







推荐算法
大致上有两种:基于内容的过滤和协同过滤;
基于内容:在基于内容的推荐系统中,项目或对象是通过相关特征的属性来定义的,系统基于用户评价对象的特征、学习用户的兴趣,考察用户资料与待预测项目的匹配程度
协同过滤:基于协同过滤的推荐算法是基于这样的假设:为一用户找到他真正感兴趣的内容的好方法是首先找到与此用户有相似兴趣的其他用户,然后将他们感兴趣的内容推荐给此用户。它一般采用最近邻技术,利用用户的历史喜好信息计算用户之间的距离,然后利用目标用户的最近邻居用户对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,从而根据这一喜好程度来对目标用户进行推荐。
Tf-idf
用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。

向量空间模型
把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度,直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量之间的相似性来度量文档间的相似性。文本处理中最常用的相似性度量方式是余弦距离。

LSA隐含语义分析
LSA的基本假设是,如果两个词多次出现在同一文档中,则这两个词在语义上具有相似性。LSA使用大量的文本上构建一个矩阵,这个矩阵的一行代表一个词,一列代表一个文档,矩阵元素代表该词在该文档中出现的次数,然后再此矩阵上使用奇异值分解(SVD)来保留列信息的情况下减少矩阵行数,之后每两个词语的相似性则可以通过其行向量的cos值(或者归一化之后使用向量点乘)来进行标示,此值越接近于1则说明两个词语越相似,越接近于0则说明越不相似。

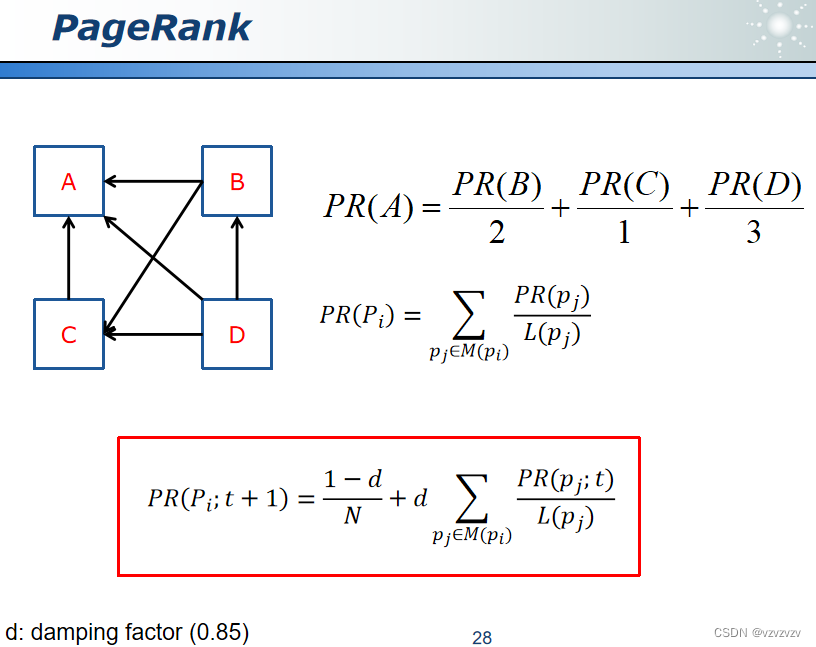
PageRank
PageRank算法的基本想法是在有向图上定义一个随机游走模型,即一阶马尔可夫链,描述随机游走者沿着有向图随机访问各个结点的行为。在一定条件下,极限情况访问每个结点的概率收敛到平稳分布,这时各个结点的平稳概率值就是其PageRank值,表示结点的重要度。PageRank 是递归定义的,PageRank 的计算可以通过迭代算法进行。
协同过滤
协同过滤算法是一种较为著名和常用的推荐算法,它基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐。协同过滤算法分为两种,基于用户的协同过滤算法(user-based collaboratIve filtering),以及基于物品的协同过滤算法(item-based collaborative filtering)。
User-Based CF
思想:找到和目标用户相似的用户,推荐该相似用户使用过但该用户没见过的物品。
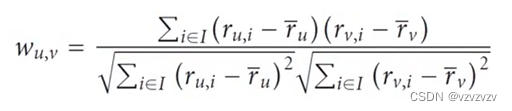
其中权重Wu,v是用户u和用户v的相似度,ru,i是用户s对物品i的评分。
缺点:
1.维护用户的相似度矩阵的成本较高,因为在互联网中用户的数量是远远多于物品的数量的,而且用户的数量增长的飞快,这会使相似度矩阵的空间复杂度以n^2的速度快速增长,这是在线存储系统难以承受的扩展速度。
2.在正反馈获取较难的场景(酒店预订,大件商品的购买等)适用效果不好。例如说一个平台售卖大件商品那么这个商品的历史购买用户一定是较少的,因此找到相似的用户就十分困难。
Item-Based CF
思想:找到和历史上用户感兴趣的物品相似的物品进行推荐。
















 3595
3595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









