






前言
为什么突然就说到了向量数据库呢?向量数据库对于我们对接AI来说有什么用呢?
从个人目前所做的事情来看,简单地说,就是可以解决AI接收Token数有限的问题,提前从海量知识库中提取问题关联的知识,针对性地提供Prompt给AI。
比方说,你有一本唐诗三百首,你希望AI随时帮你解答某个诗句的出处,但是4000到40000个Token数显然装不下你这整本书,那怎么办呢?可以把每首诗拿出来计算成向量并存下,然后通过向量计算近似语义,找到和你提问最关联的若干诗词,然后再交给AI进行鉴赏评析,最终就可以给出合理的答案了。
实践
本篇内容会延续之前,为AI对接指标解析API的工作补充一些内容。
一、开通pinecone
为什么是pinecone呢?因为免费… (0.0) 因为LangChain本身支持多种向量计算组件,所以这里从中随机选择了pinecone
网址:https://app.pinecone.io/
pinecone免费账号只能创建一个index
1、进去后注册账号即可进入管理界面,然后点击界面上的 Create Index 即可开始创建向量存储库
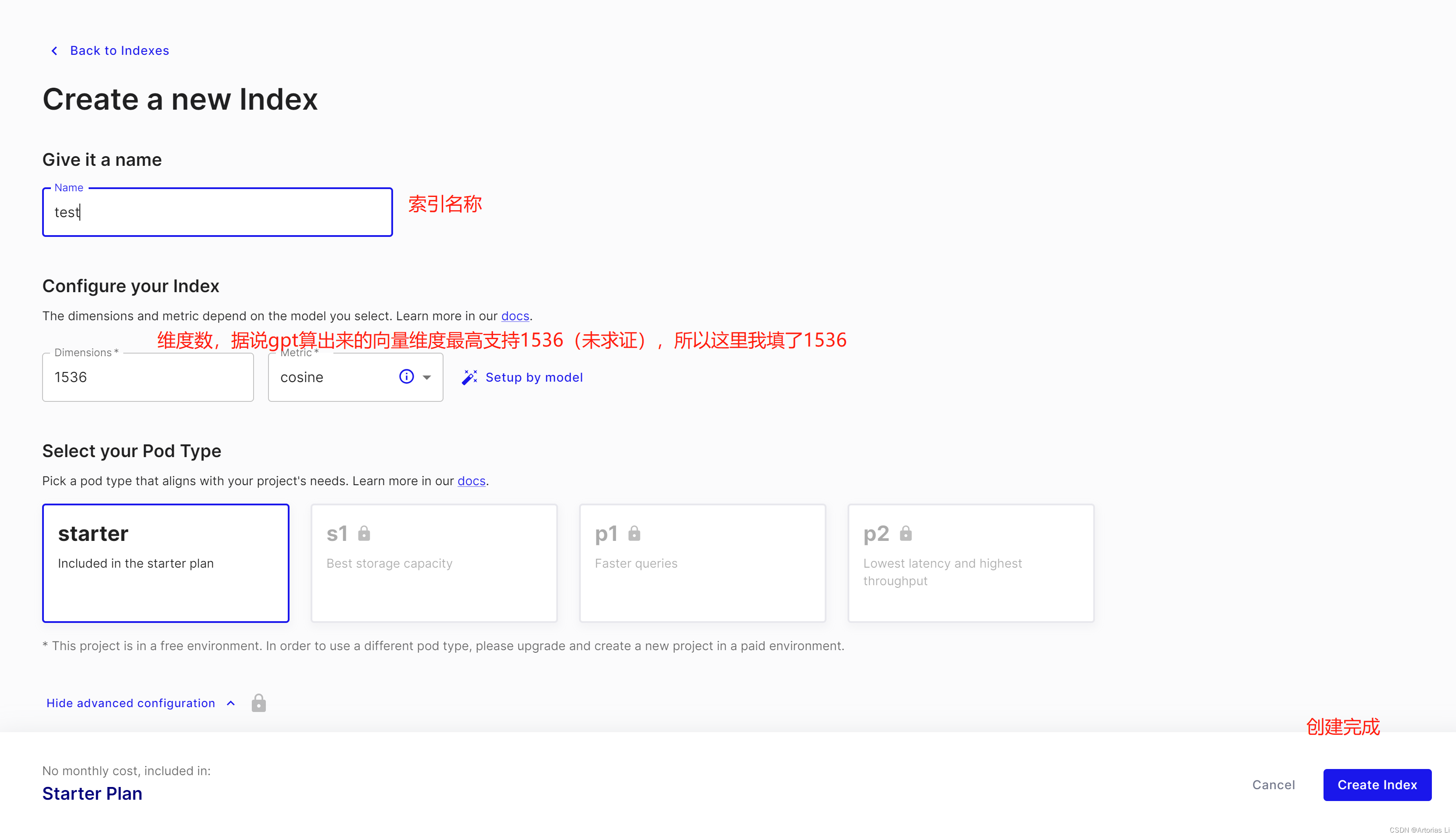
2、创建完成后,可以在左边栏找到API KEY等配置

二、pinecone的初始化、新增更新、删除、查询
这里我们封装一个类,然后开始一步步填充内容进去(libs/dims.py)
1、初始化
import openai
import pinecone
class Dims:
api_key = "xxxxxxxx" # 上一步开通pinecone时获得的API KEY
environment = "gcp-starter"
index = None
def __init__(self):
# 初始化索引
pinecone.init(api_key=self.api_key, environment=self.environment)
active_indexes = pinecone.list_indexes()
self.index = pinecone.Index(active_indexes[0])
2、使用openai计算向量
"""
使用llm计算向量
"""
def computeVec(self, name):
# 通过openai计算embedding向量
embedding_res = openai.Embedding.create(
engine="text-embedding-ada-002",
input=name
)
return embedding_res['data'][0]['embedding']
3、读取配置文件,upsert到pinecone
使用时只需要创建Dims对象,然后调用该方法将配置文件中的维度知识初始换到pinecone即可
"""
初始化,从维度文件导入到pinecone
"""
def upsertDims(self):
# 获取所有维度信息 此处配置文件格式:
# 天 day
# 月 month
# 游戏 game
# ......
file = open('data/dims.txt', 'r')
content = file.read()
file.close()
# 文件内容按行拆分
content = content.split("\n")
embedding_data = []
for msg in content:
# 每行按tab拆分
msg_sp = msg.split("\t")
# 维度名
name = msg_sp[0]
# 维度KEY
key = msg_sp[1]
# 生成知识库embedding vector
embedding_res = self.computeVec(name)
# 记录需要upsert的数据
embedding_data.append((key, embedding_res, {"data": msg}))
# 更新知识库向量以及对应的元数据
return self.index.upsert(embedding_data)
4、向量近似查询
"""
查找给定名称最近似的num个维度
"""
def search(self, name, num):
# 通过openai计算embedding向量
embedding_res = self.computeVec(name)
# 通过pinecone查询最近似的num个数据
prompt_res = self.index.query(
embedding_res,
top_k=num,
include_metadata=True
)
# 取出相近维度
contexts = [item['metadata']['data'] for item in prompt_res['matches']]
return contexts
三、pinecone做成LangChain工具
工具关键的属性需要有名称、描述,以及一个是否直接返回结果的标识(return_direct,如同名称含义,如果调用了这个工具,那么这个工具的输出将直接作为整个链的结果返回,不再继续反哺和思考)
这里先做一个维度搜索工具,用来接收用户输入的维度名称,并去知识库查找最近似的知识。
(tools/search_dim.py)
from typing import Any
from langchain.tools import BaseTool
from lib.dims import Dims
class DimSearchTool(BaseTool):
name = "维度搜索"
description = "用于查找维度定义"
def __init__(self, **data: Any):
super().__init__(**data)
def _run(self, query: str) -> str:
"""使用工具。"""
dims = query.split("、")
contexts = []
dim_tool = Dims()
for dim in dims:
# 取出相近指标
contexts += dim_tool.search(dim, 1)
return "\n".join(contexts) + "\n"
async def _arun(self, query: str) -> str:
"""异步使用工具。"""
raise NotImplementedError("不支持异步")
然后用同一个类复制出来改改,再做两个几乎一样的Tool(MetaSearchTool和FilterSearchTool)
PS. 这是因为每个免费pinecone账号只能有一个库,SO……
四、用Agent串联pinecone工具,组装AI的左手
现在三个工具准备好了,目前有两种使用方法:交给LangChain通过提示来自动选择、手动控制使用流程。按照第二节流程,我们已经从对话的自然语言中解析出来了含名称的Json,所以解下来明确是需要依次使用三个工具依次替换的,所以是否自动选择并不是重要。
{
"metas": ["广告费"],
"dims": ["月"],
"filters": {"游戏":"游戏名称", "时间":"2023年上半年"}
}
所以这里为了减少调教Prompt准确性的时间,就直接写死三个工具的处理流程了。
不过由于我目前对于LangChain不是很熟练,不是很清楚如何判断和记录Agent的状态,所以就遍历历史步骤中用过的工具,然后再确定下一步该用的工具了。
这里建议可以自行翻阅文档找到更合适的实现方式。
(agents/prompt_agent.py)
import json
from typing import List, Tuple, Any, Union
from langchain.agents import BaseSingleActionAgent
from langchain.schema import AgentAction, AgentFinish
class PrepareAgent(BaseSingleActionAgent):
prompt_pared = {}
@property
def input_keys(self):
return ["input"]
def plan(self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any) -> Union[AgentAction, AgentFinish]:
"""Given input, decided what to do.
Args:
intermediate_steps: Steps the LLM has taken to date, along with observations
**kwargs: User inputs.
Returns:
Action specifying what tool to use.
"""
inputs = json.loads(kwargs["input"])
metas = inputs['metas']
dims = inputs['dims']
filters = inputs['filters']
step = 0
prompt = ""
for item in intermediate_steps:
action = item[0]
output = item[1]
if action.tool == '指标定义':
self.prompt_pared['metas'] = output
step += 1
prompt += "指标:\n" + output + "\n"
if action.tool == '维度搜索':
self.prompt_pared['dims'] = output
step += 1
prompt += "维度:\n" + output
if action.tool == '筛选搜索':
self.prompt_pared['dims'] += output
step += 1
prompt += output + "\n"
if step == 0:
tool_input = "、".join(metas)
return AgentAction(tool="指标定义", tool_input=tool_input, log="现在需要使用指标定义搜索工具获取指标相关定义\n")
elif step == 1:
tool_input = "、".join(dims)
return AgentAction(tool="维度搜索", tool_input=tool_input, log="现在需要使用维度搜索工具获取维度信息\n")
elif step == 2:
tmp = []
for item in filters:
tmp.append(item)
tool_input = "、".join(tmp)
return AgentAction(tool="筛选搜索", tool_input=tool_input, log="现在需要使用筛选搜索工具获取筛选名称\n")
else:
return_values = prompt + kwargs["input"]
return AgentFinish(return_values={"output": return_values}, log="prompt准备完毕\n")
async def aplan(
self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any
) -> Union[AgentAction, AgentFinish]:
"""Given input, decided what to do.
Args:
intermediate_steps: Steps the LLM has taken to date,
along with observations
**kwargs: User inputs.
Returns:
Action specifying what tool to use.
"""
return AgentFinish(return_values={"output": ""}, log="不支持异步\n")
在这个Agent内显式地控制了三个工具的使用流程:先查指标的prompt,再查维度和筛选的,最后组装起来成为完整的prompt。
五、用Agent做API请求,组装AI的右手
一个简单的接收参数然后去请求接口的代理
import json
import requests
from typing import List, Tuple, Any, Union
from langchain.agents import BaseSingleActionAgent
from langchain.schema import AgentAction, AgentFinish
class HennaAgent(BaseSingleActionAgent):
@property
def input_keys(self):
return ["input"]
def plan(self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any) -> Union[AgentAction, AgentFinish]:
inputs = kwargs["input"]
# 前面得到的json是便于用户查看的阅读格式,这里借用json的编解码转换成没有空格、换行等字符的json
inputs = json.loads(inputs)
inputs = json.dumps(inputs)
headers = {'host': 'henna url'}
url = "http://192.168.1.1/xxxx.php"
response = requests.post(url, inputs, headers=headers)
return AgentFinish(return_values={"output": response.text}, log="请求完毕\n")
async def aplan(
self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any
) -> Union[AgentAction, AgentFinish]:
return AgentFinish(return_values={"output": ""}, log="不支持异步\n")
六、串联所有chain、agent、tools来解决问题
import os
import time
from tornado.httpserver import HTTPServer
import include
import tornado.ioloop
import tornado.web
from langchain.agents import AgentExecutor
from langchain.chains import SimpleSequentialChain
from agents.henna_agent import HennaAgent
from agents.prepare_agent import PrepareAgent, prompt_pared
from chains.convert_chain import convert_chain
from chains.split_chain import split_chain
from lib.tools import henna_result_convert
from tools.search_dim import DimSearchTool
from tools.search_filter import FilterSearchTool
from tools.search_meta import MetaSearchTool
from tornado.options import options, define
# 这里配置的是日志的路径,配置好后控制台的相应信息就会保存到目标路径中。
options.log_file_prefix = os.path.join(os.path.dirname(__file__), 'logs/tornado_main.log')
class MainHandler(tornado.web.RequestHandler):
def get(self):
question = self.get_argument('question', default='', strip=True)
tools = [
MetaSearchTool(),
DimSearchTool(),
FilterSearchTool(),
]
agent = PrepareAgent()
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)
henna = HennaAgent()
henna_executor = AgentExecutor.from_agent_and_tools(agent=henna, tools=(), verbose=True)
overall_chain = SimpleSequentialChain(chains=[split_chain, agent_executor, convert_chain, henna_executor],
verbose=True)
result = overall_chain.run(question)
show_data = henna_result_convert(result, prompt_pared)
show_str = '<table border="1">'
for item in show_data:
show_str += "<tr>"
for val in item:
show_str += "<td>" + val + "</td>"
show_str += "</tr>"
show_str += "</table>"
self.write(show_str)
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
], debug=True)
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
我们通过浏览器访问
http://127.0.0.1:8888/?question=xxx平台2023年9月游戏xxxxxx的充值金额、广告费、注册人数、1-3日留存,维度按天、游戏、游戏品类,筛选币种usd、时区Asia/Shanghai
可以后台看到执行流程,对自然语言进行识别、转换后,去向量库搜索了相关知识并组装,最终提交到指标中心进行海娜获取数据。
> Entering new SimpleSequentialChain chain...
> Entering new LLMChain chain...
Prompt after formatting:
Recognize all the meta names, dimension names, and filters in the given sentence, return them is json format.
常用时区:
美国:America/New_York
中国、港澳台:Asia/Shanghai
日本:Asia/Tokyo
韩国:Asia/Seoul
欧洲:Europe/Minsk
东南亚:Asia/Bangkok
UTC:UTC
example:
Sentence:xxxx平台游戏1、2在2023年第二季度充值金额、退款金额、广告费,按天、渠道维度,筛选币种为rmb、美国时区、
Result:
{
"metas": ["充值金额", "退款金额", "广告费"],
"dims": ["天", "渠道"],
"filters": {"平台":"xxxx", "游戏":"1,2", "时间":"2023年第二季度", "币种":"rmb", "时区":"America/New_York"}
}
Sentence: xxxx平台2023年9月游戏xxxxxx的充值金额、广告费、注册人数、1-3日留存,维度按天、游戏、游戏品类,筛选币种usd、时区Asia/Shanghai
Result:
> Finished chain.
{
"metas": ["充值金额", "广告费", "注册人数", "1-3日留存"],
"dims": ["天", "游戏", "游戏品类"],
"filters": {"平台":"xxxx", "游戏":"xxxxxx", "时间":"2023年9月", "币种":"usd", "时区":"Asia/Shanghai"}
}
> Entering new AgentExecutor chain...
现在需要使用指标定义搜索工具获取指标相关定义
充值金额 p-s-pay_money-p
广告费 adf-s-cost_money-c
注册人数 r-cd-login_account-r
*日留存数 u-s-day_*-d
现在需要使用维度搜索工具获取维度信息
天 tj_day
游戏 tj_sole_gid
游戏品类 tj_game_type
现在需要使用筛选搜索工具获取筛选名称
平台 tj_pid
游戏 tj_sole_gid
小时 tj_hour
币种 tj_mtype
时区 tj_tzone
prompt准备完毕
> Finished chain.
指标:
充值金额 p-s-pay_money-p
广告费 adf-s-cost_money-c
注册人数 r-cd-login_account-r
*日留存数 u-s-day_*-d
维度:
天 tj_day
游戏 tj_sole_gid
游戏品类 tj_game_type
平台 tj_pid
游戏 tj_sole_gid
小时 tj_hour
币种 tj_mtype
时区 tj_tzone
{
"metas": ["充值金额", "广告费", "注册人数", "1-3日留存"],
"dims": ["天", "游戏", "游戏品类"],
"filters": {"平台":"xxxx", "游戏":"xxxxxx", "时间":"2023年9月", "币种":"usd", "时区":"Asia/Shanghai"}
}
> Entering new LLMChain chain...
Prompt after formatting:
Use the given meta and dimension and filter definition, convert mata and dimension and filter names to code.
If '*' exist, use number mentioned in the name instead.
Current time is 2023-12-28 10:25:42, convert the filters '时间' into start_date and end_date.
example:
指标:
充值金额 p-s-pay_money-p
*日留存数 u-s-day_*-d
维度:
天 tj_day
渠道 tj_sole_cid
{
"metas": ["充值金额", "1-2日留存数"],
"dims": ["天"],
"filters": {"时间":"2023年","渠道":"109,110"}
}
Result:
{
"metas": ["p-s-pay_money-p", "u-s-day_1-d", "u-s-day_2-d"],
"dims": ["tj_day"],
"filters": {"start_date":"2023-01-01 00:00:00", "end_date":"2023-12-31 23:59:59", "tj_sole_cid": "109,110"}
}
指标:
充值金额 p-s-pay_money-p
广告费 adf-s-cost_money-c
注册人数 r-cd-login_account-r
*日留存数 u-s-day_*-d
维度:
天 tj_day
游戏 tj_sole_gid
游戏品类 tj_game_type
平台 tj_pid
游戏 tj_sole_gid
小时 tj_hour
币种 tj_mtype
时区 tj_tzone
{
"metas": ["充值金额", "广告费", "注册人数", "1-3日留存"],
"dims": ["天", "游戏", "游戏品类"],
"filters": {"平台":"xxxx", "游戏":"xxxxxx", "时间":"2023年9月", "币种":"usd", "时区":"Asia/Shanghai"}
}
Result:
> Finished chain.
{
"metas": ["p-s-pay_money-p", "adf-s-cost_money-c", "r-cd-login_account-r", "u-s-day_1-d", "u-s-day_2-d", "u-s-day_3-d"],
"dims": ["tj_day", "tj_sole_gid", "tj_game_type"],
"filters": {"tj_pid":"xxxx", "tj_sole_gid":"xxxxxx", "start_date":"2023-09-01 00:00:00", "end_date":"2023-09-30 23:59:59", "tj_mtype":"usd", "tj_tzone":"Asia/Shanghai"}
}
> Entering new AgentExecutor chain...
{"metas": ["p-s-pay_money-p", "adf-s-cost_money-c", "r-cd-login_account-r", "u-s-day_1-d", "u-s-day_2-d", "u-s-day_3-d"], "dims": ["tj_day", "tj_sole_gid", "tj_game_type"], "filters": {"tj_pid": "xxxx", "tj_sole_gid": "xxxxxx", "start_date": "2023-09-01 00:00:00", "end_date": "2023-09-30 23:59:59", "tj_mtype": "usd", "tj_tzone": "Asia/Shanghai"}}
海娜请求完毕
> Finished chain.
{"data":{...此处不展示实际数据...}}
> Finished chain.
页面显示的部分内容
















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









