







和声搜索(Harmony Search, HS)算法是一种新颖的智能优化算法。类似于遗传算法对生物进化的模仿、模拟退火算法对物理退火的模拟以及粒子群优化算法对鸟群的模仿等,和声算法模拟了音乐演奏的原理。

上图是一个由7个人组成的乐队,每个人演奏一种乐器,它们的演奏加起来对应一组和声X={x1, x2, x3, x4, x5, x6, x7},他们会进行不断的进行配合以及排练来得到最好的和声效果,整个过程使用一个f(x)函数来衡量和声的效果好坏,这个f(x)就相当于总指挥,对他们演奏出的每一组和声进行权衡,如果达不到要求就继续演奏,直到得到一组满意的和声为止,这就是和声算法的最优化过程。
上面就是和声算法的基本思想,下面来具体看看算法的实现过程。
一、理解几个变量
1、和声库大小( Harmony memory Size,HMS):因为每个乐器演奏的音乐具有一定的范围,我们可以通过每个乐器的音乐演奏范围来构造一个解空间,然后通过这个解空间来随机产生一个和声记忆库,所以我们需要先为这个和声记忆库指定一个大小。
2、记忆库取值概率(Harmony memory considering rate, HMCR):每次我们需要通过一定的概率来从这个和声记忆库中取一组和声,并且对这组和声进行微调,得到一个组新的和声,然后对这组新和声进行判别是否优于和声记忆库中最差的和声,这个判别使用的就是上面说的f(x)函数进行比较,所以,我们需要随机产生一个记忆库取值概率。
3、微调概率(Pitch adjusting rate, PAR):上面已经说过,我们以一定的概率来在和声记忆库中选取一组和声,进行微调,这里指定的就是这个微调概率。
4、音调微调带宽 bw:上面说了会把从记忆库中取出的一组和声以一定的概率进行微调,这里指定就是这个调整幅度。
5、创作的次数 Tmax:这里指定的就是演奏家需要创作的次数,也就是上面整个调整过程需要重复多少次。
二、算法步骤
1、初始化上面的五个变量
2、确定解空间
上面有7个乐器,每个乐器的乐器演奏都在一定的范围内,通过确定每个乐器的音乐演奏范围,确定一个解空间。

上面的N对应的就是7,表示有7种乐器,U表示音乐的上限,L表示音乐的下限,这样就为每个乐器的乐器确定了一个范围,整个组合对应的就是一个解空间。
3、初始化和声记忆库
我们首先会根据初始化的和声库大小HMCR和上面和声的解空间来随机的产生一个大小为HMCR的和声记忆库。
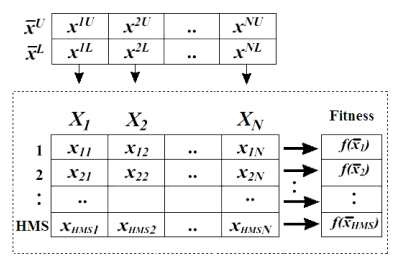
矩阵表示如下:

4、产生一个新和声
(1)在[0,1]之间随机的产生一个变量rand1,并且将rand1与上面初始化的HMCR进行比较。
- 如果rand1小于HMCR,那么在上面初始化的和声记忆库中随机的得到一组和声
- 否则就在上面的解空间中随机的得到一组和声。
最终,就得到一组和声,如果这组和声是从和声库中得到的,就需要对这组和声进行微调,在[0,1]之间随机的产生一个变量rand2
- 如果rand2小于上面初始化的PAR,就需要以上面初始化的微调带宽bw来对和声进行调整,得到一组新和声
- 否则,不做调整
可以看到上面进行了两次的变异过程,最终得到了一组和声。
5、更新和声库
将得到的新和声使用f(x)进行进行计算,如果这个新和声比上面初始化的和声库HM中最差的的解具有更好的目标函数解,那么将这新的和声替换掉和声库中那个最差的和声。
6、判断是否终止
根据上面初始化的创作的次数来看当前创作次数是否已经达到这个最大次数,如果没有,则重复4-5的过程,直到达到最大创作次数。
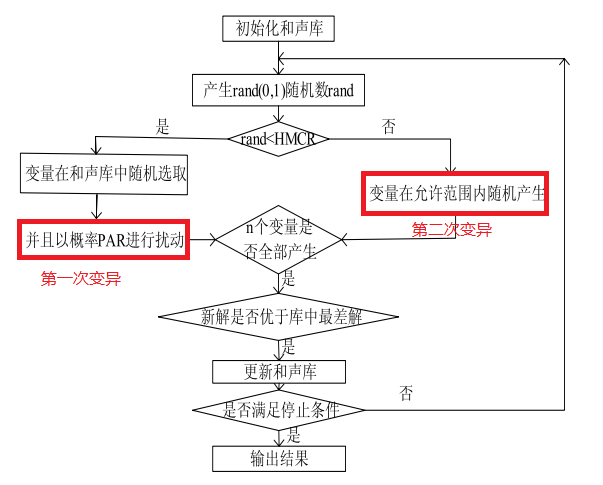

和声搜索算法的核心思想:首先初始化规模为预设大小的和声记忆库(Harmony Memory, HM);然后从和声记忆库和允许的范围中随机生成新的和声(一般依照概率来判断从哪里生成新的和声),如果新的和声优于和声记忆库中最差的和声,则将和声记忆库中最差的和声替换为新生成的和声;按照上述步骤进行循环直到满足停止条件为止。
和声搜索算法步骤:
Step1: 确定优化问题的目标函数、约束条件及和声搜索基本参数。(1)乐器(变量)个数m; (2)各种乐器的音调范围(变量取值范围);(3)和声记忆库HM可保存的和声个数M,而M应远小于所有可行解数目;(4)和声记忆库保留概率HMCR,即在产生新解时从和声记忆库中保留解分量的概率大小;(5)记忆库扰动概率PAR,即每次对部分解分量进行扰动的概率大小;(6)最大迭代次数,即循环的最大次数,为循环终止条件。
Step2: 和声记忆库初始化。将随机产生M个优化问题的初始解放入和声记忆库HM。
Step3: 产生新的解。每次产生一个新解X_new=(x_new1,x_new2……,x_newm),其中新解分量x_newi可通过三种机理产生:(1)保留和声记忆库中的某些解分量;(2)随机选择产生;(3)对(1)、(2)中的某些分量进行微调扰动。
保留和声记忆库中的某些解分量,以一定概率随机对和声记忆库的某些分量进行保留,即新产生的x_newi来源于记忆库中第i个解分量的集合Xi={x1i,x2i,……,xMi}的概率为HMCR。按机理(2)产生的新解分量x_newi是从第i个解分量的可行解空间(即变量i的权值范围)中以1-HMCR的概率随机产生的。对两种机理产生的解分量按概率PAR进行扰动,得到按机理(3)产生的新解分量。扰动原则为:
x_newi=x_newi+2*u*rand-u
其中,等式右边的x_new是扰动前新解的第i个解分量;u为带宽;rand为0到1的随机数。
Step4: 更新记忆库。判断新解是否优于HM内的最差解,若是,则将新的解替换最差解,得到新的和声记忆库。
Step5: 重复Step3、Step4,直到达到最大的迭代次数或满足停止准则后结束循环,输出最优解。

案例:
我们利用和声搜索算法求f(x)=(x1-2)2+(x2-3)2+(x3-1)2+3在[0,9]中的最小值问题;
首先:根据Step1来确定各个参数,变量个数m=3,变量取值范围是0到9,和声记忆库的和声数M取值为4(自己设定),和声记忆库保留概率HMCR=0.9(自己设定),记忆扰动概率PAR=0.1(自己设定),最大迭代次数1000(自己设定)。
其次:根据Step2为HM随机产生M=4个初始解。例如其中一个初始解为x1=8,x2=2,x3=4并且根据这个初始解得到相应的f(x)。
然后:根据Step3产生新的解。首先产生一个随机数,如果这个随机数小于保留概率HMCR,则从M个初始解的第1(以x1为例)个变量中随机选取一个,否则,从取值范围中选区一个值作为x1,再以扰动概率进行扰动(公式如上)。其他变量以此类推,然后得到新的一个解向量。并以这个解向量计算其f(x).如果得到的值小于HM内解向量相应的f(x),则替换其解向量。然后重复上面的工作,直到达到最大的迭代次数。最后从HM内中选取最小的那个解向量相应的f(x).其f(x)就是相应的最小值。。。。这个就是和声搜索的大致基本思想。。。。















 86
86

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









