






文本分类任务是自然语言处理中最常见的任务,文本分类任务简单来说就是对给定的一个句子或一段文本使用文本分类器进行分类。
文本分类任务广泛应用于长短文本分类、情感分析、新闻分类、事件类别分类、政务数据分类、商品信息分类、商品类目预测、文章分类、论文类别分类、专利分类、案件描述分类、罪名分类、意图分类、论文专利分类、邮件自动标签、评论正负识别、药物反应分类、对话分类、税种识别、来电信息自动分类、投诉分类、广告检测、敏感违法内容检测、内容安全检测、舆情分析、话题标记等各类日常或专业领域中。
常见问题:
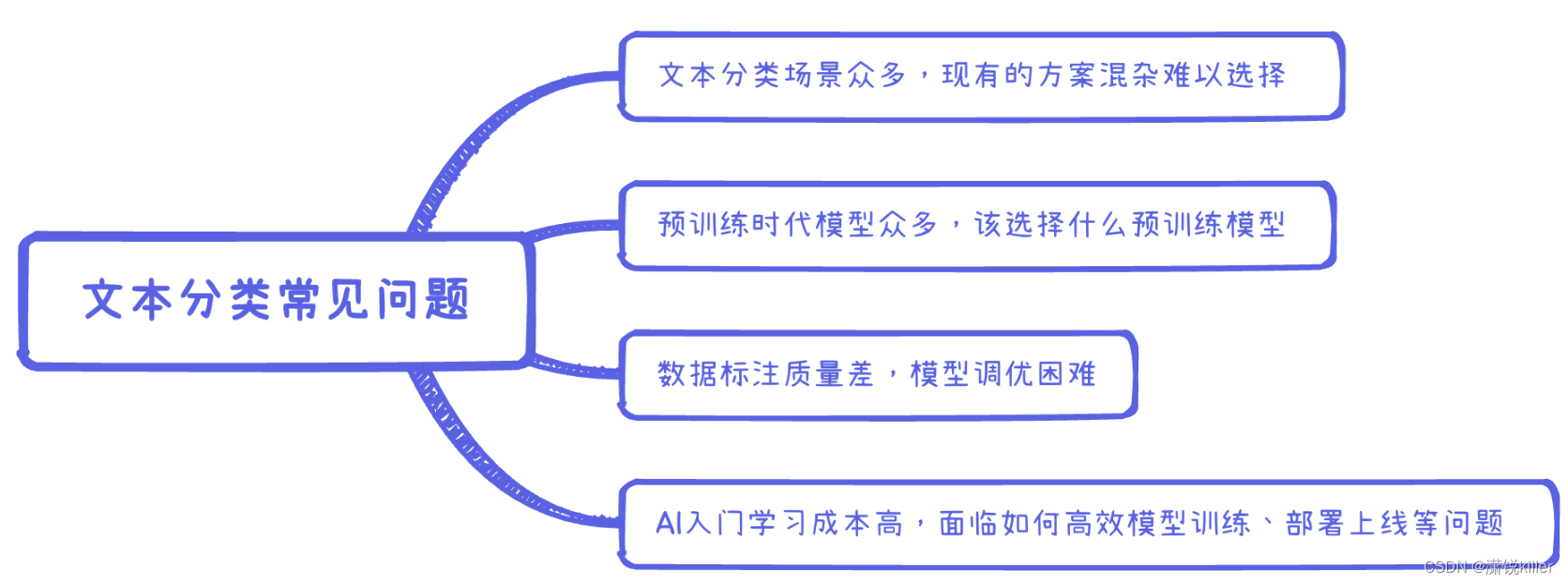
总体流程
主要场景
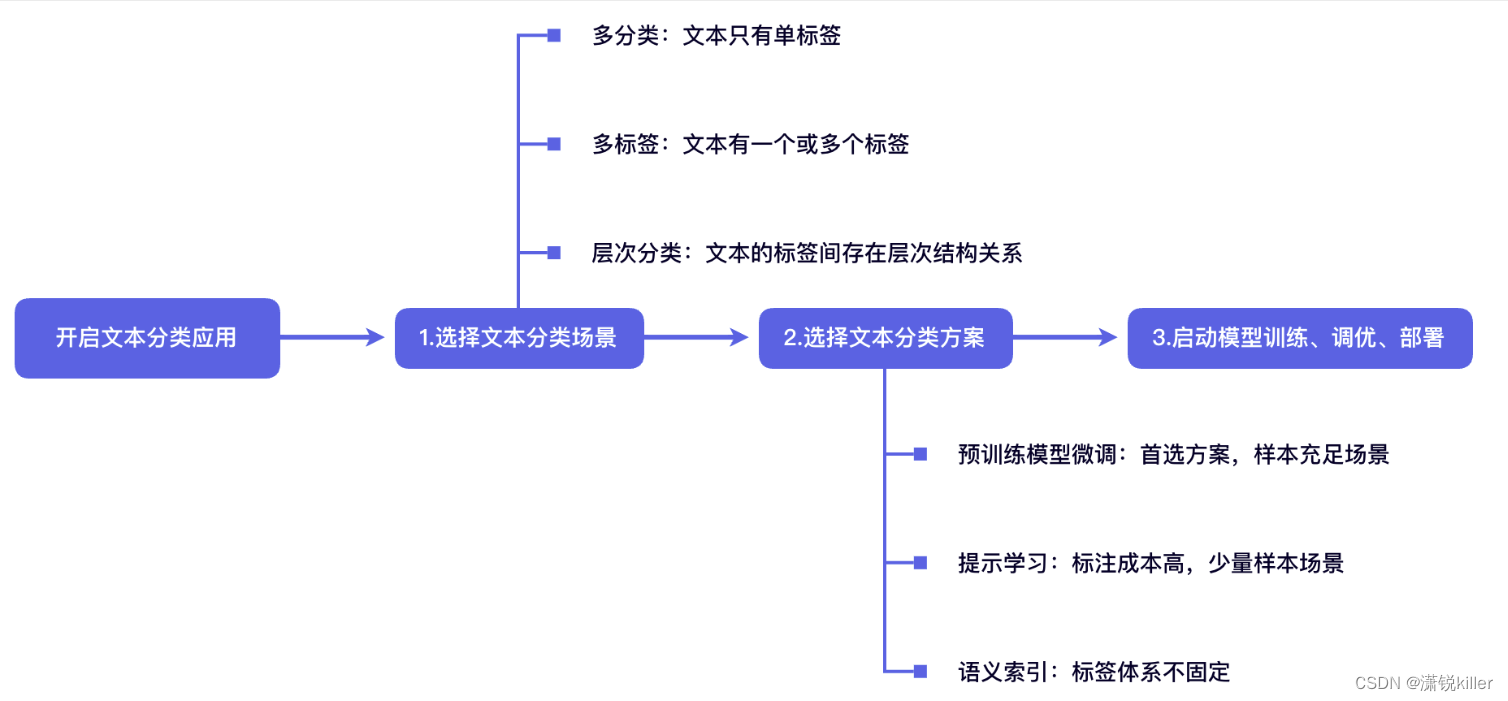
文本分类任务可以根据标签类型分为多分类(multi class)、多标签(multi label)、层次分类(hierarchical等三类任务,接下来我们将以下图的新闻文本分类为例介绍三种分类任务的区别。

方案一 :预训练模型微调
【方案选择】对于大多数任务,我们推荐使用预训练模型微调作为首选的文本分类方案,预训练模型微调提供了数据标注-模型训练-模型分析-模型压缩-预测部署全流程,有效减少开发时间,低成本迁移至实际应用场景。
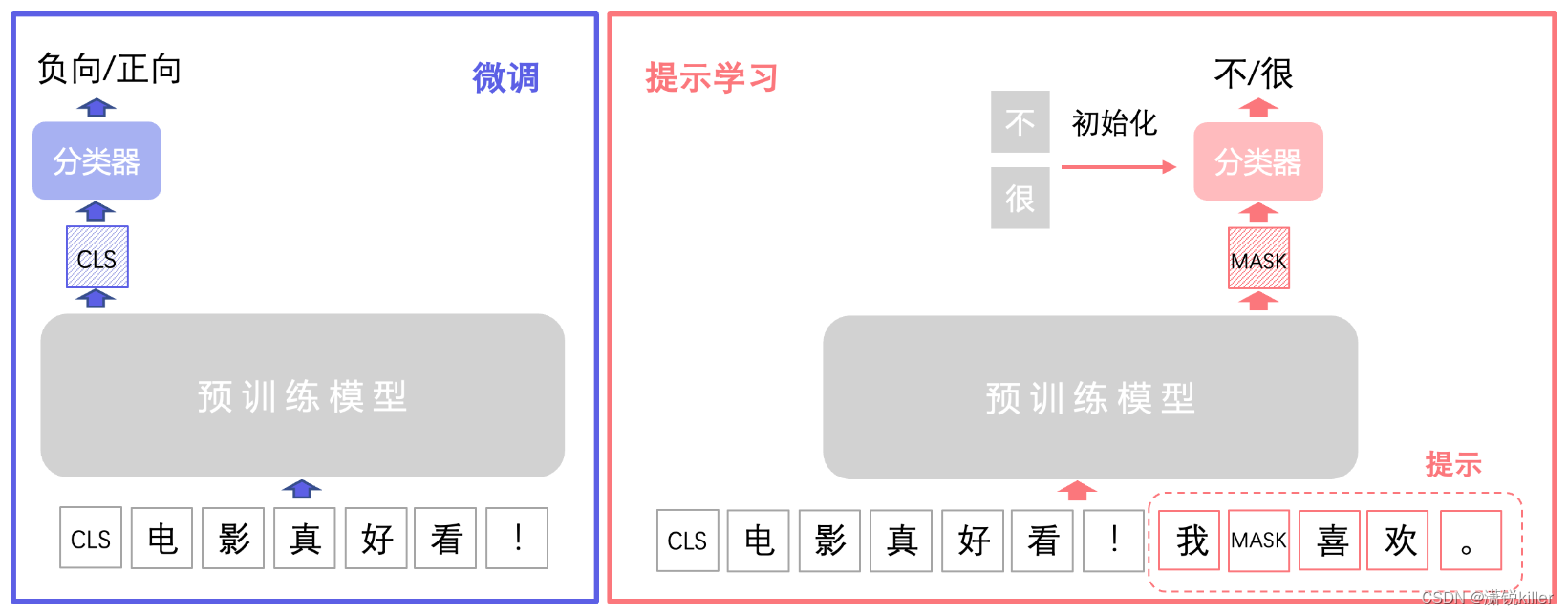
预训练模型微调在预训练模型 [CLS] 输出向量后接入线性层作为文本分类器,用具体任务数据进行微调训练文本分类器,使预训练模型”更懂”这个任务。
[CLS] 输出向量 是针对整个输入序列的全局表示,用于下游任务中对序列的整体属性进行分类或判断,
[MASK] 向量 则是在预训练阶段代表被遮盖词汇的预测表示,用于学习语言模型并通过预测任务提升模型对上下文的理解能力。
方案二:提示学习
提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。
提示学习的主要思想是将文本分类任务转换为构造提示中掩码 [MASK] 的分类预测任务,也即在掩码 [MASK]向量后接入线性层分类器预测掩码位置可能的字或词。提示学习使用待预测字的预训练向量来初始化分类器参数(如果待预测的是词,则为词中所有字的预训练向量平均值),充分利用预训练语言模型学习到的特征和标签文本,从而降低样本需求。
我们以下图情感二分类任务为例来具体介绍提示学习流程,分类任务标签分为 0:负向 和 1:正向 。在文本加入构造提示 我[MASK]喜欢。 ,将情感分类任务转化为预测掩码 [MASK] 的待预测字是 不 还是 很。具体实现方法是在掩码[MASK]的输出向量后接入线性分类器(二分类),然后用不和很的预训练向量来初始化分类器进行训练,分类器预测分类为 0:不 或 1:很 对应原始标签 0:负向 或 1:正向。
预训练模型微调则是在预训练模型[CLS]向量接入随机初始化线性分类器进行训练,分类器直接预测分类为 0:负向 或 1:正向。
二分类/多分类任务指南
基于预训练模型微调的二分类/多分类端到端应用方案,打通数据标注-模型训练-模型调优-模型压缩-预测部署全流程
二分类/多分类数据集的标签集含有两个或两个以上的类别,所有输入句子/文本有且只有一个标签。在文本多分类场景中,我们需要预测输入句子/文本最可能来自 n 个标签类别中的哪一个类别。在本项目中二分类任务被视为多分类任务中标签集包含两个类别的情况,以下统一称为多分类任务。
多分类数据标注-模型训练-模型分析-模型压缩-预测部署流程图
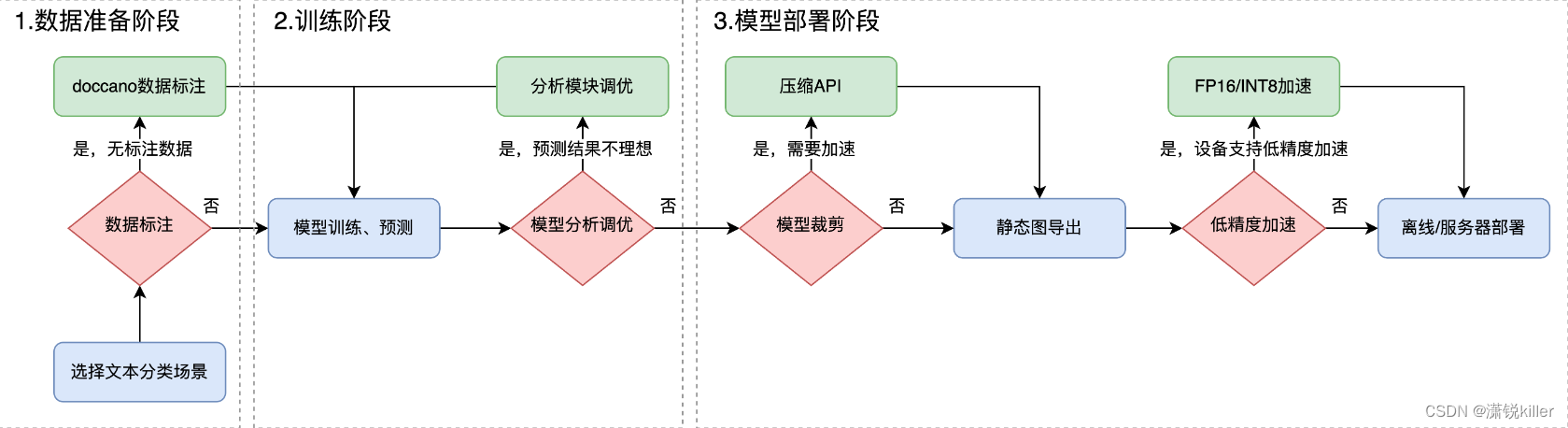
PaddleNLP/applications/text_classification/multi_class at develop · PaddlePaddle/PaddleNLP · GitHub
2.2 代码结构

2.3 数据准备
训练需要准备指定格式的本地数据集
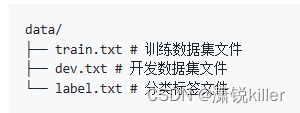
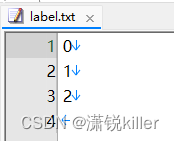
训练、开发、测试数据集 文件中文本与标签类别名用tab符'\t'分隔开,文本中避免出现tab符'\t'

2.4 模型训练
python3 train.py --do_train --do_eval --do_export --model_name_or_path ernie-3.0-tiny-medium-v2-zh --output_dir checkpoint --device gpu:0 --early_stopping_patience 5 --learning_rate 3e-5 --max_length 128 --metric_for_best_model accuracy --load_best_model_at_end --logging_steps 5 --evaluation_strategy epoch --save_strategy epoch --save_total_limit 1
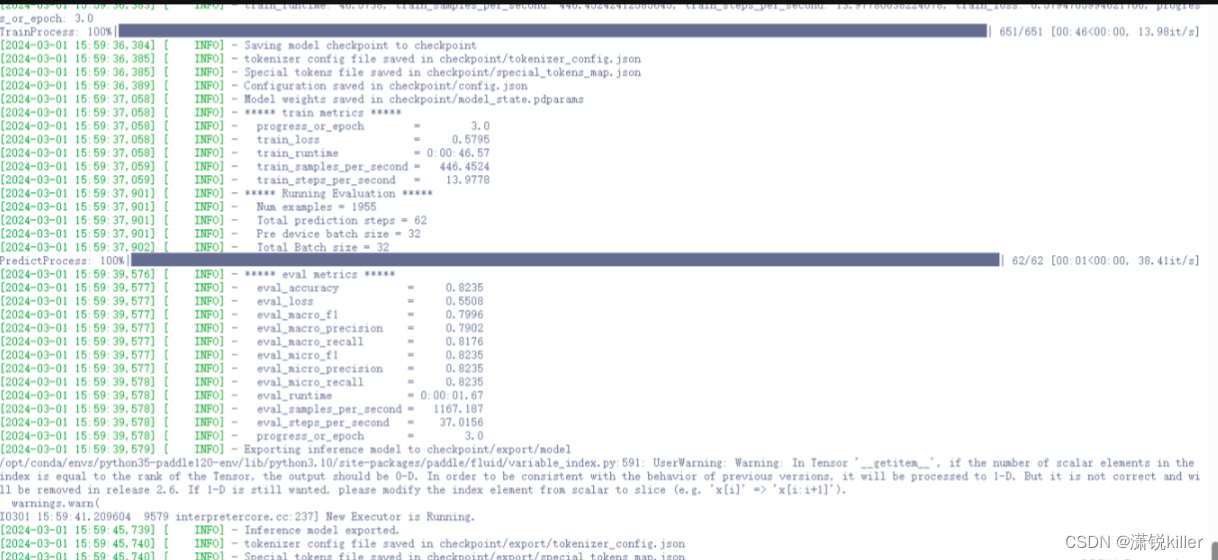
2.4.2 训练评估
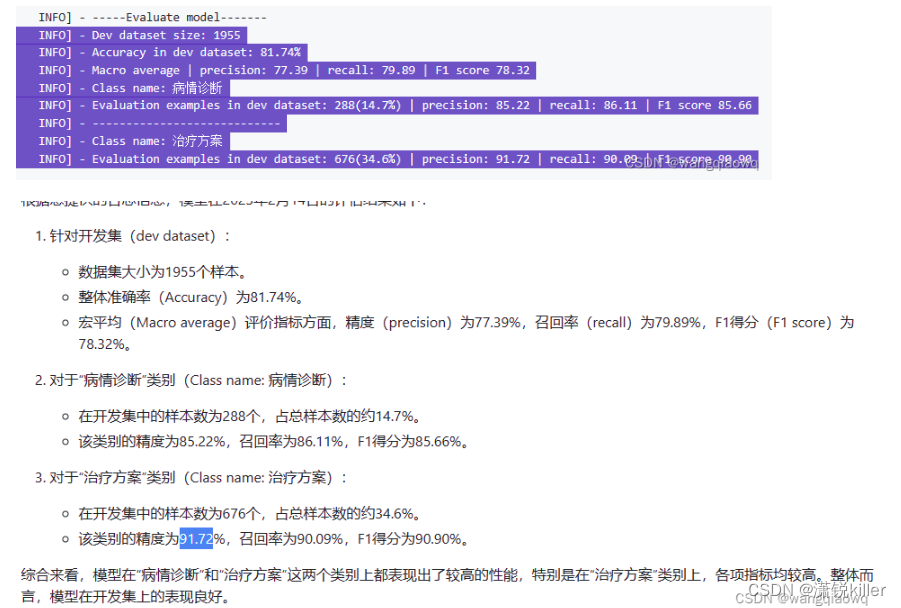
训练后的模型我们可以开启debug模式,对每个类别分别进行评估,并打印错误预测样本保存在bad_case.txt。
python train.py --do_eval --debug --device gpu:0 --model_name_or_path checkpoint --output_dir checkpoint --per_device_eval_batch_size 32 --max_length 128 --test_path './data/dev.txt'

2.5 模型预测 和 服务化
# 用于启动FastAPI应用的ASGI服务器。
import uvicorn
# FastAPI的核心组件,分别用于构建API应用和处理HTTP请求。
from fastapi import FastAPI,Request
# (来自anyio库):用于在FastAPI应用启动时设置线程限制。
from anyio.lowlevel import RunVar
from anyio import CapacityLimiter
import json
from typing import List
# PaddlePaddle深度学习框架
import paddle
from fastapi import FastAPI
# 基于PaddlePaddle的自然语言处理库
from paddlenlp import Taskflow
from paddlenlp.transformers import ErnieTokenizer, ErnieModel
# 加载静态文本分类模型
cls = Taskflow("text_classification", task_path='../../checkpoint/export', is_static_model=True)
# 加载ERNIE 3.0模型
model = ErnieModel.from_pretrained('ernie-3.0-tiny-medium-v2-zh')
# 加载预训练模型参数
model.set_state_dict(paddle.load('ernie_3.0_text_classification_model.pdparams'))
# 将模型设置为评估模式
model.eval()
# 加载分词器
tokenizer = ErnieTokenizer.from_pretrained('ernie-3.0-tiny-medium-v2-zh')
# 创建一个FastAPI实例app
app = FastAPI()
# 在应用启动时(@app.on_event("startup")),设置默认线程限制器为单线程(容量限制为1)
@app.on_event("startup")
def startup():
print("start")
RunVar("_default_thread_limiter").set(CapacityLimiter(1))
# 定义一个名为encode的异步路由,处理/路径上的POST请求
@app.post("/")
async def encode(request: Request):
# 从请求体中获取并解析JSON数据
request_body = await request.body()
request_json = json.loads(request_body.decode("utf-8"))
texts = [item["text"] for item in request_json["data"]]
print(texts)
result = cls(texts)
print(result)
# 使用分词器对文本进行编码
# 对texts中的文本进行分词、填充、截断等预处理操作,生成模型所需的输入张量encoded_input(最大序列长度为512
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pd', max_seq_len=512)
#print(encoded_input)
#使用无梯度计算模式(with paddle.no_grad():)执行以下步骤
#获取模型的输出向量(第二个返回值),转换为NumPy数组并存储到search_vector
with paddle.no_grad():
search_vector = model(**encoded_input)[1].numpy()
#print(search_vector)
print("end vector")
# 获取预测结果
with paddle.no_grad():
logits = model(**encoded_input)
print(logits)
probs = paddle.nn.functional.softmax(logits, axis=-1) #计算模型输出的softmax概率分布(probs)
print(probs)
#print("Shape of probs:", probs.shape)
#print("Type of probs:", type(probs))
print(paddle.argmax(probs, axis=-1)) #找出每个样本的概率最大类别的索引(paddle.argmax(probs, axis=-1)
print("this one")
print(paddle.argmax(probs, axis=-1).numpy())
print("this two")
#predicted_class = paddle.argmax(probs, axis=-1).numpy()[0] # 获取概率最高的类别索引
#print("this three " + predicted_class)
# 每个输入文本经过模型编码后得到的向量表示(列表形式)
return {"predictionList": result, "vector": search_vector.tolist(), "predicted_class": predicted_class}nohup python3 -m uvicorn main:app --host 192.168.1.243 --port 4001 > paddlenlpweb.log 2>&1 &
检验:
curl -X POST http://192.168.1.243:4001/ -H 'Content-Type: application/json' -d '{"data":[{"text": "智能大屏"}, {"text": "智能销售"}]}'
GPU
飞桨AI Studio星河社区-人工智能学习与实训社区 (baidu.com)
1、训练用的脚本
pip install openpyxl
train.py
import pandas as pd
import paddle
from paddlenlp.transformers import ErnieForSequenceClassification, ErnieTokenizer
# 1. 读取Excel文件中的数据
data = pd.read_excel('sentense3.xlsx')
texts = data['sentences'].tolist()
labels = data['labels'].tolist()
# 2. 初始化 ERNIE 3.0 模型和分词器
model_name = 'ernie-3.0-tiny-medium-v2-zh' # 根据实际情况选择模型版本
tokenizer = ErnieTokenizer.from_pretrained(model_name)
num_classes = len(set(labels)) # 计算类别数量
model = ErnieForSequenceClassification.from_pretrained(model_name, num_classes=num_classes)
# 3. 数据预处理
def preprocess_fn(text, label):
inputs = tokenizer(text, max_seq_length=128, padding='max_length', truncation=True)
return {'input_ids': paddle.to_tensor(inputs['input_ids']),
'token_type_ids': paddle.to_tensor(inputs['token_type_ids']),
'label': paddle.to_tensor([label])}
# 转换为模型可以接受的数据格式
dataset = [preprocess_fn(text, label) for text, label in zip(texts, labels)]
# 4. 创建数据加载器
batch_size = 6
data_loader = paddle.io.DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 5. 定义优化器和其他训练参数
optimizer = paddle.optimizer.AdamW(parameters=model.parameters(), learning_rate=5e-5)
num_epochs = 3 #根据实际需求调整训练轮数
# 6. 开始训练
for epoch in range(num_epochs):
lit = 0
for batch_data in data_loader:
input_ids = batch_data['input_ids']
token_type_ids = batch_data['token_type_ids']
labels = batch_data['label']
logits = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = paddle.nn.functional.cross_entropy(logits, labels)
loss.backward()
optimizer.step()
optimizer.clear_grad()
lit += 1
print(f"Epoch {epoch + 1}: step:{str(lit)}")
print(f"Epoch {epoch + 1}: Loss: {loss.numpy().mean()}")
model_path = "ernie_3.0_text_classification_model.pdparams"
paddle.save(model.state_dict(), model_path) # 保存模型参数训练的数据(部分)
各账户汇总及明细 0
查看账户信息 0
想看销售的统计分析情况 0
想看采购的统计分析情况 0
智能大屏 0
如何添加单位客户 1
如何添加销售订单 1
添加销售订单有哪些注意 1
如何发起入库 1
如何申请出库单 1
入库单有哪些特点 1
总账的详细说明 1
怎么看当前的资金情况 1
看一下帮助中心 1
付款单的帮助 1
怎么进行收款计划 1
系统有哪些功能 1
销售人员有哪些操作 1
管理员应该做哪些预处理 1
去年各地区的销售情况 2
2020年销量最好的产品 2
目前有哪些进行中的合同 2
合同额最多的十个客户 2
下个月要到期的应付账款 2
今年的收款计划完成情况 2
2、预测用的脚本
predict.py
import paddle
from paddlenlp.transformers import ErnieForSequenceClassification, ErnieTokenizer
from paddlenlp import Taskflow
# 模型预测
cls = Taskflow("text_classification", task_path='../../checkpoint/exportnew', is_static_model=True)
# 加载模型
model = ErnieForSequenceClassification.from_pretrained('ernie-3.0-tiny-medium-v2-zh', num_classes=3) # NUM_CLASSES是你的分类任务中的类别数量
# 加载预训练模型参数
model.set_state_dict(paddle.load('/opt/dockerinstall/PaddleNLP/applications/text_classification/multi_class/deploy/simple_serving/ernie_3.0_text_classification_model.pdparams'))
# 将模型设置为评估模式
model.eval()
# 加载分词器
tokenizer = ErnieTokenizer.from_pretrained('ernie-3.0-tiny-medium-v2-zh')
# 待预测的文本
text = "去年各地区的销售情况"
# 使用分词器对文本进行编码
encoded_input = tokenizer(text, padding=True, truncation=True, return_tensors='pd', max_length=512) # max_length应匹配模型训练时的最大序列长度
# 获取预测结果
with paddle.no_grad():
logits = model(**encoded_input)
probs = paddle.nn.functional.softmax(logits, axis=-1) # 获取概率分布
predicted_class = paddle.argmax(probs, axis=-1).numpy()[0] # 获取概率最高的类别索引
# 假设你有一个标签到索引的映射
label_map = {0: '快捷功能', 1: '帮助手册', 2: '数据查询'} # 根据你的实际情况填写
# 获取预测的类别名称
predicted_label = label_map[predicted_class]
result = cls(text)
print(result)
print(probs[0].tolist())
print(f"预测结果为:{predicted_label}")3、提供在线向量计算和文本分类的脚本
main.py
import uvicorn
from fastapi import FastAPI,Request
from anyio.lowlevel import RunVar
from anyio import CapacityLimiter
import json
from typing import List
import paddle
from fastapi import FastAPI
from paddlenlp import Taskflow
from paddlenlp.transformers import ErnieForSequenceClassification, ErnieTokenizer, ErnieModel
import numpy as np
# 模型预测
#cls = Taskflow("text_classification", task_path='../../checkpoint/export', is_static_model=True)
paddle.seed(1234)
# 加载ERNIE 3.0模型和分词器
model_vector = ErnieModel.from_pretrained('ernie-3.0-tiny-medium-v2-zh')
model_vector.eval()
# 禁用模型的Dropout层(如果有的话)
for layer in model_vector.sublayers():
if isinstance(layer, paddle.nn.Dropout):
layer.train = False
model = ErnieForSequenceClassification.from_pretrained('ernie-3.0-tiny-medium-v2-zh', num_classes=3) # NUM_CLASSES是你的分类任务中的类别数量
# 加载预训练模型参数
model.set_state_dict(paddle.load('ernie_3.0_text_classification_model.pdparams'))
# 将模型设置为评估模式
model.eval()
# 加载分词器
tokenizer = ErnieTokenizer.from_pretrained('ernie-3.0-tiny-medium-v2-zh')
app = FastAPI()
@app.on_event("startup")
def startup():
print("start")
RunVar("_default_thread_limiter").set(CapacityLimiter(1))
@app.post("/")
async def encode(request: Request):
# 从请求体中获取并解析JSON数据
request_body = await request.body()
request_json = json.loads(request_body.decode("utf-8"))
#request_body = '{"data":[{"text": "智能大屏"}, {"text": "智能销售"}]}'
#request_json = json.loads(request_body)
texts = [item["text"] for item in request_json["data"]]
#print(texts)
# 使用分词器对文本进行编码
#encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pd', max_length=512) # max_length应匹配模型训练时的最大序列长度
# 获取预测结果
#with paddle.no_grad():
# logits = model(**encoded_input)
#print(logits)
# probs = paddle.nn.functional.softmax(logits, axis=-1) # 获取概率分布
#print(paddle.argmax(probs, axis=-1).numpy())
#print(paddle.argmax(probs, axis=-1).numpy()[0])
# predicted_class = paddle.argmax(probs, axis=-1).numpy()[0] # 获取概率最高的类别索引
# print(predicted_class.tolist())
#print(texts)
#print(list(texts))
#cls = Taskflow("text_classification", task_path='../../checkpoint/export', is_static_model=True)
# 加载ERNIE 3.0模型和分词器
#tokenizer = ErnieTokenizer.from_pretrained('ernie-3.0-tiny-medium-v2-zh')
#model = ErnieModel.from_pretrained('ernie-3.0-tiny-medium-v2-zh')
#textstr = ["幼儿挑食的生理原因是"]
#result = cls(texts)
#print(result)
# 使用分词器对文本进行编码
#encoded_input = tokenizer(text, padding=True, truncation=True, return_tensors='pd', max_length=512) # max_length应匹配模型训练时的最大序列长度
#encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pd', max_seq_len=512)
#print(encoded_input)
#input_ids = paddle.to_tensor(encoded_input['input_ids'], dtype='int64')
# 获取模型的隐藏状态输出
#with paddle.no_grad(): # 不计算梯度,加快计算速度
# outputs = model_vector(input_ids)
# last_hidden_state是模型的最后一个隐藏层的输出
#last_hidden_state = outputs[0]
# 假设我们取每个序列的最后一个隐藏状态作为句子的表示
sentence_embeddings = []
# 对每个句子进行循环处理
for text in texts:
# 对句子进行编码
encoded_input = tokenizer(text, padding=True, truncation=True, return_tensors='pd', max_length=512)
input_ids = paddle.to_tensor(encoded_input['input_ids'], dtype='int64')
# 获取模型的隐藏状态输出
with paddle.no_grad(): # 不计算梯度,加快计算速度
outputs = model_vector(input_ids)
# last_hidden_state是模型的最后一个隐藏层的输出
last_hidden_state = outputs[0]
# 假设我们取每个序列的最后一个隐藏状态作为句子的表示
sentence_embedding = last_hidden_state[0, -1, :]
sentence_embeddings.append(sentence_embedding.numpy())
#for i in range(len(texts)):
# 提取每个序列的最后一个隐藏状态
# sentence_embedding = last_hidden_state[i, -1, :]
# sentence_embeddings.append(sentence_embedding.numpy())
# 将每个NumPy数组转换为Python列表
sentence_embeddings_python_list = [embedding.tolist() for embedding in sentence_embeddings]
# 打印包含所有句子嵌入的Python列表
data_dict = {"vector": sentence_embeddings_python_list}
#with paddle.no_grad():
# search_vector = model_vector(**encoded_input)[1].numpy()
#with paddle.no_grad():
# paddle.seed(123456)
# outputs = model_vector(**encoded_input)
# 获取最后一层的词向量([CLS] token除外)
# token_embeddings = outputs.last_hidden_state[:, 1:] # 去除[CLS] token
# all_word_vectors = [vector.numpy().tolist() for vector in token_embeddings[0]]
#print(search_vector)
print("end vector")
# 获取预测结果
encoded_input = tokenizer(text, padding=True, truncation=True, return_tensors='pd', max_length=512) # max_length应匹配模型训练时的最大序列长度
with paddle.no_grad():
logits = model(**encoded_input)
#print(logits)
#print("first")
#print(logits[0])
#print("two")
#print(logits[1])
probs = paddle.nn.functional.softmax(logits, axis=-1) # 获取概率分布
#probs = paddle.nn.functional.softmax(logits, axis=-1) # 获取概率分布
#print("this")
#print(probs)
#print("Shape of probs:", probs.shape)
#print("Type of probs:", type(probs))
#print(paddle.argmax(probs, axis=-1))
print("this one")
print(paddle.argmax(probs, axis=-1).numpy()[0])
print("this two")
#predicted_class = paddle.argmax(probs, axis=-1)
predicted_class = paddle.argmax(probs, axis=-1).numpy() # 获取概率最高的类别索引
#print("this three " + predicted_class)
return {"vector": sentence_embeddings_python_list, "predictedList":predicted_class.tolist()}
#return {"predictionList": result, "vector": search_vector.tolist(), "predictedList": predicted_class.tolist()}
#return {"vector": search_vector.tolist(), "predictedList": predicted_class.tolist()}
#return {"vector": json.dumps(data_dict), "predictedList": predicted_class.tolist(), "all_word_vectors": all_word_vectors}
#return {"predictedList": predicted_class.tolist()}















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









