






LightGCN源码分析-零基础
论文链接:https://arxiv.org/abs/2002.02126
代码链接:https://github.com/gusye1234/LightGCN-PyTorch
论文来源:SIGIR 2020
LightGCN模型的代码
#定义LightGCN,继承BasicModel
class LightGCN(BasicModel):
def __init__(self,
config:dict,
dataset:BasicDataset):
super(LightGCN, self).__init__()
self.config = config
self.dataset : dataloader.BasicDataset = dataset
self.__init_weight()
def __init_weight(self):
#用户数量
self.num_users = self.dataset.n_users
#商品数量
self.num_items = self.dataset.m_items
#the embedding size of lightGCN,默认为64
self.latent_dim = self.config['latent_dim_rec']
#the layer num of lightGCN,默认为3
self.n_layers = self.config['lightGCN_n_layers']
#the batch size for bpr loss training procedure,默认0.6
self.keep_prob = self.config['keep_prob']
#默认flase
self.A_split = self.config['A_split']
#初始化每个user和item的Embedding,也是训练过程中调整的对象
#torch.nn.Embedding: 随机初始化词向量,词向量值在正态分布N(0,1)中随机取值
#embedding_user为num_users行latent_dim列矩阵
self.embedding_user = torch.nn.Embedding(
num_embeddings=self.num_users, embedding_dim=self.latent_dim)
#同上
self.embedding_item = torch.nn.Embedding(
num_embeddings=self.num_items, embedding_dim=self.latent_dim)
#whether we use pretrained weight or not
#默认pretrain=0
if self.config['pretrain'] == 0:
#nn.init.normal_从给定均值和标准差的正态分布N(mean, std)中生成值,填充输入的张量或变量
#用符合正态分布的标准差=0.1的数据填充embedding_user.weight
nn.init.normal_(self.embedding_user.weight, std=0.1)
nn.init.normal_(self.embedding_item.weight, std=0.1)
world.cprint('use NORMAL distribution initilizer')
else:
#否则pretrain
self.embedding_user.weight.data.copy_(torch.from_numpy(self.config['user_emb']))
self.embedding_item.weight.data.copy_(torch.from_numpy(self.config['item_emb']))
print('use pretarined data')
#定义激活函数
self.f = nn.Sigmoid()
#加载邻接矩阵
self.Graph = self.dataset.getSparseGraph()
print(f"lgn is already to go(dropout:{self.config['dropout']})")
加载邻接矩阵放在数据处理部分
如果A_split=ture,则会执行__dropout,将Graph中数据dropout,原代码中为false没有使用,所以这部分没仔细看
def __dropout_x(self, x, keep_prob):
size = x.size()
index = x.indices().t()
values = x.values()
random_index = torch.rand(len(values)) + keep_prob
random_index = random_index.int().bool()
index = index[random_index]
values = values[random_index]/keep_prob
g = torch.sparse.FloatTensor(index.t(), values, size)
return g
def __dropout(self, keep_prob):
if self.A_split:
graph = []
for g in self.Graph:
graph.append(self.__dropout_x(g, keep_prob))
else:
graph = self.__dropout_x(self.Graph, keep_prob)
return graph
前向传播
def computer(self):
"""
propagate methods for lightGCN
"""
users_emb = self.embedding_user.weight
items_emb = self.embedding_item.weight
#torch.cat()可以对tensor进行上下或左右拼接,这里是上下拼接
#用户数+物品数行,64列
all_emb = torch.cat([users_emb, items_emb])
embs = [all_emb]
#是否需要dropout
if self.config['dropout']:
if self.training:
print("droping")
g_droped = self.__dropout(self.keep_prob)
else:
g_droped = self.Graph
else:
#加载邻接矩阵
g_droped = self.Graph
for layer in range(self.n_layers):
if self.A_split:
temp_emb = []
for f in range(len(g_droped)):
temp_emb.append(torch.sparse.mm(g_droped[f], all_emb))
side_emb = torch.cat(temp_emb, dim=0)
all_emb = side_emb
else:
#torch.sparse.mm矩阵相乘g_droped*all_emb
#论文中的传播机制公式:E(k+1)=A*E(K)
all_emb = torch.sparse.mm(g_droped, all_emb)
#将每一层的数据放入embs,embs是一个list,每一个list存放一个tensor
embs.append(all_emb)
#这一行代码好像没作用?
embs = torch.stack(embs, dim=1)
#torch.mean,dim=1,按列求平均值,将3次卷积后和原本的取平均
light_out = torch.mean(embs, dim=1)
#将用户和商品分离
users, items = torch.split(light_out, [self.num_users, self.num_items])
return users, items
最后LightGCN得到的每个用户对每个Item的打分其实就是user embedding和item embedding的内积,对于结果的好坏使用loss函数进行判断。
LightGCN用到的Loss函数为贝叶斯个性排序BPRLoss,公式如下:
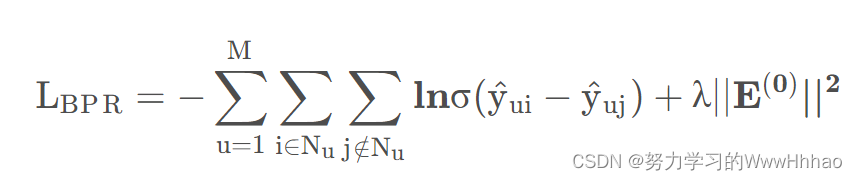
基本思想是最大化正样本和负样本之间的差距,即用户会购买的商品与用户不会购买的商品之间的概率差距越大越好。
代码中还有一个loss:
Loss即平均绝对误差(Mean Absolute Error, MAE),公式
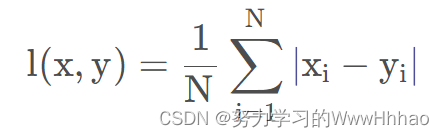
#在bpr_loss中被调用
def getEmbedding(self, users, pos_items, neg_items):
#取前向传播最后的结果的数据
all_users, all_items = self.computer()
users_emb = all_users[users]
pos_emb = all_items[pos_items]
neg_emb = all_items[neg_items]
#取原始的embedding数据
users_emb_ego = self.embedding_user(users)
pos_emb_ego = self.embedding_item(pos_items)
neg_emb_ego = self.embedding_item(neg_items)
return users_emb, pos_emb, neg_emb, users_emb_ego, pos_emb_ego, neg_emb_ego
def bpr_loss(self, users, pos, neg):
(users_emb, pos_emb, neg_emb,
userEmb0, posEmb0, negEmb0) = self.getEmbedding(users.long(), pos.long(), neg.long())
#回归损失
reg_loss = (1/2)*(userEmb0.norm(2).pow(2) +
posEmb0.norm(2).pow(2) +
negEmb0.norm(2).pow(2))/float(len(users))
pos_scores = torch.mul(users_emb, pos_emb)
pos_scores = torch.sum(pos_scores, dim=1)
neg_scores = torch.mul(users_emb, neg_emb)
neg_scores = torch.sum(neg_scores, dim=1)
#bpr_loss
loss = torch.mean(torch.nn.functional.softplus(neg_scores - pos_scores))
return loss, reg_loss
LightGCN数据处理的代码
LightGCN的Dataloader会继承一个BasicDataset类,里面初始化了所有要使用到的方法。
class BasicDataset(Dataset):
def __init__(self):
print("init dataset")
@property
def n_users(self):
raise NotImplementedError
@property
def m_items(self):
raise NotImplementedError
@property
def trainDataSize(self):
raise NotImplementedError
@property
def testDict(self):
raise NotImplementedError
@property
def allPos(self):
raise NotImplementedError
def getUserItemFeedback(self, users, items):
raise NotImplementedError
def getUserPosItems(self, users):
raise NotImplementedError
def getUserNegItems(self, users):
"""
not necessary for large dataset
it's stupid to return all neg items in super large dataset
"""
raise NotImplementedError
def getSparseGraph(self):
"""
build a graph in torch.sparse.IntTensor.
Details in NGCF's matrix form
A =
|I, R|
|R^T, I|
"""
raise NotImplementedError
正式数据处理,返回邻接矩阵
class Loader(BasicDataset):
"""
Dataset type for pytorch \n
Incldue graph information
gowalla dataset
"""
def __init__(self,config = world.config,path="../data/gowalla"):
# 加载基本的参数
cprint(f'loading [{path}]')
self.split = config['A_split']
self.folds = config['A_n_fold']
self.mode_dict = {'train': 0, "test": 1}
self.mode = self.mode_dict['train']
self.n_user = 0
self.m_item = 0
train_file = path + '/train.txt'
test_file = path + '/test.txt'
self.path = path
trainUniqueUsers, trainItem, trainUser = [], [], []
testUniqueUsers, testItem, testUser = [], [], []
self.traindataSize = 0
self.testDataSize = 0
# 读取数据
# .txt格式:userID itemID1 itemID2 ... itemIDn
with open(train_file) as f:
for l in f.readlines():
if len(l) > 0:
l = l.strip('\n').split(' ')
items = [int(i) for i in l[1:]]
uid = int(l[0])
trainUniqueUsers.append(uid)
#trainUser和trainItem长度对应,每个item 下标一一对应user
trainUser.extend([uid] * len(items))
trainItem.extend(items)
self.m_item = max(self.m_item, max(items))
self.n_user = max(self.n_user, uid)
self.traindataSize += len(items)
self.trainUniqueUsers = np.array(trainUniqueUsers)
self.trainUser = np.array(trainUser)
self.trainItem = np.array(trainItem)
with open(test_file) as f:
for l in f.readlines():
if len(l) > 0:
l = l.strip('\n').split(' ')
items = [int(i) for i in l[1:]]
uid = int(l[0])
testUniqueUsers.append(uid)
testUser.extend([uid] * len(items))
testItem.extend(items)
self.m_item = max(self.m_item, max(items))
self.n_user = max(self.n_user, uid)
self.testDataSize += len(items)
self.m_item += 1
self.n_user += 1
self.testUniqueUsers = np.array(testUniqueUsers)
self.testUser = np.array(testUser)
self.testItem = np.array(testItem)
self.Graph = None
print(f"{self.trainDataSize} interactions for training")
print(f"{self.testDataSize} interactions for testing")
print(f"{world.dataset} Sparsity : {(self.trainDataSize + self.testDataSize) / self.n_users / self.m_items}")
# (users,items)构建user item二分图,csr_matrix行压缩矩阵,行代表用户,列物品
self.UserItemNet = csr_matrix((np.ones(len(self.trainUser)), (self.trainUser, self.trainItem)),
shape=(self.n_user, self.m_item))
self.users_D = np.array(self.UserItemNet.sum(axis=1)).squeeze()
self.users_D[self.users_D == 0.] = 1
self.items_D = np.array(self.UserItemNet.sum(axis=0)).squeeze()
self.items_D[self.items_D == 0.] = 1.
# pre-calculate,获得各用户购买过物品的index,即正样本
self._allPos = self.getUserPosItems(list(range(self.n_user)))
self.__testDict = self.__build_test()
print(f"{world.dataset} is ready to go")
@property
def n_users(self):
return self.n_user
@property
def m_items(self):
return self.m_item
@property
def trainDataSize(self):
return self.traindataSize
@property
def testDict(self):
return self.__testDict
@property
def allPos(self):
return self._allPos
def _split_A_hat(self,A):
A_fold = []
fold_len = (self.n_users + self.m_items) // self.folds
for i_fold in range(self.folds):
start = i_fold*fold_len
if i_fold == self.folds - 1:
end = self.n_users + self.m_items
else:
end = (i_fold + 1) * fold_len
A_fold.append(self._convert_sp_mat_to_sp_tensor(A[start:end]).coalesce().to(world.device))
return A_fold
def _convert_sp_mat_to_sp_tensor(self, X):
coo = X.tocoo().astype(np.float32)
row = torch.Tensor(coo.row).long()
col = torch.Tensor(coo.col).long()
index = torch.stack([row, col])
data = torch.FloatTensor(coo.data)
return torch.sparse.FloatTensor(index, data, torch.Size(coo.shape))
def getSparseGraph(self):
print("loading adjacency matrix")
if self.Graph is None:
try:
pre_adj_mat = sp.load_npz(self.path + '/s_pre_adj_mat.npz')
print("successfully loaded...")
norm_adj = pre_adj_mat
except :
print("generating adjacency matrix")
s = time()
adj_mat = sp.dok_matrix((self.n_users + self.m_items, self.n_users + self.m_items), dtype=np.float32)
adj_mat = adj_mat.tolil()
R = self.UserItemNet.tolil()
adj_mat[:self.n_users, self.n_users:] = R
adj_mat[self.n_users:, :self.n_users] = R.T
adj_mat = adj_mat.todok()
# adj_mat = adj_mat + sp.eye(adj_mat.shape[0])
rowsum = np.array(adj_mat.sum(axis=1))
d_inv = np.power(rowsum, -0.5).flatten()
d_inv[np.isinf(d_inv)] = 0.
d_mat = sp.diags(d_inv)
norm_adj = d_mat.dot(adj_mat)
norm_adj = norm_adj.dot(d_mat)
norm_adj = norm_adj.tocsr()
end = time()
print(f"costing {end-s}s, saved norm_mat...")
sp.save_npz(self.path + '/s_pre_adj_mat.npz', norm_adj)
if self.split == True:
self.Graph = self._split_A_hat(norm_adj)
print("done split matrix")
else:
self.Graph = self._convert_sp_mat_to_sp_tensor(norm_adj)
self.Graph = self.Graph.coalesce().to(world.device)
print("don't split the matrix")
return self.Graph
def __build_test(self):
"""
return:
dict: {user: [items]}
"""
test_data = {}
for i, item in enumerate(self.testItem):
user = self.testUser[i]
if test_data.get(user):
test_data[user].append(item)
else:
test_data[user] = [item]
return test_data
def getUserItemFeedback(self, users, items):
"""
users:
shape [-1]
items:
shape [-1]
return:
feedback [-1]
"""
# print(self.UserItemNet[users, items])
return np.array(self.UserItemNet[users, items]).astype('uint8').reshape((-1,))
def getUserPosItems(self, users):
posItems = []
for user in users:
posItems.append(self.UserItemNet[user].nonzero()[1])
return posItems
# def getUserNegItems(self, users):
# negItems = []
# for user in users:
# negItems.append(self.allNeg[user])
# return negItems
LightGCN训练
def BPR_train_original(dataset, recommend_model, loss_class, epoch, neg_k=1, w=None):
Recmodel = recommend_model
Recmodel.train()
bpr: utils.BPRLoss = loss_class
with timer(name="Sample"):
S = utils.UniformSample_original(dataset)
# 采样,每个user采样一个正样本和一个负样本
# 提取用户id,正样本,负样本
users = torch.Tensor(S[:, 0]).long()
posItems = torch.Tensor(S[:, 1]).long()
negItems = torch.Tensor(S[:, 2]).long()
users = users.to(world.device)
posItems = posItems.to(world.device)
negItems = negItems.to(world.device)
users, posItems, negItems = utils.shuffle(users, posItems, negItems)
total_batch = len(users) // world.config['bpr_batch_size'] + 1
aver_loss = 0.
for (batch_i,
(batch_users,
batch_pos,
batch_neg)) in enumerate(utils.minibatch(users,
posItems,
negItems,
batch_size=world.config['bpr_batch_size'])):
#损失
cri = bpr.stageOne(batch_users, batch_pos, batch_neg)
aver_loss += cri
if world.tensorboard:
w.add_scalar(f'BPRLoss/BPR', cri, epoch * int(len(users) / world.config['bpr_batch_size']) + batch_i)
aver_loss = aver_loss / total_batch
time_info = timer.dict()
timer.zero()
return f"loss{aver_loss:.3f}-{time_info}"
可以看到,基本的流程为:
采样正负样本;
随机置乱样本顺序;
minibatch训练。















 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









