






代码链接:https:// github.com/MCG-NJU/BCN
这个特定的 Cascade Model 有以下参数:
num_stages:级联的神经网络数量。
num_layers:每个单独的神经网络中的层数。
num_f_maps:单独的神经网络中的特征映射数量。
dim:输入数据的维度。
num_classes:分类任务中的类别数量,即为动作类别。
dataset:用于训练模型的数据集名称。
device:模型在哪个设备上运行。
use_lbp:是否使用 LBP(局部二值模式)进行数据增强。
num_soft_lbp:LBP 的程度。

输入:
x:形状为 (batch_size, channels, seq_len, width, height) 的输入视频帧张量,其中 batch_size 为批次大小,channels 为通道数,seq_len 为序列长度,width 和 height 分别为图像的宽度和高度。
mask:形状为 (batch_size, 1, seq_len) 的输入mask张量,其中 batch_size 为批次大小,seq_len 为序列长度。mask 是一个二维的张量,用于在输入数据中标记每个时间步是否有效。mask 的值被设置为 1 表示有效帧,0 表示无效帧。
gt_target:形状为 (batch_size, 1) 的目标张量,仅在训练时使用,表示真实的分类标签。在代码中以条件语句形式加以区分:
首先分析该级联模型最重要的俩个子类SingleStageModel和SingleStageModel中的DilatedResidualLayer
SingleStageModel:
class SingleStageModel(nn.Module):
def __init__(self, num_layers, num_f_maps, dim, num_classes):
super(SingleStageModel, self).__init__()
self.conv_1x1 = nn.Conv1d(dim, num_f_maps, 1)
self.layers = nn.ModuleList([copy.deepcopy(DilatedResidualLayer(2 ** i, num_f_maps, num_f_maps)) for i in range(num_layers)])
self.conv_out = nn.Conv1d(num_f_maps, num_classes, 1)
def forward(self, x, mask):
feature = self.conv_1x1(x)
for layer in self.layers:
feature = layer(feature, mask)
out = self.conv_out(feature) * mask[:, 0:1, :]
return out, feature * mask[:, 0:1, :]该子类首先对输入进行一个一维卷积,卷积核大小为3,由于padding=dilation所以由下列公式:
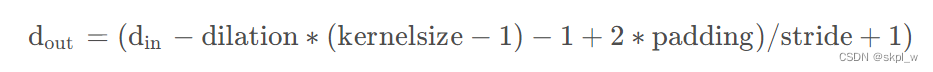
可知 feature = self.conv_1x1(x)未改变输入的shape。
之后的循环则是多次调用DilatedResidualLayer层。将前一次的输出作为下一次的输入。最后通过卷积核大小为1的卷积操作将输入通道数变成num_classes。
DilatedResidualLayer:
class DilatedResidualLayer(nn.Module):
def __init__(self, dilation, in_channels, out_channels):
super(DilatedResidualLayer, self).__init__()
self.conv_dilated = nn.Conv1d(in_channels, out_channels, 3, padding=dilation, dilation=dilation)
self.conv_1x1 = nn.Conv1d(out_channels, out_channels, 1)
self.dropout = nn.Dropout() # default value is 0.5
self.bn = nn.BatchNorm1d(in_channels, eps=1e-08, momentum=0.1, affine=True, track_running_stats=True)
def forward(self, x, mask,use_bn=False):
out = F.relu(self.conv_dilated(x))
out = self.conv_1x1(out)
if use_bn:
out=self.bn(out)
else:
out = self.dropout(out)
return (x + out) * mask[:, 0:1, :]这是扩展残差层的PyTorch实现,该层有三个主要组成部分:
具有3x3核和特定膨胀率的膨胀卷积层
1x1卷积层,用作减少信道数量的瓶颈
批处理规范化层或丢弃层,具体取决于use_bn参数的值
前向函数采用输入张量x和掩码张量掩码,掩码张量掩码用于选择性地应用残差连接。掩码张量的形状与x相同,但在输入有效的位置有一个1,在填充的位置有0。
输入x通过膨胀卷积层,然后通过1x1卷积层。如果use_bn为True,则通过批处理规范化传递输出,否则通过丢弃传递输出。最后,通过将输入张量x与输出张量相加,逐元素乘以掩码张量,来应用残差连接。
stage1:
self.stage1 = SingleStageModel(num_layers, num_f_maps, dim, num_classes)调用一次SingleStageModel。
out.size():(batch_size, num_classes, sequence_length)
feature.size():(batch_size, num_f_maps, sequence_length)
stages:
self.stages = nn.ModuleList([copy.deepcopy(SingleStageModel(num_layers, num_f_maps, dim + (s+1) * num_f_maps, num_classes)) for s in range(num_stages-1)])级联调用SingleStageModel。
stageF:
self.stageF = SingleStageModel(num_layers, 64, num_classes, num_classes)最终输出:
outputs:形状为 (num_stages, batch_size, num_classes) 的张量,其中 num_stages 为级联模型的级数,batch_size 为批次大小,num_classes 为分类数。
output_weight:形状为 (num_stages, batch_size, seq_len) 的张量,表示级联模型在各级别的置信度。
feature:形状为 (num_stages+1, batch_size, num_f_maps, seq_len) 的张量,其中 num_f_maps 为特征映射的数量,表示级联模型在各级别的特征映射。
confidence:形状为 (num_stages, batch_size, num_classes, seq_len) 的张量,表示级联模型在各级别的分类置信度。

















 1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









