






本文介绍如何通过SpringBoot整合MCP(Model Context Protocol)框架对接国产大模型DeepSeek,并实现工具函数扩展能力。通过完整案例演示AI能力与业务系统的深度集成。
最终实现自然语言提问->查询数据库->自然语言输出
MCP介绍
我们知道,AI 模型通过连接外部应用,来扩展功能。每个外部应用的接口,都不一样,如果要接入10个应用,就要写10种接入代码,非常麻烦。而且,要是换一个模型,可能所有接入代码都要重写。
有鉴于此,Anthropic 公司在2024年11月提出了 MCP 协议。外部应用只需要支持这个协议,提供一个 MCP 接口(又称 MCP 服务器),那么 AI 模型就可以用统一的格式接入,不需要了解外部应用的接入细节。
所以,MCP 可以理解成一个 AI 与外部应用之间的适配层。对于 AI 来说,只要安装某个应用的 MCP 服务器,就能接入该应用,不用写任何代码(除了少数的配置项)。
由于 MCP 解决了 AI 应用的接入痛点,诞生至今仅半年,已经变得极其流行,就连 Anthropic 的竞争对手 OpenAI 公司都公开支持,网上开源的 MCP 服务器项目已经有上万个。
一、环境准备
1.1 依赖配置
<!-- Spring AI 核心依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-core</artifactId>
<version>1.0.0-M6</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-spring-boot-autoconfigure</artifactId>
<version>1.0.0-M6</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-server-webmvc-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>1.2 DeepSeek核心配置,需使用deepseek-chat模型,其他模型暂不支持工具调用
# application.properties
spring.ai.openai.enabled=true
spring.ai.openai.base-url=https://api.deepseek.com
spring.ai.openai.api-key=your-api-key
spring.ai.openai.chat.options.model=deepseek-chat二、MCP Server配置
2.1 工具回调注册
@Configuration
public class McpServerConfig {
@Bean
public ToolCallbackProvider studentToolCallbackProvider(StudentService studentService) {
// 打印传入的 studentService 实例
System.out.println("studentService 实例: " + studentService.getClass().getName());
MethodToolCallbackProvider provider = MethodToolCallbackProvider.builder()
.toolObjects(studentService)
.build();
// 通过反射获取工具名称
Arrays.stream(provider.getToolCallbacks())
.map(ToolCallback::getName)
.forEach(name -> System.out.println("注册的工具Registered Tool: " + name));
return provider;
}
}2.2 工具函数实现
@Slf4j
@Service
public class StudentServiceImpl implements StudentService {
@Autowired
private StudentMapper studentMapper;
public StudentServiceImpl() {
System.out.println("StudentServiceImpl 实例已创建");
}
@Override
@Tool(name = "queryListByName", description = "根据学生姓名模糊查询学生信息")
public List<StudentVO> queryListByName(@ToolParam(description = "学生姓名") String name){
//TODO 处理查询条件
LambdaQueryWrapper<Student> wrapper = Wrappers.lambdaQuery();
wrapper.eq(Student::getName,name);
List<Student> list=studentMapper.selectList(wrapper);
List<StudentVO> dataVOList = new ArrayList();
if (CollectionUtils.isNotEmpty(list)) {
list.forEach(p -> dataVOList.add(BeanUtil.toBean(p, StudentVO.class)));
}
return dataVOList;
}
@Override
@Tool(name = "pageInfo", description = "根据条件分页查询学生信息")
public IPage<StudentVO> pageInfo(@ToolParam(description = "学生分页信息") StudentPageDTO pageDTO){
IPage<Student> page = new Page<>();
page.setCurrent(pageDTO.getCurrent());
page.setSize(pageDTO.getSize());
//TODO 处理查询条件
LambdaQueryWrapper<Student> wrapper = Wrappers.lambdaQuery();
wrapper.eq(Student::getSex,pageDTO.getSex());
wrapper.like(Student::getName,pageDTO.getName());
wrapper.like(Student::getClassRoom,pageDTO.getClassRoom());
wrapper.like(Student::getAddress,pageDTO.getAddress());
wrapper.orderByDesc(Student::getId);
IPage<Student> pageList = studentMapper.selectPage(page, wrapper);
List<StudentVO> voList = new ArrayList<>();
if (CollectionUtils.isNotEmpty(pageList.getRecords())) {
pageList.getRecords().forEach(v -> {
voList.add(BeanUtil.toBean(v, StudentVO.class));
});
}
Page<StudentVO> result = new Page<>();
BeanUtils.copyProperties(page,result);
result.setRecords(voList);
return result;
}
}
三、ChatClient配置
3.1 客户端构建
@Configuration
public class ChatClientConfig {
/**
* 配置ChatClient,注册系统指令和工具函数
*/
@Bean
public ChatClient chatClient(ChatClient.Builder builder,ToolCallbackProvider toolCallbackProvider) {
return builder
.defaultSystem("你是一个学生信息管理助手,可以帮助用户查询学生信息。" +
"你可以根据学生姓名模糊查询学生信息、根据条件分页查询学生信息。" +
"回复时,请使用简洁友好的语言,并将学生信息整理为易读的格式。")
// 注册工具方法
.defaultTools(toolCallbackProvider)
.build();
}
}
四、API接口实现
4.1 控制器层
@RestController
@RequestMapping("/api/chat")
public class ChatController {
@Autowired
private ChatClient chatClient;
@PostMapping
public ResponseEntity<ChatResponse> chat(@RequestBody ChatRequest request) {
try {
// 创建用户消息
String userMessage = request.getMessage();
// 使用流式API调用聊天
String content = chatClient.prompt()
.user(userMessage)
.call()
.content();
return ResponseEntity.ok(new ChatResponse(content));
} catch (Exception e) {
e.printStackTrace();
return ResponseEntity.ok(new ChatResponse("处理请求时出错: " + e.getMessage()));
}
}
}五、功能验证
5.1 测试案例
测试使用的数据
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS "public"."student";
CREATE TABLE "public"."student" (
"id" int4 NOT NULL,
"name" varchar(255) COLLATE "pg_catalog"."default",
"age" int4,
"sex" varchar(255) COLLATE "pg_catalog"."default",
"class_room" varchar(255) COLLATE "pg_catalog"."default",
"address" varchar(255) COLLATE "pg_catalog"."default"
)
;
COMMENT ON COLUMN "public"."student"."id" IS '主键';
COMMENT ON COLUMN "public"."student"."name" IS '姓名';
COMMENT ON COLUMN "public"."student"."age" IS '年龄';
COMMENT ON COLUMN "public"."student"."sex" IS '性别';
COMMENT ON COLUMN "public"."student"."class_room" IS '班级';
COMMENT ON COLUMN "public"."student"."address" IS '家庭住址';
COMMENT ON TABLE "public"."student" IS '学生表';
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO "public"."student" VALUES (1, '张三', 18, '男', '三年一班', '山东省济南市高新区');
INSERT INTO "public"."student" VALUES (2, '李四', 20, '女', '三年一班', '山东省济南市高新区');
INSERT INTO "public"."student" VALUES (3, '王五', 18, '男', '三年二班', '山东省济南市高新区');
INSERT INTO "public"."student" VALUES (4, '张三', 17, '女', '三年三班', '山东省济南市高新区');
INSERT INTO "public"."student" VALUES (5, '钱六', 15, '男', '三年三班', '山东省济南市高新区');
-- ----------------------------
-- Primary Key structure for table student
-- ----------------------------
ALTER TABLE "public"."student" ADD CONSTRAINT "student_pkey" PRIMARY KEY ("id");
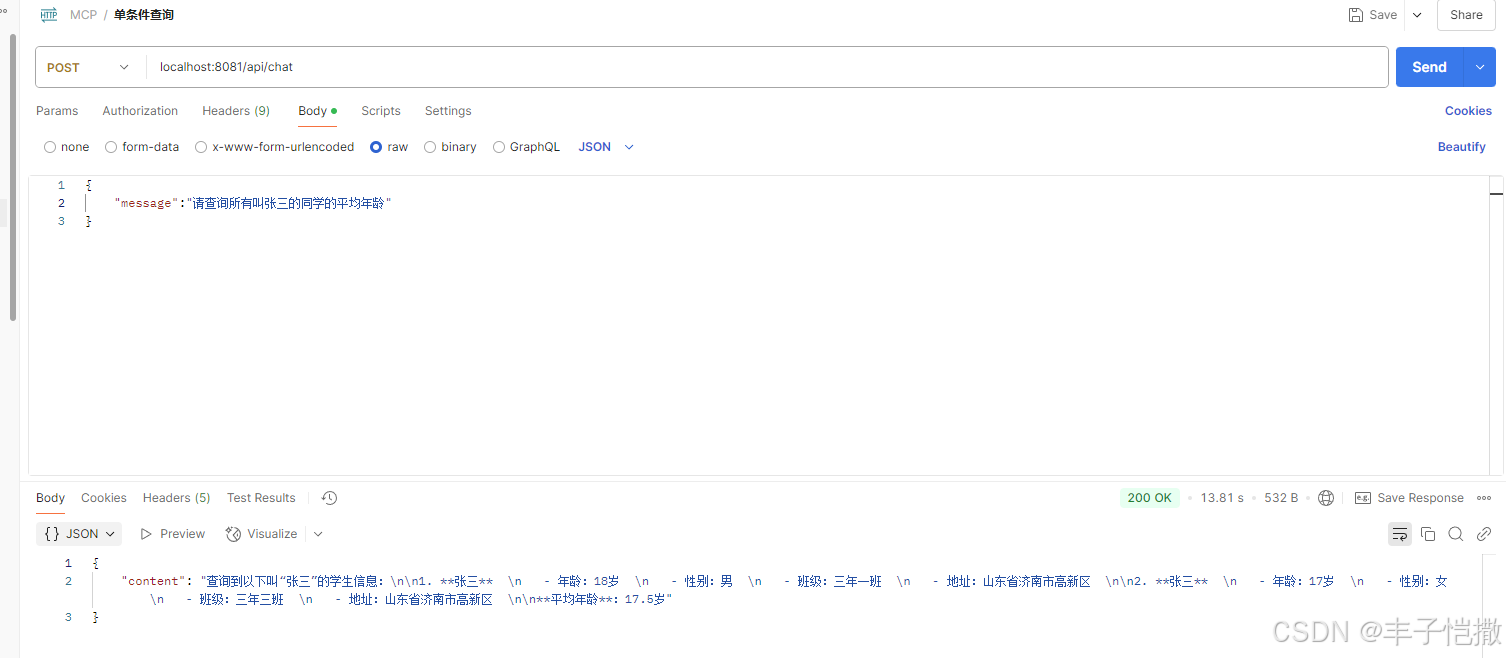
示例1:请查询所有叫张三的同学的平均年龄?
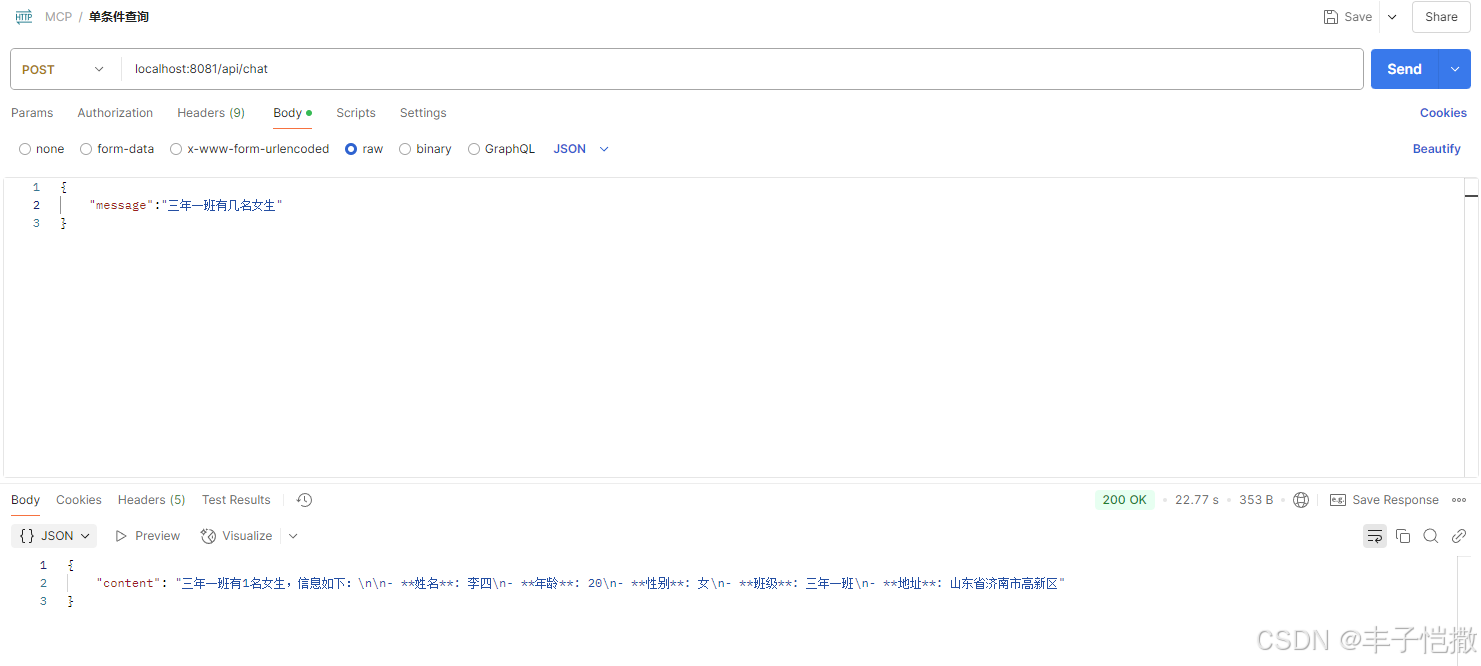
示例2:三年一班有几名女生?
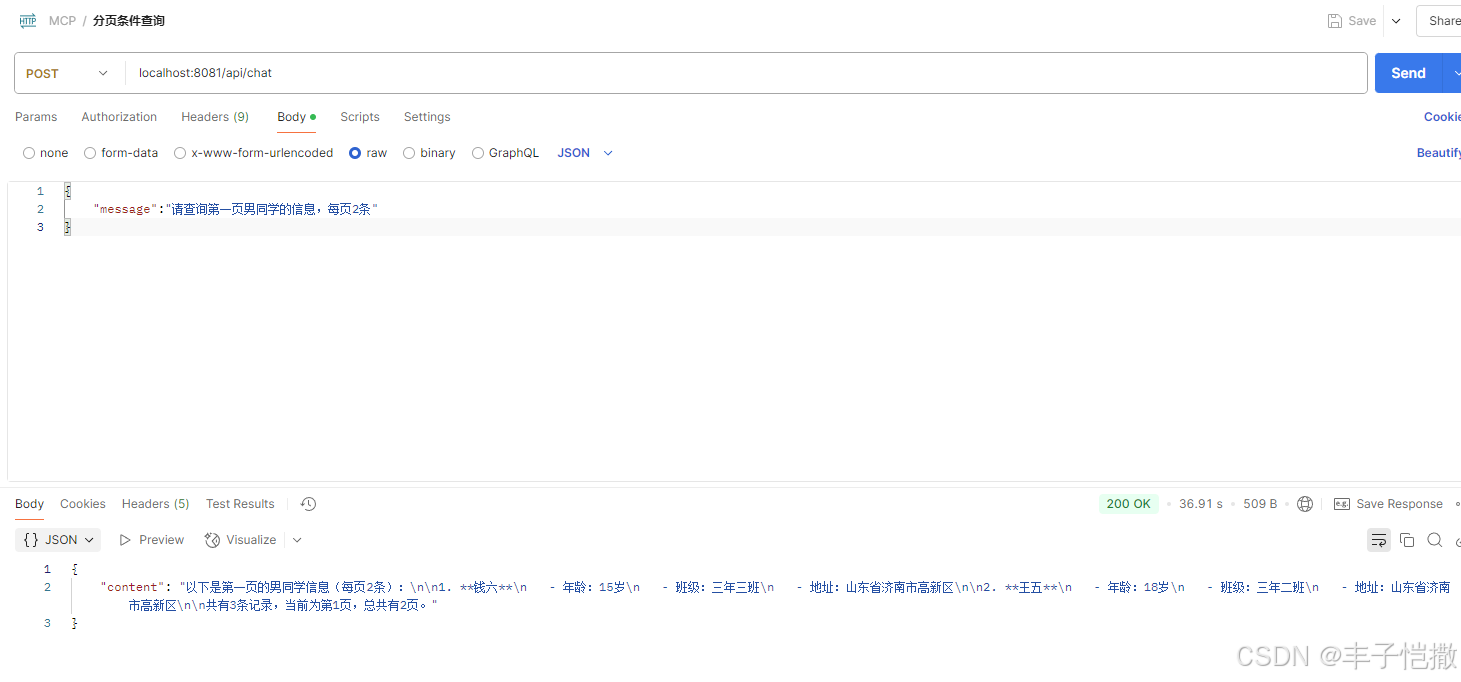
示例3:请查询第一页男同学的信息,每页2条
六、技术要点解析
-
工具动态注册机制
通过MethodToolCallbackProvider实现Spring Bean方法的自动发现,运行时动态注册工具函数 -
国产模型适配
通过修改base-url实现对DeepSeek的适配,保持与OpenAI API兼容 -
上下文管理
defaultSystem指令确保大模型始终遵守预设的业务规则
七、源码地址
注:需使用jdk17+ 源码中deepseek的api-key需替换为自己的
git源码![]() https://gitee.com/fengzikaisa/springboot-mcp-deepseek.git
https://gitee.com/fengzikaisa/springboot-mcp-deepseek.git
github源码![]() https://github.com/fengzikaisa/springboot-mcp-deepseek.git
https://github.com/fengzikaisa/springboot-mcp-deepseek.git


















 5605
5605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











