







 提出一种数据相关型上采样方法DUpsampling,替代双线性插值,提升语义分割精度,降低计算复杂度。实验显示,基于DUpsampling的解码器在多个数据集上取得SOTA效果,计算量仅为传统模型的20%~30%。
提出一种数据相关型上采样方法DUpsampling,替代双线性插值,提升语义分割精度,降低计算复杂度。实验显示,基于DUpsampling的解码器在多个数据集上取得SOTA效果,计算量仅为传统模型的20%~30%。
论文地址 :Decoders Matter for Semantic Segmentation:Data-Dependent Decoding Enables Flexible Feature Aggregation
工程地址:github 链接
0. 摘要
当前的语义分割方法多使用了编解码架构来获得逐像素的预测结果,解码模块的最后一层通常是一个双线性插值上采样来恢复特征图的分辨率,但是这种数据无关而且过于简单的上采样可能会导致不是最优的分割结果。
该论文则提出一种数据相关型的上采样方法DUpsampling来替代双线性插值,DUpsampling的优点在于恢复特征图尺寸的同时,提升了分割精度,降低了计算复杂度,这可能的原因是:1)新型上采样重构能力大大提升;2)基于DUpsampling的解码器能够灵活利用任意CNN解码器不同层特征的组合。
实验表明基于新型上采样方式的解码器在多个通用数据集上取得了SOTA效果,并且计算量仅有原有模型的20%~30%。
1. 简介
原始的全卷积神经网络(Fully convolutional networks, FCNs)虽然在语义分割任务上取得了很好的效果,但是其通过带步长的卷积和池化操作将输出特征图的尺寸缩减为原始输入的三十二分之一,导致了图像精细特征的丢失。为此Deeplab应用空洞卷积算法在扩张特征图感受野的同时保持一个尺寸较大的特征图,DeeplabV3+进一步应用了编解码的架构思想来尽量避免这个问题带来的精度损失,其将CNN视为编码模块从原始输入图像长生低分辨率的特征图,之后应用解码模块恢复特征图尺寸并融合浅层特征获得带有精细位置特征的预测结果,通常包含几层卷积和一个双线性插值上采样,如下图所示(DeepLabV3+):
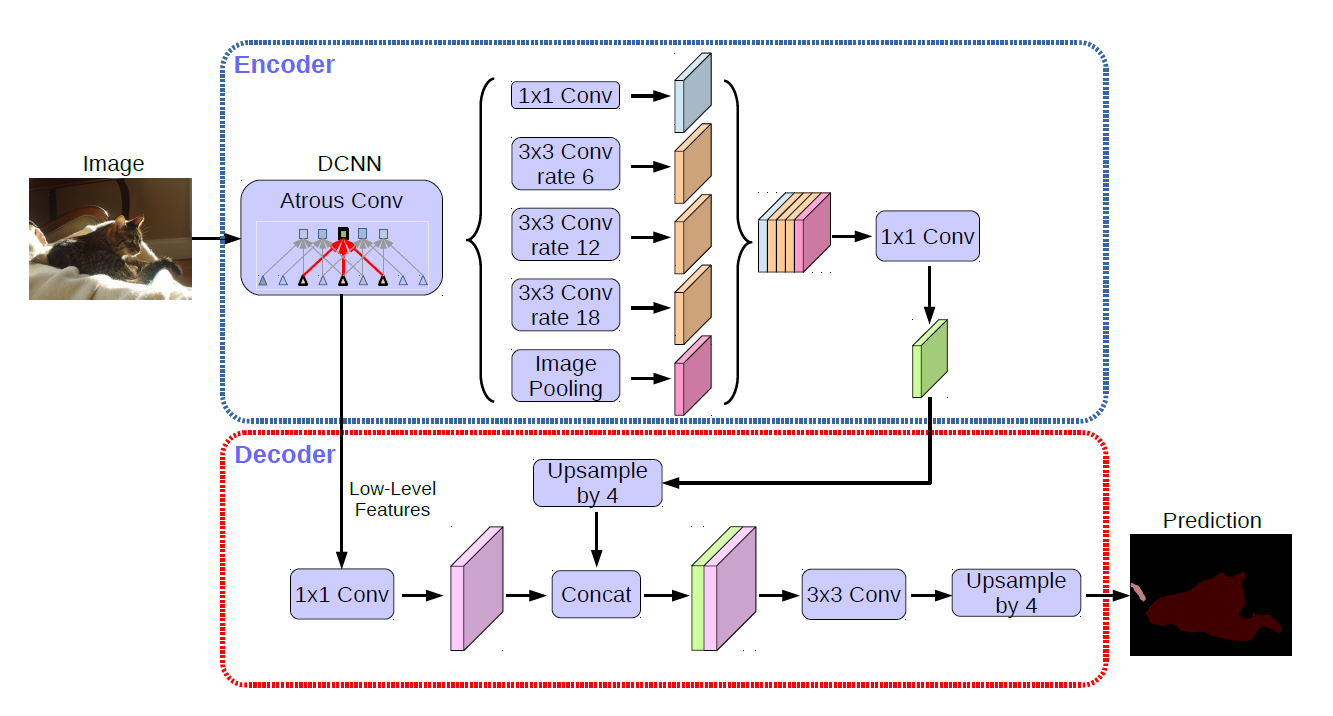
但是双线性插值上采样方法精确恢复逐像素预测结果的能力较弱,并没有考虑像素点标签之间的关系,即数据无关,这就导致编码模块需要更小的out stride解码模块才能取得较好的高分辨率特征图,这有两个方面的问题:
- Out Stride越小,编码器中就需要更多多种尺寸的空洞卷积层,导致了计算复杂度和所需内存大幅度增加,使得其在大型数据集上的训练和实时应用都受限,如DRN那样;
- 解码器需要融合来自浅层的特征来获取图像精细的位置特征,这导致了特征融合设计空间变小可能取不到最优效果。实验表明,如果特征融合可以不受特征图尺寸的限制,完全可以找到精度更高的特征融合方式。
为了消除双线性插值法能力不足而带来的各种问题,改论文提出了名为DUpsampling的新型数据相关型上采样方法,这使得编码模块无需减少其步长从而使得计算时间和内存占用大幅度改善。同时由于DUpsampling的高效,使得解码器能够将融合的特征下采样至较小的分辨率,这不但减小了解码器的内存占用而且将待融合的特征与最终预测解耦,这种解耦使得解码器能够利用任意的特征聚合从而获得最优效果。
而且DUpsampling实现简单,总得来说该论文的贡献在于:
- 提出了一种简单但是高效的数据相关型上采样DUPsampling代替双线性插值方法;
- 通过DUpsampling的使用,避免了解码器减少步长带来的计算量和内存占用的提升;
- DUpsampling使得解码器能够大幅度下采样待融合特征使其与最终预测结果解耦从而尝试不同的特征聚合获得最有效果
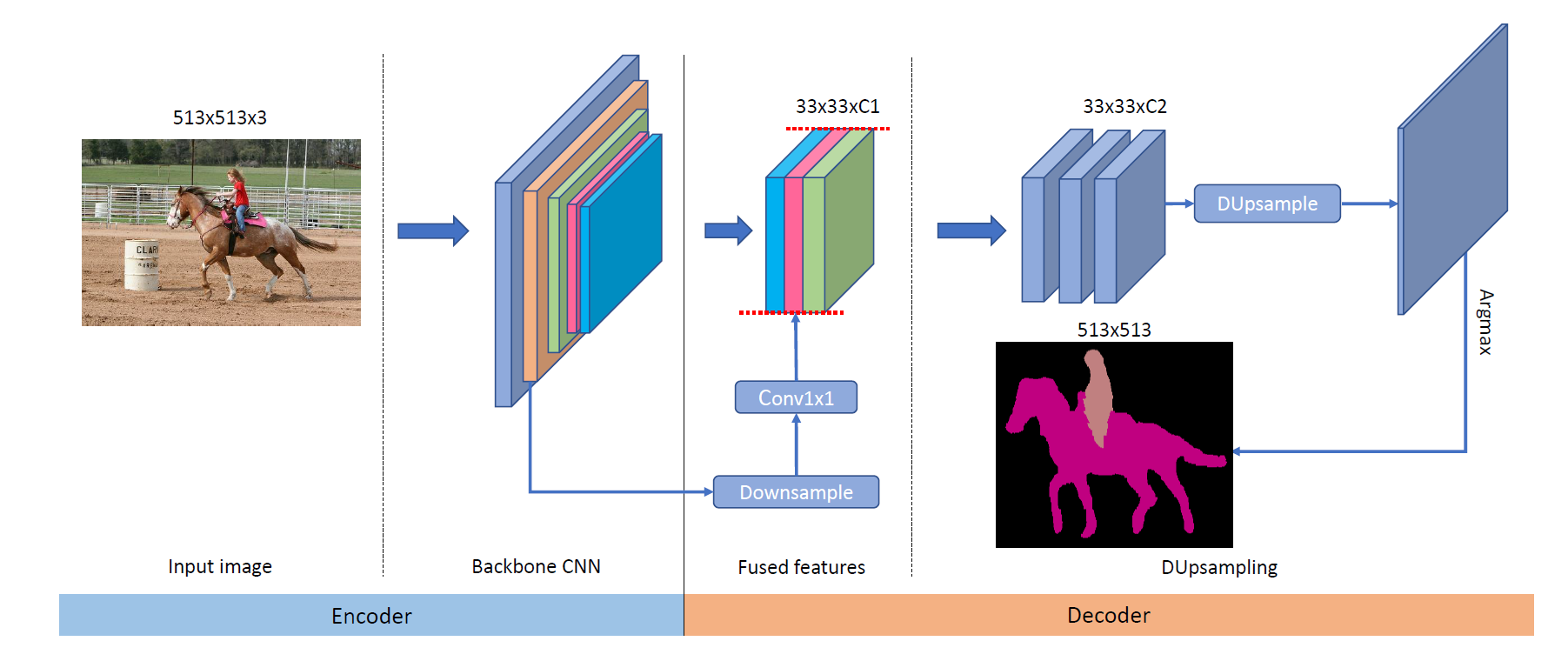
- 提出了一种新的语义分割架构(如下图所示),使用约五分之一左右的计算量取得了SOTA效果。
2. 相关工作
- 空洞卷积
- 编解码架构
3. 论文提出的方法
论文第三节先是重新形式化带有DUpsampling的语义分割,然后提出适应性softmax函数更好地训练DUpsampling,最后展示这种方法如何大幅度提升最终效果。
3.1-超越双线性插值:数据相关型上采样
首先看最简单的仅有几次上采样组成的解码器模块,给定
F
∈
R
H
^
×
W
^
×
C
^
F \in R^{\hat H\times\hat W\times\hat C}
F∈RH^×W^×C^为解码器的输出,
Y
∈
[
0
,
1
,
2
,
.
.
.
,
C
]
H
×
W
Y \in [0,1,2,...,C]^{H\times W}
Y∈[0,1,2,...,C]H×W为人工标注的掩码图,
C
和
C
^
C和\hat C
C和C^分别表示分割的类别和最终输出的通道数,通常
Y
∈
[
0
,
1
]
H
×
W
×
C
Y \in [0,1]^{H\times W\times C}
Y∈[0,1]H×W×C,
F
F
F通常比
Y
Y
Y小16或32倍,计算损失的时候需要将F上采样至与Y相同尺寸,通过下面的公式计算:
(1)
L
(
F
,
Y
)
=
L
o
s
s
(
s
o
f
t
m
a
x
(
b
i
l
i
n
e
a
r
(
F
)
)
,
Y
)
L(F,Y)=Loss(softmax(bilinear(F)),Y)\tag{1}
L(F,Y)=Loss(softmax(bilinear(F)),Y)(1)
然而这里使用双线性插值上采样可能并不是最优选择,这种上采样方式过于简单而且不能很好的对特征图进行重构。为了减少这种上采样增加的损失,要求解码器模块尽可能输出OS比较小的高分辨率特征图作为上采样的输入,解决方式就是大量使用空洞卷积算法,增加了计算复杂度。
一个重要的观察结果是,语义分割中的人工标注的掩码图Y包含结构信息,所以可以适当的无损压缩,因此不同于其他方法中将F上采样至与Y尺寸相同,论文尝试Y压缩至
Y
^
∈
R
H
^
×
W
^
×
C
^
\hat Y \in R^{\hat H\times\hat W\times\hat C}
Y^∈RH^×W^×C^然后计算F与
Y
^
\hat Y
Y^的损失。
为了将Y压缩成
Y
^
\hat Y
Y^,论文设计了一个几乎无损的重构方式,给定
r
=
O
u
t
S
t
r
i
d
e
r=OutStride
r=OutStride,Y被分为
H
r
×
W
r
\frac{H}{r}\times\frac{W}{r}
rH×rW个
r
×
r
r \times r
r×r的网格形式,对于每一个子窗口
S
∈
[
0
,
1
]
r
×
r
×
C
S \in [0,1]^{r\times r \times C}
S∈[0,1]r×r×C,将S变形为一个向量
v
∈
[
0
,
1
]
N
v \in [0,1]^N
v∈[0,1]N,其中
N
=
r
×
r
×
C
N=r \times r \times C
N=r×r×C,最终将向量
V
V
V压缩成一个低维向量
x
∈
R
C
^
x \in R^{\hat C}
x∈RC^然后从水平和垂直方向排列x以形成
Y
^
\hat Y
Y^、
最简单的就是线性映射,形式化定义为:
(2)
x
=
P
v
;
v
^
=
W
x
x=Pv;\hat v=Wx\tag{2}
x=Pv;v^=Wx(2)
其中
P
∈
R
C
^
×
N
P \in R^{\hat C \times N}
P∈RC^×N用于压缩v为x,
W
∈
R
N
×
C
^
W \in R_{N \times \hat C}
W∈RN×C^是相反的转化,
v
^
\hat v
v^是重新构建的
v
v
v。
P和W可以通过最小化v和
v
^
\hat v
v^之间的误差得到,形式化定义为:
(3)
P
∗
,
W
∗
=
a
r
g
m
i
n
P
,
W
∑
v
∣
∣
v
−
c
^
∣
∣
2
=
a
r
g
m
i
n
P
,
W
∑
∣
∣
v
−
W
P
v
∣
∣
2
P^*,W^*=argmin_{P,W}\sum_v||v-\hat c||^2 \\=argmin_{P,W}\sum||v-WPv||^2\tag{3}
P∗,W∗=argminP,Wv∑∣∣v−c^∣∣2=argminP,W∑∣∣v−WPv∣∣2(3)
可以使用标准的SGD来进行优化,正交性限制可以简单地应用主成分分析来实现。
以
Y
^
\hat Y
Y^为目标,可以使用回归损失对网络进行预训练来观察这个目标值是否是实际值:
(4)
L
(
F
,
Y
)
=
∣
∣
F
−
Y
^
∣
∣
2
L(F,Y)=||F-\hat Y||^2\tag{4}
L(F,Y)=∣∣F−Y^∣∣2(4)
此外更为直接的方式是直接计算在
Y
Y
Y维度的损失,所以论文通过对学到的转换
W
W
W来对
F
F
F进行上采样,然后计算F和Y的损失:
(5)
L
(
F
,
Y
)
=
L
o
s
s
(
s
o
f
t
m
a
x
(
D
U
p
s
a
m
p
l
e
(
F
)
)
,
Y
)
L(F,Y)=Loss(softmax(DUpsample(F)),Y)\tag{5}
L(F,Y)=Loss(softmax(DUpsample(F)),Y)(5)
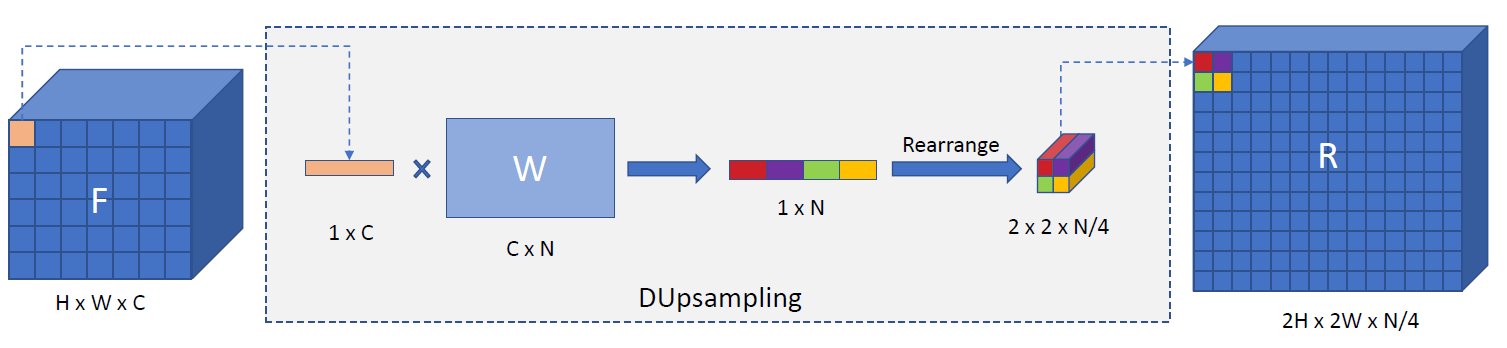
通过这个重构,DUpsampling(F)将线性上采样
W
f
Wf
Wf来应用到tensor F中的每一个特征
f
∈
R
C
^
f \in R^{\hat C}
f∈RC^中,由此替代了双线性插值。这个上采样过程和在空间维度应用点卷积一样,卷积核参数在
W
W
W中存储,过程如下图所示:
除此之外论文还使用非线性自动编码器来实现上采样,训练的过程也是最小化重构之后的损失,但是语义分割的结果几乎和线性的转化一样。
3.2 将DUpsampling和带有自适应T的Softmax结合
为了将DUpsampling融合进编解码框架中得到一个可以端到端训练的系统(DUpsampling可以以点卷积方式实现直接嵌入编解码框架但是训练难度较大),使用了带有T的softmax函数,它在softmax中增加了一个参数T,以达到在各个类上的概率分布更加soft的效果,公式如下:
(6)
s
o
f
t
m
a
x
(
z
i
)
=
e
x
p
(
z
i
/
T
)
∑
j
e
x
p
(
z
j
/
T
)
softmax(z_i)=\frac{exp(z_i/T)}{\sum_jexp(z_j/T)}\tag{6}
softmax(zi)=∑jexp(zj/T)exp(zi/T)(6)
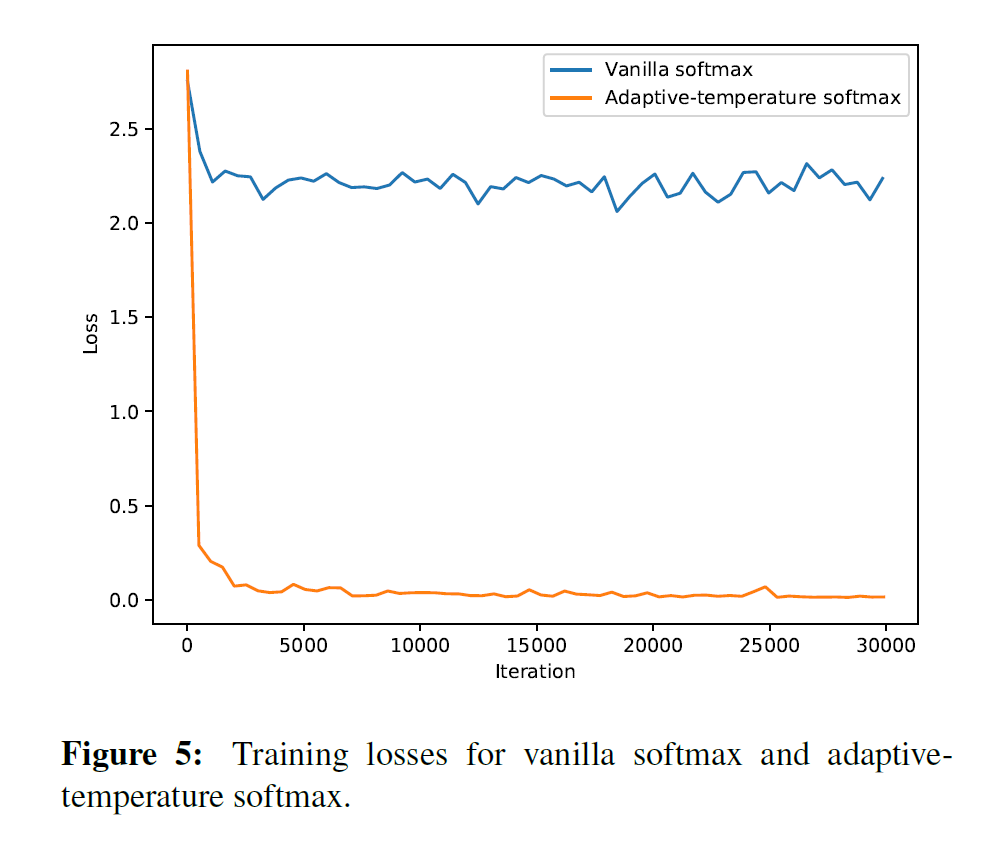
论文发现使用标准的后向传播可以自动学习T,而且试验表明这个带有自适应T的softmax能够在不调整其他超参数的情况下极大地加快训练过程的收敛。
3.3灵活的卷积特征融合
极深卷积神经网络虽然在计算机视觉方向取得了很大的进展,但是其丢失了图像精细的位置特征,因此多个研究表明结合浅层的特征能够更好的提升语义分割的精度。
假定F是CNNs的特征图用于产生最终的逐像素预测结果,
F
i
和
F
l
a
s
t
F_i和F_{last}
Fi和Flast代表了在level
i
i
i的CNN的特征图和最终的特征图。先前方法的特征聚合可以形式化为:
(7)
F
=
f
(
c
o
n
c
a
t
(
F
i
,
u
p
s
a
m
p
l
e
(
F
l
a
s
t
)
)
)
F=f(concat(F_i,upsample(F_{last})))\tag{7}
F=f(concat(Fi,upsample(Flast)))(7)
这种操作会导致1)f即CNN是在上采样之后应用{f作为CNN,计算量依赖于输入的尺寸,这种操作无疑回增加解码器的计算难度,而且这种计算弱化了解码器融合浅层特征的能力};2)待融合特征
F
i
F_i
Fi和F的尺寸相等,也就是最终输出的四分之一,为了获得更高分辨率的预测图,解码器只能选择比较浅层的特征。
作为对比,该论文提出的框架中可以安全地对浅层特征进行下采样易产生最终的
F
l
a
s
t
F_{last}
Flast,形式化如下(和公式7对比):
(8)
F
=
f
(
c
o
n
c
a
t
(
d
o
w
n
s
a
m
p
l
e
(
F
i
)
,
F
+
l
a
s
t
)
)
F=f(concat(downsample(F_i),F+{last}))\tag{8}
F=f(concat(downsample(Fi),F+last))(8)
这种方式将浅层特征和最终的分割预测结果解耦使得特征融合更加地灵活。
4. 实验
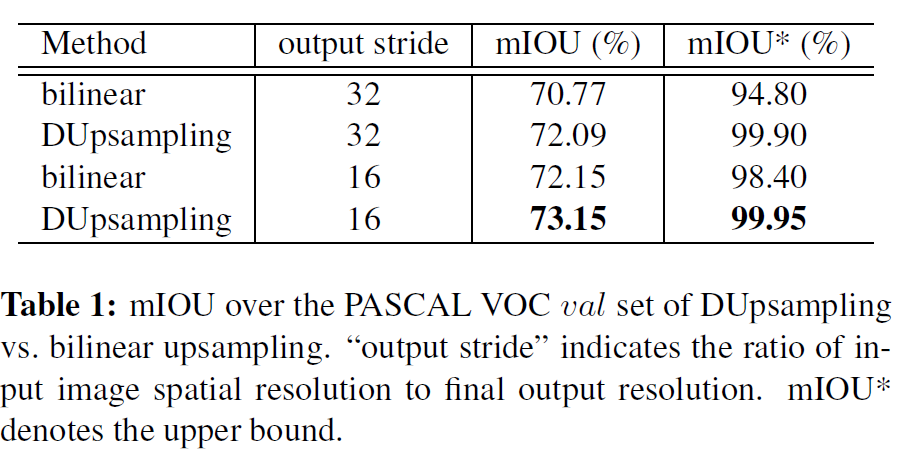
4.1 DUpsampling和Bilinear
4.2 灵活的特征融合
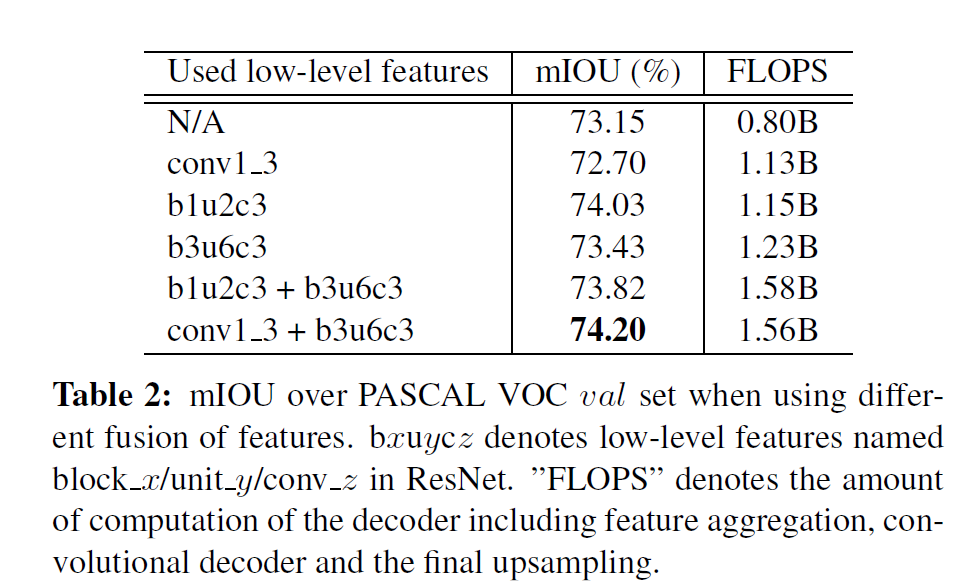
4.3 和采取双线性插值取样法的普通解码器相比
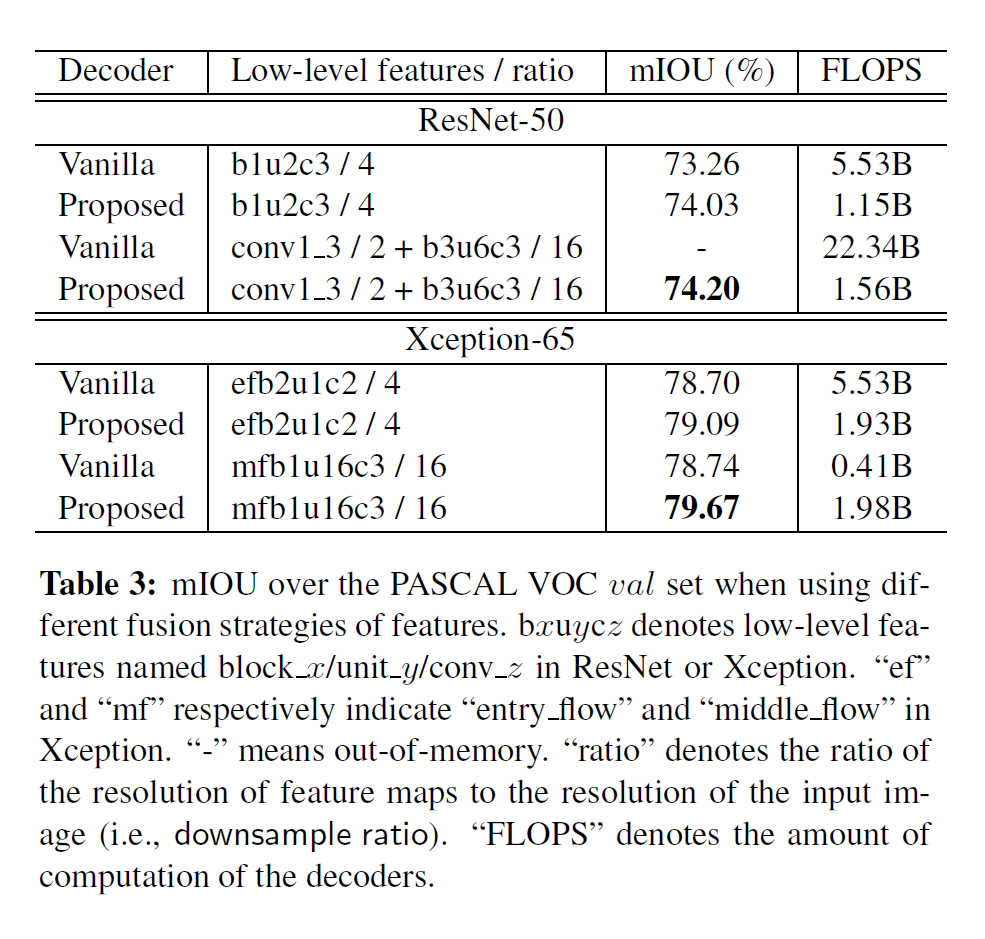

4.4 带有自适应温度参数的softmax
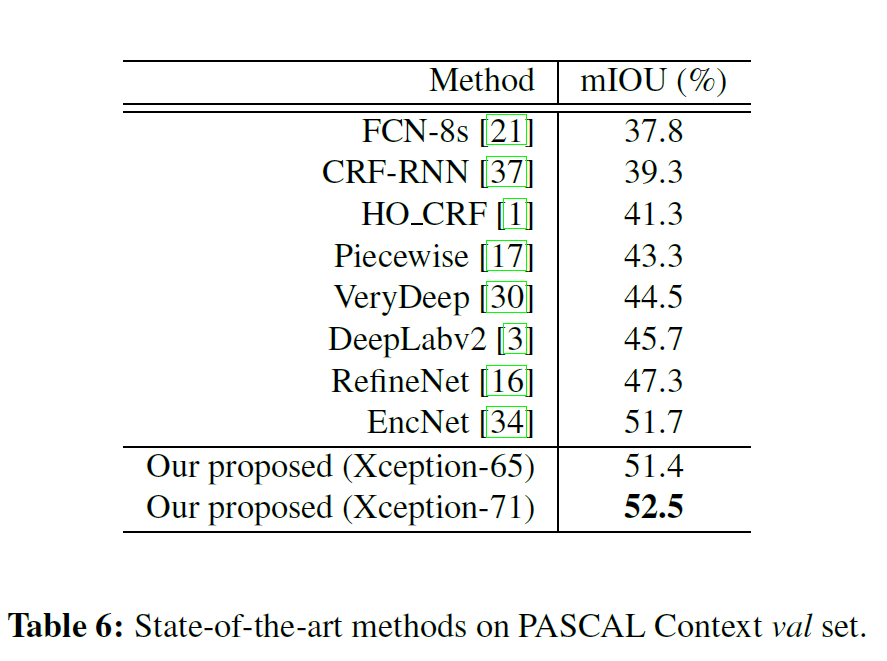
4.5 和当前SOTA方法相比
5. 结论
论文提出了一个轻量灵活的解码器用于图像语义分割,该解码器应用了DUpsampling长生逐像素点的预测结果,消除了在CNN计算高分辨率特征图的的低效计算并且解耦了待融合特征和最终输出,允许更加灵活的待融合特征选取。同时论文提出的方法避免了对低分辨率的深层特征进行上采样,降低了解码模块的计算量。实验表明论文提出的计算复杂度较低的模型在多个数据集上都得到了SOTA效果。
欢迎扫描二维码关注微信公众号 深度学习与数学 [获取免费的大数据、AI等相关的学习资源、经典和最新的深度学习相关的论文研读,算法和其他互联网技能的学习,概率论、线性代数等高等数学知识的回顾]


















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









