






一、背景:
在电子商务、社交媒体等领域,推荐系统已成为提升用户体验和平台价值的关键技术。推荐系统通过分析用户的行为数据,向用户推荐其可能感兴趣的内容或商品。ALS算法作为一种高效的矩阵分解算法,被广泛应用于推荐系统中,用于建立推荐模型。
推荐算法总的来说分为四大类:
1.基于关联规则的推荐(Association Rule) :
直观易懂,算法原理非常简单,不涉及任何矩阵、导数等。
适用于交易的信息数据:购物篮分析等等。
能够发现数据中隐藏的、不易察觉的关联关系,如“购买A商品的客户也倾向于购买B商品”。
2.基于内容的推荐(Content-based) :
比较内容相似度,进行推荐
对于新用户或新物品,只要有足够的内容信息,就可以进行推荐。
在网站没有多少客户的时候,可以使用此算法
3.基于人口统计学的推荐(Demographic):
按照用户标签进行推荐
用户可以添加或修改标签,增加与系统的互动。
4.基于协同过滤的推荐(Collaborative Filter) :CF推荐
基于用户协同过滤推荐(User-based):CF-U
基于物品协同过滤推荐(Item-based):CF-I
个性化程度高,能够基于用户的历史行为和相似用户的行为进行推荐
能够处理非结构化的复杂对象,如音乐、电影等。
二、ALS(Alternating Least Squares)交替最小二乘法:
协同过滤算法:
协同过滤算法,是最经典,最常用的推荐算法。通过分析用户兴趣,在用户群中找到指定用户的相似用户,综合这些相似用户对某一信息的评价,形成系统关于该指定用户对此信息的喜好程度预测
Spark MLlib支持ALS(Alternating Least Squares)交替最小二乘法属于协同过滤算法的一种:通过观察所有用户给产品的评价来判断每个用户的喜好,并向用户推荐适合的产品,也可以把某一个商品推进给多个用户。
算法{数据}:用户User对产品Prodect评价==rating==
算法{功能}:
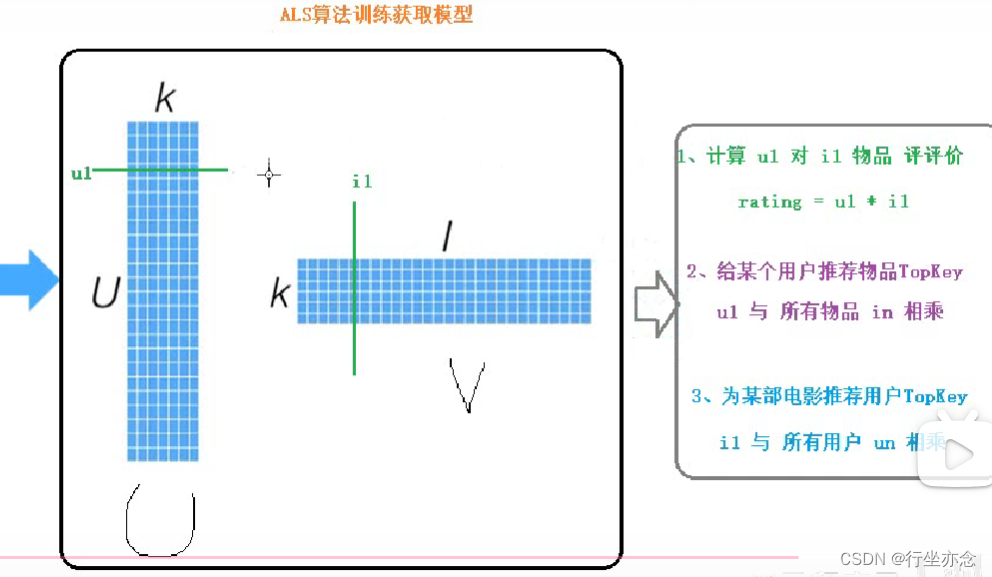
功能1:预测用户对某个产品的喜好,比如张三对某个电影喜好,以评分形式表示
功能2:给某个用户推荐可能喜好的N部电影(TopKey)
功能3:为某部电影推荐可能喜欢用户(TopKey)
实现协同过滤,需要完成以下步骤:
(1)收集用户偏好
(2)找到相似的用户或物品
(3)计算推荐
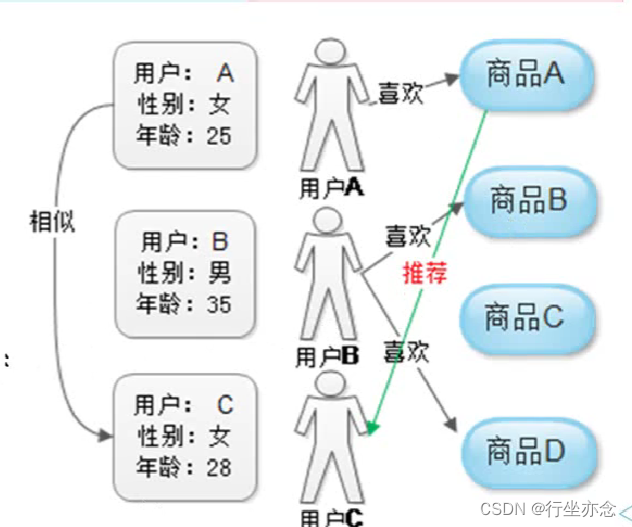
ALS算法思想:
第一步,初始化因子矩阵:U0
第二步,依据X矩阵求取另外一个因子矩阵
第三步,交替求去另外因子矩阵,知道抵达迭代次数或满足收敛条件终止。

三、ALS算法推导:
1、矩阵分解:
对于 R(m*n)的矩阵,ALS旨在找到两个低阶矩阵U(m*k) 和 矩阵 V(n*k)来近似逼近R(m*n)
即:

大矩阵:R(n*m)其中n表示用户量、m表示物品量因子(Factorization)矩阵:
用户因子矩阵User:U(n*k),其中n表示用户量,k表示维度,矩阵列个数
物品因子矩阵Item/Product:V(k*m),其中m表示物理量,k表示维度,矩阵行个数
K值称为秩rank,需要用户训练模型时,进行指定,属于超参数,通常设置为5、10、20等
2、损失函数:
为了找到便低秩矩阵U和V尽可能地迈近R,需要最小化下面的平方误差损失函数:
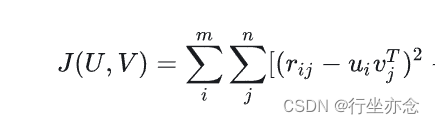
3、L2正则化:
损失函数一般需要加入正则化项来避免过拟合等问题,使用L2正则化,所以上面的公式改造为:
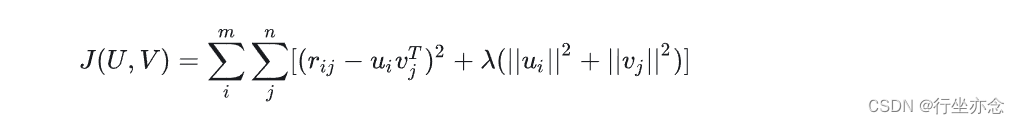
其中λ是正则化项的系数。
此时协同过滤就成功转化成了一个优化问题。由于变量u和v耦合到一起,这个问题并不
好求解,所以引入 ALS,也就是说可以先固定V(例如随机初始化 U),然后利用公式(2)先
求解U,然后固定 U,再求解 V,如此交替往复直至收敛,即所谓的交替最小二乘法求解法。
4、交替求解:
固定 V 求解U,对公式进行求导化简,可得:
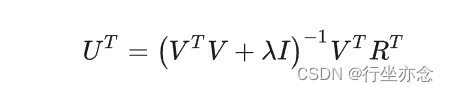
同理,固定 U 求解 V,对公式进行求导化简,可得:
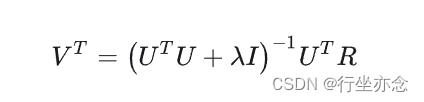
四、基于RDD构建ALS推荐模型:
第一:ALS,算法实现有两个方法{train} 和 {trainImpllicit}
当用户对物品评价为显式的调用{train}方法训练模型
当用户对物品评价为隐式的则调用{trainImplicit}方法训练模型
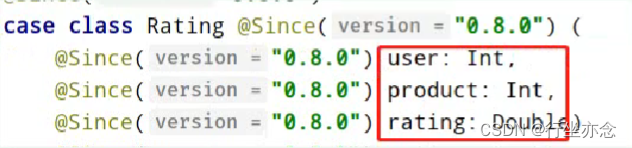
第二:Rating,样例类,用于封装用户对物品的评价。
第三:MatrixFactorizationModel,将数据放入ALS算法训练获取的模型,就是存储两个因子矩阵

接下来让我们使用ALS构建一个电影推荐模型:
整个{电影推荐模型构建}思路如下:
第一步:将用户对电影评价数据封装至Rating对象中
第二步:将数据集中到ALS算法,训练获取模型MatrixFactorizationModel
第三步:使用模型预测和推荐
代码如下:
/**
* 使用MovieLens 电影评分数据集,调用Spark MLlib 中协同过滤推荐算法ALS建立推荐模型:
* -a. 预测 用户User 对 某个电影Product 评价
* -b. 为某个用户推荐10个电影Products
* -c. 为某个电影推荐10个用户Users
*/
object SparkAlsRmdMovie {
def main(args: Array[String]): Unit = {
// TODO: 1. 构建SparkContext实例对象
val sc: SparkContext = {
// a. 创建SparkConf对象,设置应用相关配置
val sparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
// b. 创建SparkContext
val context = SparkContext.getOrCreate(sparkConf)
// 设置检查点目录
context.setCheckpointDir(s"datas/ckpt/als-ml-${System.nanoTime()}")
// c. 返回
context
}
// TODO: 2. 读取 电影评分数据
val rawRatingsRDD: RDD[String] = sc.textFile("datas/als/ml-100k/u.data")
println(s"Count = ${rawRatingsRDD.count()}")
println(s"First: ${rawRatingsRDD.first()}")
// TODO: 3. 数据转换,构建RDD[Rating]
val ratingsRDD: RDD[Rating] = rawRatingsRDD
// 过滤不合格的数据
.filter(line => null != line && line.split("\\t").length == 4)
.map{line =>
// 字符串分割
val Array(userId, movieId, rating, _) = line.split("\\t")
// 返回Rating实例对象
Rating(userId.toInt, movieId.toInt, rating.toDouble)
}
// 划分数据集为训练数据集和测试数据集
val Array(trainRatings, testRatings) = ratingsRDD.randomSplit(Array(0.9, 0.1))
// TODO: 4. 调用ALS算法中显示训练函数训练模型
// 迭代次数为20,特征数为10
val alsModel: MatrixFactorizationModel = ALS.train(
ratings = trainRatings, // 训练数据集
rank = 10, // 特征数rank
iterations = 20 // 迭代次数
)
// TODO: 5. 获取模型中两个因子矩阵
/**
* 获取模型MatrixFactorizationModel就是里面包含两个矩阵:
* -a. 用户因子矩阵
* alsModel.userFeatures
* -b. 产品因子矩阵
* alsModel.productFeatures
*/
// userId -> Features
val userFeatures: RDD[(Int, Array[Double])] = alsModel.userFeatures
userFeatures.take(10).foreach{tuple =>
println(tuple._1 + " -> " + tuple._2.mkString(","))
}
println("=======================================================")
// productId -> Features
val productFeatures: RDD[(Int, Array[Double])] = alsModel.productFeatures
productFeatures.take(10).foreach{
tuple => println(tuple._1 + " -> " + tuple._2.mkString(","))
}
// TODO: 6. 模型评估,使用RMSE评估模型,值越小,误差越小,模型越好
// 6.1 转换测试数据集格式RDD[((userId, ProductId), rating)]
val actualRatingsRDD: RDD[((Int, Int), Double)] = testRatings.map{tuple =>
((tuple.user, tuple.product), tuple.rating)
}
// 6.2 使用模型对测试数据集预测电影评分
val predictRatingsRDD: RDD[((Int, Int), Double)] = alsModel
// 依据UserId和ProductId预测评分
.predict(actualRatingsRDD.map(_._1))
// 转换数据格式RDD[((userId, ProductId), rating)]
.map(tuple => ((tuple.user, tuple.product), tuple.rating))
// 6.3 合并预测值与真实值
val predictAndActualRatingsRDD: RDD[((Int, Int), (Double, Double))] = predictRatingsRDD.join(actualRatingsRDD)
// 6.4 模型评估,计算RMSE值
val metrics = new RegressionMetrics(predictAndActualRatingsRDD.map(_._2))
println(s"RMSE = ${metrics.rootMeanSquaredError}")
// TODO 7. 推荐与预测评分
// 7.1 预测某个用户对某个产品的评分 def predict(user: Int, product: Int): Double
val predictRating: Double = alsModel.predict(196, 242)
println(s"预测用户196对电影242的评分:$predictRating")
println("----------------------------------------")
// 7.2 为某个用户推荐十部电影 def recommendProducts(user: Int, num: Int): Array[Rating]
val rmdMovies: Array[Rating] = alsModel.recommendProducts(196, 10)
rmdMovies.foreach(println)
println("----------------------------------------")
// 7.3 为某个电影推荐10个用户 def recommendUsers(product: Int, num: Int): Array[Rating]
val rmdUsers = alsModel.recommendUsers(242, 10)
rmdUsers.foreach(println)
// TODO: 8. 将训练得到的模型进行保存,以便后期加载使用进行推荐
val modelPath = s"datas/als/ml-als-model-" + System.nanoTime()
alsModel.save(sc, modelPath)
// TODO: 9. 从文件系统中记载保存的模型,用于推荐预测
val loadAlsModel: MatrixFactorizationModel = MatrixFactorizationModel
.load(sc, modelPath)
// 使用加载预测
val loaPredictRating: Double = loadAlsModel.predict(196, 242)
println(s"加载模型 -> 预测用户196对电影242的评分:$loaPredictRating")
// 为了WEB UI监控,线程休眠
Thread.sleep(10000000)
// 关闭资源
sc.stop()
}
}
电影推荐模型代码思路:
(1)创建SparkConf对象,设置应用相关配置 (2)读取电影评分数据 (3)数据转换,构建RDD[Rating] (4)调用ALS算法中显示训练函数训练模型 (5)获取模型中两个因子矩阵 (6)模型评估,使用RMSE评估模型,值越小,误差越小,模型越好 (7)推荐与预测评分 (8)将训练得到的模型进行保存,以便后期加载使用进行推荐 (9)从文件系统中记载保存的模型,用于推荐预测
使用数据计算得出以下结果:

数据源我放在这里啦:
链接:https://pan.baidu.com/s/1x4ntlxKKmEwNLam6mNPDiw?pwd=3h0i
提取码:3h0i
五、总结:
ALS交替最小二乘法作为一种高效的矩阵分解算法,在推荐系统中具有广泛的应用前景。通过交替优化U和V矩阵,ALS算法可以逼近原始评分矩阵,从而实现对未评分物品的预测和个性化推荐。同时,ALS算法还具有缓解冷启动问题和可扩展性等优点,使得其在大数据环境下更具优势。















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









