







论文地址:Decoders Matter for Semantic Segmentation:
Data-Dependent Decoding Enables Flexible Feature Aggregation
Introduction
本文主要以下四点:
1 本文提出数据依赖上采样(DUpsampling)取代双线性上采样;
2 从CNNs的低分辨率输出中恢复像素级预测
3 新的上采样层位于相对较低层的分辨率特征映射;大量降低计算的复杂性;
4 新的上采样层大大提升重建的可能性;基于解码的DUpsampling灵活性,利用任意组合的CNN编码器的特点
双线性结构
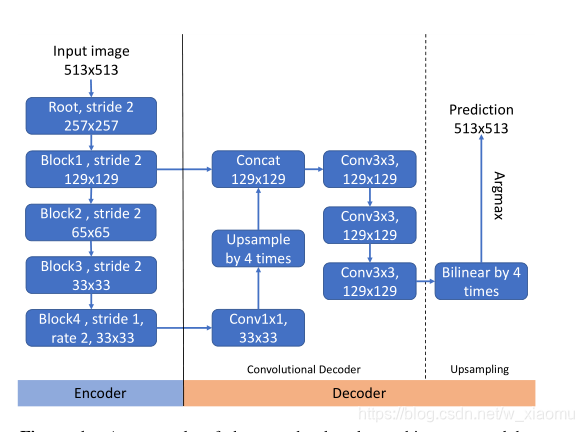
1 将下采样的底层特征和上采样的高层特征先融合在合并
2 使用双线性上采样恢复全分辨率的预测
本文将Upsample改为下采样;将双线性改为DUpsampling;
本文的结构
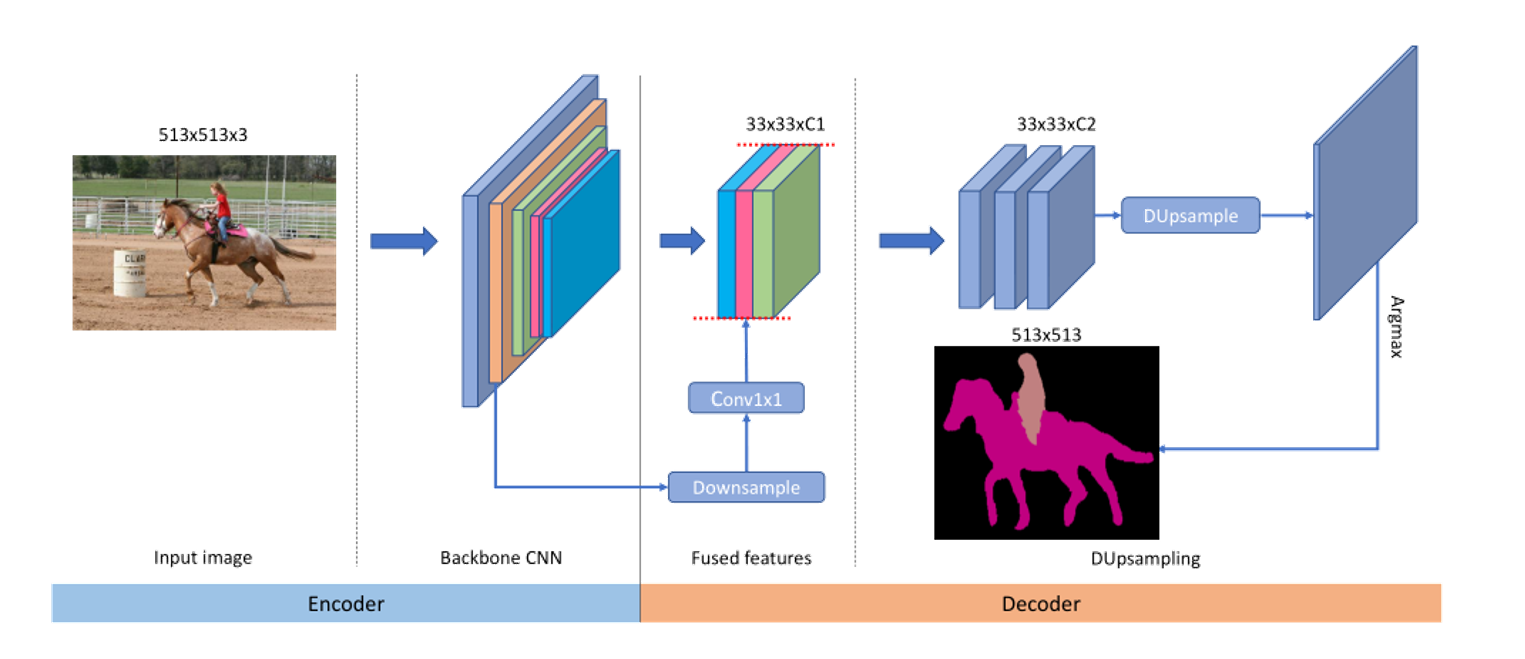
所有融合后的特征在融合前都被降采样到最低的特征分辨率;
利用DUpsampling代替双线性恢复全分辨率预测。
具体阐述:
由于数据依赖上采样性,在合并之前,将下采样的融合特征到特征映射的低分辨率上;下采样不仅仅降低解码的计算量,而且更为重要的是,它解耦融合特征的分辨率和最后的预测;这种解耦使得解码使用任意特征合并,因此可以利用更好的特征聚合尽可能提高分割性能。最后,数据依赖上采样可以通过标准的1*1卷积无缝的合并到网络中,因此不需要启发式编码;
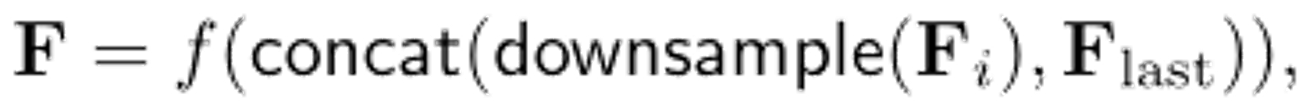
解码部分公式的说明:Fi指的是低层的特征,Flast指的是最后一层;先将Fi下采样到与Flast相同的分辨率,然后级联,最后将级联的结果执行卷积操作,得到最后的F,对F进行DUpsampling操作,得到最终的结果。DUpsampling操作之前,先来说明双线性操作,DUpsampling是以双线性为基础的:
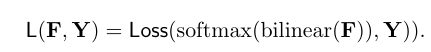
采用双线性方法将F上采样到Y的空间大小;
W是由一个有效编码Y计算来的;其中Y是实际值标签映射,通常采用有效编码;
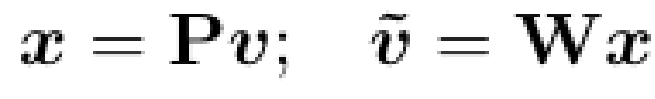
将S重构为向量v;将向量v压缩到低维向量x;然后垂直水平堆叠所有的x形成y’
W表示逆投影矩阵,表示将x返回到v;P矩阵表示将V压缩到x;
N = r × r × C 其中r表示H到H’的比率;
DUpsampling
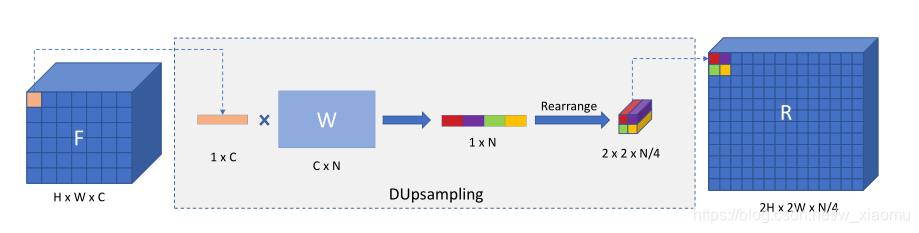
这个上采样的过程本质上等同于在空间维度应用1*1卷积,卷积核存储在W中,此处的W是基于双线性上采样的结果得出W。
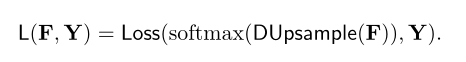
用学习到的重建矩阵W对F进行上采样,然后计算解压缩后的F和Y之间的像素分类损失;
在线性重构中,DUpsampling(F)将Wf的线性上采样应用到张量F的每个特征f上;
实验
实验数据集使用VOC2012
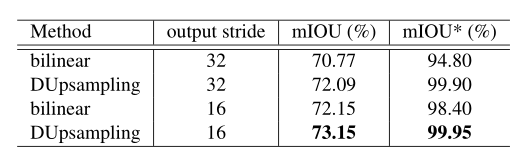
双线性上采样与DUpsampling上采样对比实验;
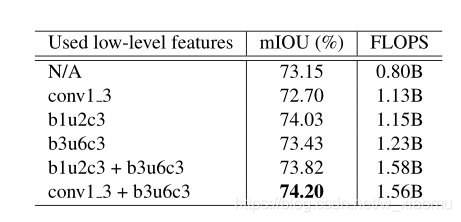
不同低层的实验结果,测试得出最优的结果;
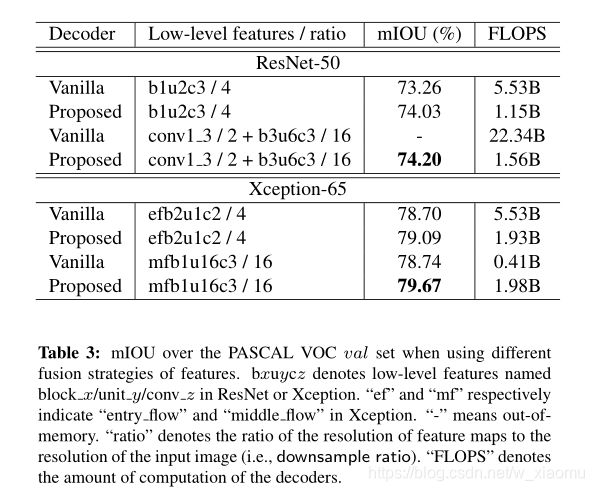
不同的网络结构的测试结果;
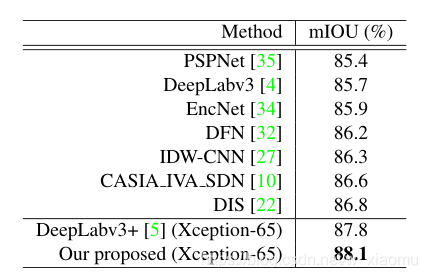
PASCAL VOC 测试集上,用不同的网络进行测试,得出测试结果;
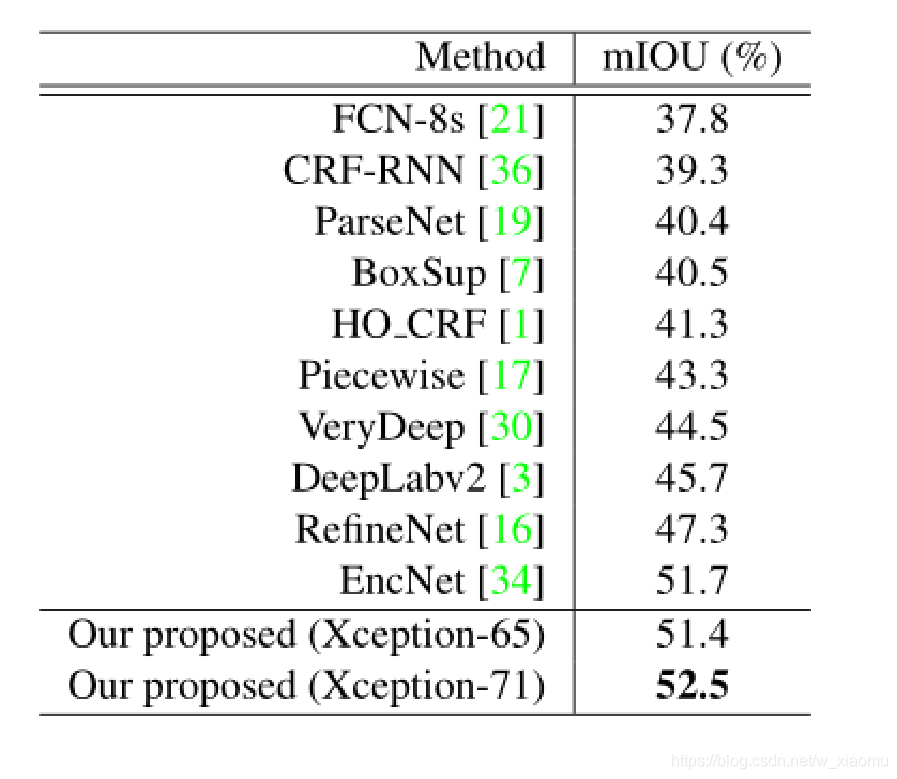
不同的网络结构在PASCAL Context 进行验证,得出本文的结构是最好的。
结论:
本文的提出的下采样的降低计算量,并且提出DUpsampling,对后续的研究提供比较新的方向,值得借鉴。














 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









