







感想
介绍
在自然场景中,场景文本(Scene text)是最常见的视觉对象(visual objects)之一。经常出现在路标,车牌,产品包装袋上等等。阅读场景文本产生了很多有用的应用,例如基于图片的地理定位(image-basedgeolocation)。尽管它和传统的OCR很相似,但是场景文本的阅读更具有挑战性,因为它的前景文本和背景物体的千变万化,还有不可控的灯光条件等等。
由于这些无法避免的挑战和复杂性,传统的文本检测方法往往包含多个处理步骤,例如字符或单词候选区域的(candidategeneration)产生,候选区域的过滤(candidate filtering)和分组。这些经常需要想办法让每个模块工作正常,花费很多精力调参,还要设计启发式规则。并且这些过程会降低检测的速度。受目标检测的启发,我们提出了一个端到端训练的神经网络,这可以通过直接通过单词边界盒子(wordbounding boxes)来预测检测的文本。
贡献
这篇文章的主要贡献提出了一个快速而精确的文本检测器,叫做TextBoxes,基于全连接的卷积神经网络。TextBoxes直接输出单词包围盒子的坐标,同时预测文本存在和默认盒子(defaultboxes)的坐标偏移(coordinate offsets)。最后的输出是所有盒子的聚合,紧接着的是一个标准的非最大化抑制过程。为了处理单词的不同的纵横比,我们设计了一些新颖的,inceptiong风格的输出层,输出层利用不规律的卷积核(irregular convolutional kernels)和默认盒子。我们的检测器只用了单个的前向传导,输入是单比例的输入,取得了高精度和高效率;同样,在多比例的输入下,用多穿到,也能取得很高的精度。
另外,单词检测对于从背景中区分出文本是有帮助的,特别是当单词局限在一个给定集合中。如一个词典(lexicon)。我们成功的提出了一个文本识别算法,CRNN,和TextBoxes配合使用。识别器不仅提供了额外的识别输出,而且使得文本检测有了语义层面的意思,结果极大的提高了单词识别的精度。TextBoxes和CRNN的结合使得在文本识别和端到端文本识别任务上性能达到最好,是一个简单且高效自然场景下的鲁棒性文本阅读(robusttext reading in the wild)的方案。
总结下,文章的贡献分为三方面:
1、 设计了一个端到端训练神经网络的场景文本检测模型。
2、 提出了一个文字识别或端到端文本识别框架,高效的把检测和识别结合起来。
3、 我们的模型,在保证效率的情况下,取得了良好的结果。
TextBoxes
结构
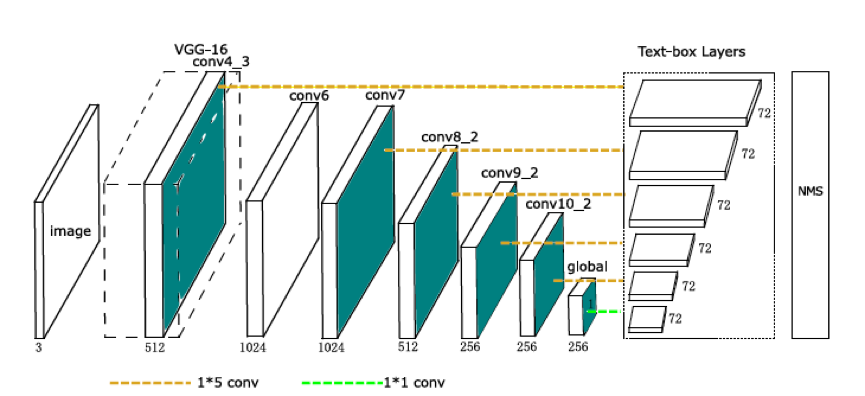
TextBoxes的结构如上,TextBoxes是一个28层的全连接卷积网络。其中13层是继承的VGG-16的网络结构,----------保留了vgg16的conv1_1到conv4_3的层,vgg16最后的全连接层转换成了参数下采样的卷积层,后面在了一些卷积核池化层,称为conv6到pool11层---------,额外的9个卷积层添加在VGG-16层之后,Text-box层连接着6个卷积层。在每一个特征位置,一个text-box预测72维向量,这是文本出现的得分(text presencescores)(2维)和12个默认盒子的偏移(offsets)(4层)。一个非最大抑制(NMS)用来聚合所有文本盒子(text-boxlayers)层的输出。
TextBoxes用300*300的图片训练的,优化规则为SGD。Momentum设置的是0.9,权重衰变(weightdecay)设置的是5*10^-4。学习率初始化设置为10^-3,训练迭代了40,000次。除了SVT,在所有的数据集上,我们首先在SynthText上迭代了50,000次来训练TextBoxes,之后在SVT上,我们用SVT训练数据集进行微调(finetuning)。所有训练图片进行了随机的切割和翻转,用来对图片进行在线扩充。所有的实验在一台有Titan X GPU上的PC上进行的。整个训练过程是25个小时。文本识别是用一个预训练的CRNN模型来实现的,这个模型原作者已经实现并且发布了。
Text-box layers
Text-box层是TextBoxes的关键组件,一个text-box层同时预测文本存在和边界盒子(bounding boxes),以输入的特征图为条件,在每一个图的位置,输出分类的得分和相关默认盒子的卷积偏移。假设图片和特征图的大小单独用(wim,him)和(wmap,hmap)来表示。在一个和默认盒子b0=(x0,y0,w0,h0)相关的图位置(map location)(i,j),text-box层预测(△x, △y,△w, △h,c),表明一个盒子b=(x,y,w,h)以置信度c检测到了。

在训练阶段,ground-truth单词盒子与默认盒子根据盒子覆盖度(boxoverlap)对应。根据匹配规则,每一个图位置和多个不同大小的默认盒子对应。这样就高效的把单词分为不同的纵横比和比例,并且TextBoxes还可以学习特定的回归和分类权重来处理相似大小的单词。因此,默认盒子的设计是与特定任务息息相关的。
和一般的物体不一样,单词往往有较大的纵横比。因此,我们设计了长的有大纵横比的默认盒子。特别地,我们设计了6种不同纵横比率的默认盒子,分别是1,2,3,5,7和10.可是,这使得在水平方向上的默认盒子密集而在垂直方向上的默认盒子变得稀疏,这会导致很差的匹配盒子(poor matchingboxes)。

上图为4*4网格的默认盒子的解释,为了更好的可视化,仅仅只有一列默认盒子的纵横比为1和5被描绘出来。剩下的纵横比是2,3,7,10,放的方法都是相似的。黑色(纵横比是5)和蓝色的(纵横比是1)默认盒子位于单元的中心位置。绿色的(纵横比是5)和红色的(纵横比是1)的盒子有相同的纵横比(same aspect ratios)和相对于网格中心的垂直偏移(verticaloffset)(偏移是该单元高的一半)。
另外,在text-box层,我们采取了非常规的1*5的滤波器,而没有采取3*3的滤波器。这种inception风格的滤波器产生矩形接受域(receptive fields),使得能适应大纵横比的单词,也避免了正方形接受域带来的噪声信号(noisysignals)。
学习
X为匹配指示矩阵(indication matrix),c为置信度。L为预测位置,g为位置的ground truth.特别地,对于第i个默认盒子和第j个ground truth,xij=1,意味着它们匹配删了,xij=0意味着它们没有匹配。损失函数定义如下:
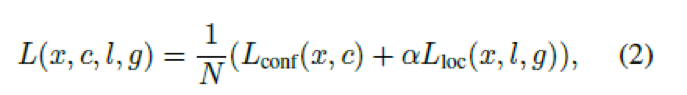
N是匹配ground truth盒子的默认盒子的数量,α设置为1,。我们采用的smooth L1损失函数作为Lloc的损失,2分类的softmax损失作为Lconf。
多比例输入
我们前面有在默认盒子和卷积滤波器上的优化,但是在有极端纵横比和大小的单词的鲁棒性定位仍然很困难。为了进一步提高检测的精度,我们使用多种比例版本的输入图片作为TextBoxes的输入。输入图片有5种比例,(宽*高)300*300,700*700,300*700,500*700和1600*1600.注意到一些比例是水平压缩图片,所以长的单词就变短了。多比例输入仅仅是增加了少量的计算量,但是提到了精度。在ICDAR2013数据集上,提高了5个百分点的f-measure.检测所有5中比例的输入,每张图片需要花费0.73秒;如果我们移除了1600*1600的比例,运行时间是0.24秒。运行时间是在一个Titan X GPU上测量的。注意到,不同于测试,我们仅仅使用单比例(300*300)输入进行训练。
非最大抑制(Non-maximum suppression)
非最大抑制被用于聚合所有text-box层的输出。在文本定位的任务上,我们采用额外的非最大抑制来来处理多比例的输入。
文字识别(Word spotting)和端到端的训练
文字识别是定位字典中特定的单词,端到端识别关心的是检测和识别两个方面。尽管两个任务都可以通过把TextBoxes和文本识别器简单的相连来实现。但是我们改进了检测和识别。我们认为一个识别器可以帮助消除false-positive检测结果,这些结果不可能是有意义的文字。例如重复片段。特别是,当有一个字典的时候,一个判别器可以有效地移除被探测出来的边界盒子,这些边界盒子与任何给定单词都不匹配。
我们采用了CRNN模型作为我们的文本识别器。CRNN使用CTC作为输出层,CTC可以估计根据输入图片预测序列可能性,例如:p(w|I),I是输入图片,w代表一个字符序列。我们把这个概率当做匹配的分数。用来衡量图片对应一个特定文字的使用性。检测分数就是在一个词典的所有单词中的得分最大单词的分数。
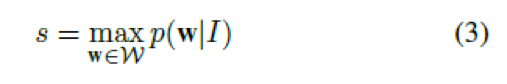
W是一个词典,如果任务没有指定词典,我们用一个通用的词典,词典由90,000个英语单词组成。
我们用(3)式的结果代替了原来TextBoxes检测分数。实际中,我们开始使用TextBoxes产生了一个冗余的单词候选集合,这是通过设置一个较小的得分阈值(lowerscore threshold)和一个高的NMS覆盖阈值来实现的。每张图片保留了大约35个边界盒子(bounding boxes),在IDCAR 2013的多比例输入上,recal达到了0.93.之后我们应用了(3)对所有的候选盒子去在评估它们的分数,紧接着是第二个分数阈值和一个NMS。当处理到多比例输入的时候,l我们在每一个比例上分开产生候选盒子,并且把上面的步骤应用到所有的比例输入上。我们采取了稍微不同于NMS策略。我们用了一个较低覆盖率阈值来选取盒子,它们被识别为一样的字。以至于相同的字的盒子赋予了更强的抑制(so thatstronger suppression is imposed on boxes of the same word,不知道怎么翻译,我翻译的仅供参考)。
实验
数据集
1、 SynthText,该训练集用来预训练模型
2、 ICDAR 2011 (IC11),该数据集的测试集合用于评估我们的模型
3、 ICDAR 2013 (IC13),该数据集合的训练集用于训练
4、 Street View Text (SVT),SVT数据集比ICDAR数据集更具有挑战性,因为图片的分辨率低。现存的有一些未标记的文本在图片上。我们仅使用数据集做文本识别,识别的词典仅包含50个词。
文本定位
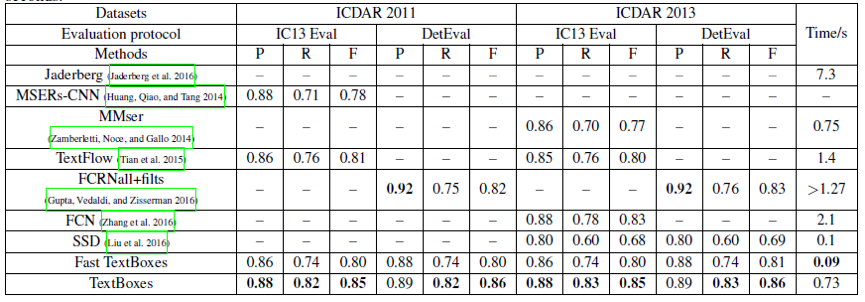
上表示在ICDAR 2011和ICDAR2013上的文本定位。P代表precision, R代表Recall, F代表F-measure。FCRNall+filts报告了执行回归步骤的时间消耗为1.27秒,我们假设它花费的时间超过了1.27秒。
文字识别与端到端识别
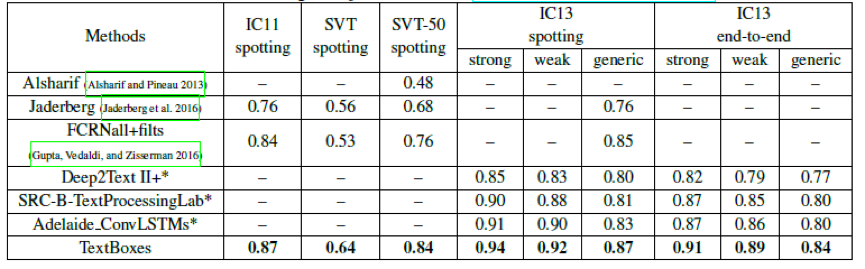
文字识别和端到端结果。表格里面的值是f-measure.对于ICDAR 2013,strong一个小词典包含100个字的图片,weak代表一个包含整个测试集合的字典,generic代表包含很大的字典。Generic词典包含了90,000个字。这些用*表示的方法是在ICDAR 2015鲁棒性阅读竞赛中发布的,网址为:http://rrc.cvc.uab.es.
缺点

上图为文本定位的结果,绿色的边界盒子是正确的检测,红色的是错误的正例(falsepositives),红色虚线的盒子是错误的负例(false negatives)。

上图是文字识别结果的样例。黄色单词是识别的结果,单词少于3个字母的被忽略了,和根据用的的评估协议。盒子的颜色和前面一张图相同。
参考文献
[1]. Minghui Liao, Baoguang Shi, Xiang Bai, Xinggang Wang,Wenyu Liu:
TextBoxes: A Fast Text Detector with a Single Deep NeuralNetwork. AAAI 2017: 4161-4167
















 194
194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











