







【机器学习04】-【逻辑回归】(Logistic Regression)
逻辑回归(Logistic Regression)是一种广泛应用于分类问题的统计学习方法,尤其适用于二分类(如判断肿瘤是恶性还是良性)。尽管名字中有“回归”,但它实际上是一种分类算法,其核心思想是利用Sigmoid函数(Logistic函数)将线性回归的输出映射到概率区间(0,1),从而进行分类决策。
1. 逻辑回归的核心思想
逻辑回归的目标是建立一个模型,预测某个样本属于某一类别的概率。其关键步骤包括:
- 线性组合:计算输入特征的加权和(类似线性回归)。
- Sigmoid变换:将线性输出映射到(0,1)区间,表示概率。
- 决策阈值:设定一个阈值(如0.5或0.7),将概率转换为类别标签。
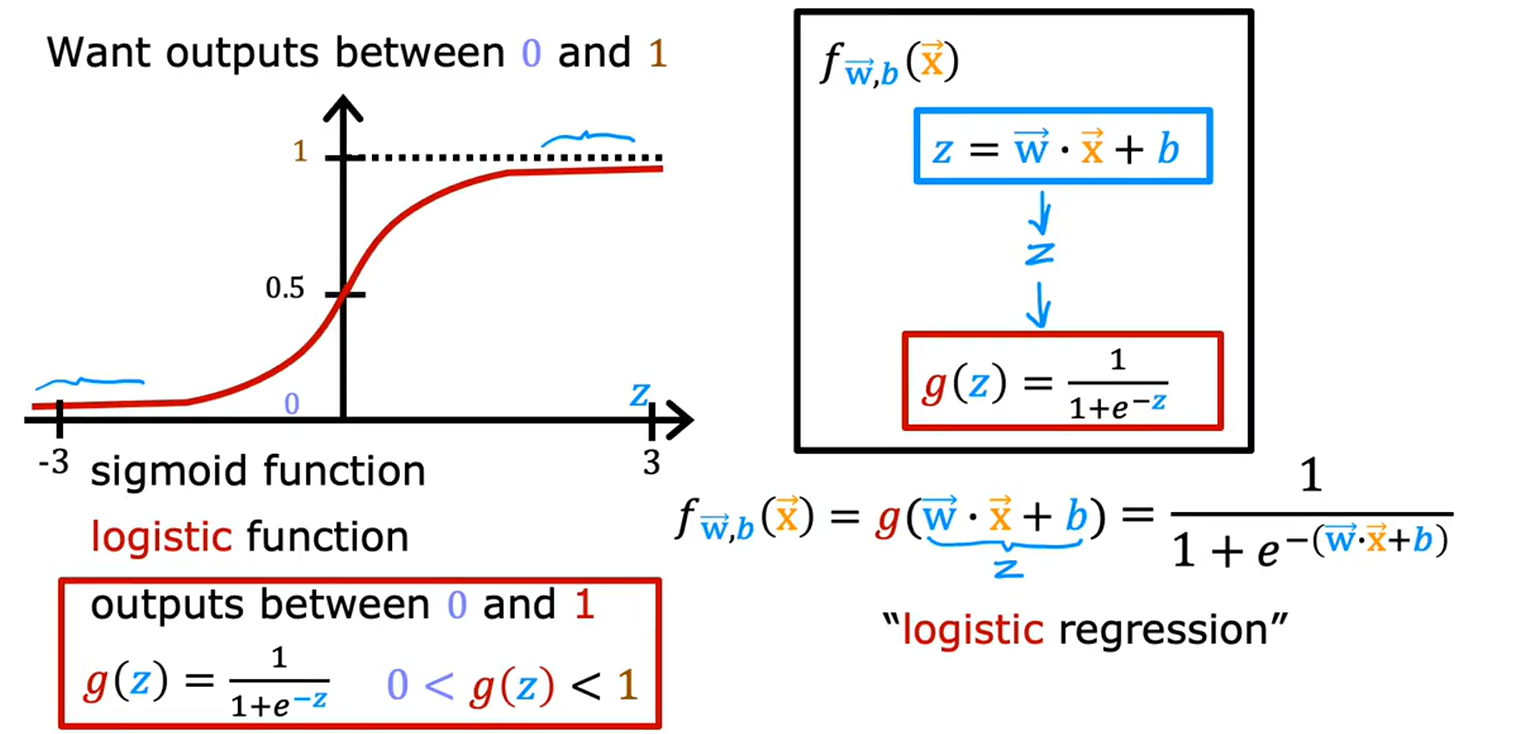
2. Sigmoid函数(Logistic函数)
Sigmoid函数是逻辑回归的核心,其公式为:
g ( z ) = 1 1 + e − z g(z) = \frac{1}{1 + e^{-z}} g(z)=1+e−z1
其中:
•
z
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
⋯
+
θ
n
x
n
z = \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \dots + \theta_n x_n
z=θ0+θ1x1+θ2x2+⋯+θnxn(线性回归的输出)
•
g
(
z
)
g(z)
g(z) 表示样本属于正类(如“恶性”)的概率
P
(
y
=
1
∣
x
)
P(y=1 | x)
P(y=1∣x)
逻辑回归模型:
f
w
,
b
(
x
)
=
1
1
+
e
−
(
w
⋅
x
+
b
)
f_{\mathbf{w}, b}(\mathbf{x}) = \frac{1}{1 + e^{-(\mathbf{w} \cdot \mathbf{x} + b)}}
fw,b(x)=1+e−(w⋅x+b)1
概率解释:
P
(
y
=
1
∣
x
)
=
f
w
,
b
(
x
)
,
P
(
y
=
0
∣
x
)
=
1
−
f
w
,
b
(
x
)
P(y=1 \mid \mathbf{x}) = f_{\mathbf{w}, b}(\mathbf{x}), \quad P(y=0 \mid \mathbf{x}) = 1 - f_{\mathbf{w}, b}(\mathbf{x})
P(y=1∣x)=fw,b(x),P(y=0∣x)=1−fw,b(x)
示例:
- 输入:肿瘤大小
x
x
x,输出
f
w
,
b
(
x
)
=
0.7
f_{\mathbf{w}, b}(x) = 0.7
fw,b(x)=0.7
→ 70%概率为恶性。
Sigmoid函数的特性:
• 输出范围在 (0,1) 之间,适合表示概率。
• 当 z = 0 z = 0 z=0, g ( z ) = 0.5 g(z) = 0.5 g(z)=0.5(决策边界)。
• 当 z → + ∞ z \to +\infty z→+∞, g ( z ) → 1 g(z) \to 1 g(z)→1(预测为正类)。
• 当 z → − ∞ z \to -\infty z→−∞, g ( z ) → 0 g(z) \to 0 g(z)→0(预测为负类)。
3. 逻辑回归的决策规则
给定一个样本 x x x,逻辑回归的预测过程如下:
- 计算 z = θ T x z = \theta^T x z=θTx(线性组合)。
- 计算概率 P ( y = 1 ∣ x ) = g ( z ) P(y=1 | x) = g(z) P(y=1∣x)=g(z)。
- 设定阈值(如0.5):
• 若 P ( y = 1 ∣ x ) ≥ 0.5 P(y=1 | x) \geq 0.5 P(y=1∣x)≥0.5,预测 ( y = 1 )(正类)。
• 若 P ( y = 1 ∣ x ) < 0.5 P(y=1 | x) < 0.5 P(y=1∣x)<0.5,预测 ( y = 0 )(负类)。
4. 逻辑回归的损失函数(Log Loss)
逻辑回归使用**对数损失(Log Loss)**作为优化目标,其公式为:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) log ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J(\theta) = -\frac{1}{m} \sum_{i=1}^m \left[ y^{(i)} \log(h_\theta(x^{(i)})) + (1 - y^{(i)}) \log(1 - h_\theta(x^{(i)})) \right] J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
其中:
•
h
θ
(
x
)
h_\theta(x)
hθ(x) 是预测概率
P
(
y
=
1
∣
x
)
P(y=1 | x)
P(y=1∣x)。
•
y
(
i
)
y^{(i)}
y(i) 是真实标签(0或1)。
•
m
m
m 是样本数量。
优化方法:
• 通常使用**梯度下降(Gradient Descent)**最小化损失函数。
• 也可以使用牛顿法(Newton-Raphson)或拟牛顿法(如L-BFGS)。
5. 逻辑回归 vs. 线性回归
| 特性 | 逻辑回归 | 线性回归 |
|---|---|---|
| 输出 | 概率(0~1) | 连续值((-\infty, +\infty)) |
| 函数 | Sigmoid | 线性 |
| 应用 | 分类 | 回归 |
| 损失函数 | 对数损失(Log Loss) | 均方误差(MSE) |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









