






目录
1 论文阅读与学习
1.1 ResNet
深度残差网络
论文Deep Residual Learning for Image Recognition提出了一种残差学习框架来减轻网络训练,这些网络比以前使用的网络更深。将层变为学习关于层输入的残差函数,而不是学习未参考的函数。提供了全面的经验证据说明这些残差网络很容易优化,并可以显著增加深度来提高准确性。在ImageNet 数据集上评估了深度高达 152 层的残差网络——比 VGG深 8 倍但仍具有较低的复杂度。这些残差网络的集合在ImageNet 测试集上取得了 3.57% 的错误率。这个结果在 ILSVRC 2015 分类任务上赢得了第一名,也赢得了 ImageNet 检测任务,ImageNet 定位任务,COCO 检测和 COCO 分割任务的第一名。
摘要中提出更深的神经网络更难训练,而作者提出的深度残差网络可以解决这个问题,从而可以通过显著增加深度来提高准确性。并且,深度残差网络在几次大赛中都获得了第一名的成绩。
但是更深的网络面临着梯度消失/爆炸这个退化问题,并且不是由过拟合引起。

作者提出通过深度残差(恒等映射、快捷连接)来解决这个退化问题,并且既不增加额外的参数也不增加计算复杂度,使得网络易于优化,提高了泛化性能。

其中F(x)+x可以通过带有“跳接”的前向神经网络来实现。跳接简单地执行恒等映射,并将其输出添加到堆叠层的输出,可以从大大增加的深度中轻松获得准确性收益。在CIFAR-10数据集上展示了成功训练的超过 100 层的模型,并探索了超过 1000 层的模型。

在每一个堆叠层都采用了残差学习,残差块用数学公式表示为:

在这里x是当前层的输入相量,y是当前层的输出向量,式子F(x, {Wi})代表要学习的残差映射。输入x→权重层1→ReLU→权重层2。为了简化记号,我们忽略偏置项,操作F+x是通过shortcut连接的方式逐元素相加,然后对求和结果再用一次ReLU非线性激活。式中x和F的维度要相同,如果不是这种情况(当改变输入、输出通道数时),我们通过shortcut连接实施线性投影(Ws)以匹配维度。
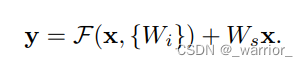
残差F的构造形式有两层和三层的构造方式(更多层也是可以的),但是如果残差F只有一层,就相当于一个线性层,但是这样的构造不会有太大的收益。

上面的式子不仅针对全连接层,还可以应用到卷积层中,函数F(x,{Wi})可以表示多个卷积层,因此逐元素加法的实施是在两个特征图上逐元素、逐通道相加。
网络架构
- 对于相同大小的输出特征图,该层应具有相同数量的卷积核(即每一个block内卷积核数量不变)
- 如果特征图大小减半,卷积核的数量会增加一倍,以保持每层的时间复杂度
基于上述无残差网络,加入了short connection使得网络变为了对应的残差网络。
当输入和输出维度相同时(实线)。
当维度增加时即下采样时(虚线),有两个选择。
A:shortcut路仍执行恒等映射,此时要用padding补零使得维度增加,此方案没有引入额外的参数;
B:用投影shortcut来匹配维度(通过1×1卷积来完成)
对于这两个选项,当shortcut通过两个不同大小的特征图时,shortcut分支第一个卷积层步幅均设为2,即下采样卷积核步幅为2。
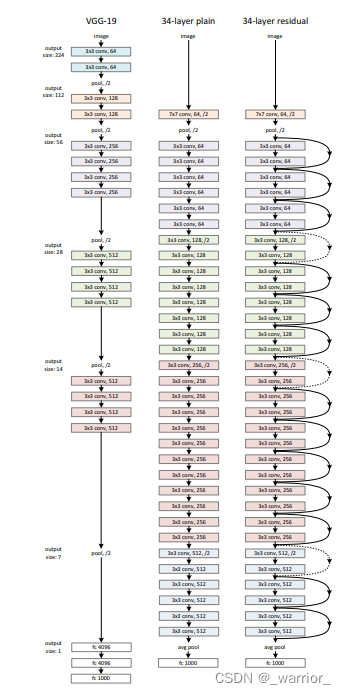
在实验中,作者通过实验ImageNet 分类、CIFAR-10 和分析证实了
- 深度简单网络可能有指数级低收敛特性
- 投影快捷连接对于解决退化问题不是至关重要的
- ResNet 的响应比其对应的简单网络的响应更小,即残差函数通常具有比非残差函数更接近零,同时也探索超过 1000 层的网络,并指出这种极深的模型仍然存在着开放的问题。
总结:
1、退化
定义:随着网络深度的增加,准确率开始达到饱和并且在之后会迅速下降。
判断方法:随着网络的加深,错误率不降反升,收敛速率也呈指数级下降。
原因:网络过于复杂,训练不加约束。
解决方案:使用残差网络结构。
2、在残差网络中得出的结论为:①极深残差网络易于优化收敛;②解决了退化问题;③可以在很深的同时提升准确率。
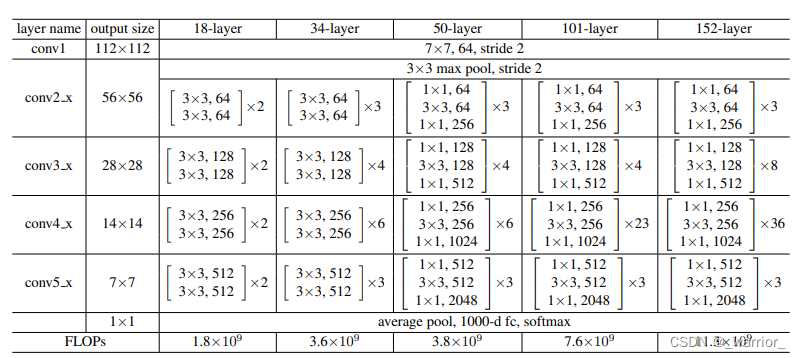
3、网络构造选用步长为2的卷积核进行下采样,最后是一个GAP层和一个1000个神经元的带有softmax的FC层。其余大部分遵照VGGNet的设计原则。
4、本文提出两种残差结构,一种是两层卷积残差块,应用于ResNet-18和ResNet-34;另一种是bottleneck三层卷积残差块(分别为1×1降维、3×3、1×1升维),应用于ResNet-50、ResNet-101和ResNet-152。ResNet-50、ResNet-101、ResNet-152性能都比ResNet-34好。
5、升维(下采样)时有三种方案供选择,但是优先选择B方案(通过1×1卷积匹配维度)
1.2 Pytorch搭建ResNet网络
import torch
import torch.nn as nn
import torch.nn.functional as F
# 用于ResNet-18和ResNet-34的残差块,用的是2个3x3的卷积
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
# 经过处理后的x要与x的维度相同(尺寸和深度)
# 如果不相同,需要添加1×1卷积+BN来变换为同一维度
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes))
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
# 用于ResNet-50,ResNet-101和ResNet-152的残差块,用的是1x1+3x3+1x1的卷积
class Bottleneck(nn.Module):
# 前面1x1和3x3卷积的filter个数相等,最后1x1卷积是其expansion倍
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion * planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion * planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes))
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNet18():
return ResNet(BasicBlock, [2, 2, 2, 2])
def ResNet34():
return ResNet(BasicBlock, [3, 4, 6, 3])
def ResNet50():
return ResNet(Bottleneck, [3, 4, 6, 3])
def ResNet101():
return ResNet(Bottleneck, [3, 4, 23, 3])
def ResNet152():
return ResNet(Bottleneck, [3, 8, 36, 3])
1.3 ResNeXt
作者提出了一种简单、高度模块化的图像分类网络体系结构。通过重复一个构建块来构建的,该构建块聚合了一组具有相同拓扑的变换。简单设计导致了一个同构的、多分支的体系结构,只需要设置几个超参数。这一策略体现了一个新的维度,称之为“Cardinality”(转换集的大小),作为深度和宽度维度之外的一个基本因素。在ImageNet-1K数据集上的实验表明,即使在保持复杂度的限制条件下,增加基数也能够提高分类精度。而且,当我们增加容量时,增加基数比深入或扩大更有效。
split-transform-merge
作者提出了ResNeXt,同时采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想,但是可扩展性比较强。
- Splitting,X分解为多个低维向量Xi
- Transforming,每个Xi对应一个Wi以进行变换
- Aggregating/Merge,每个Xi变换后进行累加

在ResNeXt网络中,变换函数使用ResNet中的Bottleneck形式来替代。
分组卷积
ResNeXt对ResNet进行了改进,采用了多分支的策略,在论文中作者提出了三种等价的模型结构,这三个结构实际上是等价的。

在ResNet-50模型的基础上,提出了ResNeXt-50,ResNeXt-101模型,两者模型的参数、复杂度差不多,但最后在数据集ImageNet1k中得到的准确率ResNeXt更胜一筹。结果显示增加Cardianlity比增加深度和宽度更有效。

另外与Inception网络相比,计算复杂度明显小很多,也对比验证了残差结构的有效性,证明引入残差结构,可以明显提高模型的性能。
总结:
ResNext在ResNet的基础上增加了分组卷积的方式,用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率。
1.4 Pytorch搭建ResNeXt网络
在resnet基础上进行修改
import torch.nn as nn
import torch
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
2 代码练习
2.1 背景
AI研习社 “猫狗大战” 比赛,通过训练模型正确识别猫狗图片,1= dog,0 = cat。
需要先下载数据集进行本地训练,然后以CSV格式提交测试集结果。
2.2 LeNet训练
首先下载数据集,分为训练集和测试集
# 训练集
! wget https://gaopursuit.oss-cn-beijing.aliyuncs.com/2021/files/train.zip
! unzip train.zip
# 测试集
! wget https://gaopursuit.oss-cn-beijing.aliyuncs.com/202007/dogs_cats_test.zip
! unzip dogs_cats_test.zip

参考其他代码设置图片的路径,并将图片进行预处理
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = "cat_dog/" # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
搭建网络
import torch
import torch.nn as nn
import torch.utils.data
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 16, 3, padding=1)
self.conv2 = torch.nn.Conv2d(16, 16, 3, padding=1)
self.fc1 = nn.Linear(50*50*16, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 2)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.softmax(x, dim=1)
训练网络
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(20):
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels.long())
loss.backward()
optimizer.step()
print('Epoch: %d loss: %.6f' %(epoch + 1, loss.item()))
print('Finished Training')
Epoch: 1 loss: 0.695099
Epoch: 2 loss: 0.691022
Epoch: 3 loss: 0.696171
Epoch: 4 loss: 0.696550
Epoch: 5 loss: 0.696903
Epoch: 6 loss: 0.654672
Epoch: 7 loss: 0.671865
Epoch: 8 loss: 0.681123
Epoch: 9 loss: 0.592113
Epoch: 10 loss: 0.553935
Epoch: 11 loss: 0.594890
Epoch: 12 loss: 0.548812
Epoch: 13 loss: 0.497507
Epoch: 14 loss: 0.575524
Epoch: 15 loss: 0.487654
Epoch: 16 loss: 0.580382
Epoch: 17 loss: 0.487696
Epoch: 18 loss: 0.613327
Epoch: 19 loss: 0.574596
Epoch: 20 loss: 0.532503
Finished Training
测试网络
加载测试集图片,一共2000张。将测试结果按照格式1= dog,0 = cat写入csv文件并提交。



从结构来看,训练效果不好。调整网络结构、激活函数等参数没有明显提高。
2.3 ResNet训练
流程和上面基本一样,参考网上博客将网络改为34层的Resnet。
mport torch.nn as nn
import torch
# ResNet18/34的残差结构,用的是2个3x3的卷积
class BasicBlock(nn.Module):
expansion = 1 # 残差结构中,主分支的卷积核个数是否发生变化,不变则为1
def __init__(self, in_channel, out_channel, stride=1, downsample=None): # downsample对应虚线残差结构
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None: # 虚线残差结构,需要下采样
identity = self.downsample(x) # 捷径分支 short cut
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
# ResNet50/101/152的残差结构,用的是1x1+3x3+1x1的卷积
class Bottleneck(nn.Module):
expansion = 4 # 残差结构中第三层卷积核个数是第一/二层卷积核个数的4倍
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(out_channel)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel * self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x) # 捷径分支 short cut
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
# block = BasicBlock or Bottleneck
# block_num为残差结构中conv2_x~conv5_x中残差块个数,是一个列表
def __init__(self, block, blocks_num, num_classes=1000, include_top=True):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0]) # conv2_x
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2) # conv3_x
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2) # conv4_x
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2) # conv5_x
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
# channel为残差结构中第一层卷积核个数
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
# ResNet50/101/152的残差结构,block.expansion=4
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
测试结果

可以看出resnet的残差网络结构可以很好的提升网络性能,提升网络的深度并提高准确率。
2.4 问题总结
- 在AI研习社里提供的数据集中一共有24000的图片,在colab中训练会中断,参考网上其他的方案,选用2000张进行训练,可能结果会受影响。
- 在图片预处理时,可以做一些更复杂的处理变换
- 在LeNet网络模型中,最后的输出层增加softmax函数进行处理。
- 在结果写入csv文件时,序号和类别的应该和要求一样。之前因为格式错误没有评审得分。
3 思考题
3.1 Residual learning
ResNet引入残差网络结构,即在输入与输出之间引入一个前向反馈的shortcut connection,这有点类似与电路中的“短路”。原来的网络是学习输入到输出的映射H(x),而残差网络学习的是F(x)=H(x)−x。

深层网络的训练误差一般比浅层网络更高,但是对一个浅层网络,添加多层恒等映射(y=x)变成一个深层网络,这样的深层网络却可以得到与浅层网络相等的训练误差。

利用链式规则,可以求得反向过程的梯度,残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差不会导致梯度消失。所以残差学习会更容易。
3.2Batch Normailization 的原理
在实际训练过程中,经常出现隐含层因数据分布不均,导致梯度消失或不起作用的情况。BN是对隐藏层的标准化处理,可使各隐藏层输入的均值和方差为任意值。

3.3为什么分组卷积可以提升准确率?即然分组卷积可以提升准确率,同时还能降低计算量,分数数量尽量多不行吗?
分组卷积将卷积的输入 feature map 进行分组,每个卷积核也相应地分成组,在对应的组内分别做卷积。用少量的参数量和运算量就能生成大量的 feature map,大量的 feature map 意味着能够编码更多的信息,提高准确率。
分组卷积由于引入稀疏连接,减弱了卷积的表达能力,导致性能的降低,特别对于难样本。如果分组过多,会破坏局部信息之间的关联性,使网络的性能降低。















 931
931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









