







搜索文本
关键词上下文——concordance
使用函数concordance可以查找关键词每次的出现,以及连同关键词出现的上下文一起显示。(查看关键词出现的上下文)
from nltk.book import *
text1.concordance("monstrous")
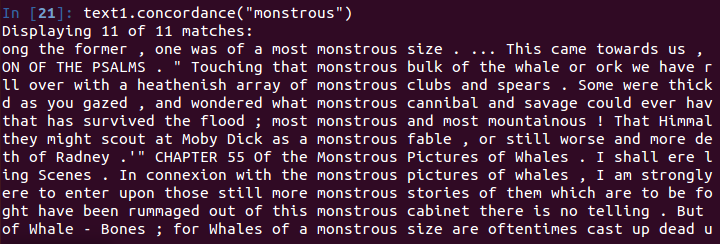
相似上下文查找——similar
使用similar函数可以看到同关键词出现在相似的上下文中的词,即查找近义词
text1.similar("monstrous") #查找monstrous的近义词,出现在相似的上下文中的词

共同上下文——common_contexts
函数common_contexts允许研究两个或两个以上的词共同的上下文。
text2.common_contexts(["monstrous","very"])

注意此处的多个单词须要使用[]括起来
生成随意文本——generate
`text3.generate()` #基于文章生成新的随机文本
计数词汇
函数len
`len(text1)` #文本中出现的词和标点符号,从文本头到尾的长度
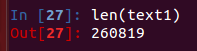
使用len()函数获取的是文本所有的标识符,其中有大量的重复成分,如何获取文本中的词汇数?
函数set
sorted(set(text1)) #获取文本text1的词汇表,并按照英文字母排序
len(set(text1)) #获取文本text1词汇表的数量(词类型)
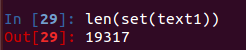
注意set方法不能将文本中的标点符号过滤掉,其中包含了标点符号
标识符的平均使用次数
len(text1)/len(set(text1)) #词汇总数量/词汇表数量

特定词的出现次数及占比
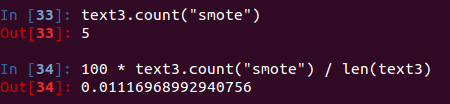
text3.count("smote") #单词smote在文本中出现次数
100 * text3.count("smote") / len(text3) #获取单词的占比















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









