







Abstract
只在输入空间中引入少量(小于1%的模型参数)可训练参数,同时保持模型主干不变。
在许多情况下,VPT甚至超越了模型容量和训练数据规模的全面微调,同时降低了每个任务的存储成本。
Introduction
常用技术:full fine-tuning,这种策略要求为每一个任务存储和部署一个独立的骨干参数副本。这是一个昂贵且通常不可行的命题,特别是对于现代的基于Transformer的体系结构
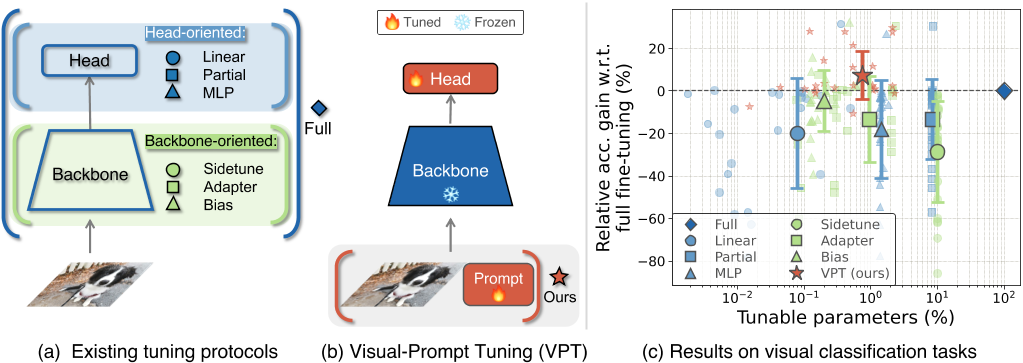
(a) 三种传统微调方法:Full fine-tuning, Head-oriented, and Backbone-oriented approaches
(b) VPT: 我们不是修改或微调预先训练的Transformer本身,而是修改对Transformer的输入
我们的方法只在输入空间中引入少量任务特定的可学习参数,而在下游训练时冻结整个预训练的Transformer骨干。在实践中,这些额外的参数只是预先添加到每个Transformer层的输入序列中,并在微调期间与线性头一起学习。
Related work
Adapters [64] and BitFit [5].
适配器[34]在每个Transformer层中插入额外的轻量级模块。一个适配器模块通常由一个线性向下投影、一个非线性激活函数和一个线性向上投影以及一个剩余连接组成[63,64]。[8]没有插入新的模块,而是在对ConvNets进行微调时,提出更新偏置项并冻结其余的骨干参数。BitFit[3]将该技术应用于变压器,并验证了其在LM调谐上的有效性。我们的研究表明,相对于前面提到的NLP中的两种完善的方法,VPT在适应Transformer模型的视觉任务方面提供了更好的性能。
prompt
treat the prompts as task-specific continuous vectors and directly optimize them via gradients during fine-tuning(最近的研究提出将提示符作为任务特定的连续向量,并在微调过程中通过梯度直接对其进行优化,即Prompt Tuning)
与完全微调相比,它获得了类似的性能,但使用了1000×less参数存储。
方法
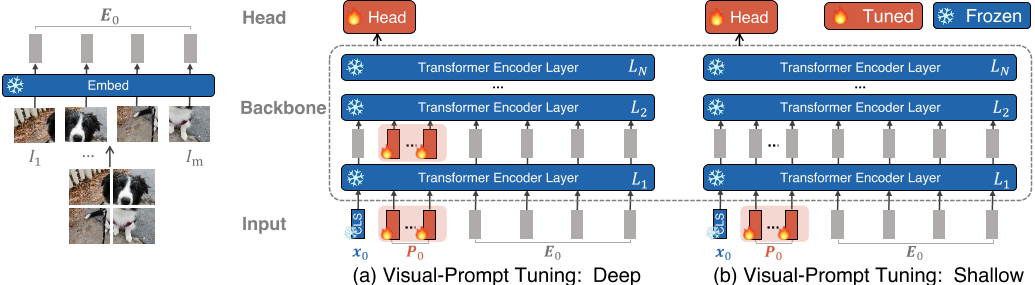
VPT-Deep变体为Transformer编码器每层的输入预先设置一组可学习的参数;
VPT-Shallow变体则仅将提示参数插入第一层的输入。
两者在下游任务的训练过程中,只有特定于任务的提示和线性头的参数会更新,而整个Transformer编码器被冻结。
方法:在原有VIT的基础上增加可学习的token参数 P 0 P_0 P0,这部分的参数需要梯度,其余部分全部冻结
给定一个预训练的Transformer模型,我们在Embed层之后的输入空间中引入一组p个维数为d的连续嵌入,即提示符。在微调期间,只有特定于任务的提示被更新,而Transformer主干被冻结。
结论
作者提出了一种新的参数有效的方法,将大规模视觉Transformer模型广泛应用到下游任务,即VPT。它超越了其他的微调方法。














 1516
1516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









