









背景:突然脑残,搞不明白单例在多进程中的使用,所以想看下单例在多进程中到底是不是同一份,所以下了以下测试程序
#include <unistd.h>
#include <errno.h>
#include <stdio.h>
template <typename T>
class CSingleton
{
public:
static T *getInstance()
{
static T t;
return &t;
/*
static T * t = NULL;
if(t == NULL)
{
printf("init t\n");
t = new T();
}
return t;
*/
}
};
class CData
{
public:
CData()
{
printf("pid:%d, init cdata, a:%d\n", getpid(), a);
}
~CData()
{
}
public:
static int a;
};
int CData::a = 1;
int main()
{
int iCount = 0;
int iRet = fork();
if(iRet < 0)
{
printf("fork error:%d\n", errno);
}
else if(iRet == 0) //子进程
{
printf("pid:%d, before write, child address is %p, a:%d, a's address:%p\n", getpid(), CSingleton<CData>::getInstance(),
CSingleton<CData>::getInstance()->a, &(CSingleton<CData>::getInstance()->a));
sleep(3);
CSingleton<CData>::getInstance()->a++;
printf("pid:%d, after write, child address is %p, a:%d, a's address:%p\n", getpid(), CSingleton<CData>::getInstance(),
CSingleton<CData>::getInstance()->a, &(CSingleton<CData>::getInstance()->a));
iCount++;
}
else
{
sleep(1);
printf("pid:%d, before write, father address is %p, a:%d, a's address:%p\n", getpid(), CSingleton<CData>::getInstance(),
CSingleton<CData>::getInstance()->a, &(CSingleton<CData>::getInstance()->a));
CSingleton<CData>::getInstance()->a++;
printf("pid:%d, after write, father address is %p, a:%d, a's address:%p\n", getpid(), CSingleton<CData>::getInstance(),
CSingleton<CData>::getInstance()->a, &(CSingleton<CData>::getInstance()->a));
iCount++;
sleep(5);
}
printf("iCount is %d\n", iCount);
return 0;
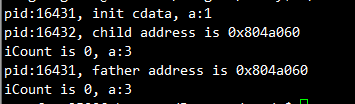
}执行结果是这样的:

可以看到,两个进程中实例的虚拟地址都是一样的,但是实际上指向的是两个不同的变量(物理地址不同),这点可以从a的值上看出。
但是我没明白的是,我多次运行并且更换系统,父子进程中这个虚拟地址都是一模一样的,但是实例是在fork之后才建立的,所以子进程拷贝父进程的数据跟这个貌似无关啊,可是为什么虚拟地址一直是一样的呢?
附:在fork前建立实例
int main()
{
int iCount = 0;
CData *pCData = CSingleton<CData>::getInstance();
pCData->a++;
int iRet = fork();
if(iRet < 0)
{
printf("fork error:%d\n", errno);
}
else if(iRet == 0) //子进程
{
printf("pid:%d, child address is %p\n", getpid(), pCData);
pCData->a++;
}
else
{
sleep(2);
printf("pid:%d, father address is %p\n", getpid(),pCData);
pCData->a++;
}
printf("iCount is %d, a:%d\n", iCount, pCData->a);
return 0;
}运行结果:
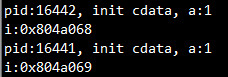
这个还是比较好理解的,在fork后,子进程“继承”父进程的变量,其地址总是一样的,因为在fork时整个虚拟地址空间被复制,但是虚拟地址空间所对应的物理内存却没有复制(这个时候父子进程中变量 x对应的虚拟地址和物理地址都相同)。等到虚拟地址空间被写时,对应的物理内存空间被复制(这个时候父子进程中变量 i 对应的虚拟地址还是相同的,但是物理地址不同),这就是"写时复制"。这个一样的地址是线性地址,每个进程的相同的线性地址都可以映射到不同的物理地址上。在fork的时候,子进程从父进程了copy了task_struct结构,其中task_struct里的mm就是线性地址的使用情况,mm也会被copy给子进程,所以在fork之前声明的变量,在fork后在父进程和子进程里的线性地址是一样的。
再附:这种情况下,虚拟地址是不一样的:
int main()
{
int iRet = fork();
if(iRet < 0)
{
printf("fork error:%d\n", errno);
}
else if(iRet == 0) //子进程
{
static CData a;
printf("i:%p\n", &a);
}
else
{
sleep(1);
static CData a;
printf("i:%p\n", &a);
sleep(5);
}
return 0;
}运行结果:
附一张图:(http://blog.chinaunix.net/uid-24774106-id-3361500.html)
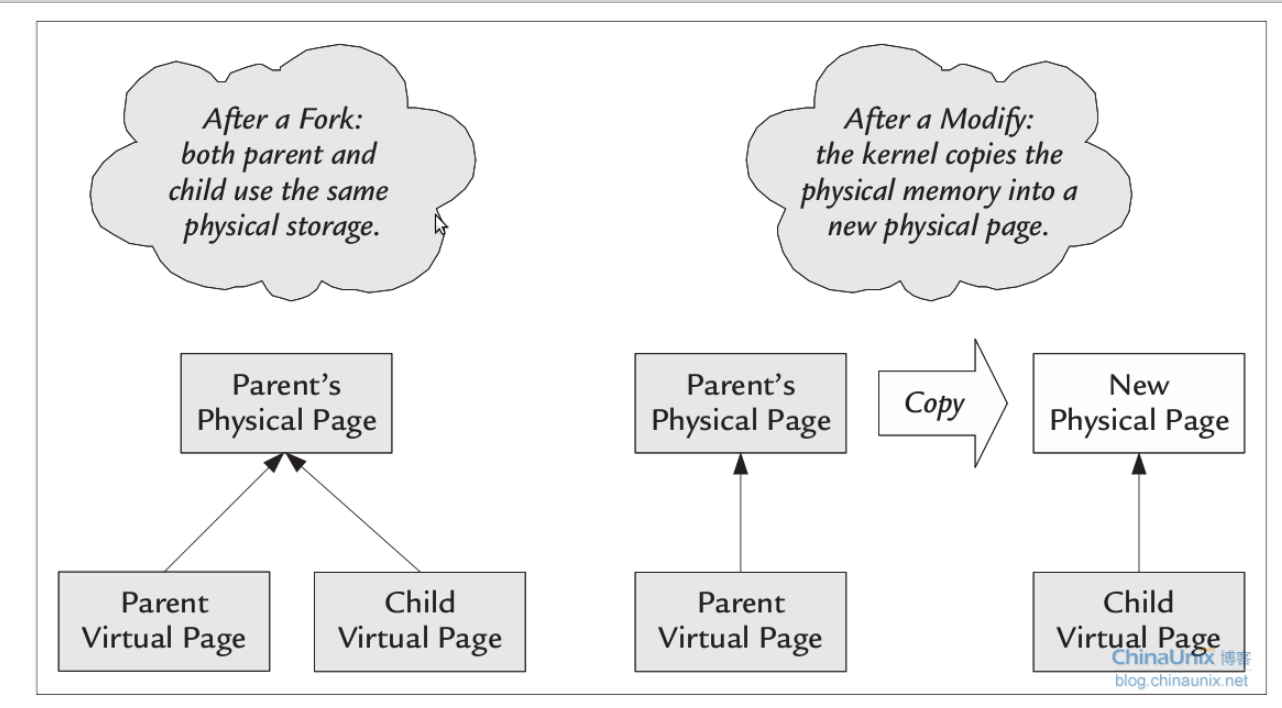
我们都知道fork创建进程的时候,并没有真正的copy内存,因为我们知道,对于fork来讲,有一个很讨厌的东西叫exec系列的系统调用,它会勾引子进程另起炉灶。如果创建子进程就要内存拷贝的的话,一执行exec,辛辛苦苦拷贝的内存又被完全放弃了。
内核采用的策略是写时拷贝,换言之,先把页表映射关系建立起来,并不真正将内存拷贝。如果进程读访问,什么都不许要做,如果进程写访问,情况就不同了,因为父子进程的内存空间是独立的,不应该互相干扰。所以这时候不能在公用同一块内存了,否则子进程的改动会被父进程觉察到。
下图是linux toolbox里面的一张图,比较好,我就拷贝出来了(如果有侵权通知立删),很好的解释了COW的原理。















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









