









文章目录
前言
每种聚类方法在不同数据状况下表现的优劣图:

代码实现
import time
import warnings
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn import cluster
from sklearn import datasets as ds
from sklearn.neighbors import kneighbors_graph
from sklearn.preprocessing import StandardScaler
## 设置属性防止中文乱码
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
warnings.filterwarnings(action='ignore', category=UserWarning)
## 产生模拟数据
n_samples = 1500
np.random.seed(0)
# 产生圆形的
noisy_circles = ds.make_circles(n_samples=n_samples, factor=.5, noise=.05)
# 产生月牙形
noisy_moons = ds.make_moons(n_samples=n_samples, noise=.05)
# 高斯分布
blobs = ds.make_blobs(n_samples=n_samples, n_features=2, cluster_std=0.5, centers=3, random_state=0)
no_structure = np.random.rand(n_samples, 2), None
datasets = [noisy_circles, noisy_moons, blobs, no_structure]
clusters = [2, 2, 3, 2]
clustering_names = [
'KMeans', 'MiniBatchKMeans', 'AC-ward', 'AC-average',
'Birch', 'DBSCAN', 'SpectralClustering']
## 开始画图
plt.figure(figsize=(len(clustering_names) * 2 + 3, 9.5), facecolor='w')
plt.subplots_adjust(left=.02, right=.98, bottom=.001, top=.96, wspace=.05, hspace=.01)
colors = np.array([x for x in 'bgrcmykbgrcmykbgrcmykbgrcmyk'])
colors = np.hstack([colors] * 20)
plot_num = 1
for i_dataset, (dataset, n_cluster) in enumerate(zip(datasets, clusters)):
X, y = dataset
X = StandardScaler().fit_transform(X)
connectivity = kneighbors_graph(X, n_neighbors=10, include_self=False)
connectivity = 0.5 * (connectivity + connectivity.T)
km = cluster.KMeans(n_clusters=n_cluster)
mbkm = cluster.MiniBatchKMeans(n_clusters=n_cluster)
ward = cluster.AgglomerativeClustering(n_clusters=n_cluster, connectivity=connectivity, linkage='ward')
average = cluster.AgglomerativeClustering(n_clusters=n_cluster, connectivity=connectivity, linkage='average')
birch = cluster.Birch(n_clusters=n_cluster)
dbscan = cluster.DBSCAN(eps=.2)
spectral = cluster.SpectralClustering(n_clusters=n_cluster, eigen_solver='arpack', affinity="nearest_neighbors")
clustering_algorithms = [km, mbkm, ward, average, birch, dbscan, spectral]
for name, algorithm in zip(clustering_names, clustering_algorithms):
t0 = time.time()
algorithm.fit(X)
t1 = time.time()
# 如果模型中存在"labels__"这个属性的话,那么获取这个预测的类别值
if hasattr(algorithm, 'labels_'):
y_pred = algorithm.labels_.astype(np.int)
else:
y_pred = algorithm.predict(X)
# 画子图
plt.subplot(4, len(clustering_algorithms), plot_num)
if i_dataset == 0:
plt.title(name, size=18)
plt.scatter(X[:, 0], X[:, 1], color=colors[y_pred].tolist(), s=10)
# 如果模型有中心点属性,那么画出中心点
if hasattr(algorithm, 'cluster_centers_'):
centers = algorithm.cluster_centers_
center_colors = colors[:len(centers)]
plt.scatter(centers[:, 0], centers[:, 1], s=100, c=center_colors)
plt.xlim(-2, 2)
plt.ylim(-2, 2)
plt.xticks(())
plt.yticks(())
plt.text(.99, .01, ('%2fs' % (t1 - t0)).lstrip('0'),
transform=plt.gca().transAxes, size=15,
horizontalalignment='right')
plot_num += 1
plt.show()

一、K-Means


二、K-means++
由于 K-means 算法的分类结果会受到初始点的选取而有所区别,因此有提出这种算法的改进: K-means++ 。
2.1 算法步骤

原始K-means算法最开始随机选取数据集中K个点作为聚类中心,而K-means++按照如下的思想选取K个聚类中心:
- 假设已经选取了n个初始聚类中心(0<n<K),则在选取第n+1个聚类中心时:距离当前n个聚类中心越远的点会有更高的概率被选为第n+1个聚类中心。
- 在选取第一个聚类中心(n=1)时同样通过随机的方法。
2.2 K-means++例子
下面结合一个简单的例子说明K-means++是如何选取初始聚类中心的。
数据集中共有8个样本,分布以及对应序号如下图所示:

假设经过图2的步骤一后6号点被选择为第一个初始聚类中心,
那在进行步骤二时每个样本的D(x)和被选择为第二个聚类中心的概率如下表所示:

其中的P(x)就是每个样本被选为下一个聚类中心的概率。
最后一行的Sum是概率P(x)的累加和,用于轮盘法选择出第二个聚类中心。
方法是随机产生出一个0~1之间的随机数,判断它属于哪个区间,那么该区间对应的序号就是被选择出来的第二个聚类中心了。
例如1号点的区间为[0,0.2),2号点的区间为[0.2, 0.525)。
从上表可以直观的看到第二个初始聚类中心是1号,2号,3号,4号中的一个的概率为0.9。
而这4个点正好是离第一个初始聚类中心6号点较远的四个点。
这也验证了K-means的改进思想:即离当前已有聚类中心较远的点有更大的概率被选为下一个聚类中心。
可以看到,该例的K值取2是比较合适的。当K值大于2时,每个样本会有多个距离,需要取最小的那个距离作为D(x)。
2.3 效率
K-means++ 能显著的改善分类结果的最终误差。
尽管计算初始点时花费了额外的时间,但是在迭代过程中,k-mean 本身能快速收敛,因此算法实际上降低了计算时间。
网上有人使用真实和合成的数据集测试了他们的方法,速度通常提高了 2 倍,对于某些数据集,误差提高了近 1000 倍。
三、MeanShift(均值迁移)
3.1 概述
Mean-shift(均值迁移)的基本思想:在数据集中选定一个点,然后以这个点为圆心,r为半径,画一个圆(二维下是圆),求出这个点到所有点的向量的平均值,而圆心与向量均值的和为新的圆心,然后迭代此过程,直到满足一点的条件结束。
后来在此基础上加入了 核函数 和 权重系数 ,使得Mean-shift 算法开始流行起来。目前它在聚类、图像平滑、分割、跟踪等方面有着广泛的应用。
3.2 图解过程
为了方便大家理解,借用下几张图来说明Mean-shift的基本过程。
第一张图有一个子中心点,它向四周最近的点开始寻找,找到圆心与向量均值的和为新的圆心,然后依次循环,直到满足条件,则不会再寻找其他圆心点。

3.3 算法函数
a)核心函数:sklearn.cluster.MeanShift(核函数:RBF核函数)
由上图可知,圆心(或种子)的确定和半径(或带宽)的选择,是影响算法效率的两个主要因素。所以在sklearn.cluster.MeanShift中重点说明了这两个参数的设定问题。
b)主要参数
bandwidth :半径(或带宽),float型。如果没有给出,则使用sklearn.cluster.estimate_bandwidth计算出半径(带宽).(可选)
from sklearn.cluster import estimate_bandwidth,MeanShift
bandwidth = estimate_bandwidth(X,quantile=0.1,n_samples=len(X))
print(bandwidth)
seeds :圆心(或种子),数组类型,即初始化的圆心。(可选)
bin_seeding :布尔值。如果为真,初始内核位置不是所有点的位置,而是点的离散版本的位置,其中点被分类到其粗糙度对应于带宽的网格上。将此选项设置为True将加速算法,因为较少的种子将被初始化。默认值:False.如果种子参数(seeds)不为None则忽略。
c)主要属性
cluster_centers_ : 数组类型。计算出的聚类中心的坐标。
labels_ :数组类型。每个数据点的分类标签。
四、Hierarchical methods(层次聚类)
4.1 层次聚类的原理及分类
1)层次法(Hierarchicalmethods)先计算样本之间的距离。每次将距离最近的点合并到同一个类。然后,再计算类与类之间的距离,将距离最近的类合并为一个大类。不停的合并,直到合成了一个类。其中类与类的距离的计算方法有:最短距离法,最长距离法,中间距离法,类平均法等。比如最短距离法,将类与类的距离定义为类与类之间样本的最短距离。
层次聚类算法根据层次分解的顺序分为:自下底向上和自上向下,即凝聚的层次聚类算法和分裂的层次聚类算法(agglomerative和divisive),也可以理解为自下而上法(bottom-up)和自上而下法(top-down)。自下而上法就是一开始每个个体(object)都是一个类,然后根据linkage寻找同类,最后形成一个“类”。自上而下法就是反过来,一开始所有个体都属于一个“类”,然后根据linkage排除异己,最后每个个体都成为一个“类”。这两种路方法没有孰优孰劣之分,只是在实际应用的时候要根据数据特点以及你想要的“类”的个数,来考虑是自上而下更快还是自下而上更快。至于根据Linkage判断“类”的方法就是最短距离法、最长距离法、中间距离法、类平均法等等(其中类平均法往往被认为是最常用也最好用的方法,一方面因为其良好的单调性,另一方面因为其空间扩张/浓缩的程度适中)。为弥补分解与合并的不足,层次合并经常要与其它聚类方法相结合,如循环定位。
2)Hierarchical methods中比较新的算法有BIRCH(Balanced Iterative Reducingand Clustering Using Hierarchies利用层次方法的平衡迭代规约和聚类)主要是在数据量很大的时候使用,而且数据类型是numerical。首先利用树的结构对对象集进行划分,然后再利用其它聚类方法对这些聚类进行优化;ROCK(A Hierarchical ClusteringAlgorithm for Categorical Attributes)主要用在categorical的数据类型上;Chameleon(A Hierarchical Clustering AlgorithmUsing Dynamic Modeling)里用到的linkage是kNN(k-nearest-neighbor)算法,并以此构建一个graph,Chameleon的聚类效果被认为非常强大,比BIRCH好用,但运算复杂度很高,O(n^2)。
4.2 层次聚类的流程
凝聚型层次聚类的策略是先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有对象都在一个簇中,或者某个终结条件被满足。绝大多数层次聚类属于凝聚型层次聚类,它们只是在簇间相似度的定义上有所不同。 这里给出采用最小距离的凝聚层次聚类算法流程:
(1) 将每个对象看作一类,计算两两之间的最小距离;
(2) 将距离最小的两个类合并成一个新类;
(3) 重新计算新类与所有类之间的距离;
(4) 重复(2)、(3),直到所有类最后合并成一类。
4.3 层次聚类的优缺点
优点:
1,距离和规则的相似度容易定义,限制少;2,不需要预先制定聚类数;3,可以发现类的层次关系;4,可以聚类成其它形状
缺点:
1,计算复杂度太高;2,奇异值也能产生很大影响;3,算法很可能聚类成链状
4.4 层次聚类的动态图展示
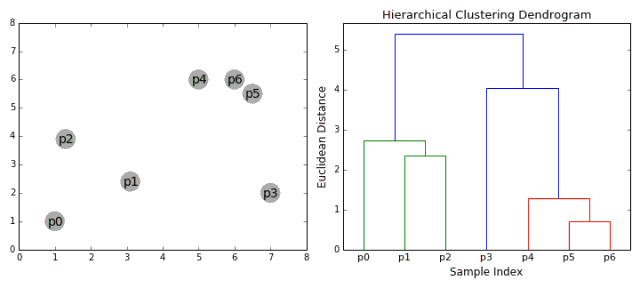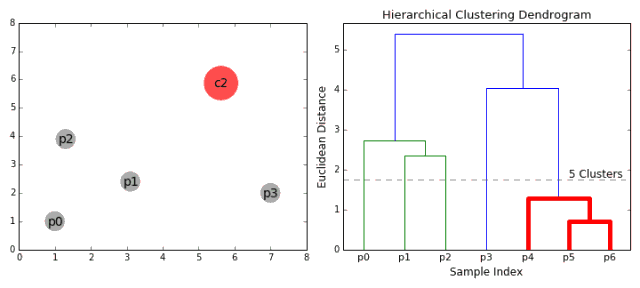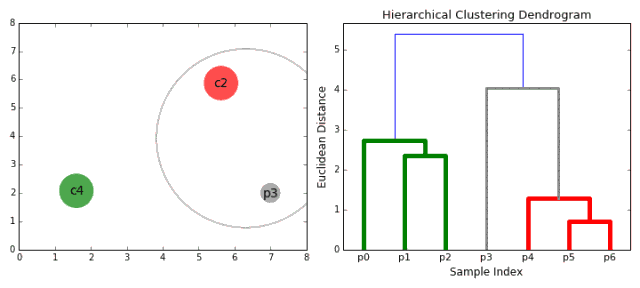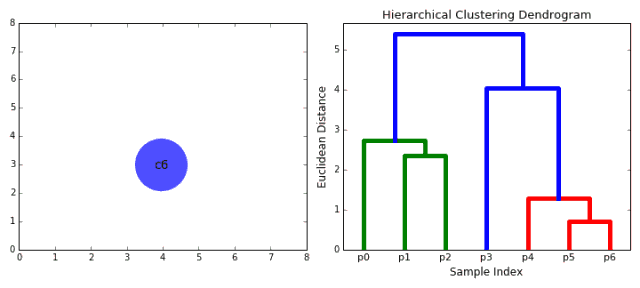
五、代码
import matplotlib.pyplot as plt
from sklearn.mixture import GaussianMixture
from sklearn.datasets import samples_generator# 样本生成器
from sklearn import metrics, cluster #评价方法,聚类库
# X, _ = samples_generator.make_blobs(n_samples=200, centers=2, cluster_std=0.60, random_state=0)
X, y_true = samples_generator.make_moons(200, noise=.05, random_state=0)
# X, y_true = samples_generator.make_circles(200, noise=0.05, random_state=0,factor=0.4)
# gmm = GaussianMixture(n_components=2)
# gmm = cluster.MeanShift()
# gmm = cluster.KMeans(4)
gmm = cluster.AgglomerativeClustering(2)
# gmm = cluster.AffinityPropagation()
# gmm = cluster.SpectralClustering(2,affinity="nearest_neighbors")
# gmm = cluster.DBSCAN()
labels = gmm.fit_predict(X)
print(metrics.silhouette_score(X, labels))
print(metrics.calinski_harabasz_score(X, labels))
print(metrics.davies_bouldin_score(X, labels))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis');
plt.show()
















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











