







摘要
编解码器框架在离线语义图像分割领域处于最先进的水平。随着自主系统的兴起,实时计算变得愈发受到青睐。在本文中,我们引入了快速分割卷积神经网络(Fast-SCNN),这是一种针对高分辨率图像数据(1024×2048像素)的实时语义分割模型,适用于在内存较低的嵌入式设备上进行高效计算。在现有的快速分割双分支方法基础上,我们引入了“学习下采样”模块,该模块可同时为多个分辨率分支计算低级特征。我们的网络将高分辨率下的空间细节与低分辨率下提取的深度特征相结合,在Cityscapes数据集上实现了每秒123.5帧的处理速度,平均交并比准确率达到68.0%。我们还表明,大规模的预训练并非必要。我们通过在ImageNet预训练以及Cityscapes的粗标注数据上进行实验,对我们的指标进行了全面验证。最后,我们展示了在对输入进行子采样的情况下,无需对网络做任何修改就能实现更快的计算速度且能得到颇具竞争力的结果。
1. 引言
快速语义分割在实时应用中尤为重要,在这些应用中,需要快速解析输入内容,以便与环境进行灵敏的交互。由于人们对自主系统和机器人技术的兴趣日益浓厚,因此很明显,近期实时语义分割的研究受到了极大的关注[21, 34, 17, 25, 36, 20]。我们要强调的是,实际上往往需要比实时性能更快的速度,因为语义标注通常仅作为其他对时间要求苛刻任务的预处理步骤。此外,在嵌入式设备(无法使用强大的GPU)上进行实时语义分割可能会催生许多其他应用,比如可穿戴设备的增强现实应用。
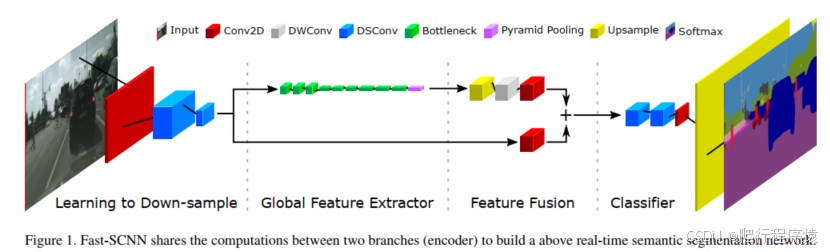
我们注意到,在文献中,语义分割通常由带有编解码器框架的深度卷积神经网络(DCNN)来处理[29, 2],而许多运行时高效的实现采用双分支或多分支架构[21, 34, 17]。通常情况如下:
• 更大的感受野对于学习对象类别之间的复杂关联(即全局上下文)非常重要;
• 图像中的空间细节对于保留对象边界是必要的;
• 需要特定的设计来平衡速度和准确性(而不是对分类用的DCNN进行重新定向)。
具体在双分支网络中,在低分辨率下采用更深的分支来捕捉全局上下文,而设置较浅的分支在全输入分辨率下学习空间细节。然后通过合并这两个分支来提供最终的语义分割结果。重要的是,由于更深网络的计算成本通过较小的输入尺寸得以克服,且仅在少数几层上采用全分辨率执行,所以在现代GPU上实现实时性能是可能的。与编解码器框架不同的是,双分支方法中不同分辨率下的初始卷积是不共享的。在此值得注意的是,引导上采样网络(GUN)[17]和图像级联网络(ICNet)[36]仅在前几层共享权重,但不共享计算。
在这项工作中,我们提出了快速分割卷积神经网络Fast-SCNN,这是一种实时语义分割算法,它将先前技术[21, 34, 17, 36]中的双分支设置与经典的编解码器框架[29, 2]相结合(图1)。基于初始DCNN层提取低级特征[35, 19]这一观察结果,我们在双分支方法中共享了初始层的计算。我们将这种技术称为学习下采样。其效果与编解码器模型中的跳跃连接相似,但为了保持运行时效率,这种跳跃连接仅使用一次,并且该模块设计得较浅以确保特征共享的有效性。最后,我们的Fast-SCNN采用了高效的深度可分离卷积[30, 10]和逆残差块[28]。
将Fast-SCNN应用于Cityscapes数据集[6]时,在现代GPU(英伟达Titan Xp(帕斯卡架构))上以全分辨率(1024×2048像素)运行,可实现每秒123.5帧(fps)的处理速度,平均交并比(mIoU)达到68.0%,这比之前的技术(如BiSeNet,其mIoU为71.4%)快一倍[34]。
我们使用了111万个参数,而大多数离线分割方法(如DeepLab[4]和PSPNet[37])以及一些实时算法(如GUN[17]和ICNet[36])所需的参数数量远多于此。Fast-SCNN的模型容量特意保持在较低水平。原因有两点:(i)较低的内存需求使其能够在嵌入式设备上运行;(ii)期望能有更好的泛化能力。特别是,通常建议在ImageNet[27]上进行预训练以提高准确性和泛化能力[37]。在我们的工作中,我们研究了预训练对低容量Fast-SCNN的影响。与高容量网络的趋势相反,我们发现通过预训练或添加额外的粗标注训练数据,结果仅有微不足道的提升(在Cityscapes数据集[6]上mIoU仅提高了0.5%)。
综上所述,我们的贡献如下:
- 我们提出了Fast-SCNN,这是一种针对高分辨率图像(1024×2048像素)具有竞争力(mI
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2335
2335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









