







2024-7-15 22:34:02
系统环境:

创建conda环境
conda create -n llamafactory python=3.10
拉取代码并安装依赖包
git clone https://github.com/LlamaFamily/Llama-Chinese.git
cd Llama-Chinese
pip install -r requirements.txt
看下当前版本
![[dd片转存中...(img-Vnh6FNBj-1726275684364)]](https://i-blog.csdnimg.cn/direct/b6e8e5aaf5134a5ab78f5de20862aa2a.png)
下载模型
vim download_model.py
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('FlagAlpha/Llama3-Chinese-8B-Instruct',local_dir='./models/FlagAlpha/Llama3-Chinese-8B-Instruct')
local_dir 设置为自己本地地址
进行推理
创建一个名为 quick_start.py 的文件,并将以下内容复制到该文件中。 模型替换为上面自己本地地址
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device_map = "cuda:0" if torch.cuda.is_available() else "auto"
model_id = "/home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_id,device_map=device_map,torch_dtype=torch.float16,load_in_8bit=True,trust_remote_code=True,use_flash_attention_2=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained(model_id,use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids
if torch.cuda.is_available():
input_ids = input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
运行 quick_start.py 代码。
python quick_start.py
报错如下

解决
pip install flash_attn
上面的安装很慢,参考快速安装flash-attn
再次运行 quick_start.py,还是有不对
transformers 版本不对

解决
pip uninstall transformers
pip install transformers
启动就能正常显示结果了,但是会有一些warning

修改位置如下图

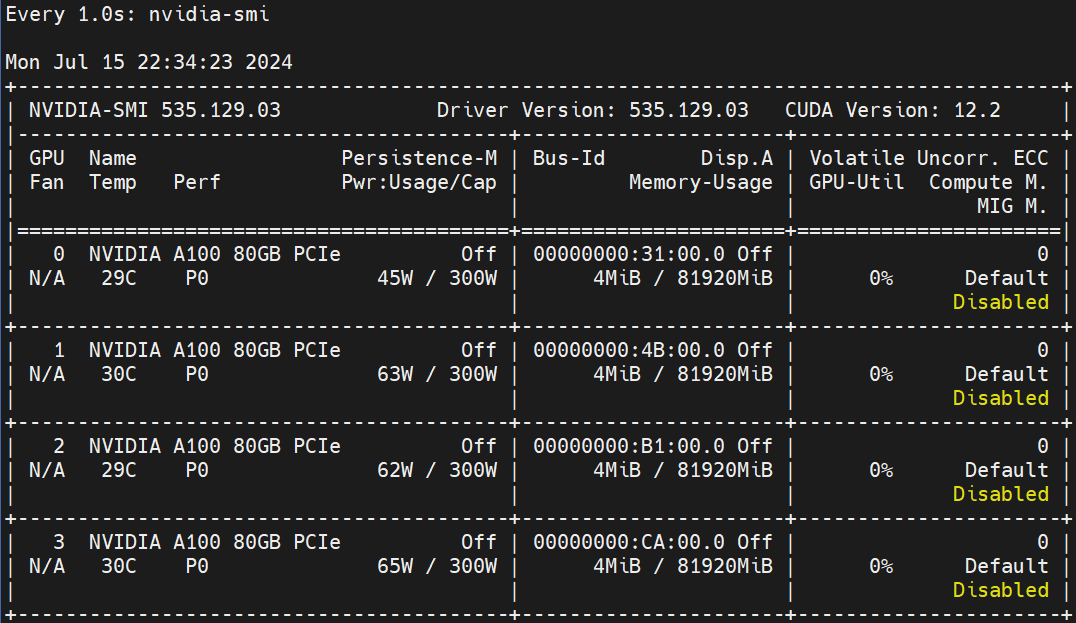
大概占用显存如下

最终结果

快速上手-使用gradio
python examples/chat_gradio.py --model_name_or_path /home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct
默认启动,生成很慢

修改源码
vim examples/chat_gradio.py
启动后大概占用15G多

发现输出很慢,而且结果也不是我想要的
后来查看https://huggingface.co/FlagAlpha/Llama3-Chinese-8B-Instruct 根据这里面的使用代码
import transformers
import torch
model_id = "/home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.float16},
device="cuda",
)
messages = [{"role": "system", "content": ""}]
messages.append(
{"role": "user", "content": "介绍一下机器学习"}
)
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9
)
content = outputs[0]["generated_text"][len(prompt):]
print(content)
这个很快就有结果了

配置完预览命令
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template llama3 \
--flash_attn fa2 \
--dataset_dir data \
--dataset alpaca_zh_demo \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 1000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-07-15-23-18-31 \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all

评估
llamafactory-cli train \
--stage sft \
--model_name_or_path /home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template llama3 \
--flash_attn fa2 \
--dataset_dir data \
--eval_dataset alpaca_zh_demo \
--cutoff_len 1024 \
--max_samples 1000 \
--per_device_eval_batch_size 128 \
--predict_with_generate True \
--max_new_tokens 512 \
--top_p 0.7 \
--temperature 0.95 \
--output_dir saves/LLaMA3-8B-Chinese-Chat/lora/eval_2024-07-15-23-18-31 \
--do_predict True
训练前
描述一下焦页2-3HF井两次井漏的具体处理过程和结果?
},
{
"input": "描述一下焦xxxxxxxxxxxxxxxxxx果?",
"output": "焦页xxxxxxxxxxxxxxxxxxxxxxxxxx。",
"instruction": ""
},

请为下面的内容提供一个简洁的摘要。\n接方xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx。
{
“output”: “通过对内容的解读,可以形成一个概括性的摘要。\nxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx。”,
“input”: “请为下面的内容提供一个简洁的摘要。\nxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx。”,
“instruction”: “”
},

增加自定义数据集
https://blog.csdn.net/weixin_53162188/article/details/137754362
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template llama3 \
--flash_attn fa2 \
--dataset_dir data \
--dataset qa.json,qa_v3.json,summary_v3.json \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 50 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-07-16-10-48-21 \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--deepspeed cache/ds_z2_config.json
- 后台运行前端项目:如果前端项目是通过终端启动的,可以按下
Ctrl + Z 将其暂停,并使用 bg 命令将其放入后台运行。
- 使用
jobs 命令查看后台作业的列表,找到你想要切换回前台的作业的编号。
- 使用
fg 命令将作业切换回前台。指定作业编号作为参数,例如 fg 1,其中 1 是你要切换回前台的作业编号。
训练期间截图

训练完结果
[INFO|tokenization_utils_base.py:2583] 2024-07-16 19:48:10,724 >> Special tokens file saved in saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-07-16-10-48-21/special_tokens_map.json
***** train metrics *****
epoch = 2.9993
num_input_tokens_seen = 404210112
total_flos = 16998741876GF
train_loss = 0.9822
train_runtime = 9:09:18.13
train_samples_per_second = 11.721
train_steps_per_second = 0.046
Figure saved at: saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-07-16-10-48-21/training_loss.png
评估
llamafactory-cli train \
--stage sft \
--model_name_or_path /home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template llama3 \
--flash_attn auto \
--dataset_dir data \
--eval_dataset qa.json \
--cutoff_len 1024 \
--max_samples 1000 \
--per_device_eval_batch_size 32 \
--predict_with_generate True \
--max_new_tokens 512 \
--top_p 0.7 \
--temperature 0.95 \
--output_dir saves/LLaMA3-8B-Chinese-Chat/lora/eval_2024-07-16-21-08-04 \
--do_predict True
评估结果
***** predict metrics *****
predict_bleu-4 = 5.69
predict_rouge-1 = 25.6939
predict_rouge-2 = 6.2167
predict_rouge-l = 19.1876
predict_runtime = 0:02:50.56
predict_samples_per_second = 5.863
predict_steps_per_second = 0.047
好的,让我们来分析一下这些模型评估结果,以理解模型的效果。
- BLEU-4 (predict_bleu-4 = 5.69)
:
- BLEU(Bilingual Evaluation Understudy)评分是衡量机器翻译和文本生成模型输出质量的常用指标。BLEU-4表示使用4-gram作为基础进行计算。
- 得分5.69表示模型生成的文本与参考文本之间有一定的相似度,但相对较低。一般来说,BLEU-4分数较低可能意味着模型生成的文本不够精确或流畅。
- ROUGE-1 (predict_rouge-1 = 25.6939)
:
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation)评分用于评估文本摘要的质量。ROUGE-1表示使用单个词作为基础进行计算。
- 得分25.6939表示模型生成的摘要与参考摘要在单词层面上有25.6939%的相似度。这在文本生成任务中是一个中等水平的结果。
- ROUGE-2 (predict_rouge-2 = 6.2167)
:
- ROUGE-2表示使用2-gram(成对的连续词)作为基础进行计算。
- 得分6.2167表示模型生成的摘要在2-gram层面上有6.2167%的相似度,这个结果较低,表明模型在捕捉词对关系方面效果不佳。
- ROUGE-L (predict_rouge-l = 19.1876)
:
- ROUGE-L表示使用最长公共子序列(Longest Common Subsequence, LCS)作为基础进行计算。
- 得分19.1876表示模型生成的摘要在LCS层面上有19.1876%的相似度,略高于ROUGE-2,但仍然不算高。
- 预测运行时间 (predict_runtime = 0:02:50.56)
:
- 运行时间为2分50秒,表明模型在预测阶段的计算速度。
- 每秒处理样本数 (predict_samples_per_second = 5.863)
:
- 这个指标表示模型每秒钟可以处理的样本数,5.863个样本每秒,这个速度对于大多数应用来说是可以接受的。
- 每秒步数 (predict_steps_per_second = 0.047)
:
- 这个指标表示模型每秒钟可以完成的预测步数,0.047步每秒,表明每一步预测消耗的时间较多。
综合分析
整体来看,模型的BLEU和ROUGE分数都相对较低,表明模型在生成文本或摘要任务上的效果不理想。特别是ROUGE-2分数较低,说明模型在生成连贯的短语时存在明显问题。
低分数可能的原因包括:
-
训练数据不足或质量不高。
-
模型结构或超参数设置不理想。
-
任务本身的复杂性较高,模型难以捕捉到其中的深层次关系。
如果需要提升模型效果,可以考虑以下几种方法:
-
增加训练数据的量和质量。
-
调整模型的结构和超参数,尝试不同的模型架构。
-
使用更复杂的预训练模型或结合多种技术提升性能。
总的来说,虽然当前模型有一定的效果,但还需要进一步优化以达到更高的性能。2024-7-15 22:34:02
系统环境:
创建conda环境
conda create -n llamafactory python=3.10
拉取代码并安装依赖包
git clone https://github.com/LlamaFamily/Llama-Chinese.git
cd Llama-Chinese
pip install -r requirements.txt
看下当前版本
下载模型
vim download_model.py
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('FlagAlpha/Llama3-Chinese-8B-Instruct',local_dir='./models/FlagAlpha/Llama3-Chinese-8B-Instruct')
local_dir 设置为自己本地地址
进行推理
创建一个名为 quick_start.py 的文件,并将以下内容复制到该文件中。 模型替换为上面自己本地地址
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device_map = "cuda:0" if torch.cuda.is_available() else "auto"
model_id = "/home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_id,device_map=device_map,torch_dtype=torch.float16,load_in_8bit=True,trust_remote_code=True,use_flash_attention_2=True)
model =model.eval()
tokenizer = AutoTokenizer.from_pretrained(model_id,use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
input_ids = tokenizer(['<s>Human: 介绍一下中国\n</s><s>Assistant: '], return_tensors="pt",add_special_tokens=False).input_ids
if torch.cuda.is_available():
input_ids = input_ids.to('cuda')
generate_input = {
"input_ids":input_ids,
"max_new_tokens":512,
"do_sample":True,
"top_k":50,
"top_p":0.95,
"temperature":0.3,
"repetition_penalty":1.3,
"eos_token_id":tokenizer.eos_token_id,
"bos_token_id":tokenizer.bos_token_id,
"pad_token_id":tokenizer.pad_token_id
}
generate_ids = model.generate(**generate_input)
text = tokenizer.decode(generate_ids[0])
print(text)
运行 quick_start.py 代码。
python quick_start.py
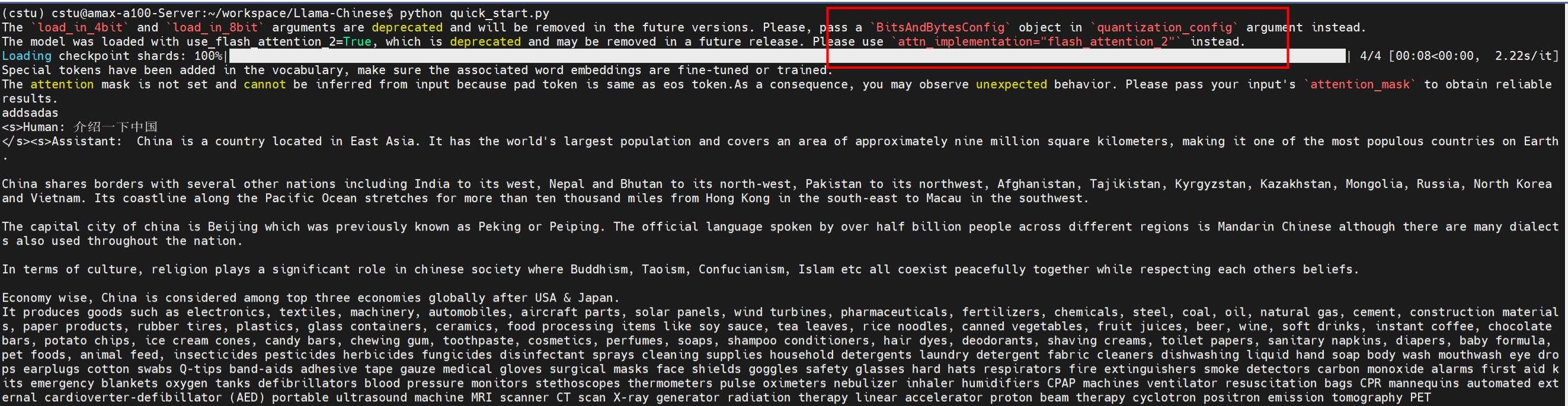
报错如下
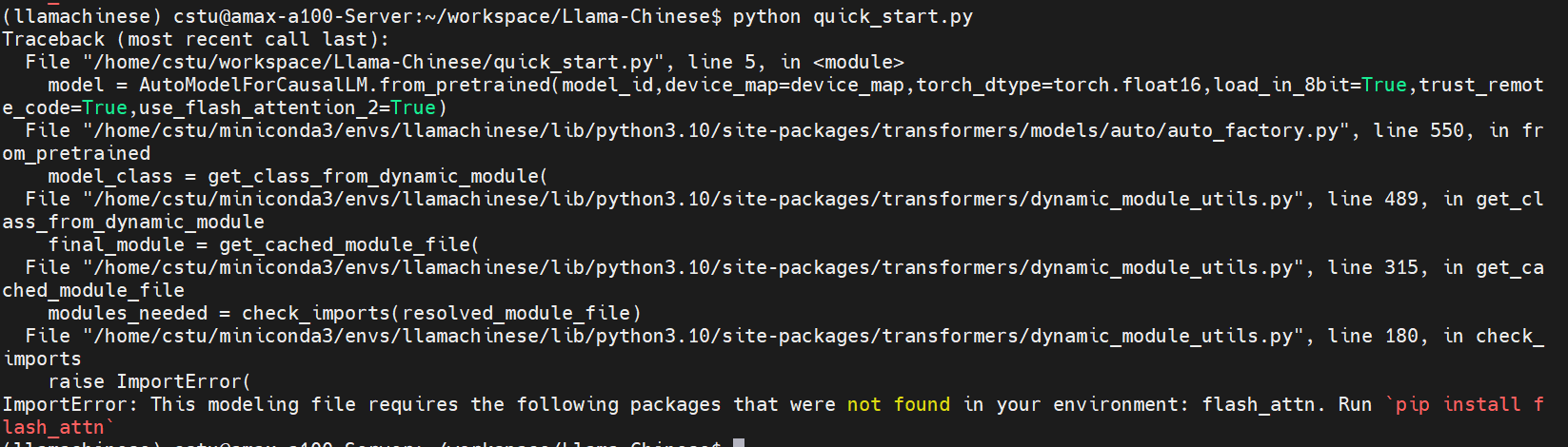
解决
pip install flash_attn
上面的安装很慢,参考快速安装flash-attn
再次运行 quick_start.py,还是有不对
transformers 版本不对
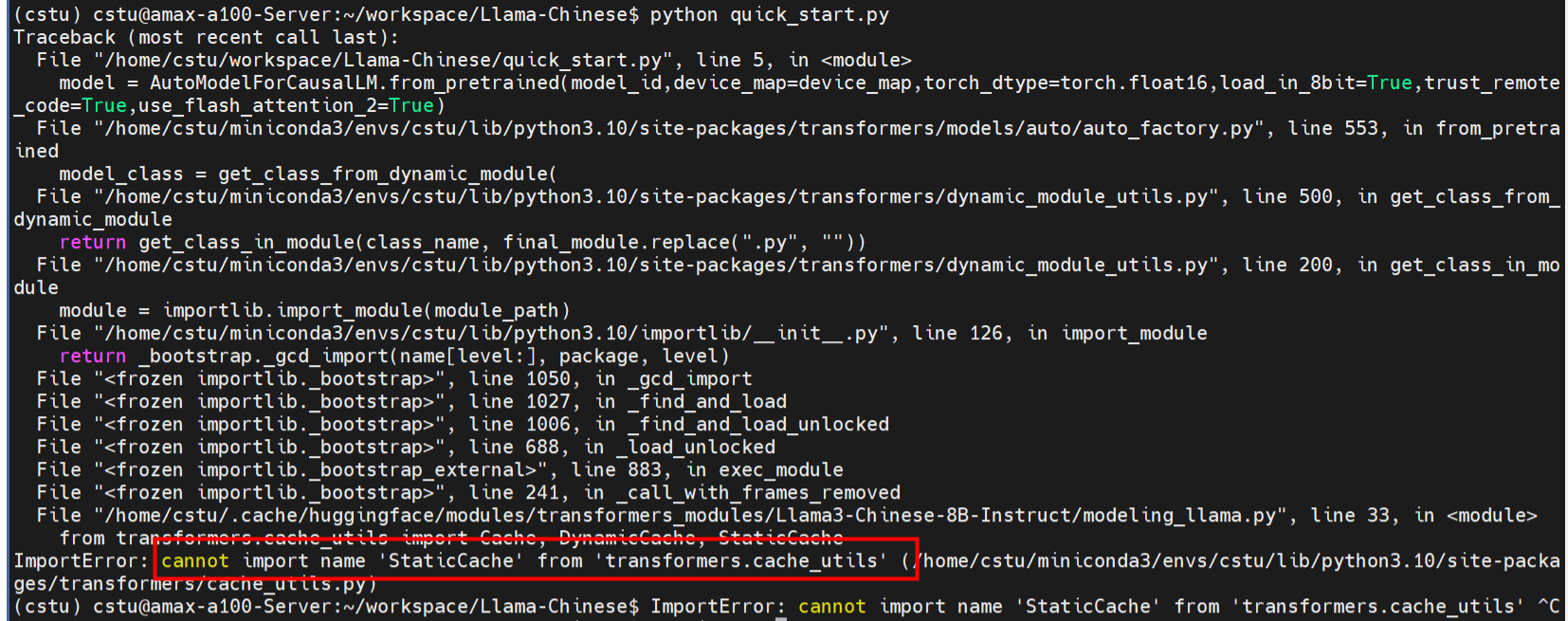
解决
pip uninstall transformers
pip install transformers
启动就能正常显示结果了,但是会有一些warning
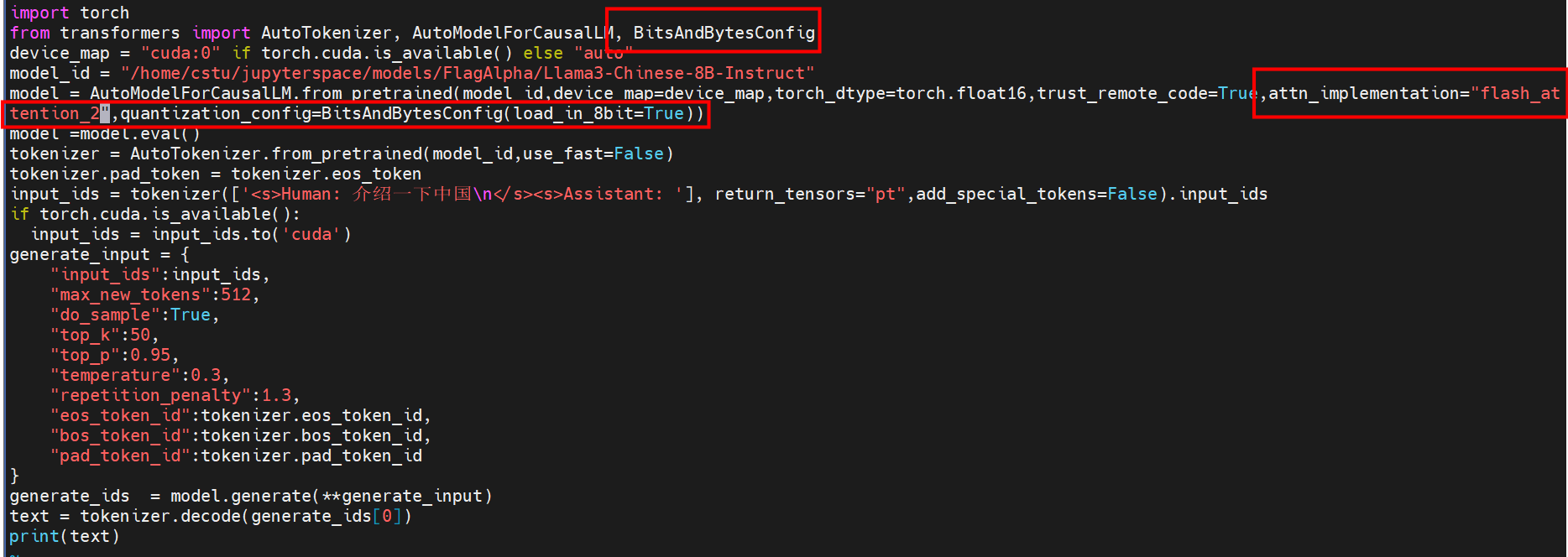
修改位置如下图
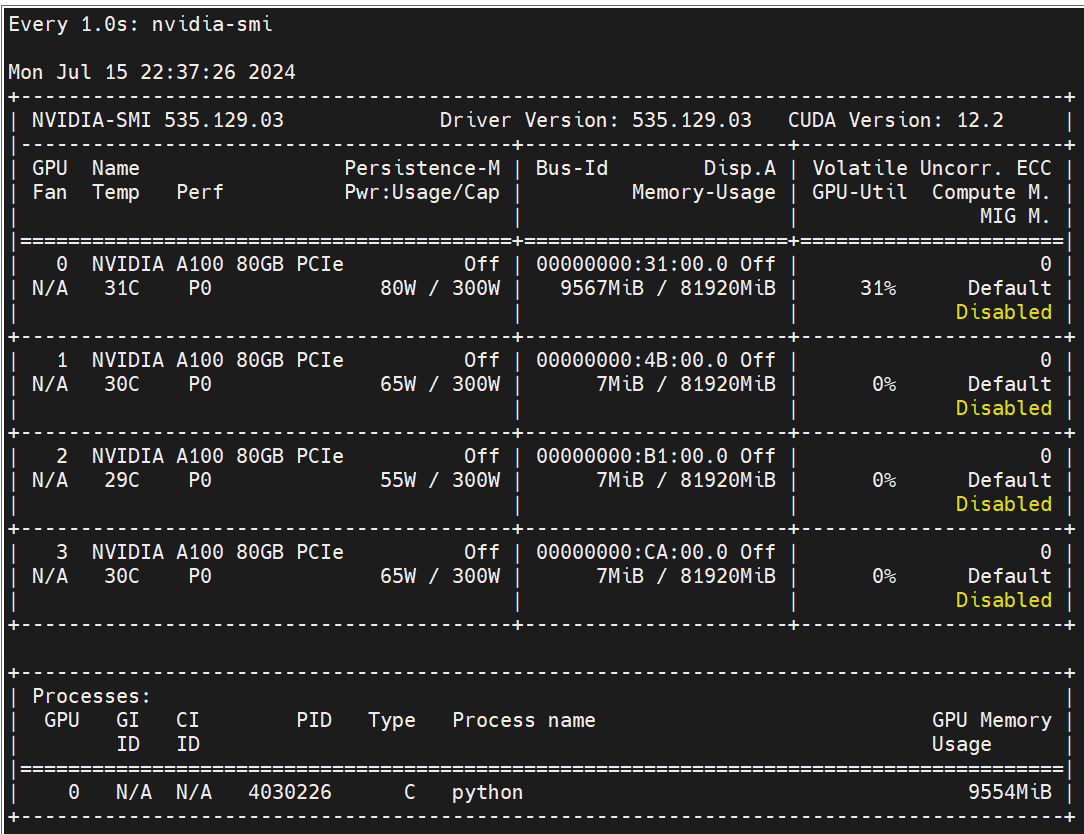
大概占用显存如下
最终结果

快速上手-使用gradio
python examples/chat_gradio.py --model_name_or_path /home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct
默认启动,生成很慢
修改源码
vim examples/chat_gradio.py
启动后大概占用15G多
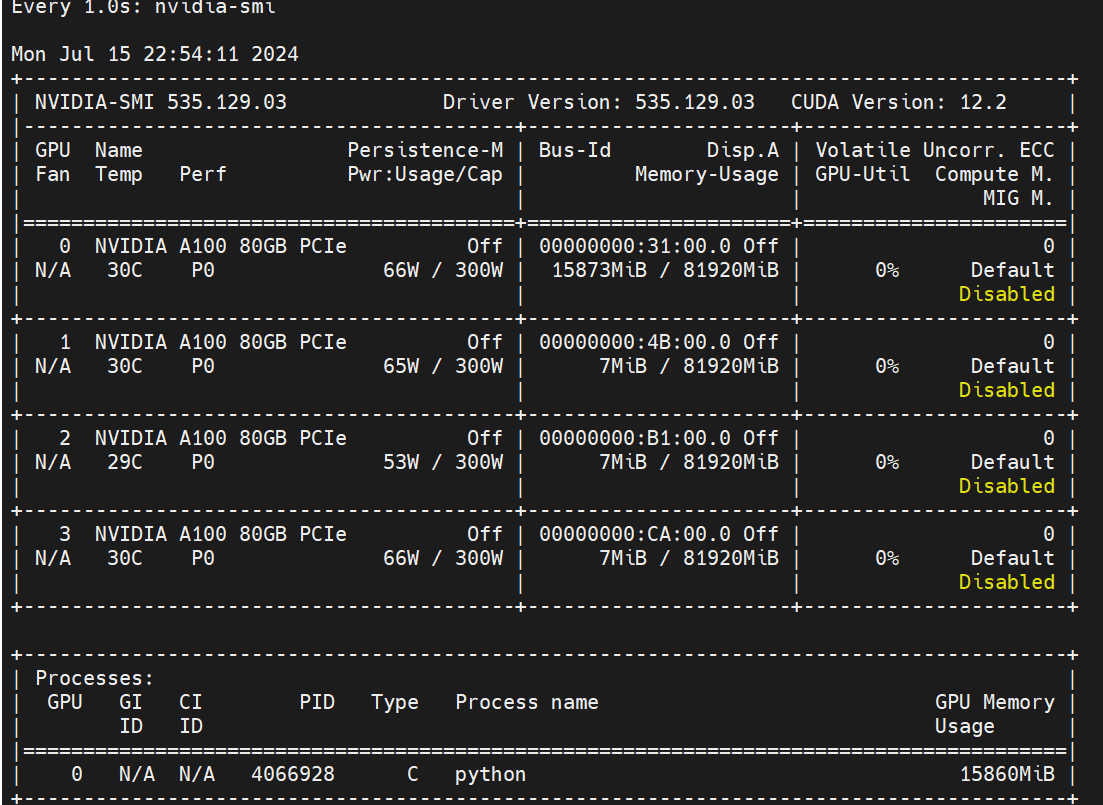
发现输出很慢,而且结果也不是我想要的
后来查看https://huggingface.co/FlagAlpha/Llama3-Chinese-8B-Instruct 根据这里面的使用代码
import transformers
import torch
model_id = "/home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.float16},
device="cuda",
)
messages = [{"role": "system", "content": ""}]
messages.append(
{"role": "user", "content": "介绍一下机器学习"}
)
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=512,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9
)
content = outputs[0]["generated_text"][len(prompt):]
print(content)
这个很快就有结果了

配置完预览命令
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template llama3 \
--flash_attn fa2 \
--dataset_dir data \
--dataset alpaca_zh_demo \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 1000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-07-15-23-18-31 \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
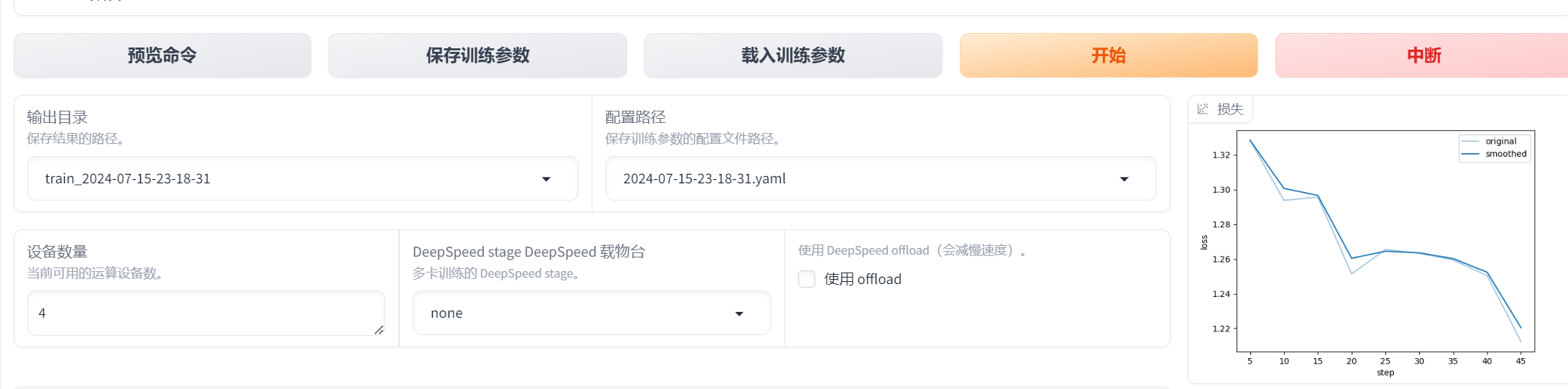
评估
llamafactory-cli train \
--stage sft \
--model_name_or_path /home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template llama3 \
--flash_attn fa2 \
--dataset_dir data \
--eval_dataset alpaca_zh_demo \
--cutoff_len 1024 \
--max_samples 1000 \
--per_device_eval_batch_size 128 \
--predict_with_generate True \
--max_new_tokens 512 \
--top_p 0.7 \
--temperature 0.95 \
--output_dir saves/LLaMA3-8B-Chinese-Chat/lora/eval_2024-07-15-23-18-31 \
--do_predict True
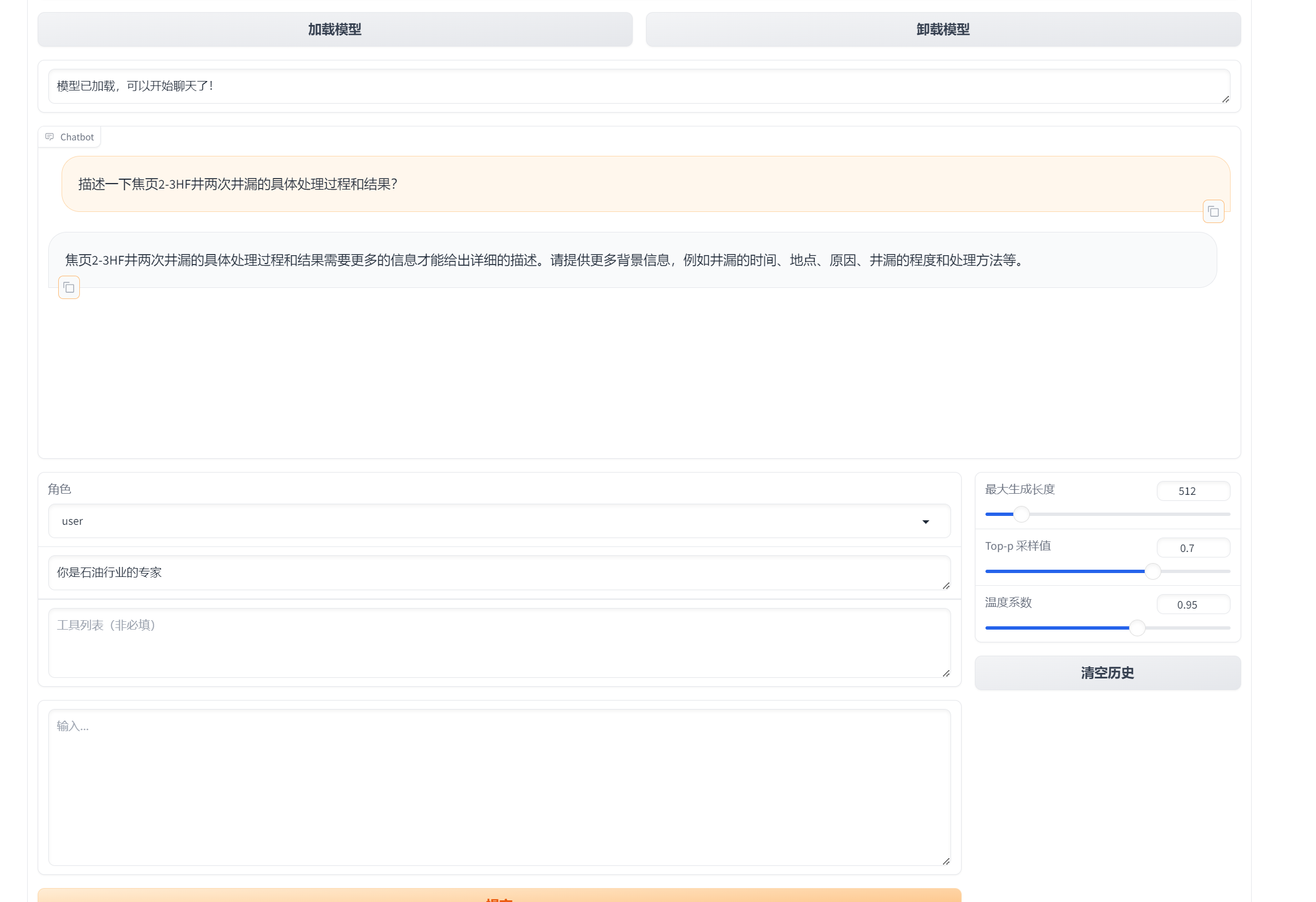
训练前
描述一下焦页2-3HF井两次井漏的具体处理过程和结果?
},
{
"input": "描述一下焦页2-3HF井两次井漏的具体处理过程和结果?",
"output": "焦页2-3HF井在一开钻进期间发生了两次井漏。第一次井漏在168.86m,漏速23.72m³/h,通过加入随钻堵漏材料解决了;第二次井漏在534.55m,堵漏浆注入后井口返出,尝试了不同浓度的堵漏浆并替换钻井液,最终在井深320m处成功堵漏,但存在井口返出的情况。两次共漏失162.89m³的钻井液。",
"instruction": ""
},
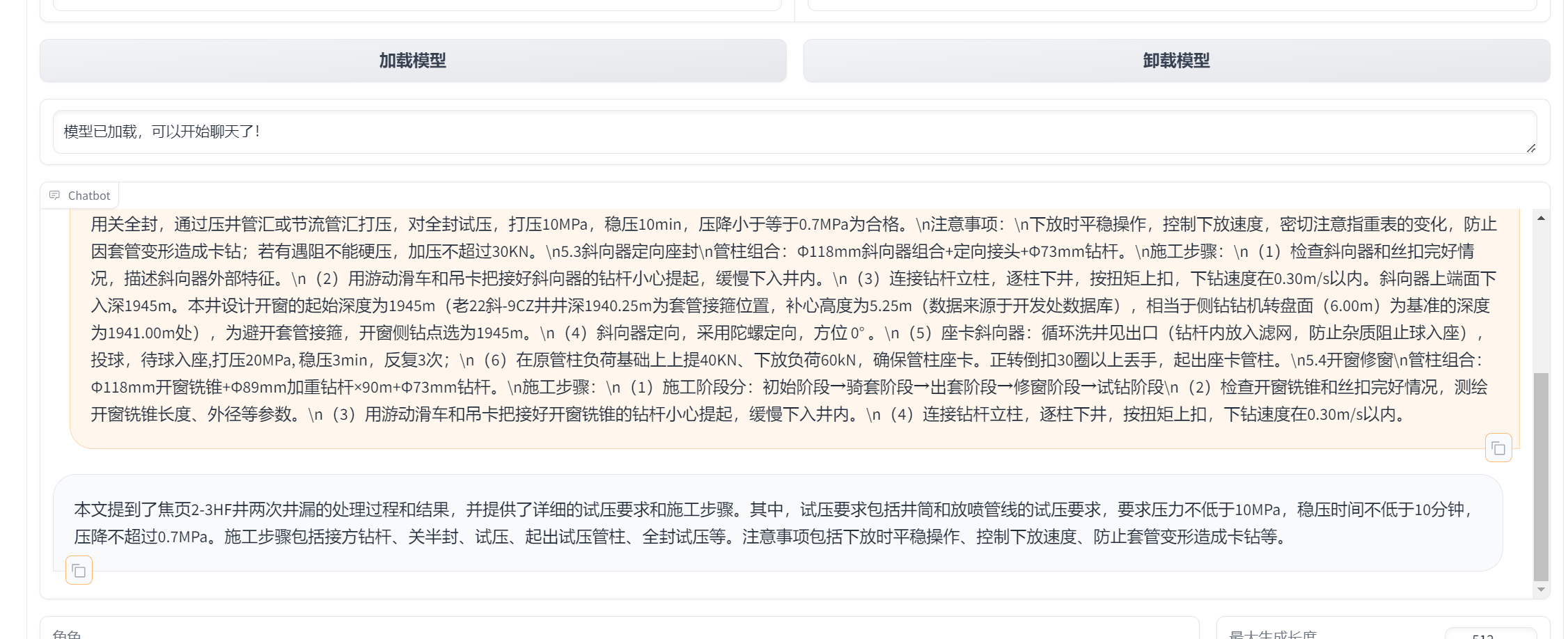
请为下面的内容提供一个简洁的摘要。\n接方钻杆,关半封,泥浆泵打压,对半封、井口、压井管汇、节流管汇及井筒试压。试压要求:井筒打压10MPa,稳压30min,压降小于等于0.5MPa为合格,其余试压10MPa,稳压10min,压降小于等于0.7MPa为合格。放喷管线试压要求10 MPa,稳压10min,压降小于等于0.7MPa为合格。\n(4)起出试压管柱。\n(5)全封、井口试压。\n采用关全封,通过压井管汇或节流管汇打压,对全封试压,打压10MPa,稳压10min,压降小于等于0.7MPa为合格。\n注意事项:\n下放时平稳操作,控制下放速度,密切注意指重表的变化,防止因套管变形造成卡钻;若有遇阻不能硬压,加压不超过30KN。\n5.3斜向器定向座封\n管柱组合:Φ118mm斜向器组合+定向接头+Φ73mm钻杆。\n施工步骤:\n(1)检查斜向器和丝扣完好情况,描述斜向器外部特征。\n(2)用游动滑车和吊卡把接好斜向器的钻杆小心提起,缓慢下入井内。\n(3)连接钻杆立柱,逐柱下井,按扭矩上扣,下钻速度在0.30m/s以内。斜向器上端面下入深1945m。本井设计开窗的起始深度为1945m(老22斜-9CZ井井深1940.25m为套管接箍位置,补心高度为5.25m(数据来源于开发处数据库),相当于侧钻钻机转盘面(6.00m)为基准的深度为1941.00m处),为避开套管接箍,开窗侧钻点选为1945m。\n(4)斜向器定向,采用陀螺定向,方位 0° 。\n(5)座卡斜向器:循环洗井见出口(钻杆内放入滤网,防止杂质阻止球入座),投球,待球入座,打压20MPa, 稳压3min,反复3次;\n(6)在原管柱负荷基础上上提40KN、下放负荷60kN,确保管柱座卡。正转倒扣30圈以上丢手,起出座卡管柱。\n5.4开窗修窗\n管柱组合:Φ118mm开窗铣锥+Φ89mm加重钻杆×90m+Φ73mm钻杆。\n施工步骤:\n(1)施工阶段分:初始阶段→骑套阶段→出套阶段→修窗阶段→试钻阶段\n(2)检查开窗铣锥和丝扣完好情况,测绘开窗铣锥长度、外径等参数。\n(3)用游动滑车和吊卡把接好开窗铣锥的钻杆小心提起,缓慢下入井内。\n(4)连接钻杆立柱,逐柱下井,按扭矩上扣,下钻速度在0.30m/s以内。
{
“output”: “通过对内容的解读,可以形成一个概括性的摘要。\n施工过程中,首先进行接方钻杆、关半封、打压井口设备和井筒试压,要求分别满足不同压力下的稳压和压降标准。然后进行全封试压,强调平稳操作和监控压力变化。斜向器定向座封步骤包括检查工具、下入井内、定向、座卡以及确认管柱座卡。开窗修窗则涉及多个阶段,检查工具、下入、连接钻杆、修窗和试钻,每个阶段都有严格的操作要求。”,
“input”: “请为下面的内容提供一个简洁的摘要。\n接方钻杆,关半封,泥浆泵打压,对半封、井口、压井管汇、节流管汇及井筒试压。试压要求:井筒打压10MPa,稳压30min,压降小于等于0.5MPa为合格,其余试压10MPa,稳压10min,压降小于等于0.7MPa为合格。放喷管线试压要求10 MPa,稳压10min,压降小于等于0.7MPa为合格。\n(4)起出试压管柱。\n(5)全封、井口试压。\n采用关全封,通过压井管汇或节流管汇打压,对全封试压,打压10MPa,稳压10min,压降小于等于0.7MPa为合格。\n注意事项:\n下放时平稳操作,控制下放速度,密切注意指重表的变化,防止因套管变形造成卡钻;若有遇阻不能硬压,加压不超过30KN。\n5.3斜向器定向座封\n管柱组合:Φ118mm斜向器组合+定向接头+Φ73mm钻杆。\n施工步骤:\n(1)检查斜向器和丝扣完好情况,描述斜向器外部特征。\n(2)用游动滑车和吊卡把接好斜向器的钻杆小心提起,缓慢下入井内。\n(3)连接钻杆立柱,逐柱下井,按扭矩上扣,下钻速度在0.30m/s以内。斜向器上端面下入深1945m。本井设计开窗的起始深度为1945m(老22斜-9CZ井井深1940.25m为套管接箍位置,补心高度为5.25m(数据来源于开发处数据库),相当于侧钻钻机转盘面(6.00m)为基准的深度为1941.00m处),为避开套管接箍,开窗侧钻点选为1945m。\n(4)斜向器定向,采用陀螺定向,方位 0° 。\n(5)座卡斜向器:循环洗井见出口(钻杆内放入滤网,防止杂质阻止球入座),投球,待球入座,打压20MPa, 稳压3min,反复3次;\n(6)在原管柱负荷基础上上提40KN、下放负荷60kN,确保管柱座卡。正转倒扣30圈以上丢手,起出座卡管柱。\n5.4开窗修窗\n管柱组合:Φ118mm开窗铣锥+Φ89mm加重钻杆×90m+Φ73mm钻杆。\n施工步骤:\n(1)施工阶段分:初始阶段→骑套阶段→出套阶段→修窗阶段→试钻阶段\n(2)检查开窗铣锥和丝扣完好情况,测绘开窗铣锥长度、外径等参数。\n(3)用游动滑车和吊卡把接好开窗铣锥的钻杆小心提起,缓慢下入井内。\n(4)连接钻杆立柱,逐柱下井,按扭矩上扣,下钻速度在0.30m/s以内。”,
“instruction”: “”
},
增加自定义数据集
https://blog.csdn.net/weixin_53162188/article/details/137754362
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template llama3 \
--flash_attn fa2 \
--dataset_dir data \
--dataset qa.json,qa_v3.json,summary_v3.json \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 50 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-07-16-10-48-21 \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--deepspeed cache/ds_z2_config.json
- 后台运行前端项目:如果前端项目是通过终端启动的,可以按下
Ctrl + Z 将其暂停,并使用 bg 命令将其放入后台运行。
- 使用
jobs 命令查看后台作业的列表,找到你想要切换回前台的作业的编号。
- 使用
fg 命令将作业切换回前台。指定作业编号作为参数,例如 fg 1,其中 1 是你要切换回前台的作业编号。
训练期间截图
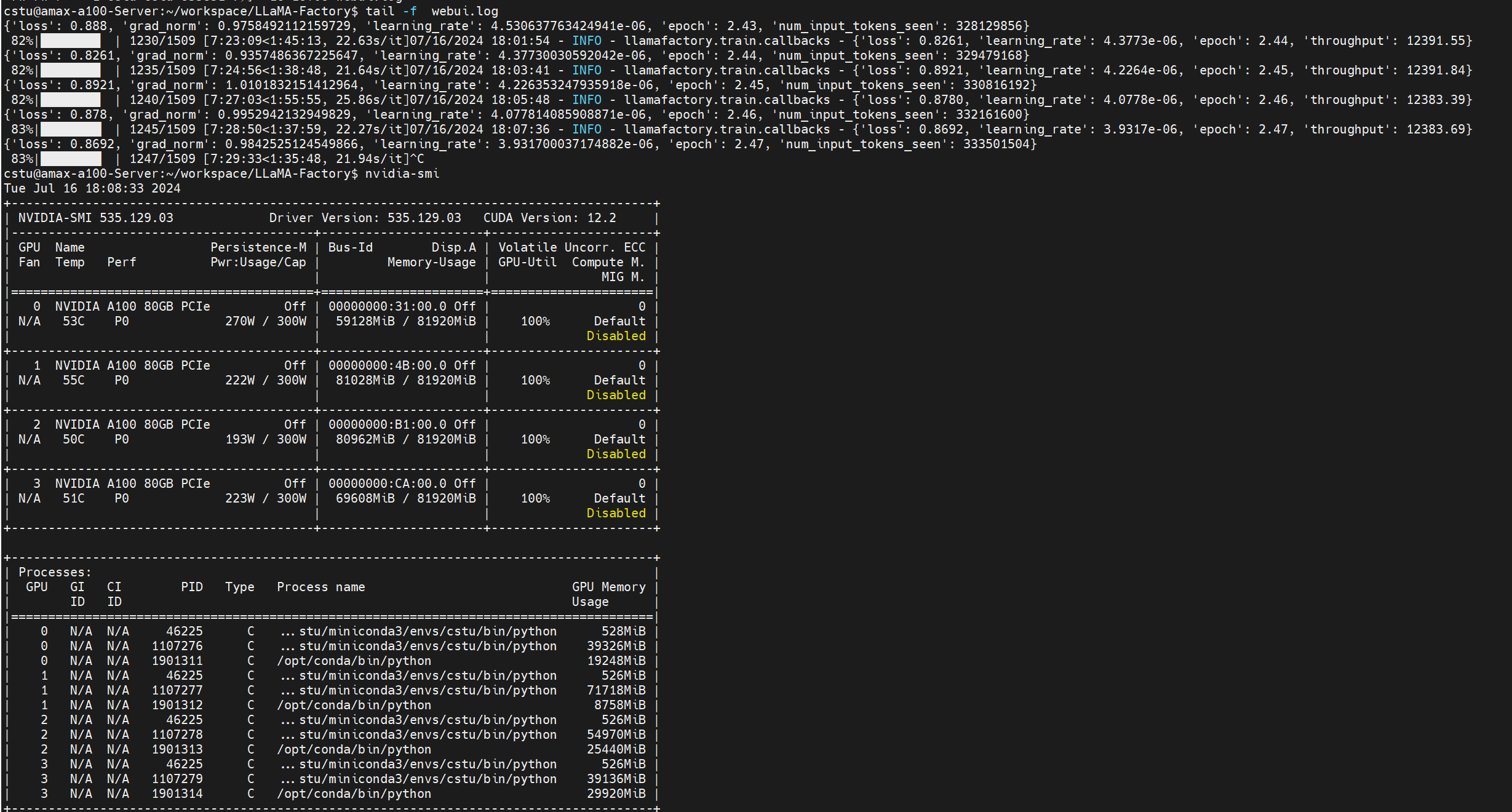
训练完结果
[INFO|tokenization_utils_base.py:2583] 2024-07-16 19:48:10,724 >> Special tokens file saved in saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-07-16-10-48-21/special_tokens_map.json
***** train metrics *****
epoch = 2.9993
num_input_tokens_seen = 404210112
total_flos = 16998741876GF
train_loss = 0.9822
train_runtime = 9:09:18.13
train_samples_per_second = 11.721
train_steps_per_second = 0.046
Figure saved at: saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-07-16-10-48-21/training_loss.png
评估
llamafactory-cli train \
--stage sft \
--model_name_or_path /home/cstu/jupyterspace/models/FlagAlpha/Llama3-Chinese-8B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template llama3 \
--flash_attn auto \
--dataset_dir data \
--eval_dataset qa.json \
--cutoff_len 1024 \
--max_samples 1000 \
--per_device_eval_batch_size 32 \
--predict_with_generate True \
--max_new_tokens 512 \
--top_p 0.7 \
--temperature 0.95 \
--output_dir saves/LLaMA3-8B-Chinese-Chat/lora/eval_2024-07-16-21-08-04 \
--do_predict True
评估结果
***** predict metrics *****
predict_bleu-4 = 5.69
predict_rouge-1 = 25.6939
predict_rouge-2 = 6.2167
predict_rouge-l = 19.1876
predict_runtime = 0:02:50.56
predict_samples_per_second = 5.863
predict_steps_per_second = 0.047
好的,让我们来分析一下这些模型评估结果,以理解模型的效果。
- BLEU-4 (predict_bleu-4 = 5.69)
:
- BLEU(Bilingual Evaluation Understudy)评分是衡量机器翻译和文本生成模型输出质量的常用指标。BLEU-4表示使用4-gram作为基础进行计算。
- 得分5.69表示模型生成的文本与参考文本之间有一定的相似度,但相对较低。一般来说,BLEU-4分数较低可能意味着模型生成的文本不够精确或流畅。
- ROUGE-1 (predict_rouge-1 = 25.6939)
:
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation)评分用于评估文本摘要的质量。ROUGE-1表示使用单个词作为基础进行计算。
- 得分25.6939表示模型生成的摘要与参考摘要在单词层面上有25.6939%的相似度。这在文本生成任务中是一个中等水平的结果。
- ROUGE-2 (predict_rouge-2 = 6.2167)
:
- ROUGE-2表示使用2-gram(成对的连续词)作为基础进行计算。
- 得分6.2167表示模型生成的摘要在2-gram层面上有6.2167%的相似度,这个结果较低,表明模型在捕捉词对关系方面效果不佳。
- ROUGE-L (predict_rouge-l = 19.1876)
:
- ROUGE-L表示使用最长公共子序列(Longest Common Subsequence, LCS)作为基础进行计算。
- 得分19.1876表示模型生成的摘要在LCS层面上有19.1876%的相似度,略高于ROUGE-2,但仍然不算高。
- 预测运行时间 (predict_runtime = 0:02:50.56)
:
- 运行时间为2分50秒,表明模型在预测阶段的计算速度。
- 每秒处理样本数 (predict_samples_per_second = 5.863)
:
- 这个指标表示模型每秒钟可以处理的样本数,5.863个样本每秒,这个速度对于大多数应用来说是可以接受的。
- 每秒步数 (predict_steps_per_second = 0.047)
:
- 这个指标表示模型每秒钟可以完成的预测步数,0.047步每秒,表明每一步预测消耗的时间较多。
综合分析
整体来看,模型的BLEU和ROUGE分数都相对较低,表明模型在生成文本或摘要任务上的效果不理想。特别是ROUGE-2分数较低,说明模型在生成连贯的短语时存在明显问题。
低分数可能的原因包括:
-
训练数据不足或质量不高。
-
模型结构或超参数设置不理想。
-
任务本身的复杂性较高,模型难以捕捉到其中的深层次关系。
如果需要提升模型效果,可以考虑以下几种方法:
-
增加训练数据的量和质量。
-
调整模型的结构和超参数,尝试不同的模型架构。
-
使用更复杂的预训练模型或结合多种技术提升性能。
总的来说,虽然当前模型有一定的效果,但还需要进一步优化以达到更高的性能。2024-7-15 22:34:02


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









