







def Dectree():
#获取数据
train=pd.read_csv('./train.csv')
test=pd.read_csv('./test.csv')
true=pd.read_csv('./gender_submission.csv')
#处理数据(找特征值。目标值)
# print(data[0:10])
x_train=train[['Pclass','Sex','Age']]
y_train=train['Survived']
x_test = test[['Pclass', 'Sex', 'Age']]
y_true=true['Survived']
#填补缺失值
x_train['Age'].fillna(x_train['Age'].mean(),inplace=True)
x_test['Age'].fillna(x_test['Age'].mean(), inplace=True)
#数据集分割
# x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
#特征工程数据处理,针对类别属性(即非数值类型)使用one-hot编码
#字典处理
dict=DictVectorizer(sparse=False)
X_train=dict.fit_transform(x_train.to_dict(orient='record'))
X_test=dict.transform(x_test.to_dict(orient='record'))
print(X_train)
print('names',dict.feature_names_)#获取特征名称
print(X_test)
#用决策树预测
dec=DecisionTreeClassifier(max_depth=5)
dec.fit(X_train,y_train)
y_predict = dec.predict(X_test)
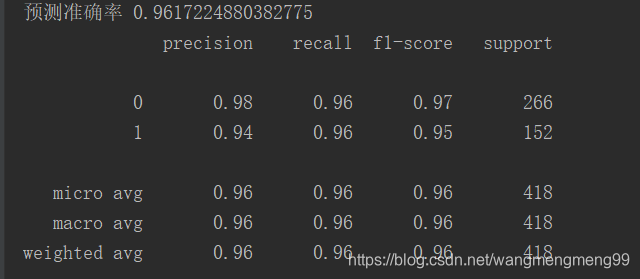
print('预测准确率',dec.score(X_test,y_true))
print(classification_report(y_true,y_predict))
print('y_predict', y_predict)
# 创造提交文件
ids = test["PassengerId"]
submission_df = {"PassengerId": ids,"Survived": y_predict}
submission = pd.DataFrame(submission_df)
submission.to_csv("submission_Titanic.csv", index=False)
if __name__ == '__main__':
Dectree()结果如下:
















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











