






Introduction
对于大多数识别任务来说,大多数的精确结果是来自基础模型在全新数据上训练的结果,但将大型模型应用在下游任务本身就是一个需要解决的问题。
现有的策略是用full fine-tuning预训练,这种方式需要为每个任务存储部署大量骨干参数,非常耗费资源。而Transformer恰好参数远大于卷积神经网络,更浪费。
作者的方法只在输入空间中引入少量特定于任务的可学习参数,同时在下游训练期间冻结整个预训练的Transformer骨干,结果对24种下游识别任务都有不错的表现。
Related Work
Transformer
Transformer相比于卷积会有更优越的性能以及各大的规模,那么如何将Transformer应用在不同视觉任务上就成为了难题。
Transformer learning
迁移学习一般针对卷积神经网络,很少有人关注到Vision Transformer的应用以及之前迁移学习的方法表现情况
Approach
1.输入图片被分为m个相同大小的hw的patches(VIT中224224的图片被分为1616大小的patches,共196个)
2.每个patch经过embed变为包含位置信息的d维向量(d=16163=768),总体为196768

3.将patch加上d维的CLS,总体为197*768

4.VPT-Shallow
 5.
5.
5.VPT-Deep

Experiments


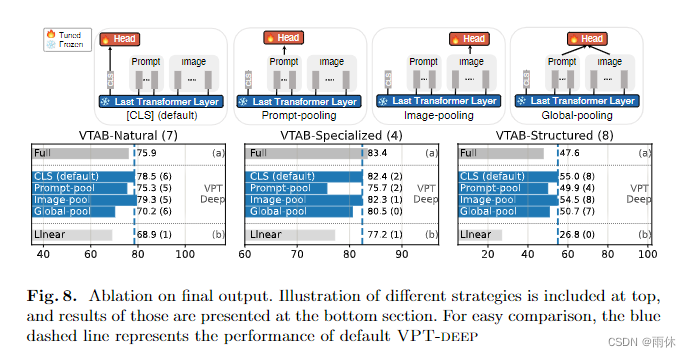
消融实验
















 1563
1563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









