






引入对偶的好处
为什么要引入对偶算法
1.对偶问题往往更加容易求解(结合拉格朗日和kkt条件)
2.可以很自然的引用核函数(拉格朗日表达式里面有内积,而核函数也是通过内积进行映射的)
要注意用拉格朗日对偶并没有改变最优解,而是改变了算法复杂度:在原问题下,求解算法的复杂度与样本维度(等于权值w的维度)有关;而在对偶问题下,求解算法的复杂度与样本数量(等于拉格朗日算子a的数量)有关。
因此,如果你是做线性分类,且样本维度低于样本数量的话,在原问题下求解就好了,Liblinear之类的线性SVM默认都是这样做的;但如果你是做非线性分类,那就会涉及到升维(比如使用高斯核做核函数,其实是将样本升到无穷维),升维后的样本维度往往会远大于样本数量,此时显然在对偶问题下求解会更好。
GBDT分类和回归的原理:
http://www.cnblogs.com/pinard/p/6140514.html
回归树讲解:http://idatamining.net/blog/?p=698

1、无监督和有监督算法的区别?
所谓的学习,其本质就是找到特征和标签间的关系(mapping)。输入数据有标签,则为有监督学习,没标签则为无监督学习。
A、训练集有输入有输出是有监督,包括所有的回归算法分类算法,比如线性回归、决策树、KNN、SVM等;
B、训练集只有输入没有输出是无监督,包括所有的聚类算法,比如k-means 、PCA、 GMM等
2、SVM 的推导,特性?多分类怎么处理?
答案参考:http://blog.csdn.net/keepreder/article/details/47146939
推导过程参见西瓜书
SVM有如下主要几个特点:
(1) 非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射;
(2) 对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心;
(3) 支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量。
(4) SVM 是一种有坚实理论基础的新颖的小样本学习方法。它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法。从本质上看,它避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预报样本的“转导推理”,大大简化了通常的分类和回归等问题。
(5) SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
(6) 少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。这种“鲁棒”性主要体现在:
①增、删非支持向量样本对模型没有影响;
②支持向量样本集具有一定的鲁棒性;
③有些成功的应用中,SVM 方法对核的选取不敏感
(7) SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
(8) SVM通过最大化决策边界的边缘来控制模型的能力。尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等。
(9) SVM在小样本训练集上能够得到比其它算法好很多的结果。支持向量机之所以成为目前最常用,效果最好的分类器之一,在于其优秀的泛化能力,这是是因为其本身的优化目标是结构化风险最小,而不是经验风险最小,因此,通过margin的概念,得到对数据分布的结构化描述,因此减低了对数据规模和数据分布的要求。SVM也并不是在任何场景都比其他算法好,对于每种应用,最好尝试多种算法,然后评估结果。如SVM在邮件分类上,还不如逻辑回归、KNN、bayes的效果好。
(10) 它基于结构风险最小化原则,这样就避免了过学习问题,泛化能力强。
(11) 它是一个凸优化问题,因此局部最优解一定是全局最优解的优点。
(12) 泛华错误率低,分类速度快,结果易解释
不足之处:
(1) SVM算法对大规模训练样本难以实施
SVM的空间消耗主要是存储训练样本和核矩阵,由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。针对以上问题的主要改进有有J.Platt的SMO算法、T.Joachims的SVM、C.J.C.Burges等的PCGC、张学工的CSVM以及O.L.Mangasarian等的SOR算法。
如果数据量很大,SVM的训练时间就会比较长,如垃圾邮件的分类检测,没有使用SVM分类器,而是使用了简单的naive bayes分类器,或者是使用逻辑回归模型分类。
(2) 用SVM解决多分类问题存在困难
经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。
(3)对缺失数据敏感,对参数和核函数的选择敏感
支持向量机性能的优劣主要取决于核函数的选取,所以对于一个实际问题而言,如何根据实际的数据模型选择合适的核函数从而构造SVM算法.目前比较成熟的核函数及其参数的选择都是人为的,根据经验来选取的,带有一定的随意性.在不同的问题领域,核函数应当具有不同的形式和参数,所以在选取时候应该将领域知识引入进来,但是目前还没有好的方法来解决核函数的选取问题.
支持向量机的主要应用和研究的热点
目前支持向量机主要应用在模式识别领域中的文本识别,中文分类,人脸识别等;同时也应用到许多的工程技术和信息过滤等方面.
LR 的推导,特性?
推导参见西瓜书或者http://www.itdadao.com/articles/c15a851018p0.html
1) 可用于概率预测,也可用于分类。
并不是所有的机器学习方法都可以做可能性概率预测(比如SVM就不行,它只能得到1或者-1)。可能性预测的好处是结果又可比性:比如我们得到不同广告被点击的可能性后,就可以展现点击可能性最大的N个。这样以来,哪怕得到的可能性都很高,或者可能性都很低,我们都能取最优的topN。当用于分类问题时,仅需要设定一个阈值即可,可能性高于阈值是一类,低于阈值是另一类。
2) 仅能用于线性问题
只有在feature和target是线性关系时,才能用Logistic Regression(不像SVM那样可以应对非线性问题)。这有两点指导意义,一方面当预先知道模型非线性时,果断不使用Logistic Regression; 另一方面,在使用Logistic Regression时注意选择和target呈线性关系的feature。
3) 各feature之间不需要满足条件独立假设,但各个feature的贡献是独立计算的。
逻辑回归不像朴素贝叶斯一样需要满足条件独立假设(因为它没有求后验概率)。但每个feature的贡献是独立计算的,即LR是不会自动帮你combine 不同的features产生新feature的 (时刻不能抱有这种幻想,那是决策树,LSA, pLSA, LDA或者你自己要干的事情)。举个例子,如果你需要TF*IDF这样的feature,就必须明确的给出来,若仅仅分别给出两维 TF 和 IDF 是不够的,那样只会得到类似 a*TF + b*IDF 的结果,而不会有 c*TF*IDF 的效果。
GBDT预测时每一棵树是否能并行?
预测的时候可以并行的。训练的时候下一轮的目标值依赖上一轮的结果,需要iteratively fits,不能并行。而预测的时候每棵树都已经建好,输入是原始数据,输出是把每棵树的预测值加在一起,这也MART(muliple additive regression trees)得名的由来,预测过程树之间并没有依赖,不存在先算后算的问题,所以可以并行。
作者:黄真川
链接:https://www.zhihu.com/question/41272145/answer/94628704
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
为什么说bagging是减少variance,而boosting是减少bias?
Bagging 是 Bootstrap Aggregating 的简称,意思就是再取样 (Bootstrap) 然后在每个样本上训练出来的模型取平均,所以是降低模型的 variance. Bagging 比如 Random Forest 这种先天并行的算法都有这个效果。Boosting 则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行加权,所以随着迭代不断进行,误差会越来越小,所以模型的 bias 会不断降低。这种算法无法并行,例子比如 Adaptive Boosting.
作者:匿名用户
链接:https://www.zhihu.com/question/26760839/answer/33963551
来源:知乎
著作权归作者所有,转载请联系作者获得授权。

xgboost相比传统gbdt有何不同?xgboost为什么快?xgboost如何支持并行?
作者:wepon
链接:https://www.zhihu.com/question/41354392/answer/98658997
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1、传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
2、传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
3、xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
4、Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
4、列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
5、对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
6、xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
决策树的特性?
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
算法
C4.5
C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:
1) 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
2) 在树构造过程中进行剪枝;
3) 能够完成对连续属性的离散化处理;
4) 能够对不完整数据进行处理。
C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
决策树的优点
相对于其他数据挖掘算法,决策树在以下几个方面拥有优势:
• 决策树易于理解和实现. 人们在通过解释后都有能力去理解决策树所表达的意义。
• 对于决策树,数据的准备往往是简单或者是不必要的 . 其他的技术往往要求先把数据一般化,比如去掉多余的或者空白的属性。
• 能够同时处理数据型和常规型属性。其他的技术往往要求数据属性的单一。
• 在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
• 对缺失值不敏感
• 可以处理不相关特征数据
• 效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
决策树的缺点
1)对连续性的字段比较难预测。
2)对有时间顺序的数据,需要很多预处理的工作。
3)当类别太多时,错误可能就会增加的比较快。
4)一般的算法分类的时候,只是根据一个字段来分类。
5)在处理特征关联性比较强的数据时表现得不是太好
SVM、LR、决策树的对比?
LR,DT,SVM都有自身的特性,首先来看一下LR,工业界最受青睐的机器学习算法,训练、预测的高效性能以及算法容易实现使其能轻松适应工业界的需求。LR还有个非常方便实用的额外功能就是它并不会给出离散的分类结果,而是给出该样本属于各个类别的概率(多分类的LR就是softmax),可以尝试不同的截断方式来在评测指标上进行同一模型的性能评估,从而得到最好的截断分数。LR不管是实现还是训练或者预测都非常高效,很轻松的handle大规模数据的问题(同时LR也很适合online learning)。此外,LR对于样本噪声是robust的,对于“mild”的多重共线性问题也不会受到太大影响,在特征的多重共线性很强的情况下,LR也可以通过L2正则化来应对该问题,虽然在有些情况下(想要稀疏特征)L2正则化并不太适用。
但是,当我们有大量的特征以及部分丢失数据时,LR就开始费劲了。太多的分类变量(变量值是定性的,表现为互不相容的类别或属性,例如性别,年龄段(1,2,3,4,5)等)也会导致LR的性能较差(这个时候可以考虑做离散化,其实肯定是要做离散化的)。还有一种论调是LR使用所有的样本数据用于训练,这引发了一个争论:明显是正例或者负例的样本(这种样本离分类边界较远,不大会影响分类的curve)不太应该被考虑太多,模型理想情况是由分类边界的样本决定的(类似SVM的思想),如下图。还有一个情况就是当特征是非线性时,需要做特征变换,这可能会导致特征维度急剧上升。下面是我认为的LR的一些利弊:
LR的优势:
对观测样本的概率值输出
实现简单高效
多重共线性的问题可以通过L2正则化来应对
大量的工业界解决方案
支持online learning(个人补充)
LR的劣势
特征空间太大时表现不太好
对于大量的分类变量无能为力
对于非线性特征需要做特征变换
依赖所有的样本数据
决策树对于单调的特征变换是”indifferent”的,也就是说特征的单调变换对于决策树来说不会产生任何影响(我本人最早使用决策树时没有理解内部的机制,当时还做了特征归一化等工作,发现效果没有任何变化),因为决策树是通过简单的使用矩形切分特征空间的,单调的特征变换只是做了特征空间的缩放而已。由于决策树是的分支生成是使用离散的区间或类别值的,所以对于不管多少分类变量都能够轻松适应,而且通过决策树生成出来的模型很直观而且容易解释(随着决策树的分支解释即可),而且决策树也可以通过计算落到该叶子类目的标签平均值获得最终类别的概率输出。但是这就引发了决策树的最大问题:非常容易过拟合,我们很容易就会生成一个完美拟合训练集的模型,但是该模型在测试集合上的表现却很poor,所以这个时候就需要剪枝以及交叉验证来保证模型不要过拟合了。
过拟合的问题还可以通过使用随机森林的方式来解决,随机森林是对决策树的一个很smart的扩展,即使用不同的特征集合和样本集合生成多棵决策树,让它们来vote预测样本的标签值。但是随机森林并没有像单纯决策树一样的解释能力。
DT的优势:
直观的决策过程
能够处理非线性特征
考虑了特征相关性
DT的劣势
极易过拟合(使用RF可以一定程度防止过拟合,但是只要是模型就会过拟合!)
无法输出score,只能给出直接的分类结果
SVM最大的好处就是它只依赖于处于分类边界的样本来构建分类面,可以处理非线性的特征,同时,只依赖于决策边界的样本还可以让他们能够应对”obvious”样本缺失的问题。由于SVM能够轻松搞定大规模的特征空间所以在文本分析等特征维度较高的领域是比较好的选择。SVM的可解释性并不像决策树一样直观,如果使用非线性核函数,SVM的计算代价会高很多。
SVM的优势:
可以处理高维特征
使用核函数轻松应对非线的性特征空间
分类面不依赖于所有数据
SVM的劣势:
对于大量的观测样本,效率会很低
找到一个“合适”的核函数还是很tricky的
GBDT 和 决策森林 的区别?
GBDT和随机森林的相同点:
1、都是由多棵树组成
2、最终的结果都是由多棵树一起决定
GBDT和随机森林的不同点:
1、组成随机森林的树可以是分类树,也可以是回归树;而GBDT只由回归树组成
2、组成随机森林的树可以并行生成;而GBDT只能是串行生成
3、对于最终的输出结果而言,随机森林采用多数投票等;而GBDT则是将所有结果累加起来,或者加权累加起来
4、随机森林对异常值不敏感,GBDT对异常值非常敏感
5、随机森林对训练集一视同仁,GBDT是基于权值的弱分类器的集成
6、随机森林是通过减少模型方差提高性能,GBDT是通过减少模型偏差提高性能
如何判断函数凸或非凸?
原文网址:http://blog.csdn.net/xmu_jupiter/article/details/47400411
很多最优化问题都是在目标函数是凸函数或者凹函数的基础上进行的。原因很简单,凸函数的局部极小值就是其全局最小值,凹函数的局部极大值就是其全局最大值。因此,只要我们依据一个策略,一步步地逼近这个极值,最终肯定能够到达全局最值附近。
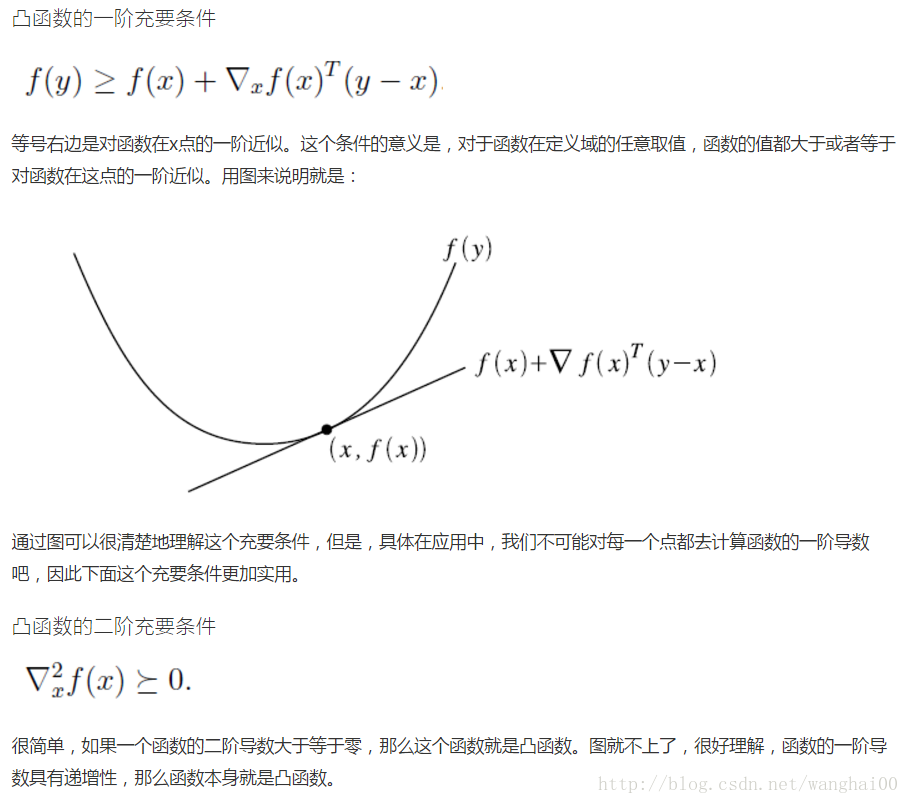
解释对偶的概念
Roughly speaking, duality provides a different angle to look at some mathematical objects.
教这门课的俄罗斯大叔每次都会举同样一个例子:你要证明一个人有罪很容易,找出他犯罪的证据;但是你要证明一个人没罪很难!不在场证据?高级犯法不一定要在场。对应回我们的线性规划可不可解的问题,某个解就是这个问题有解的证据。但是如果问题没有解,你怎么证明??!!对偶问题是解决这个事情的。这个就联系到Farkas lemma和其他一系列定理。全讲清楚就很花时间了。大概来讲就是说,有牛人找到一个跟原问题的对偶问题密切相关的问题,如果这个问题有解,原问题就没解。这样就提供了一个简单的证明原问题没解的途径。
作者:知乎用户
链接:https://www.zhihu.com/question/26658861/answer/53394624
来源:知乎
如何进行特征选择?
原文网址1:http://www.cnblogs.com/heaad/archive/2011/01/02/1924088.html
原文网址2:http://blog.csdn.net/google19890102/article/details/40019271
(1) 什么是特征选择
特征选择 ( Feature Selection )也称特征子集选择( Feature Subset Selection , FSS ) ,或属性选择( Attribute Selection ) ,是指从全部特征中选取一个特征子集,使构造出来的模型更好。
(2) 为什么要做特征选择
在机器学习的实际应用中,特征数量往往较多,其中可能存在不相关的特征,特征之间也可能存在相互依赖,容易导致如下的后果:
Ø 特征个数越多,分析特征、训练模型所需的时间就越长。
Ø 特征个数越多,容易引起“维度灾难”,模型也会越复杂,其推广能力会下降。
特征选择能剔除不相关(irrelevant)或亢余(redundant )的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。另一方面,选取出真正相关的特征简化了模型,使研究人员易于理解数据产生的过程。
一、特征选择和降维
1、相同点和不同点
特征选择和降维有着些许的相似点,这两者达到的效果是一样的,就是试图去减少特征数据集中的属性(或者称为特征)的数目;但是两者所采用的方式方法却不同:降维的方法主要是通过属性间的关系,如组合不同的属性得新的属性,这样就改变了原来的特征空间;而特征选择的方法是从原始特征数据集中选择出子集,是一种包含的关系,没有更改原始的特征空间。
2、降维的主要方法
Principal Component Analysis(主成分分析),详细见“简单易学的机器学习算法——主成分分析(PCA)”
Singular Value Decomposition(奇异值分解),详细见“简单易学的机器学习算法——SVD奇异值分解”
Sammon’s Mapping(Sammon映射)
二、特征选择的目标
引用自吴军《数学之美》上的一句话:一个正确的数学模型应当在形式上是简单的。构造机器学习的模型的目的是希望能够从原始的特征数据集中学习出问题的结构与问题的本质,当然此时的挑选出的特征就应该能够对问题有更好的解释,所以特征选择的目标大致如下:
提高预测的准确性
构造更快,消耗更低的预测模型
能够对模型有更好的理解和解释
三、特征选择的方法
主要有三种方法:
1、Filter方法
其主要思想是:对每一维的特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该维特征的重要性,然后依据权重排序。
主要的方法有:
Chi-squared test(卡方检验)
information gain(信息增益),详细可见“简单易学的机器学习算法——决策树之ID3算法”
correlation coefficient scores(相关系数)
2、Wrapper方法
其主要思想是:将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看作是一个是一个优化问题,这里有很多的优化算法可以解决,尤其是一些启发式的优化算法,如GA,PSO,DE,ABC等,详见“优化算法——人工蜂群算法(ABC)”,“优化算法——粒子群算法(PSO)”。
主要方法有:recursive feature elimination algorithm(递归特征消除算法)
3、Embedded方法
其主要思想是:在模型既定的情况下学习出对提高模型准确性最好的属性。这句话并不是很好理解,其实是讲在确定模型的过程中,挑选出那些对模型的训练有重要意义的属性。
主要方法:正则化,可以见“简单易学的机器学习算法——岭回归(Ridge Regression)”,岭回归就是在基本线性回归的过程中加入了正则项。
总结以及注意点
这篇文章中最后提到了一点就是用特征选择的一点Trap。个人的理解是这样的,特征选择不同于特征提取,特征和模型是分不开,选择不同的特征训练出的模型是不同的。在机器学习=模型+策略+算法的框架下,特征选择就是模型选择的一部分,是分不开的。这样文章最后提到的特征选择和交叉验证就好理解了,是先进行分组还是先进行特征选择。
答案是当然是先进行分组,因为交叉验证的目的是做模型选择,既然特征选择是模型选择的一部分,那么理所应当是先进行分组。如果先进行特征选择,即在整个数据集中挑选择机,这样挑选的子集就具有随机性。
我们可以拿正则化来举例,正则化是对权重约束,这样的约束参数是在模型训练的过程中确定的,而不是事先定好然后再进行交叉验证的。
为什么会产生过拟合,有哪些方法可以预防或克服过拟合?
所以过拟合有两种原因:
训练集和测试机特征分布不一致(白天鹅黑天鹅)
或者模型太过复杂(记住了每道题)而样本量不足
怎么防止过拟合呢?应该用收集多样化的样本、cross validation、正则化
采用 EM 算法求解的模型有哪些,为什么不用牛顿法或梯度下降法?
牛顿法和梯度下降法—原文网址:http://www.cnblogs.com/maybe2030/p/4751804.html
梯度下降法(Gradient Descent)
梯度下降法是最早最简单,也是最为常用的最优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。
牛顿法的缺点:
(1)靠近极小值时收敛速度减慢,如下图所示;
(2)直线搜索时可能会产生一些问题;
(3)可能会“之字形”地下降。
从上图可以看出,梯度下降法在接近最优解的区域收敛速度明显变慢,利用梯度下降法求解需要很多次的迭代。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。





1)牛顿法(Newton’s method)
牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。


牛顿法的优缺点总结:
优点:二阶收敛,收敛速度快;
缺点:牛顿法是一种迭代算法,每一步都需要求解目标函数的Hessian矩阵的逆矩阵,计算比较复杂。
非线性问题,牛顿法牛顿法提供了一种求解的办法。假设任务是优化一个目标函数f,求函数f的极大极小问题,可以转化为求解函数f的导数f’=0的问题(引入嗨森举证)http://blog.csdn.net/luoleicn/article/details/6527049
最优化问题中,牛顿法为什么比梯度下降法求解需要的迭代次数更少?
牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
作者:知乎用户
链接:https://www.zhihu.com/question/19723347/answer/14636244
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
EM算法
原文网址:http://www.cnblogs.com/lifegoesonitself/archive/2013/05/19/3087143.html




用 EM 算法推导解释 Kmeans
k-means算法与EM算法的关系是这样的:k-means是两个步骤交替进行,可以分别看成E步和M步;
M步中将每类的中心更新为分给该类各点的均值,可以认为是在「各类分布均为单位方差的高斯分布」的假设下,最大化似然值;
E步中将每个点分给中心距它最近的类(硬分配),可以看成是EM算法中E步(软分配)的近似。
作者:王赟 Maigo
链接:https://www.zhihu.com/question/49972233/answer/119434460
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
用过哪些聚类算法,解释密度聚类算法
瀚思安信在分析安全大数据时,常见的分析第一步就是把用户或者行为聚类,找出其中孤立的或者小类,然后作为潜在有问题的用户或者行为进行进一步分析。
聚类算法是最常见的机器学习算法种类,比如大家都熟悉的K-Means,原理或者实现都很简单。但是在安全大数据分析时,我们期望聚类算法满足额外的一些特性:
支持自定义的距离函数:比如衡量用户行为相识度。很多聚类算法都不满足这点,像标准K-Means就只能用欧式距离(很多初学者都没注意到这点)。
能并行化运行在Spark平台上。瀚思安全大数据分析即使是一个小系统,每天也输入接近TB级别的数据,能并发执行是基础的必需需求。而目前Spark Mllib里面只有K-Means一种并行聚类实现。
无参数,或者至少对参数不敏感。这点是因为我们数据分析大部分是无监督学习,不需要用户掌握复杂的调参数知识。前者可以用无参数贝叶斯法,后者就是下面要说的密度聚类算法。
密度聚类算法
聚类算法大致可以分为划分法(Partitioning Methods)、 层次法(Hierarchical Methods)、基于密度的方法(density-based methods)、 基于网格的方法(grid-based methods)、基于模型的方法(Model-Based Methods)。 而 OPTICS 就是一种基于密度的聚类算法,这种方法的思想就是当区域内点的密度大于某个阀值, 就把这些点归于一类,因此这种基于密度的聚类算法天生就有很强的寻找离群噪音点的能力。
各个算法详细介绍参见:https://www.zhihu.com/question/34554321
机器学习面试总结:http://www.cnblogs.com/tornadomeet/p/3395593.html
SVM详细推导过程:http://blog.csdn.net/v_july_v/article/details/7624837
K-means优缺点以及dbscan伪代码
基于划分的聚类:
K-means, k-medoids(每一个类别中找一个样本点来代表),CLARANS.
k-means是使下面的表达式值最小:
k-means算法的优点:
(1)k-means算法是解决聚类问题的一种经典算法,算法简单、快速。
(2)对处理大数据集,该算法是相对可伸缩的和高效率的,因为它的复杂度大约是O(nkt),其中n是所有对象的数目,k是簇的数目,t是迭代的次数。通常k远小于n。这个算法通常局部收敛。
(3)算法尝试找出使平方误差函数值最小的k个划分。当簇是密集的、球状或团状的,且簇与簇之间区别明显时,聚类效果较好。
缺点:
(1)k-平均方法只有在簇的平均值被定义的情况下才能使用,且对有些分类属性的数据不适合。
(2)要求用户必须事先给出要生成的簇的数目k。
(3)对初值敏感,对于不同的初始值,可能会导致不同的聚类结果。
(4)不适合于发现非凸面形状的簇,或者大小差别很大的簇。
(5)对于”噪声”和孤立点数据敏感,少量的该类数据能够对平均值产生极大影响。
2. 基于层次的聚类:
自底向上的凝聚方法,比如AGNES。
自上向下的分裂方法,比如DIANA。
3. 基于密度的聚类:
DBSACN,OPTICS,BIRCH(CF-Tree),CURE.
4. 基于网格的方法:
STING, WaveCluster.
5. 基于模型的聚类:
EM,SOM,COBWEB.
伪代码:

1、DBSCAN简介
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其他空间对象)的数目不小于某一给定阈值。DBSCAN算法的显著优点是聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类。但是由于它直接对整个数据库进行操作且进行聚类时使用了一个全局性的表征密度的参数,因此也具有两个比较明显的弱点:
(1)当数据量增大时,要求较大的内存支持I/O消耗也很大;
(2)当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差。
2、DBSCAN和传统聚类算法对比
DBSCAN算法的目的在于过滤低密度区域,发现稠密度样本点。跟传统的基于层次的聚类和划分聚类的凸形聚类簇不同,该算法可以发现任意形状的聚类簇,与传统的算法相比它有如下优点:
(1)与K-MEANS比较起来,不需要输入要划分的聚类个数;
(2)聚类簇的形状没有偏倚;
(3)可以在需要时输入过滤噪声的参数;

数据归一化好处:
归一化化定义:我是这样认为的,归一化化就是要把你需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保正程序运行时收敛加快。
相关解释参考:http://dataunion.org/15046.html
















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









