






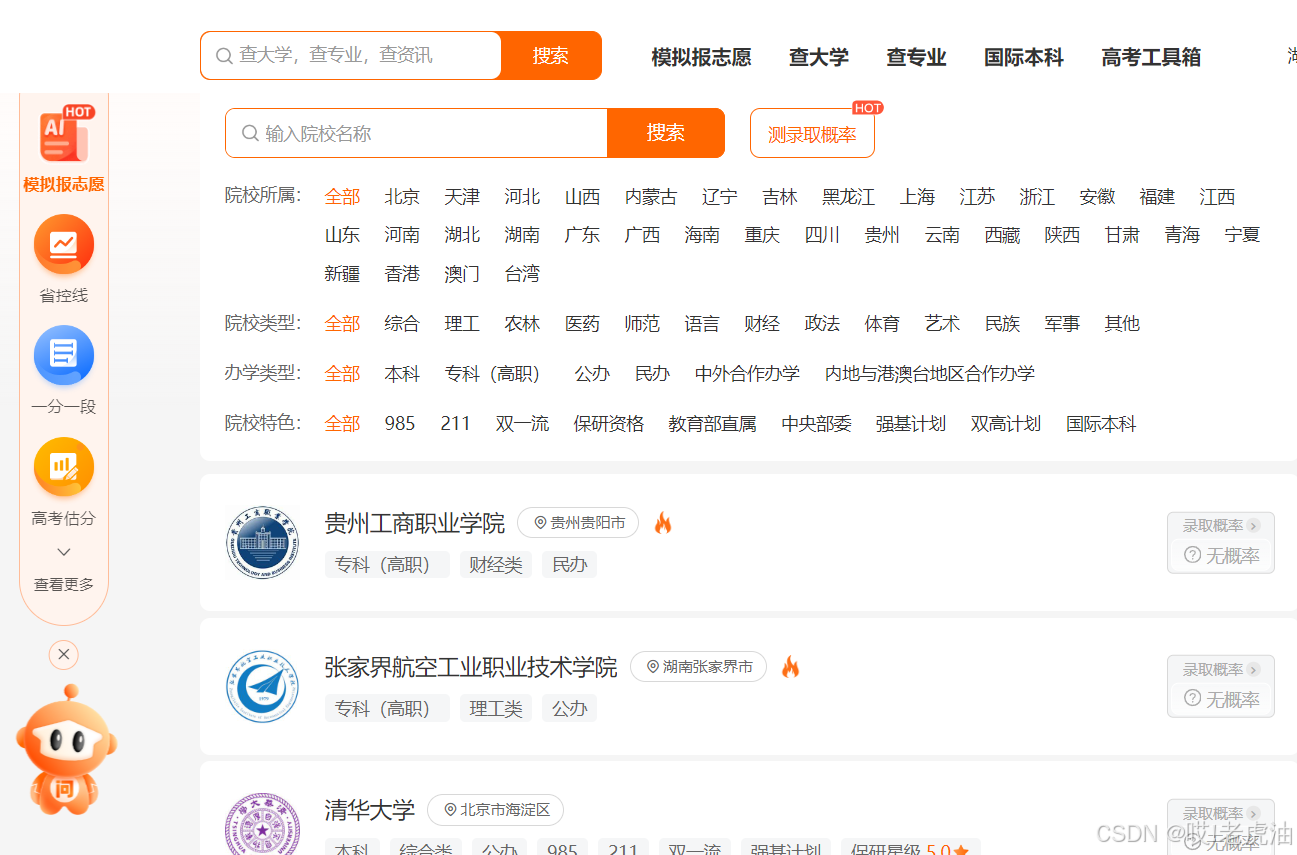
https://www.gaokao.cn/school/search
右击'检查'或者F12,我们先清空响应数据,然后ctrl+R或者刷新页面,然后搜索关键词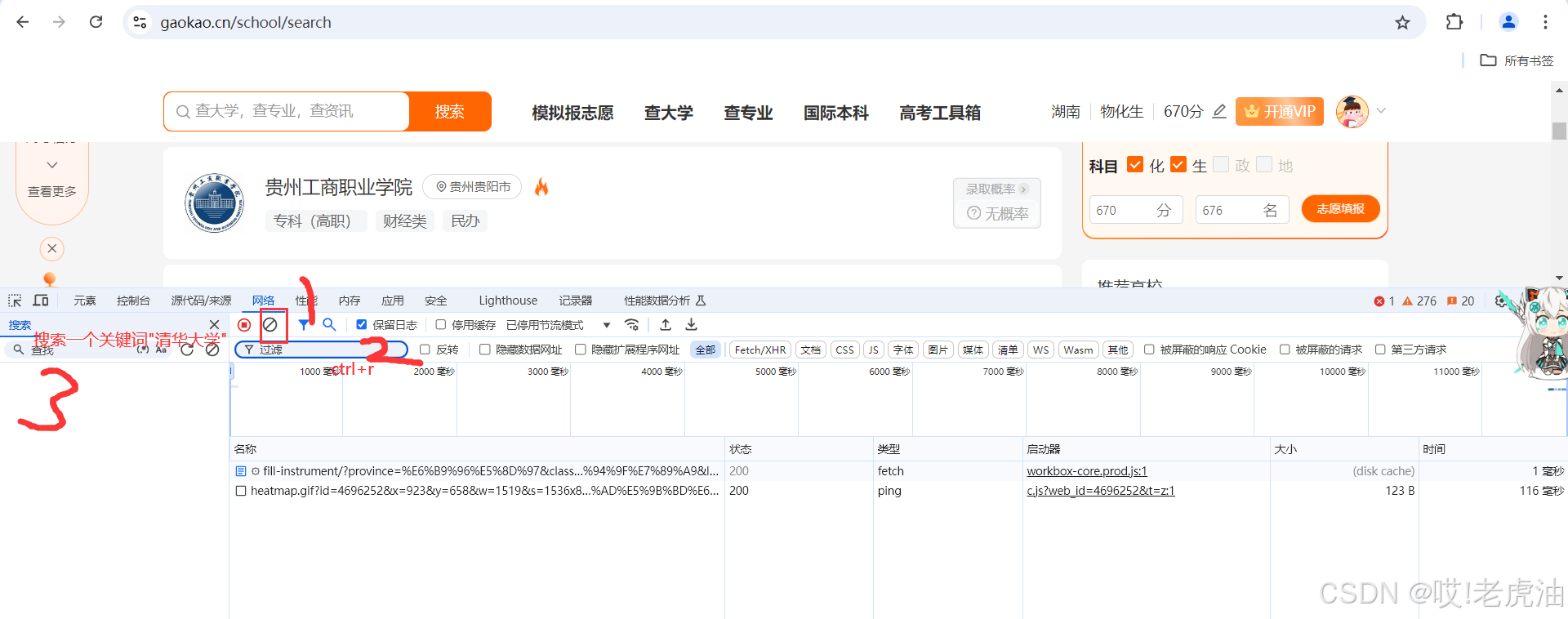
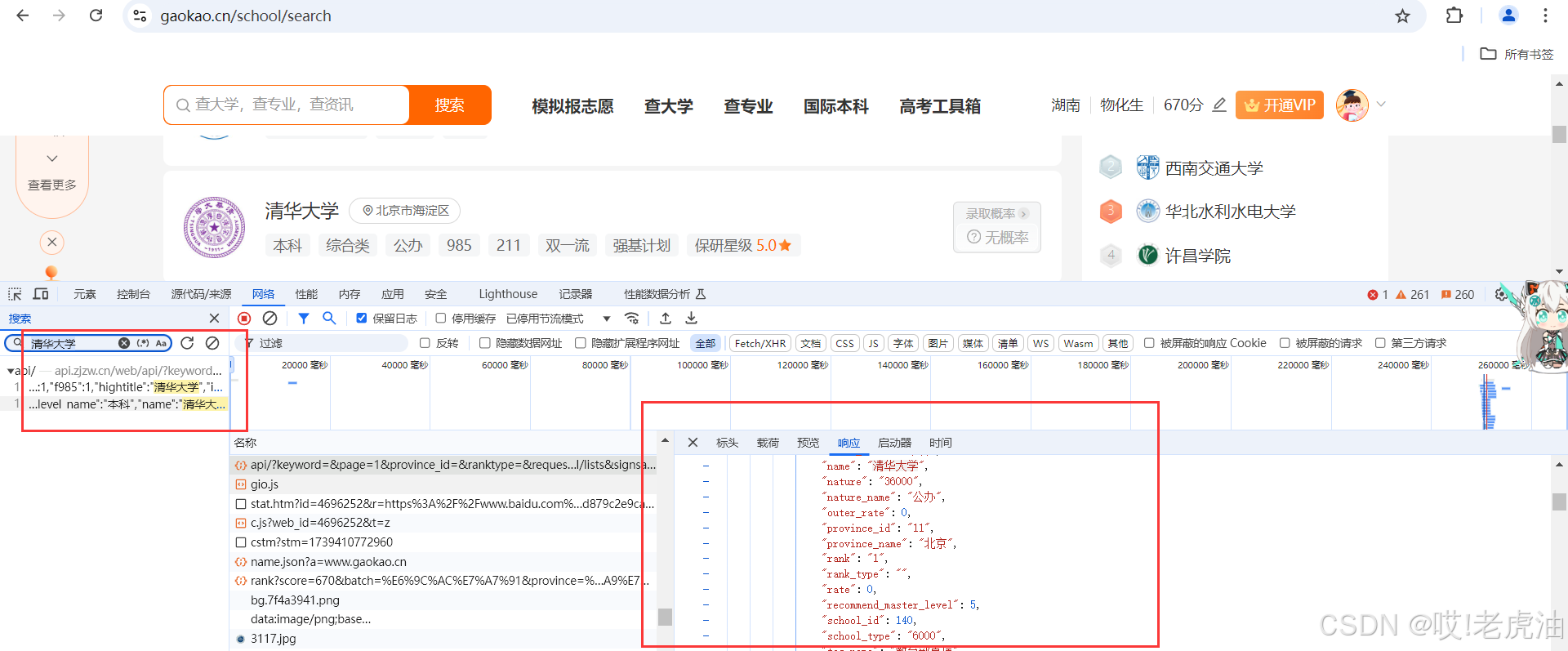
在这个接口json数据集中,数据其实并不全,我们需要点击每一所大学才有对应的齐全数据
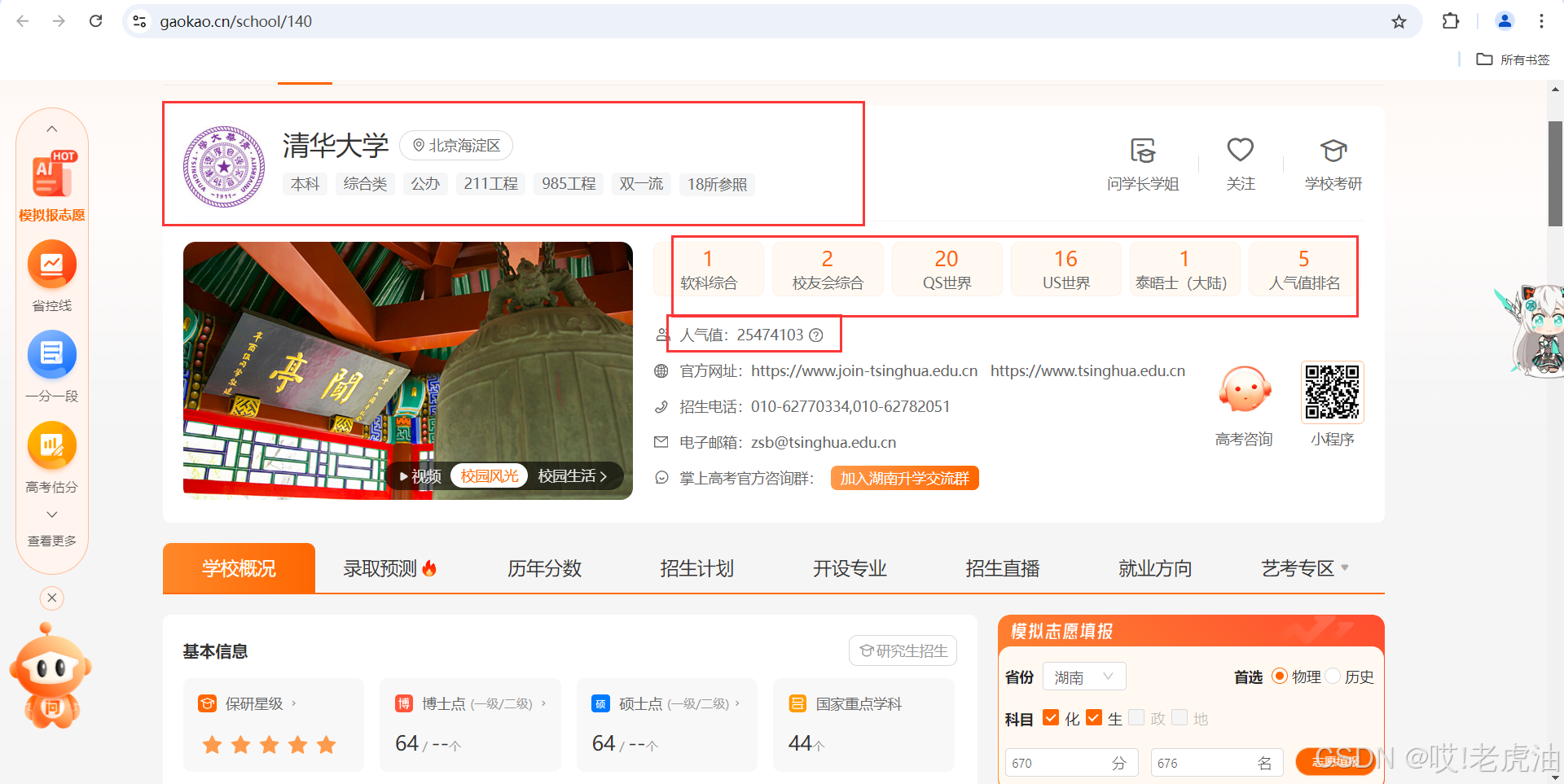
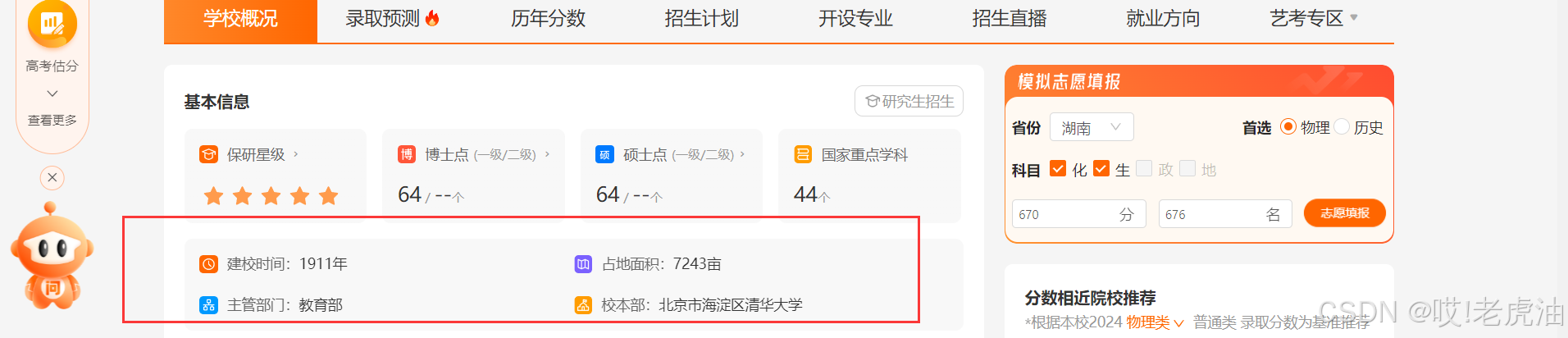
我们重新执行F12哪些操作
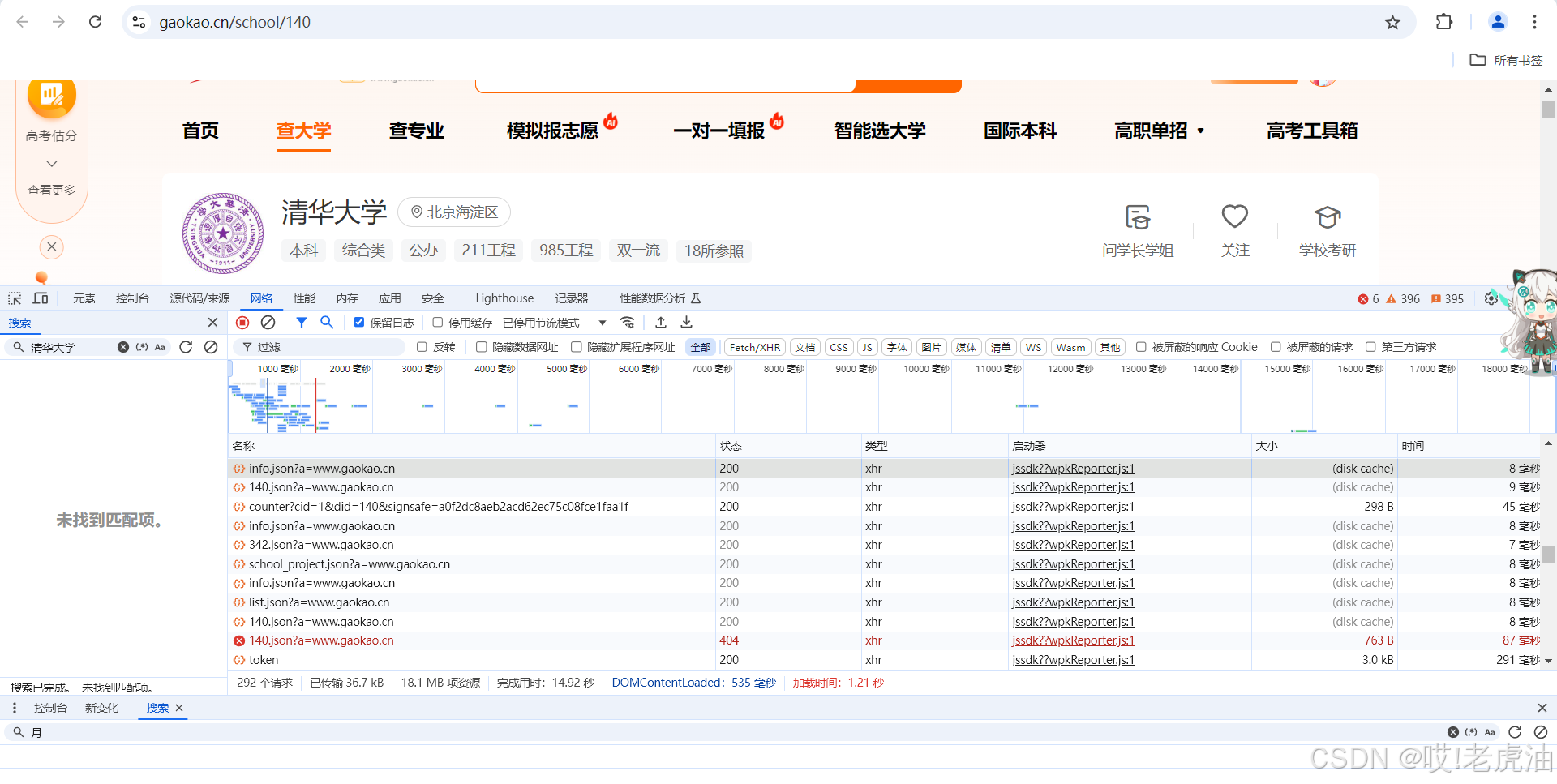
当你发现你搜索关键词'清华大学'的时候并没有匹配接口,不是没有,而是Unicode编码,不是明文,我们可以收索数字类型的关键字,这边建议收索'占地面积'的数字,为什么不是'人气值'和软科排行等数字呢,第一,人气值的数据是另外一个接口,那个接口只有人气值数据,而收索软科排行数字不好找接口,所以建议收索'占地面积'.
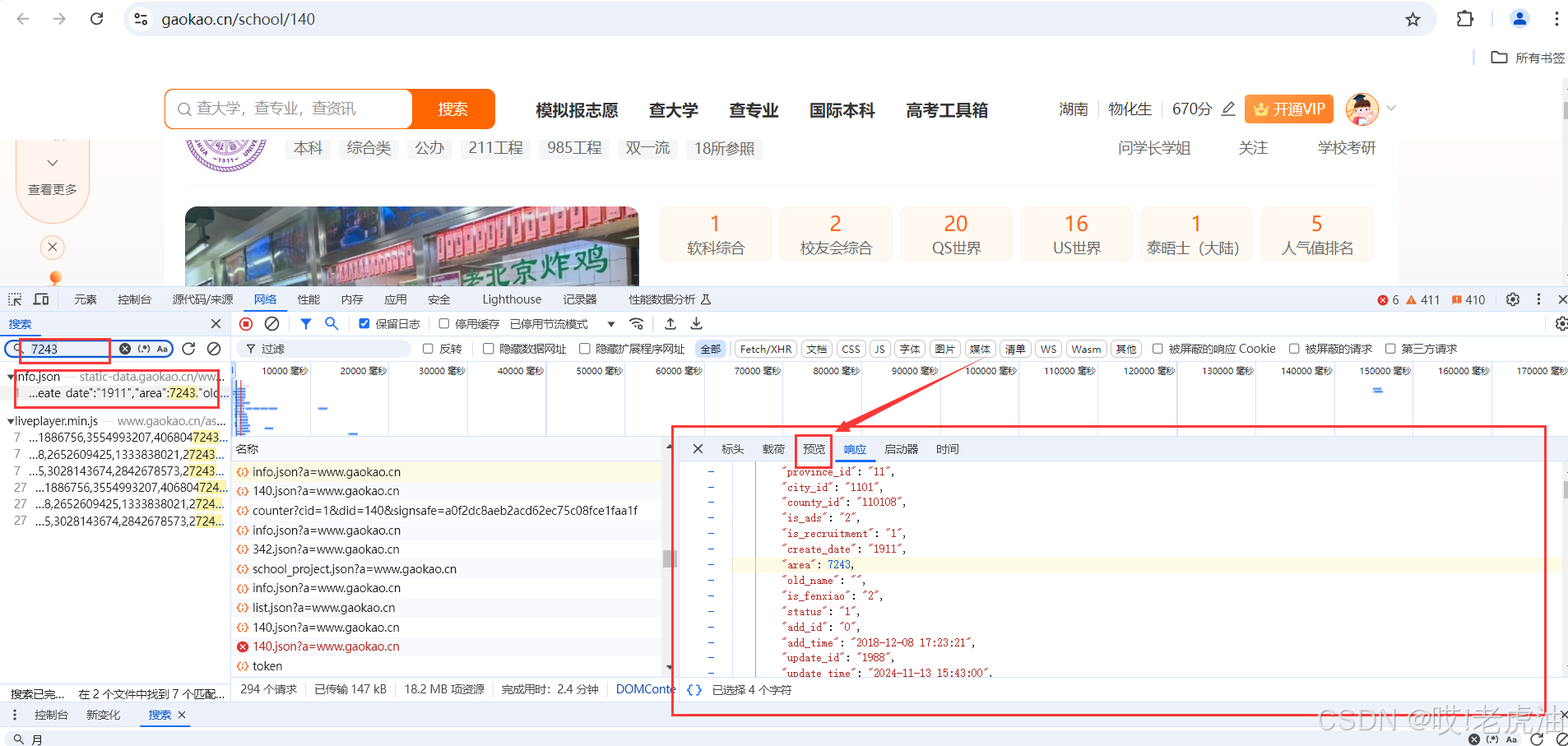
我们可以看预览数据发现是我们所要数据
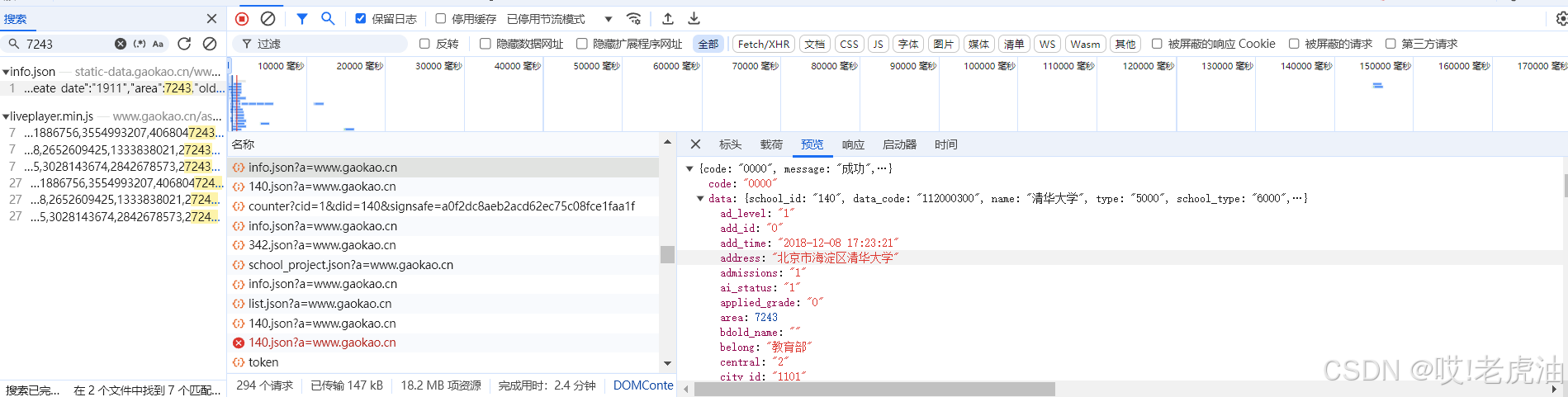
这就是他的接口
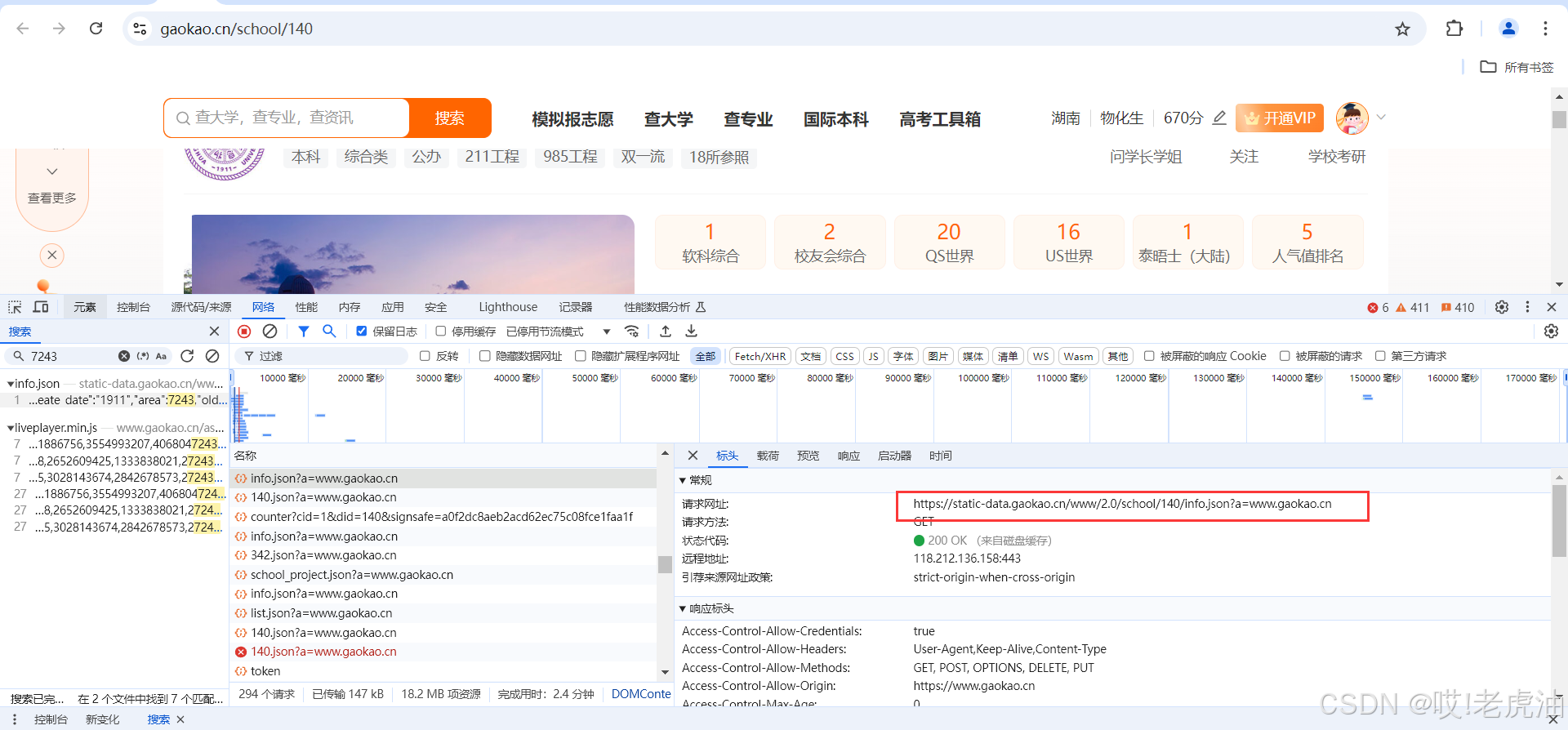
聪明的同学就知道到了,这个'140'是清华学校的id了,哪id从哪获取?
没错!是在我们第一次寻找到的接口!
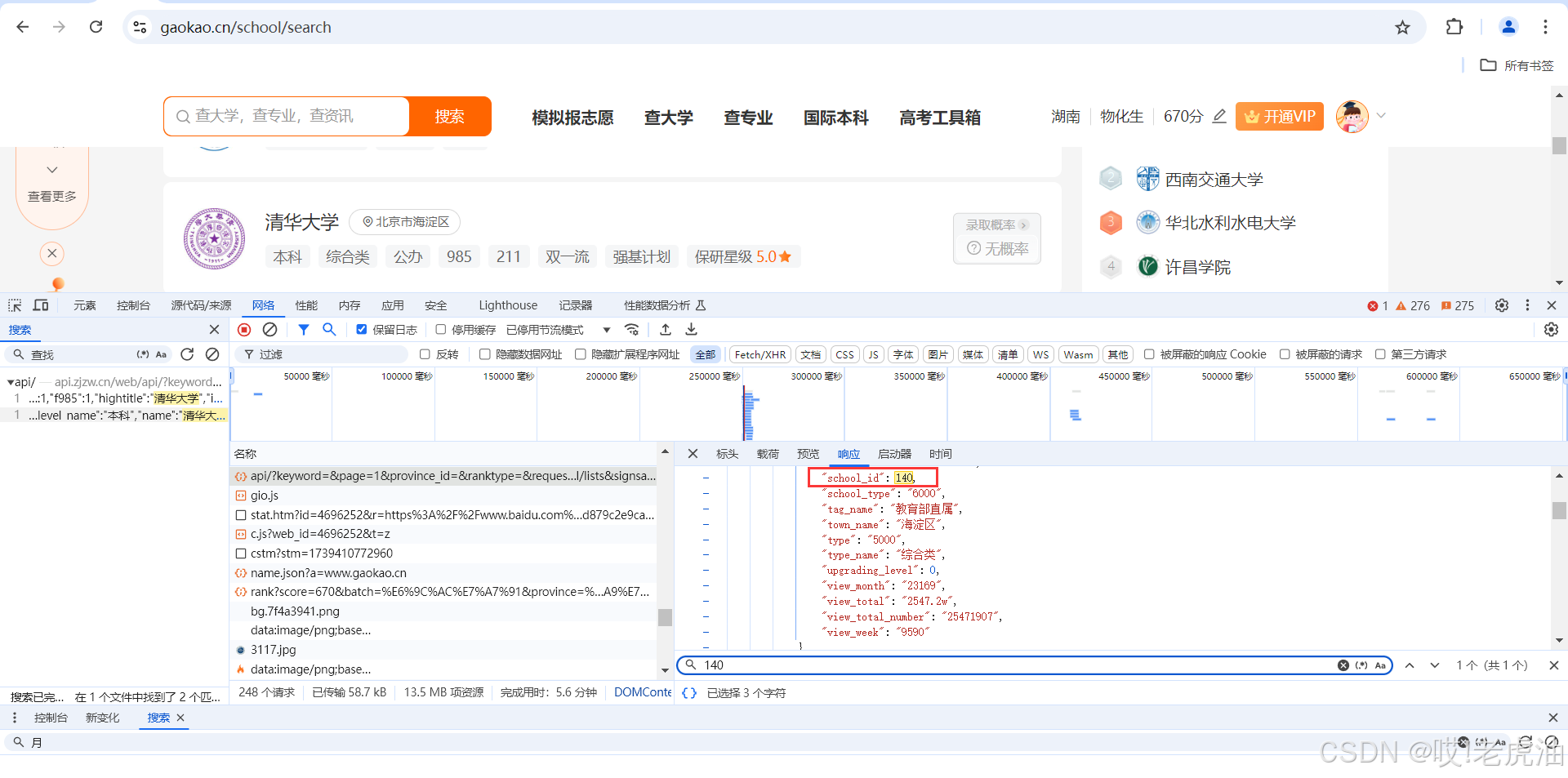
获取接口开始代码操作了
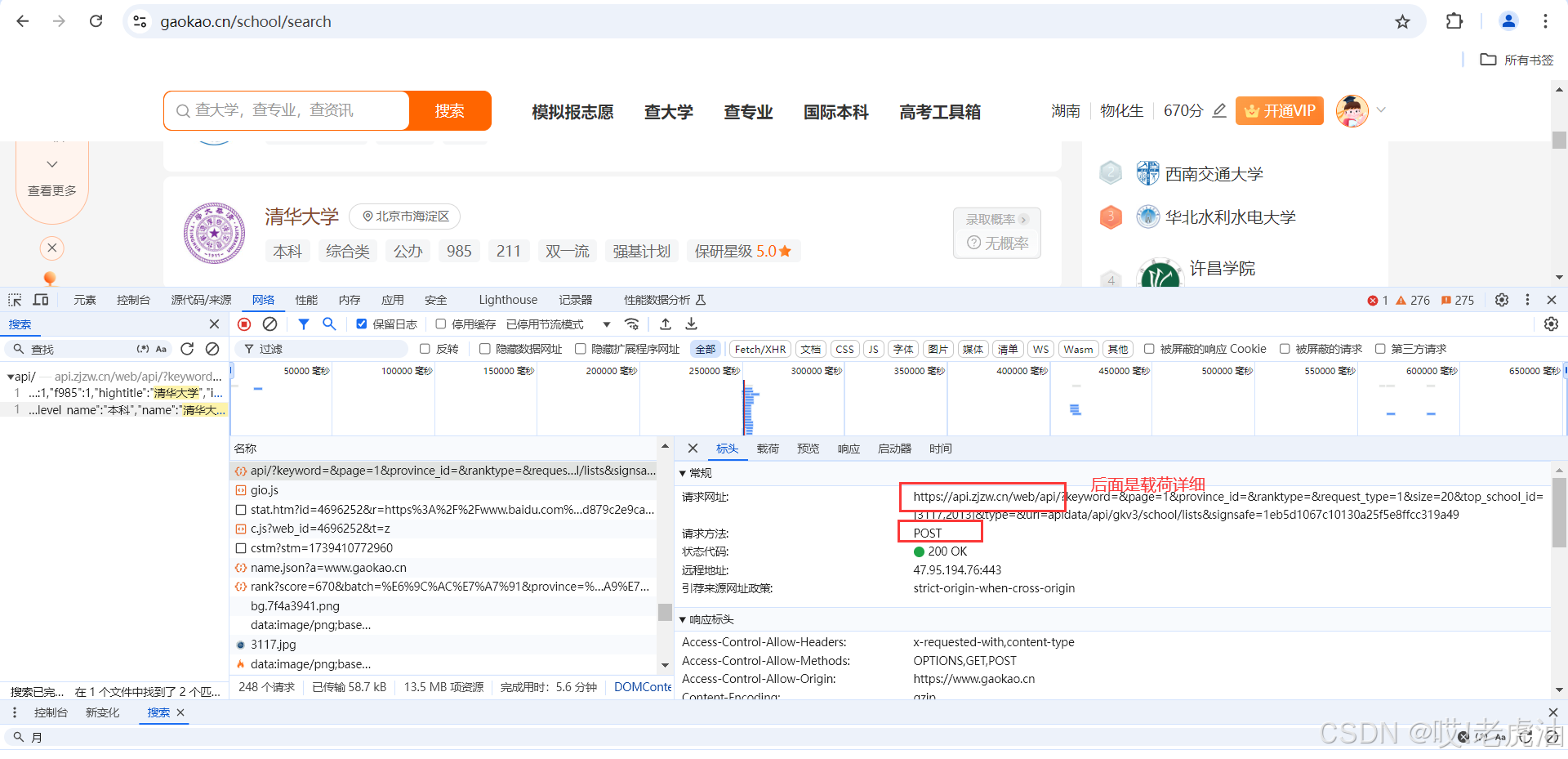
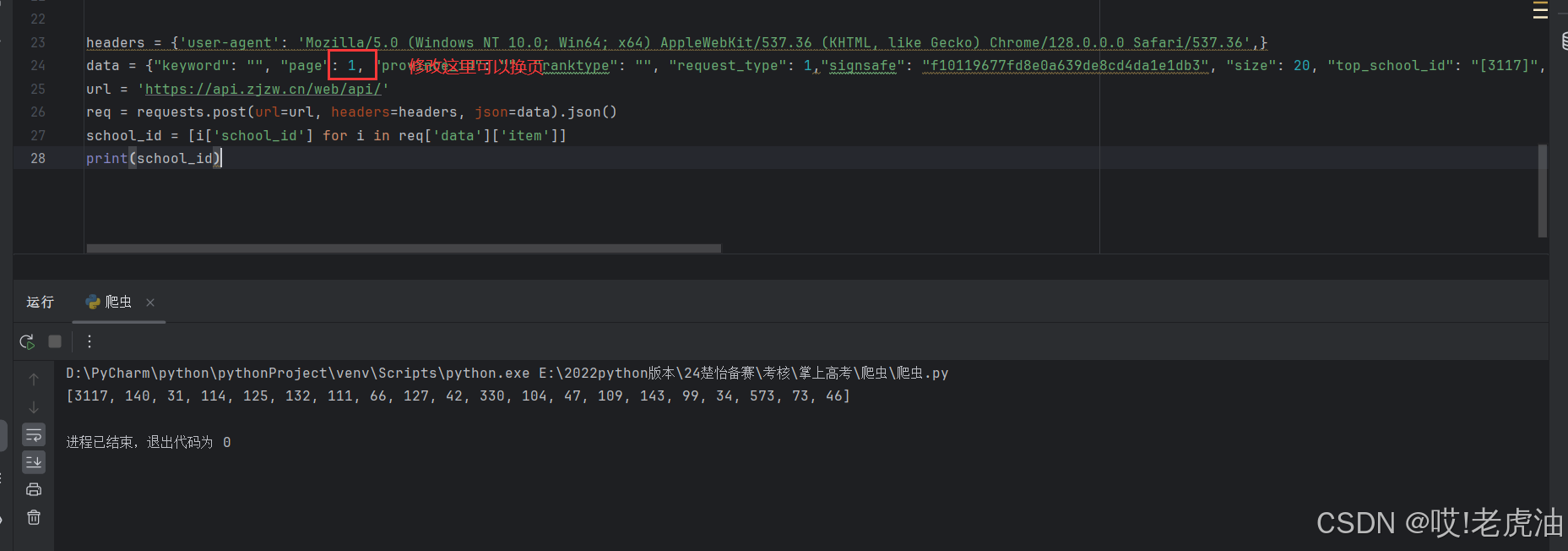
打印结果就是第一页学校的id,然后再使用第二个接口就可以了
这边建议每获取一个学校数据就睡眠1秒,要不然访问次数频繁封你.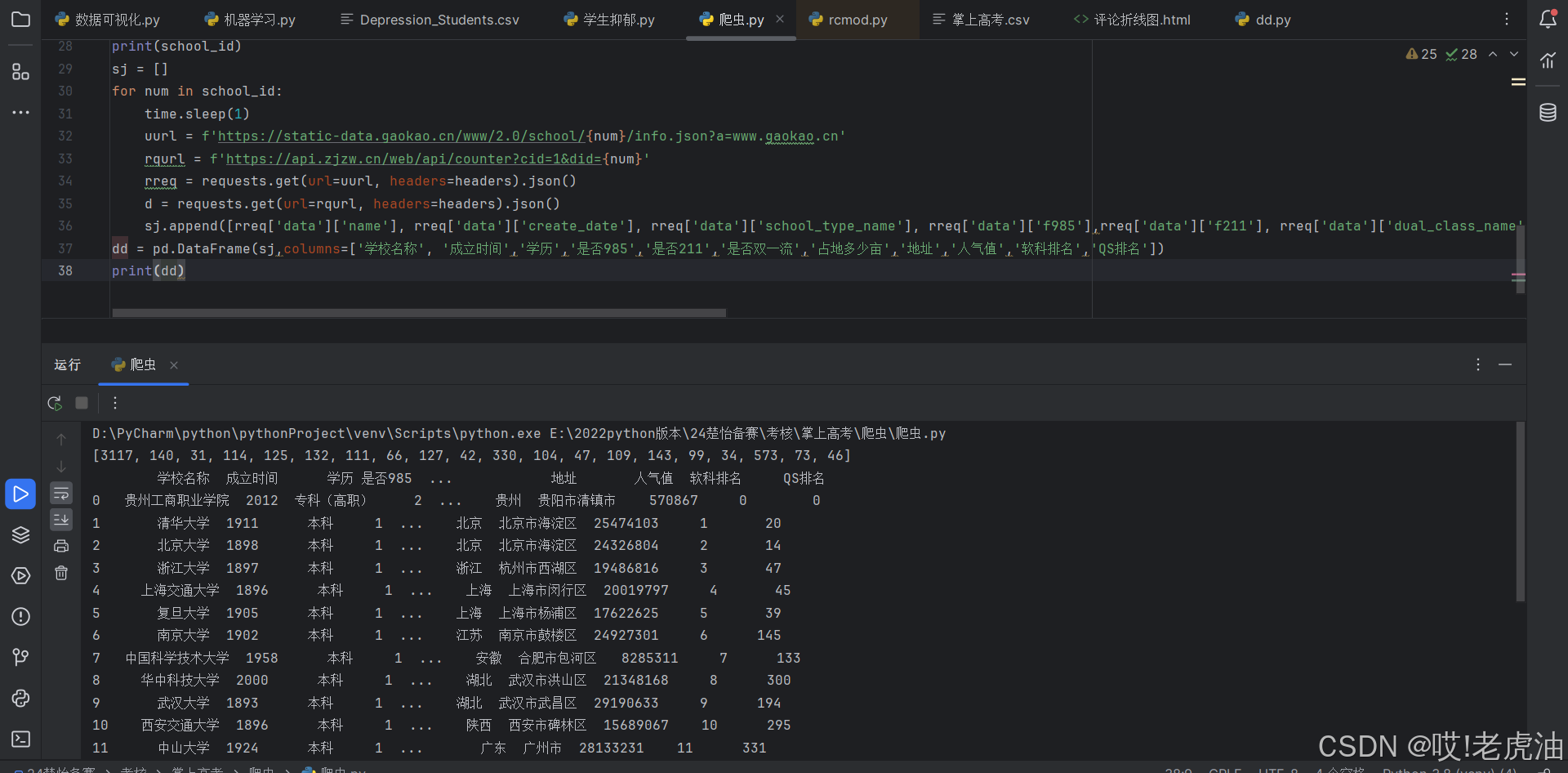
下面就是博主完整代码了,爬完可能需要70分钟,看到这点个三连不过分吧
import requests
import time
import pandas as pd
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36',}
url = 'https://api.zjzw.cn/web/api/'
sj = []
for page in range(1,149):
data = {"keyword": "", "page": page, "province_id": "", "ranktype": "", "request_type": 1,"signsafe": "f10119677fd8e0a639de8cd4da1e1db3", "size": 20, "top_school_id": "[3117]", "type": "","uri": "apidata/api/gkv3/school/lists"}
req = requests.post(url=url, headers=headers, json=data).json()
school_id = [i['school_id'] for i in req['data']['item']]
for num in school_id:
time.sleep(1)
uurl = f'https://static-data.gaokao.cn/www/2.0/school/{num}/info.json?a=www.gaokao.cn'
rqurl = f'https://api.zjzw.cn/web/api/counter?cid=1&did={num}'
rreq = requests.get(url=uurl, headers=headers).json()
d = requests.get(url=rqurl, headers=headers).json()
sj.append([rreq['data']['name'], rreq['data']['create_date'], rreq['data']['school_type_name'], rreq['data']['f985'],rreq['data']['f211'], rreq['data']['dual_class_name'], rreq['data']['area'],rreq['data']['province_name'] + " " + rreq['data']['city_name'] + rreq['data']['town_name'],d['data'][f'{num}'], rreq['data']['rank']['ruanke_rank'],rreq['data']['rank']['qs_world']])
dd = pd.DataFrame(sj,columns=['学校名称', '成立时间','学历','是否985','是否211','是否双一流','占地多少亩','地址','人气值','软科排名','QS排名'])
dd.to_csv('掌上高考2.csv',index=False)
















 4631
4631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









