {'code': '899050', 'name': '北证50'}
else:
stock = search_stock_eastmoney(stock_input)
print(stock)
# 获取该股票的历史数据,前端绘制 K 线图
# 获取历史K线数据
stock_df = spider.get_stock_kline_factor_datas(security_code=stock['code'], period='day', market_type=market_type)
stock_df = stock_df[['date', 'open', 'close', 'low', 'high']]
stock_df.sort_values(by='date', ascending=True, inplace=True)
kline_data = stock_df.values.tolist()
# 计算 BOLL 指标
stock_df['boll_mid'] = stock_df['close'].rolling(26).mean()
close_std = stock_df['close'].rolling(20).std()
stock_df['boll_top'] = stock_df['boll_mid'] + 2 * close_std
stock_df['boll_bottom'] = stock_df['boll_mid'] - 2 * close_std
# 计算日收益率
stock_df['pct_chg'] = stock_df.close.pct_change()
# 计算对数收益率
stock_df['log_ret'] = np.log(stock_df.close / stock_df.close.shift(1))
# 计算累计收益率
print('对数收益率进行累计求和,可以计算出所有时间点上的收益率')
stock_df['cumulative_rets'] = stock_df.log_ret.cumsum().values
stock_df.fillna({'cumulative_rets': 0}, inplace=True)
# 计算年化收益率
year_ret = analysis_util.calc_annualized_returns(stock_df['cumulative_rets'].values[-1], days=stock_df.shape[0])
# 计算最大回撤
reward_days = analysis_util.calc_maximum_drawdown(stock_df['cumulative_rets'].values)
name = '{}({})'.format(stock['name'], stock['code'])
hint = '{},年化收益率:<span style="color:{}">{}</span>, 最大回撤:<span style="color:{}">{}</span>'.format(
name,
'red' if year_ret > 0 else 'green',
'{:.4f}%'.format(year_ret * 100),
'red' if reward_days > 0 else 'green',
'{:.4f}%'.format(reward_days * 100)
)
stock_df.fillna('-', inplace=True)
return jsonify({
'name': hint,
'kline_data': kline_data,
'boll_data': {
'UPPER': stock_df['boll_top'].values.tolist(),
'LOWER': stock_df['boll_bottom'].values.tolist(),
'MIDDLE': stock_df['boll_mid'].values.tolist()
},
'date': stock_df['date'].values.tolist(),
'日收益率': stock_df['pct_chg'].values.tolist(),
'日对数收益率': stock_df['log_ret'].values.tolist(),
'累计收益率': stock_df['cumulative_rets'].values.tolist(),
})
if __name__ == "__main__":
app.run(host='127.0.0.1', debug=False)
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

















 986
986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









