







【注意力机制2-2】-深入理解 注意力机制 的 Q、K、V 机制
深入理解 注意力机制 的 Q、K、V 机制
Transformer 是现代自然语言处理(NLP)和计算机视觉(CV)任务中的核心架构,而其自注意力(Self-Attention)机制是 Transformer 成功的关键。本文将重点解析 Q(Query)、K(Key)、V(Value)三个矩阵的作用及其计算方法。
1. 注意力机制 机制概述
注意力机制 通过自注意力机制来捕捉序列中不同位置的相关性,从而有效建模长期依赖关系。其核心计算包括:
- 输入序列的嵌入(Embedding)
- 通过多头注意力(Multi-Head Attention)提取特征
- 通过前馈神经网络(Feed Forward Network, FFN)进行非线性变换
- 采用层归一化(Layer Normalization)和残差连接(Residual Connection)来优化训练效果
其中,自注意力机制的关键在于计算 Q、K、V 矩阵。
2. Q、K、V 矩阵的定义
在自注意力机制中,每个输入向量(Token)都会映射成三个向量:
- Query(查询向量)Q:用于提出问题,表示当前 Token 需要关注的内容。
- Key(键向量)K:用于匹配 Query,决定哪些 Token 需要被关注。
- Value(值向量)V:存储实际的信息,最终用于生成新的表示。
在实际计算中,输入矩阵 (X)(由所有 Token 组成)通过三组可训练的权重矩阵
W
Q
,
W
K
,
W
V
W_Q, W_K, W_V
WQ,WK,WV 进行线性变换得到:
Q
=
X
W
Q
,
K
=
X
W
K
,
V
=
X
W
V
Q = XW_Q, \quad K = XW_K, \quad V = XW_V
Q=XWQ,K=XWK,V=XWV
其中,
X
X
X 维度为
(
n
,
d
)
(n, d)
(n,d),
W
Q
,
W
K
,
W
V
W_Q, W_K, W_V
WQ,WK,WV 维度为
(
d
,
d
k
)
(d, d_k)
(d,dk),得到的 Q、K、V 维度均为
(
n
,
d
k
)
(n, d_k)
(n,dk),其中
n
n
n 是 Token 数量,
d
d
d 是输入嵌入维度,
d
k
d_k
dk 是注意力计算的维度。
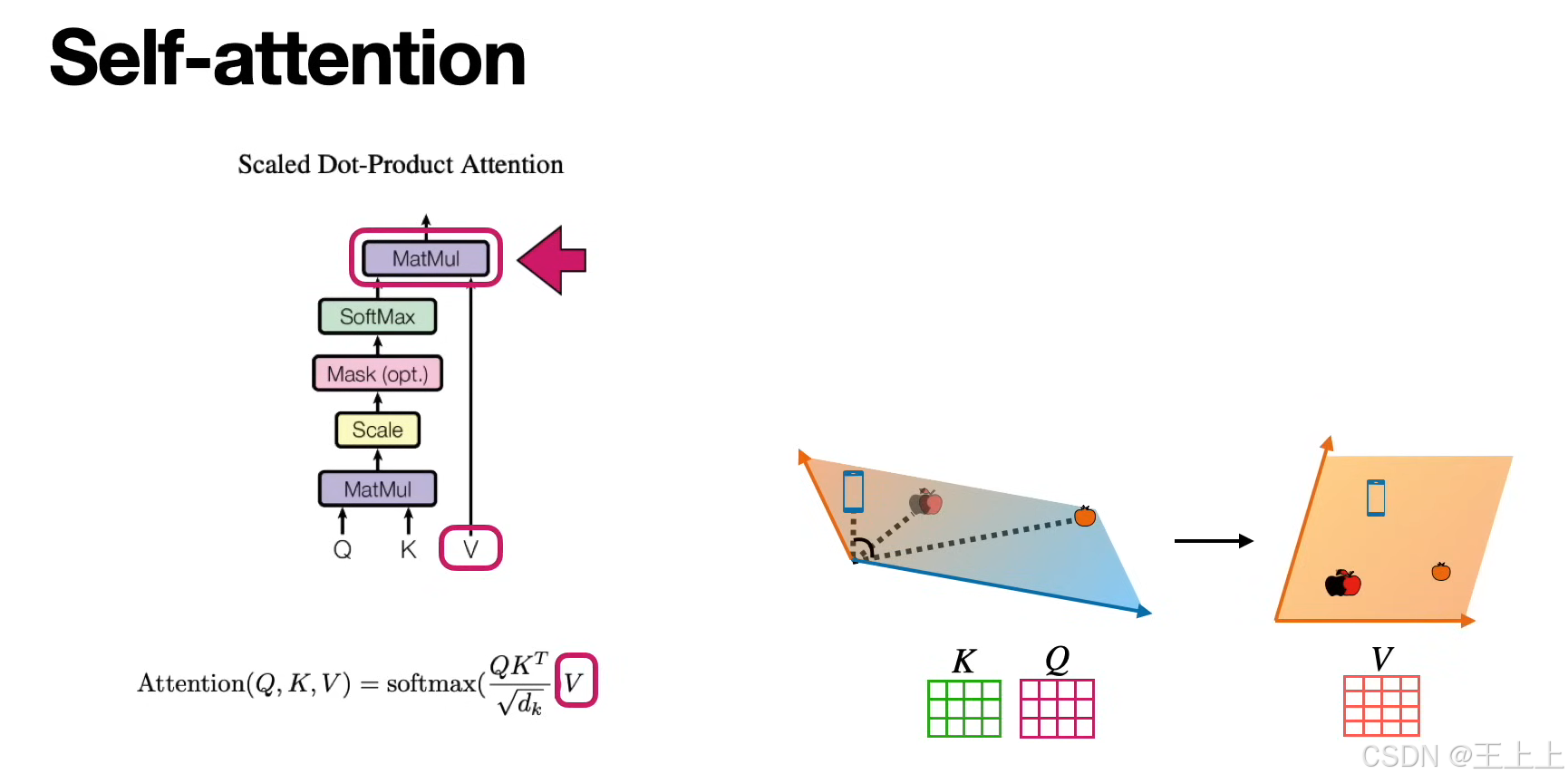
3. 自注意力计算过程
计算 Q、K、V 之后,注意力分数由 Q 和 K 计算得到:
Attention Scores
=
Q
K
T
d
k
\text{Attention Scores} = \frac{QK^T}{\sqrt{d_k}}
Attention Scores=dkQKT
其中,( \frac{1}{\sqrt{d_k}} ) 是缩放因子,避免大数值影响梯度稳定性。
然后,对注意力分数应用 Softmax 得到注意力权重:
α
=
Softmax
(
Attention Scores
)
\alpha = \text{Softmax}(\text{Attention Scores})
α=Softmax(Attention Scores)
接着,这些权重用于加权求和 V:
Output
=
α
V
\text{Output} = \alpha V
Output=αV
最终,输出结果包含了对所有输入 Token 的加权信息。
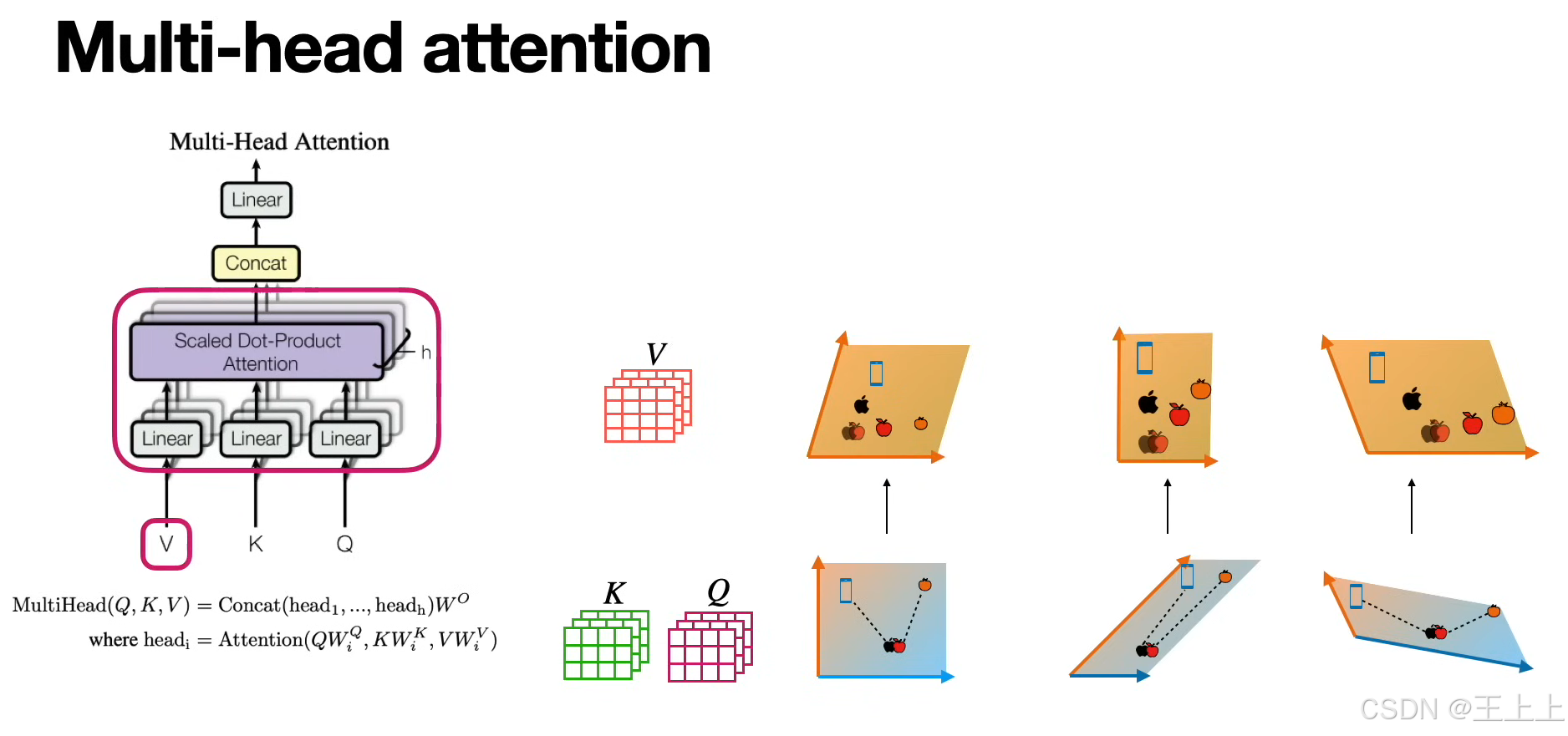
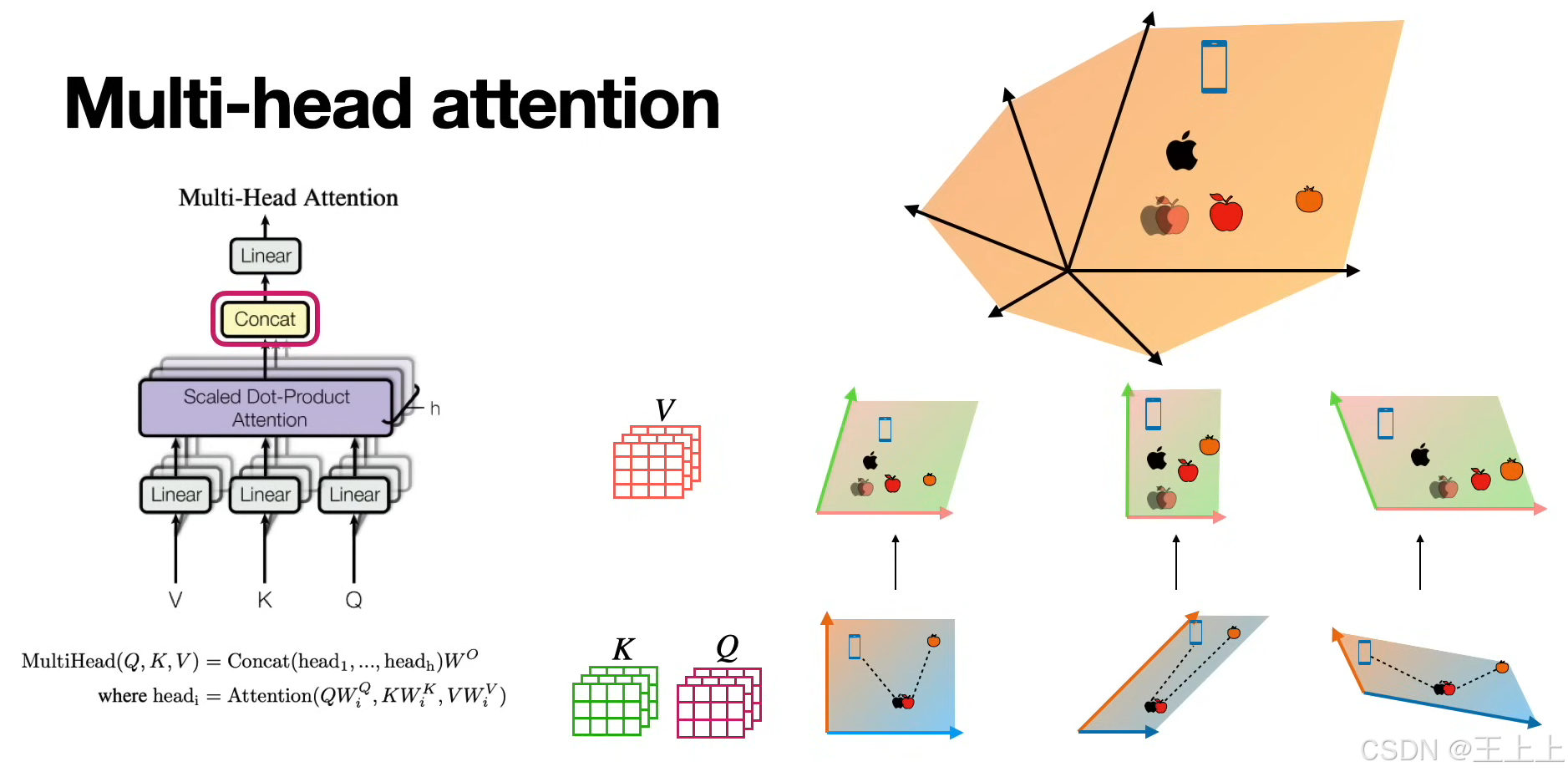
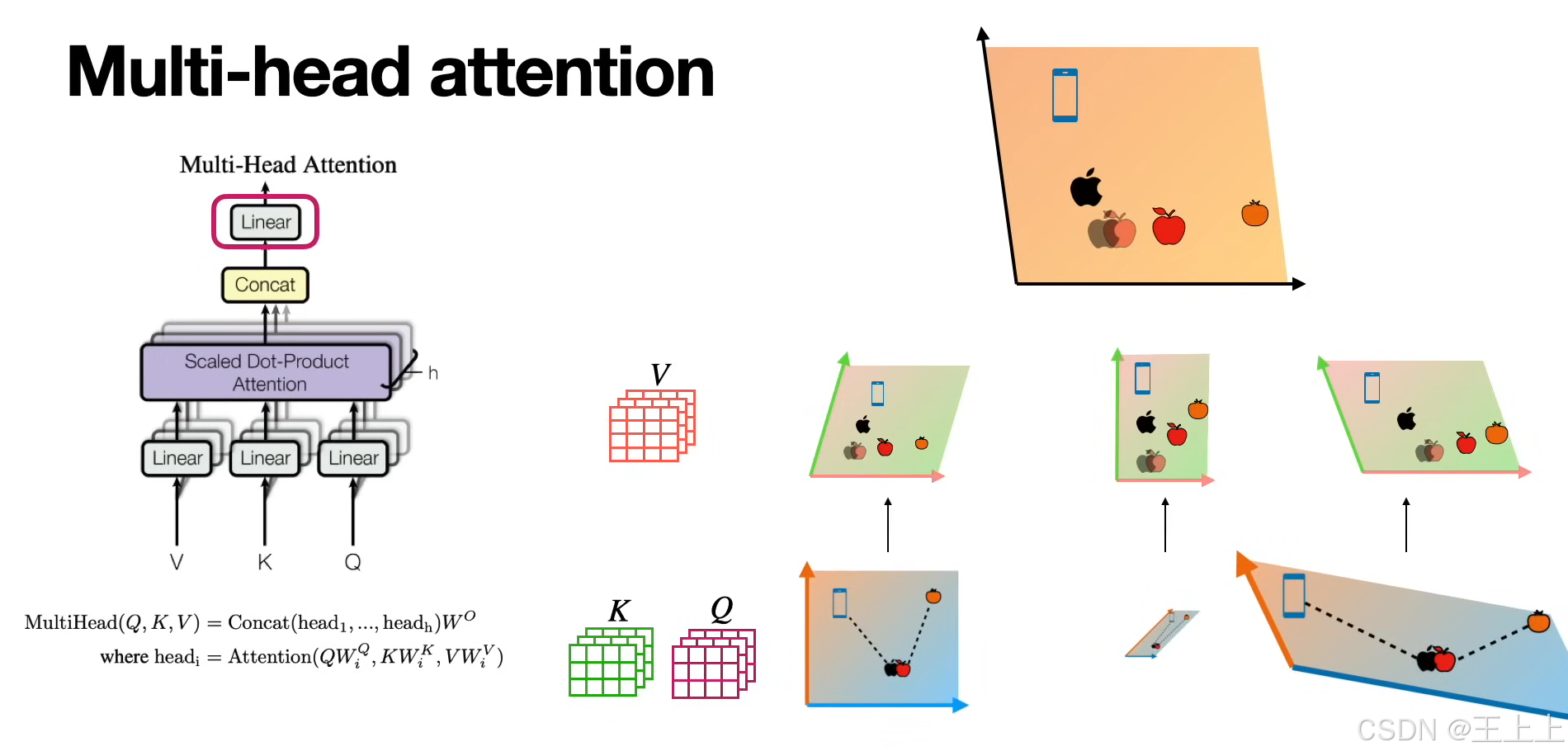
4. 多头注意力机制(Multi-Head Attention)
单个注意力头可能不足以捕捉复杂的模式,因此 Transformer 采用多头注意力:
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
head
1
,
…
,
head
h
)
W
O
\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h) W_O
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
其中,每个注意力头独立计算一组 (Q, K, V),然后拼接结果并通过 ( W_O ) 进行映射。
5. 总结
Q、K、V 是 注意力机制 的核心概念:
- Q 用于查询,K 用于匹配,V 作为最终的信息来源。
- Q 和 K 计算注意力权重,权重再作用于 V 得到最终输出。
- 多头注意力可以增强模型对不同特征的关注能力。
理解这些机制,有助于更深入掌握 Transformer 及其变体(如 BERT、GPT)在不同任务中的应用。
1. 相似度度量方法
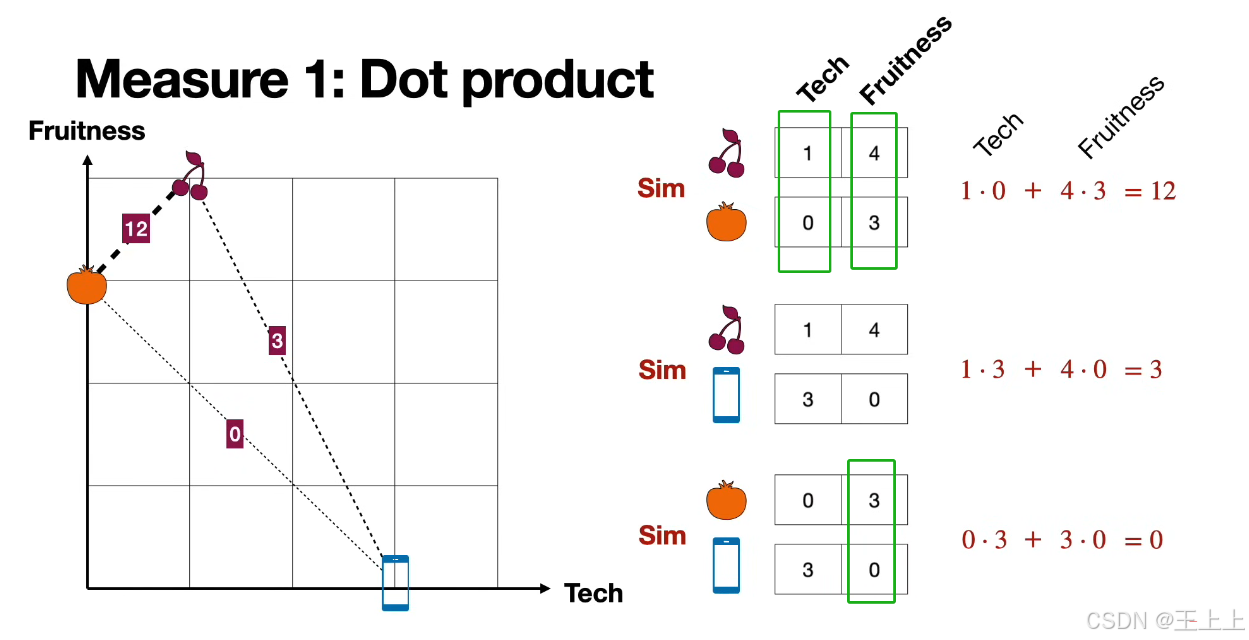
(1)点积(Dot Product)
• 核心公式:A·B = Σ(A_i × B_i)
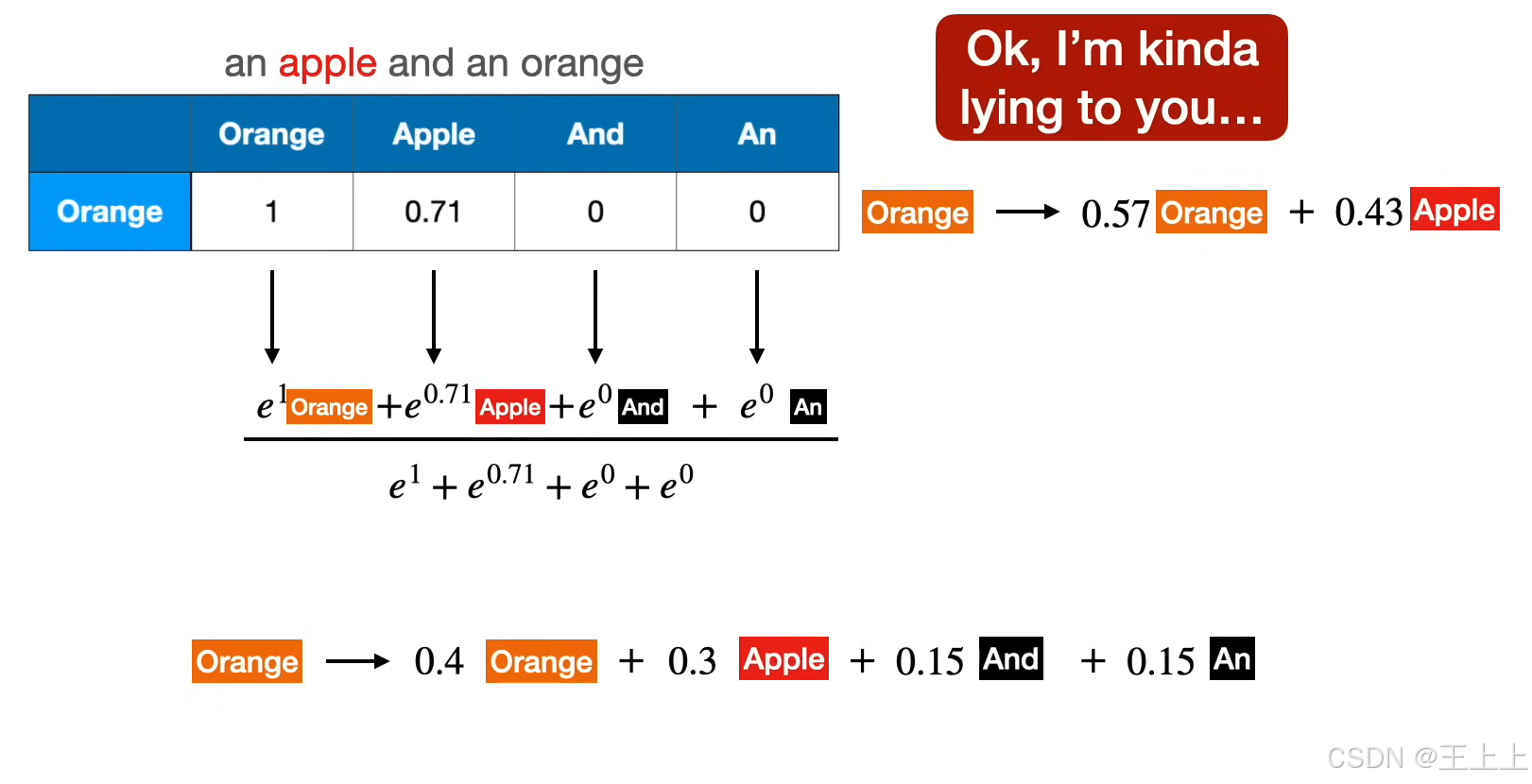
• 图片示例(图2/5):
• [1,4]·[0,3] = 1×0 + 4×3 = 12
• 局限性:受向量长度影响,需标准化处理(图5引入缩放点积)。
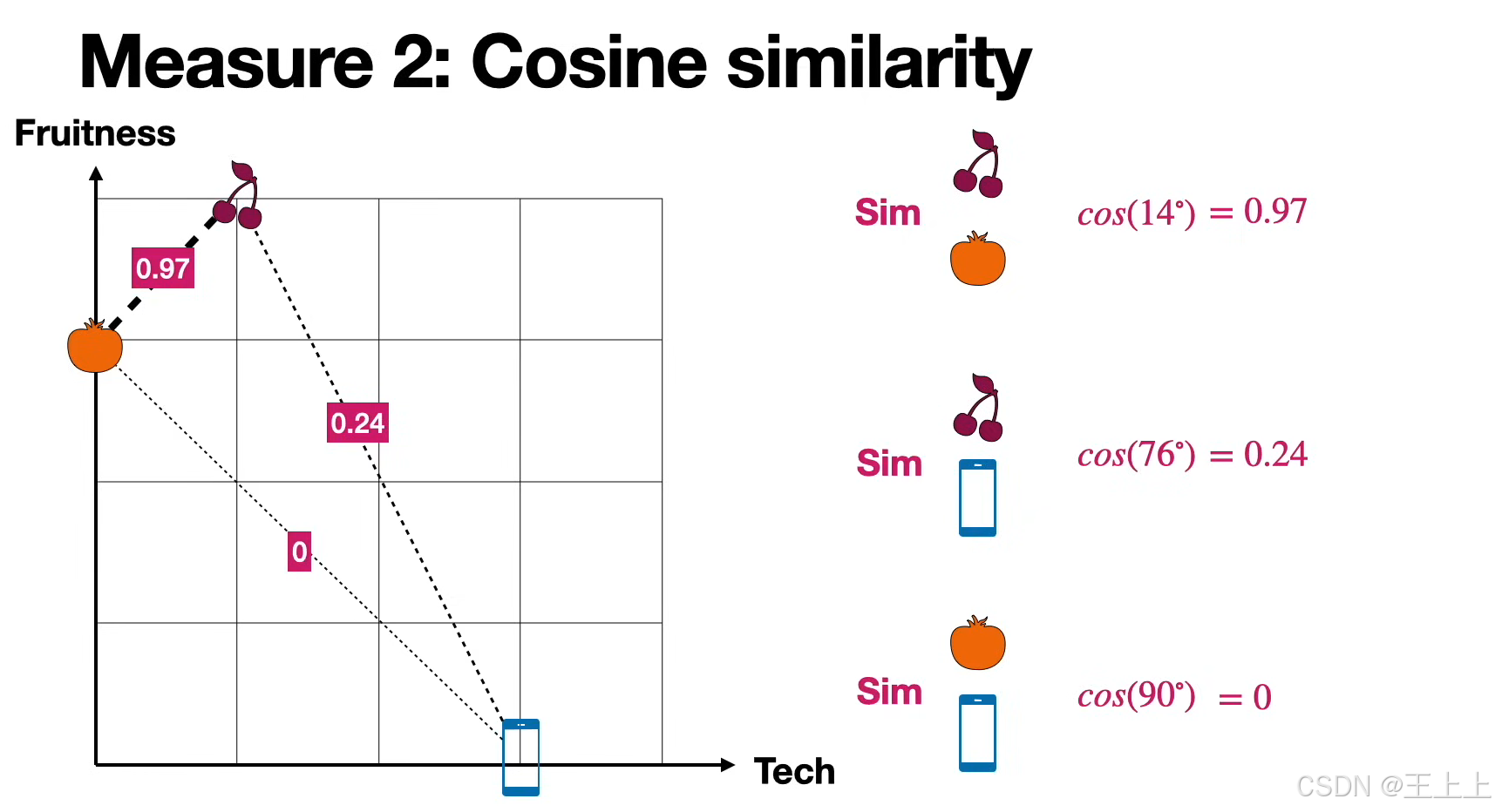
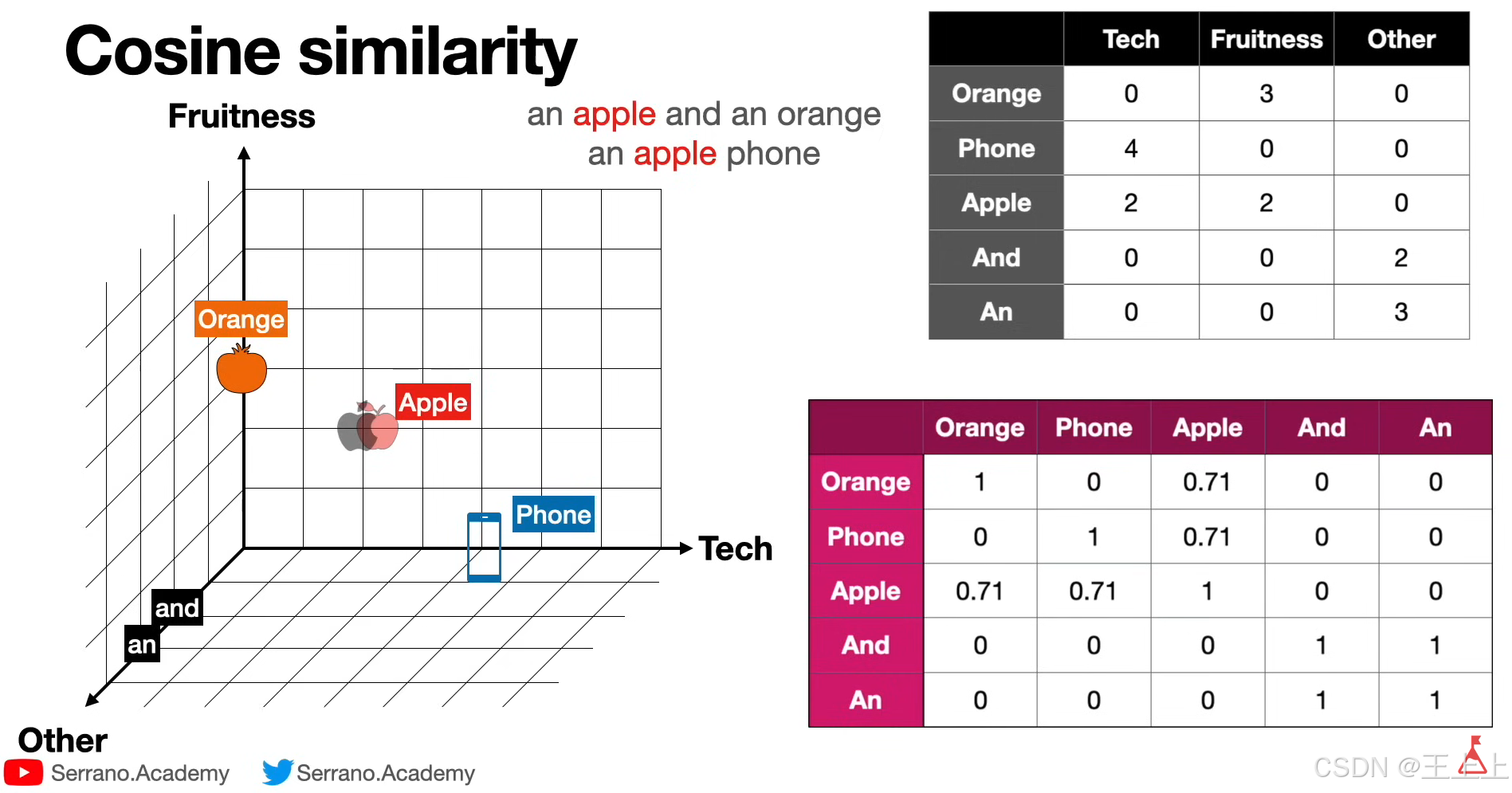
(2)余弦相似度(Cosine Similarity)
• 核心公式:cosθ = (A·B) / (||A|| × ||B||)
• 关键结论(图3/4/6):
• 角度越小(接近0°),相似度越高(cos0°=1);
• 正交向量(90°)相似度为0。
• 应用示例(图6):橙子与苹果相似度为0.71(因向量方向接近)。
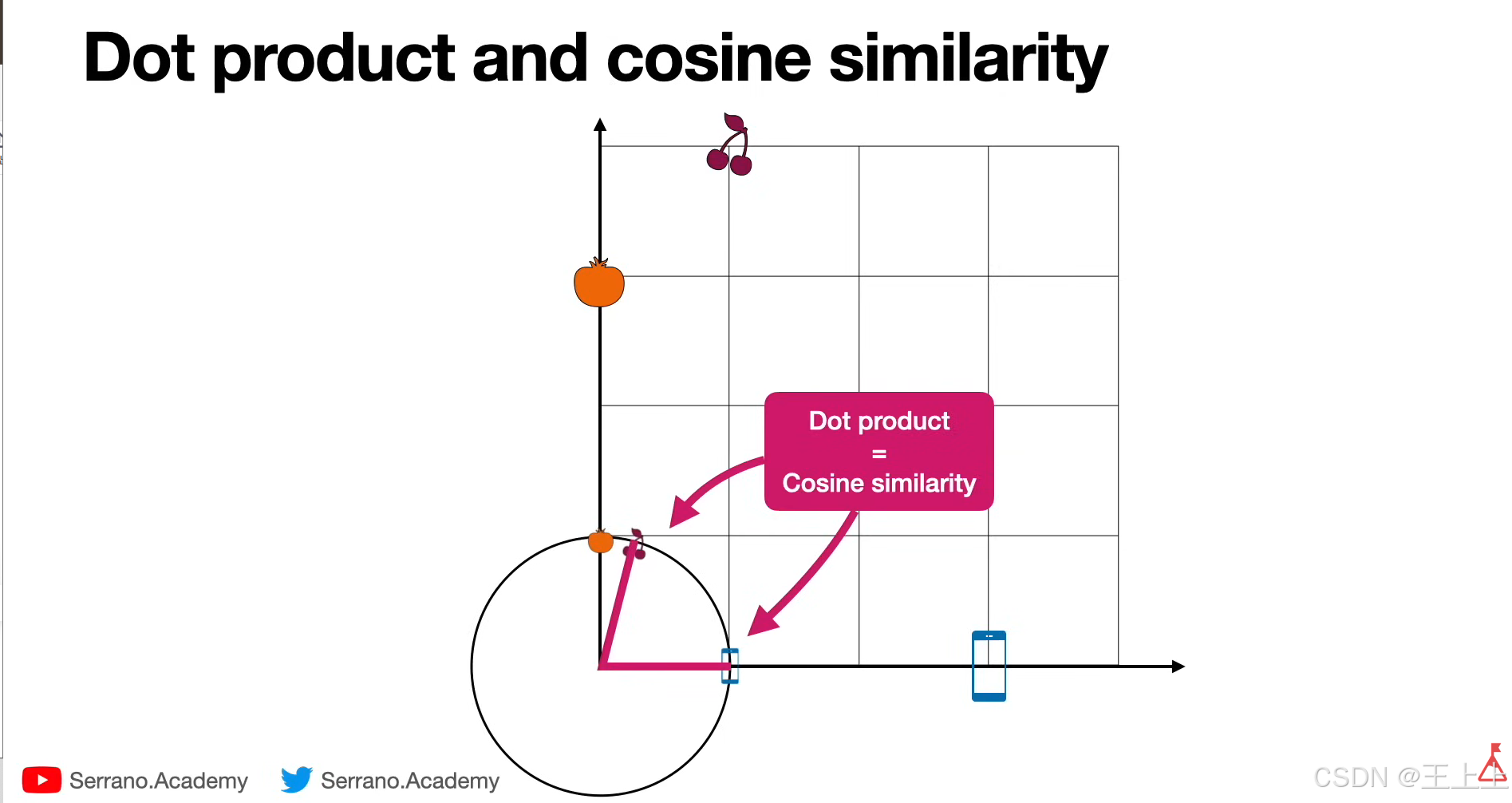
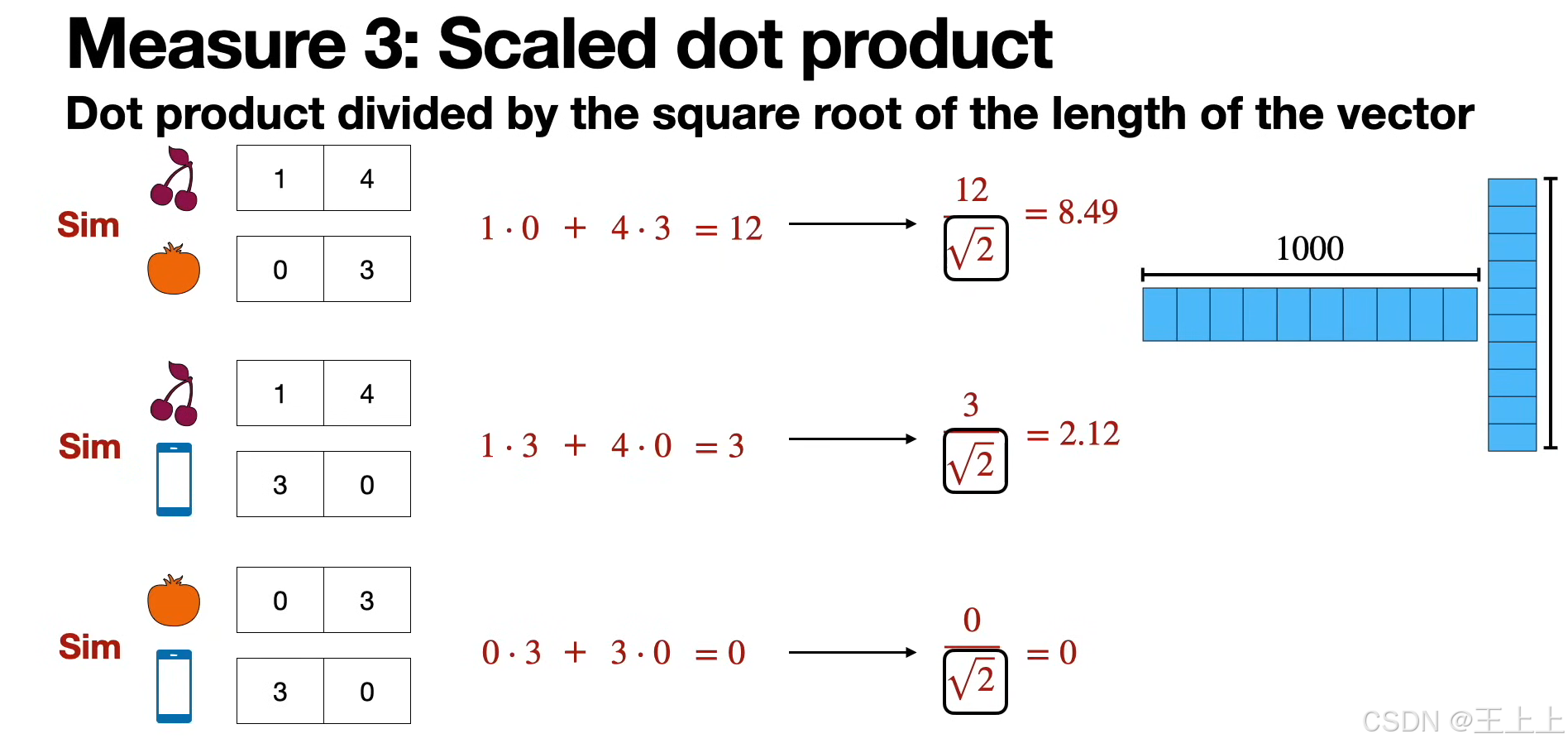
(3)缩放点积(Scaled Dot Product)
• 改进点积:除以向量长度的平方根(图5),解决长度偏差问题。
• 示例:12 / √(1²+4²) ≈ 8.49
计算过程
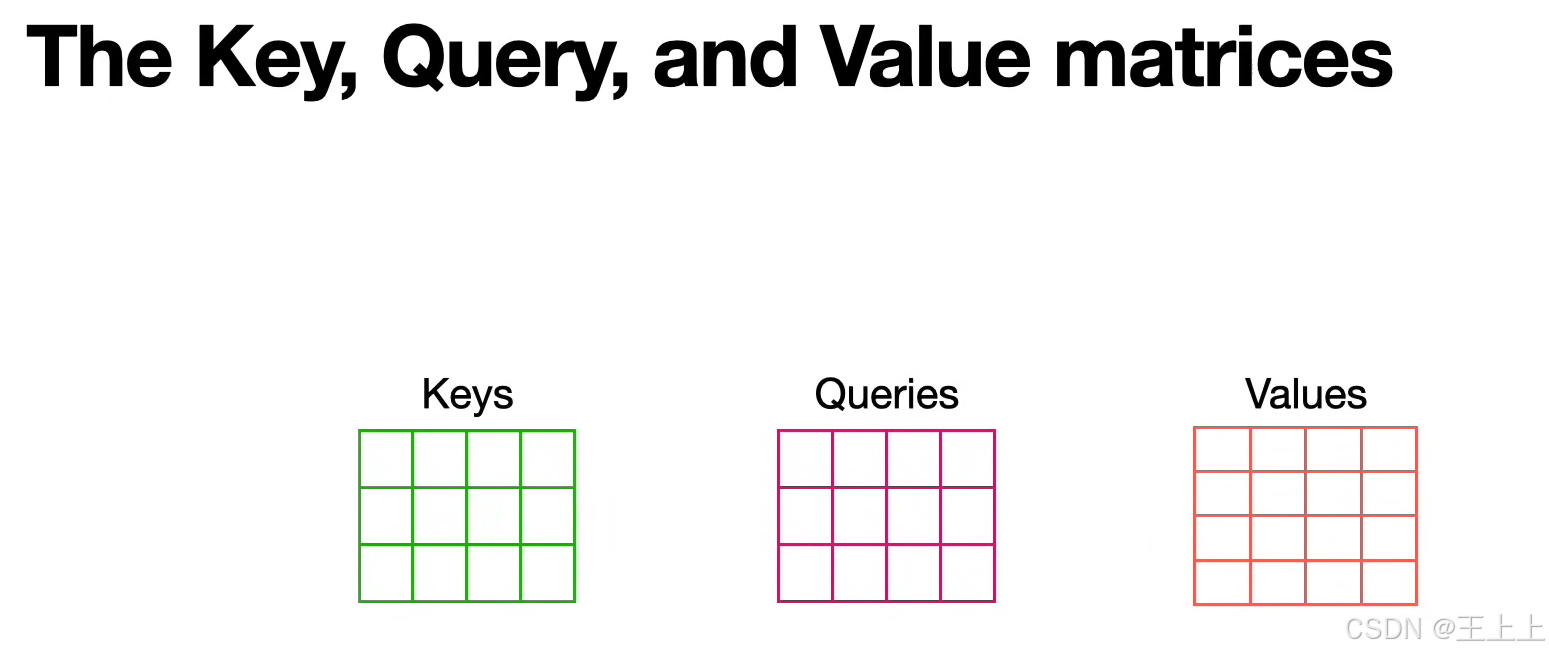
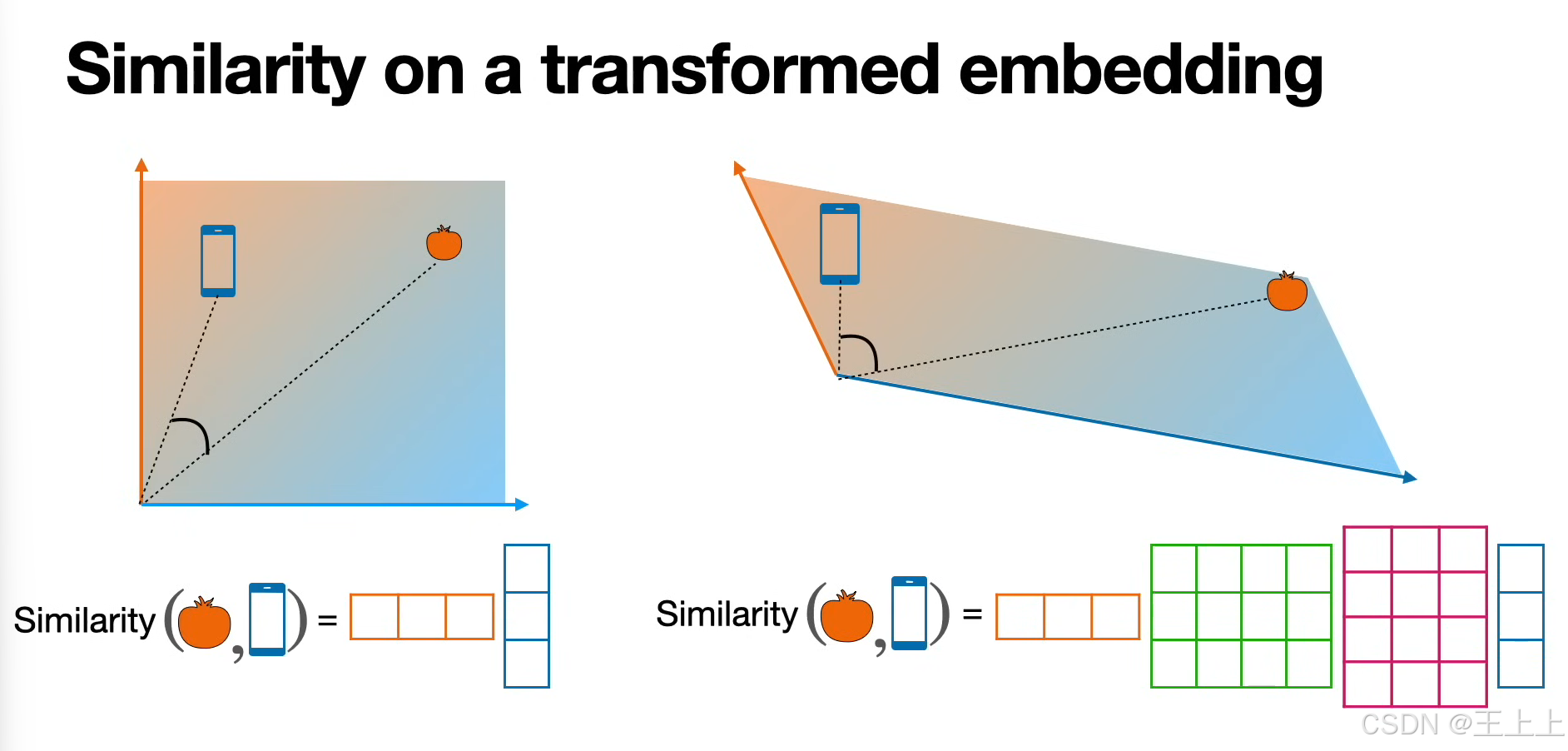
系统性地展示了注意力机制(Attention Mechanism)中Key-Query-Value(KQV)模型的核心概念和计算流程。以下是关键知识点的总结与解析:
1. KQV矩阵的核心作用
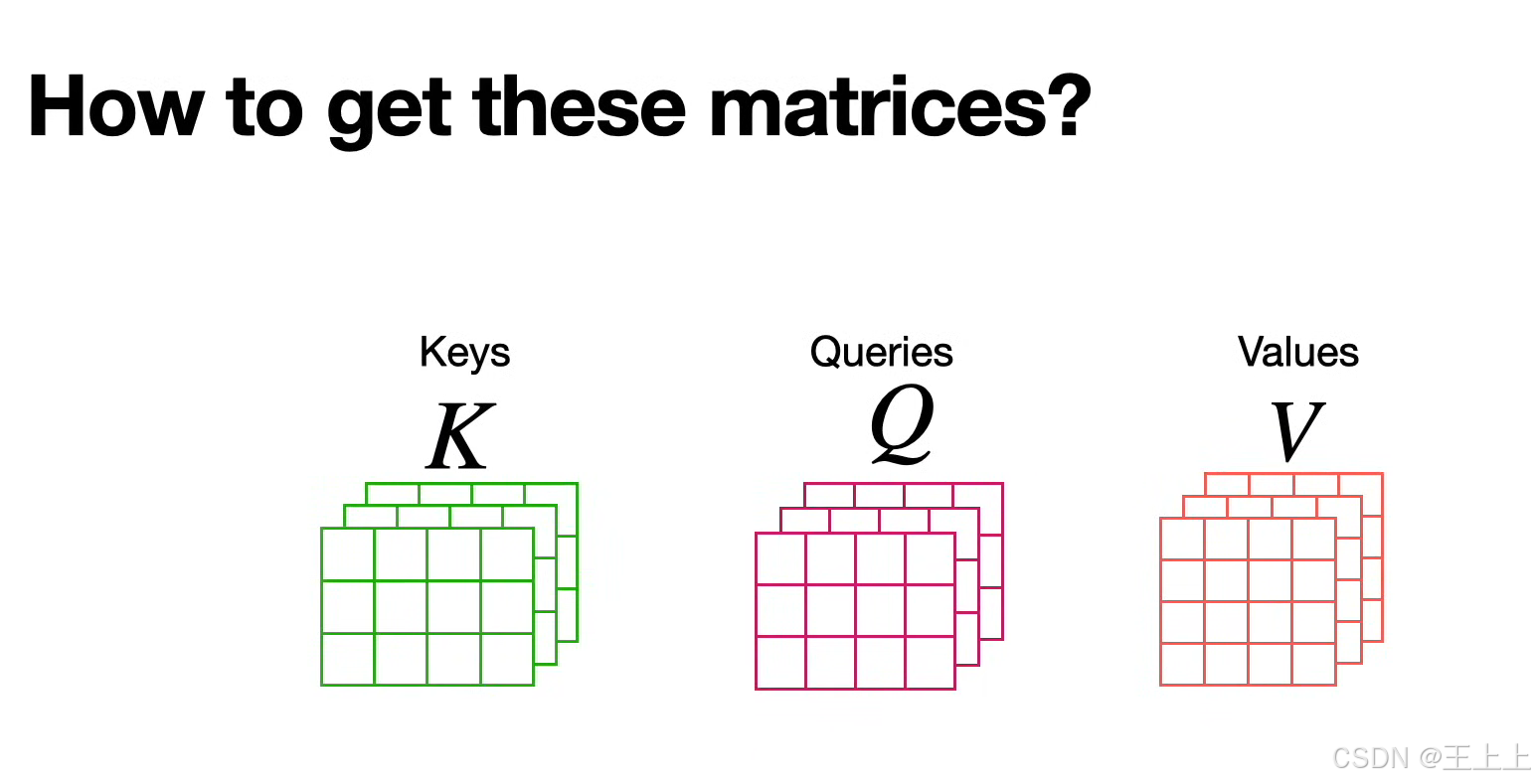
(1)三矩阵定义(图1/图6)
• Keys矩阵(绿色):存储待匹配的特征(如单词的语义属性)。
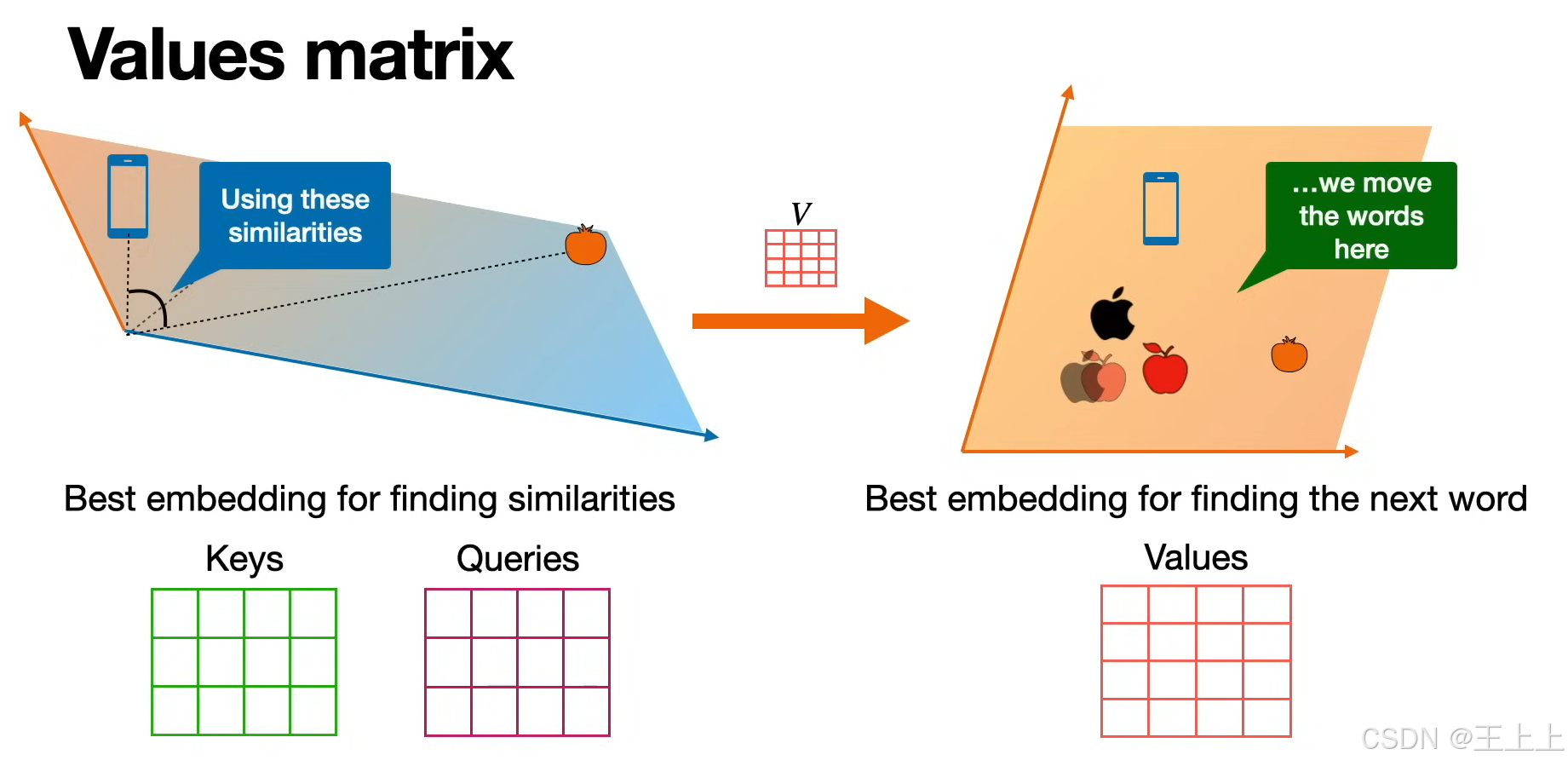
• Queries矩阵(粉色):表示当前需要查询的特征(如输入的问题或上下文)。
• Values矩阵(粉色):存储实际输出的信息(如预测的下一个单词)。
(2)核心思想(图4/图7)
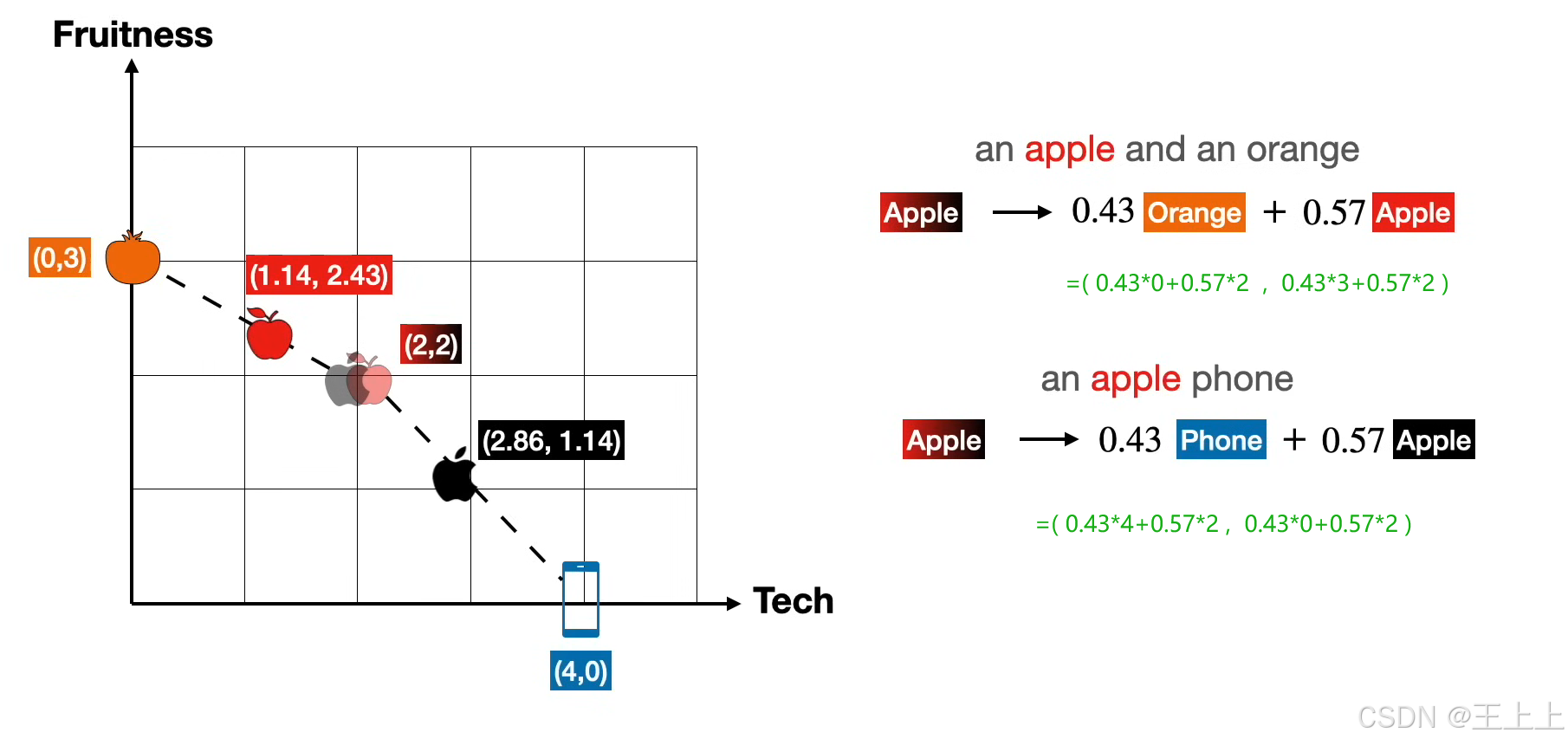
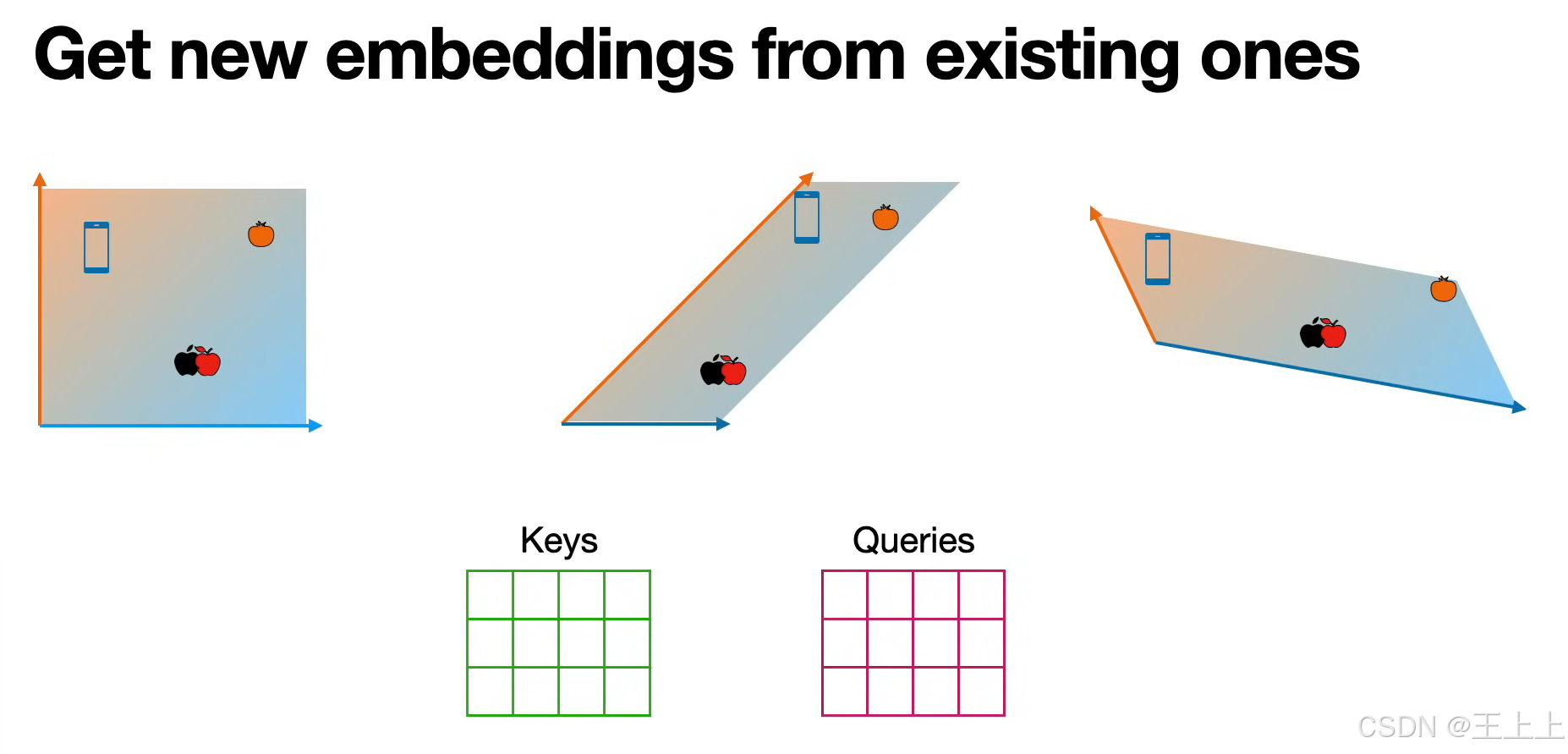
通过计算Query与Key的相似度,加权聚合Value矩阵中的信息,生成新的嵌入表示。
• 图4:线性变换(W^K, W^Q, W^V)将原始嵌入投影到KQV空间。
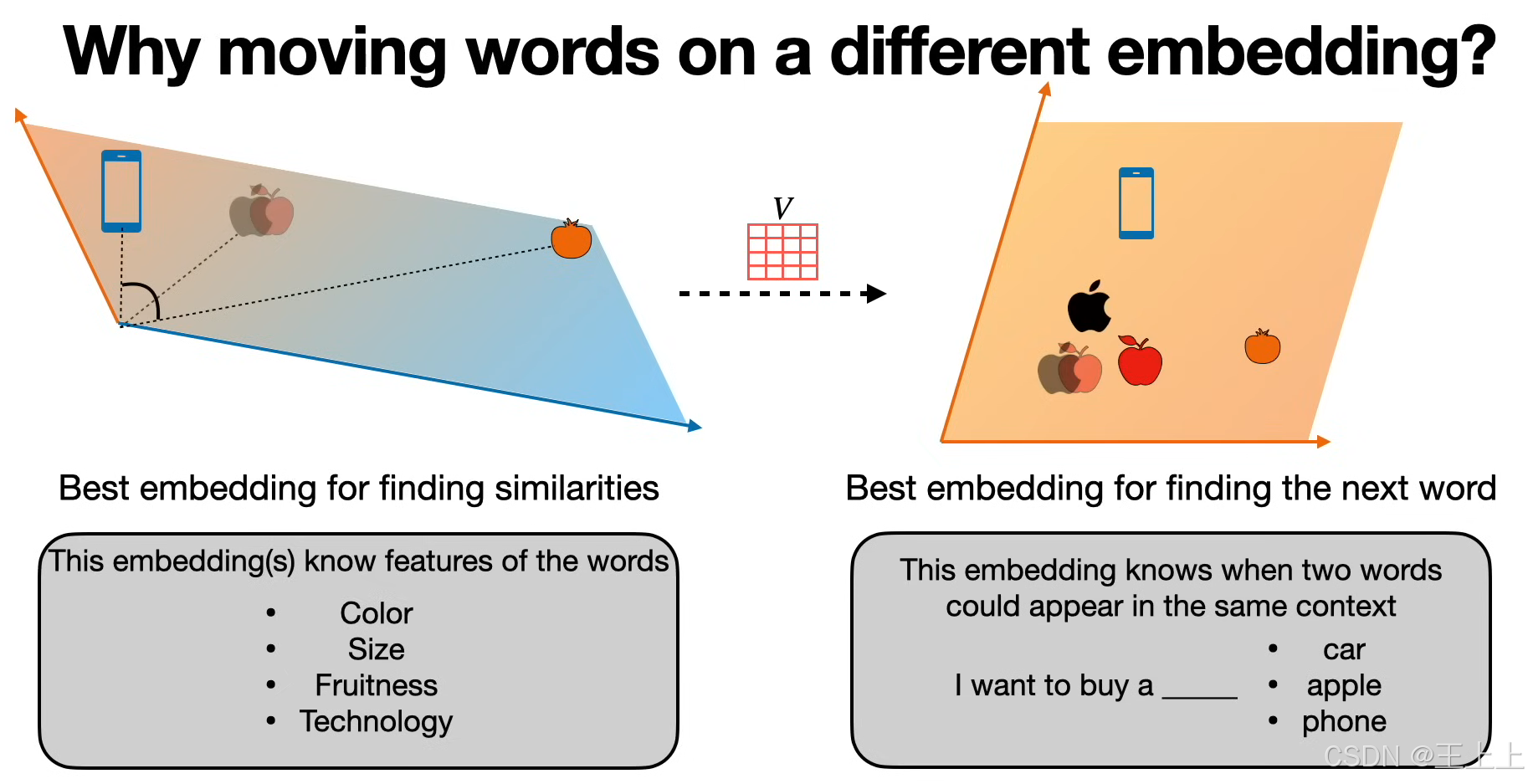
• 图7:不同嵌入空间分工明确:
• 相似性空间:理解单词属性(如颜色、技术属性);
• 上下文预测空间:学习单词共现概率(如“买苹果” vs “买手机”)。
2. 相似度计算与权重分配
(1)相似度计算(图5)
• 缩放点积相似度:Similarity = (Q·K^T) / √d_k(d_k为Key维度)
• 图5中通过变换嵌入空间(如降维344%)优化相似度分布。
(2)权重分配(图3/图8)
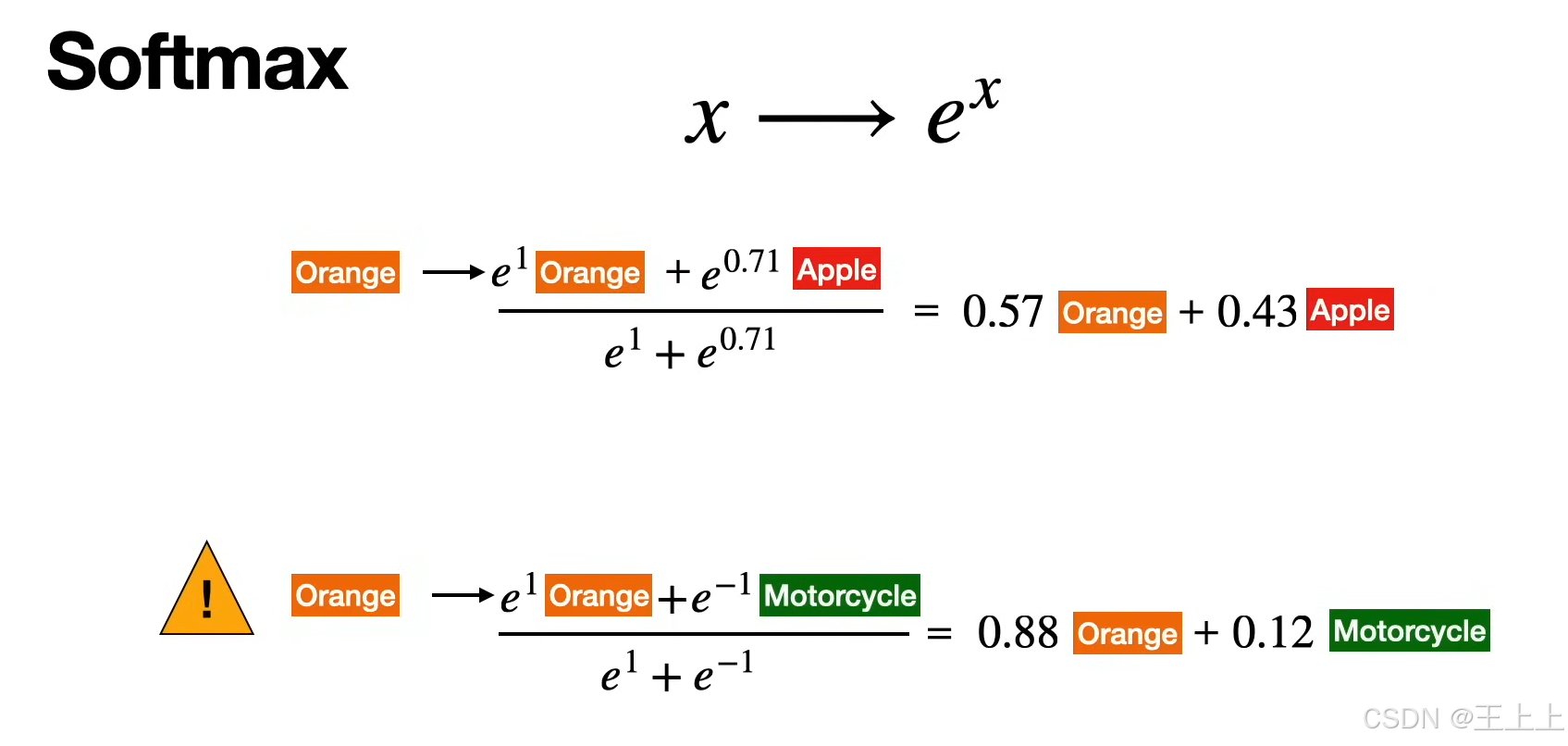
• Good vs Bad示例(图3):
• Good:相似度高的Query-Key对获得显著权重(如苹果与橙子在“水果”特征上匹配);
• Bad:无关特征(如手机与橙子)相似度趋近0。
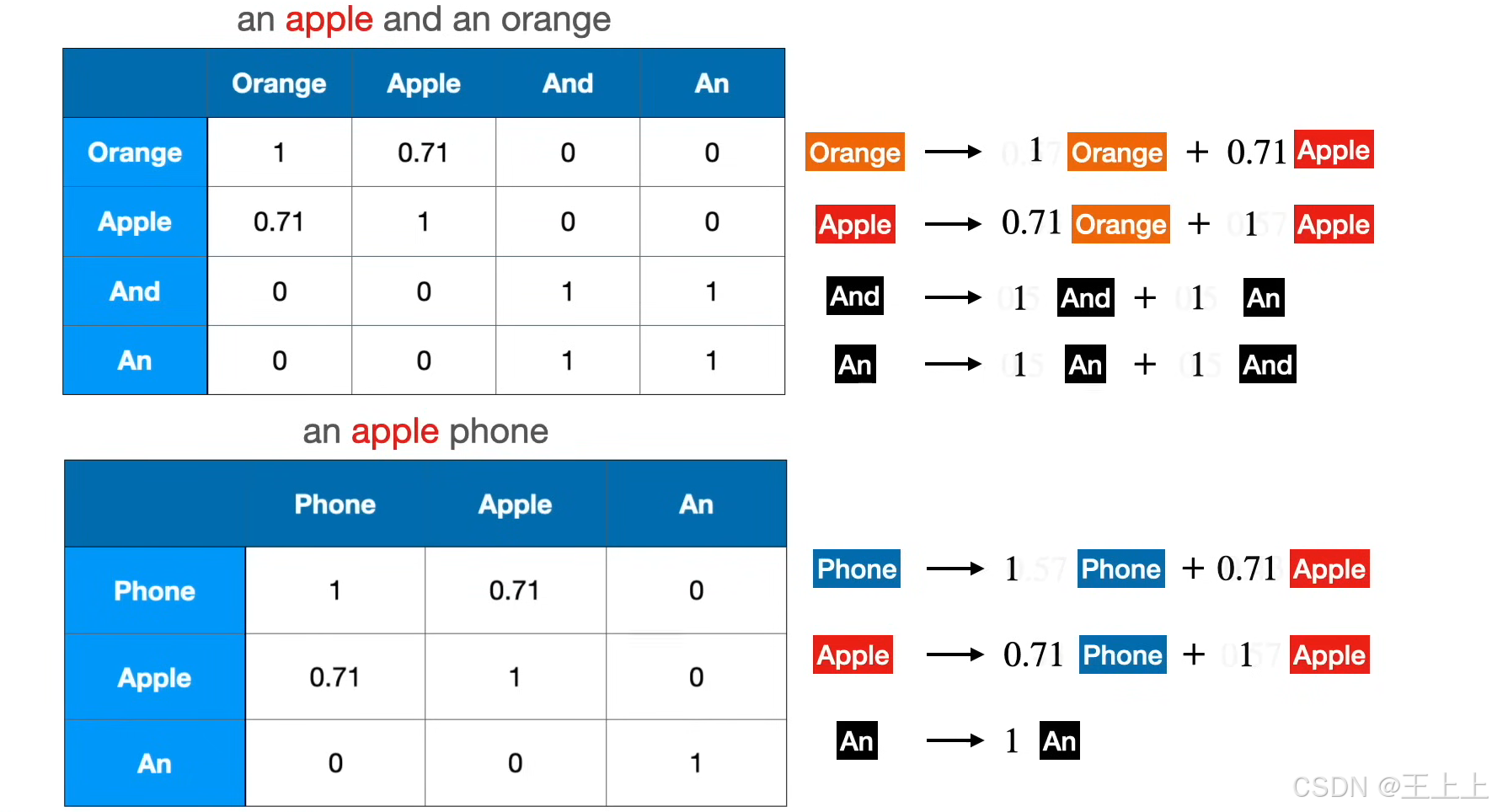
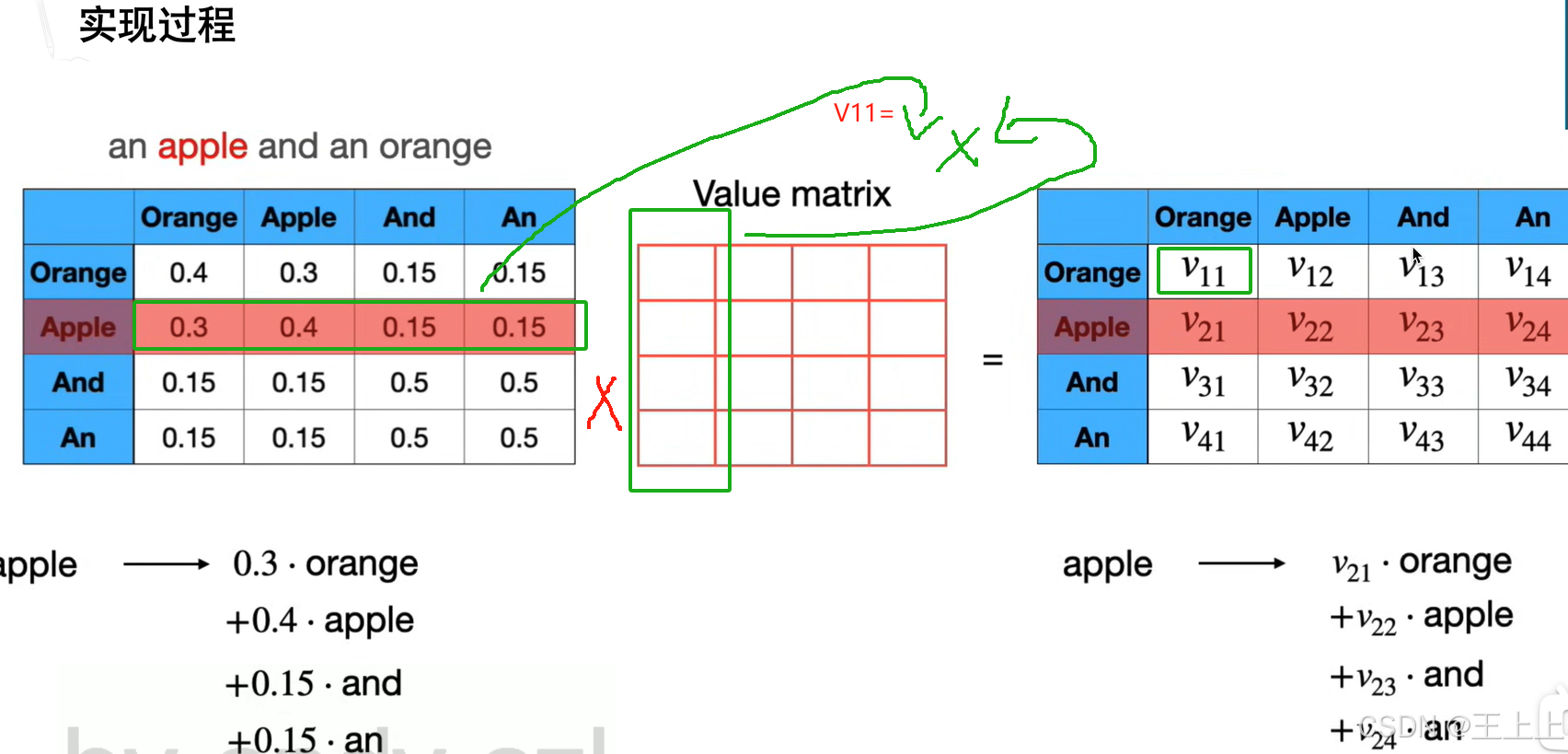
• Value矩阵加权(图8):
• 示例:apple = 0.3·orange + 0.4·apple + 0.15·and + 0.15·an
• 权重来自Query-Key相似度,Value矩阵提供实际输出值。
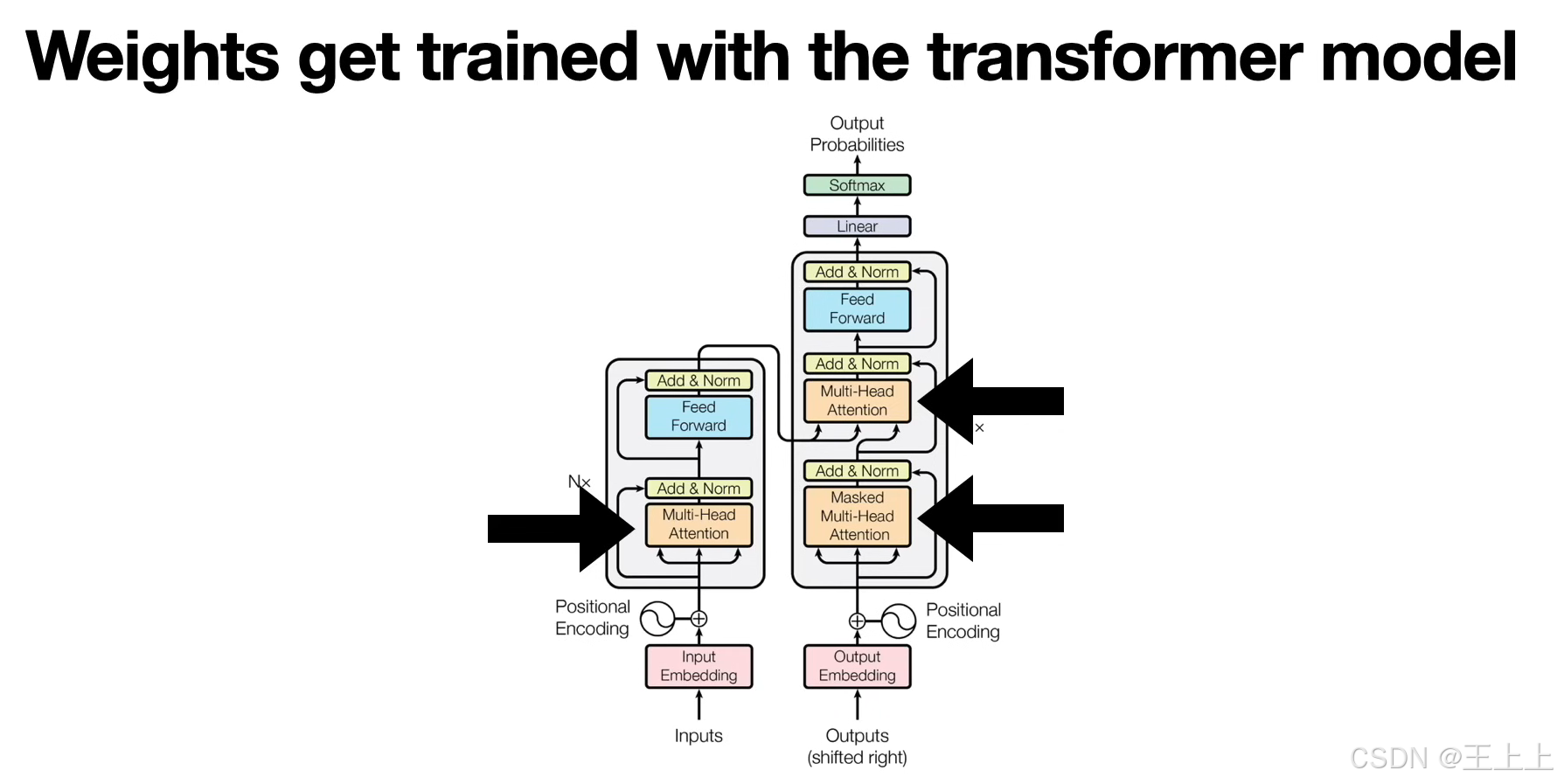
3. 完整注意力流程(图6)
- 输入嵌入 → 通过线性变换生成K/Q/V矩阵。
- 计算注意力分数:
Attention(Q,K,V) = softmax(QK^T/√d_k)·V
• 图6中箭头表示从相似度计算到Value聚合的流程。 - 输出新嵌入:加权后的Value矩阵作为上下文感知的表示。
4. 关键应用场景
• 语义相似性(图2/图4):通过KQV匹配相近语义(如“苹果”与“橙子”)。
• 序列预测(图7):预测下一个单词(如“I want to buy a [apple/phone]”)。
• 动态权重分配(图8):根据任务需求调整不同特征的贡献(如技术属性 vs 颜色)。
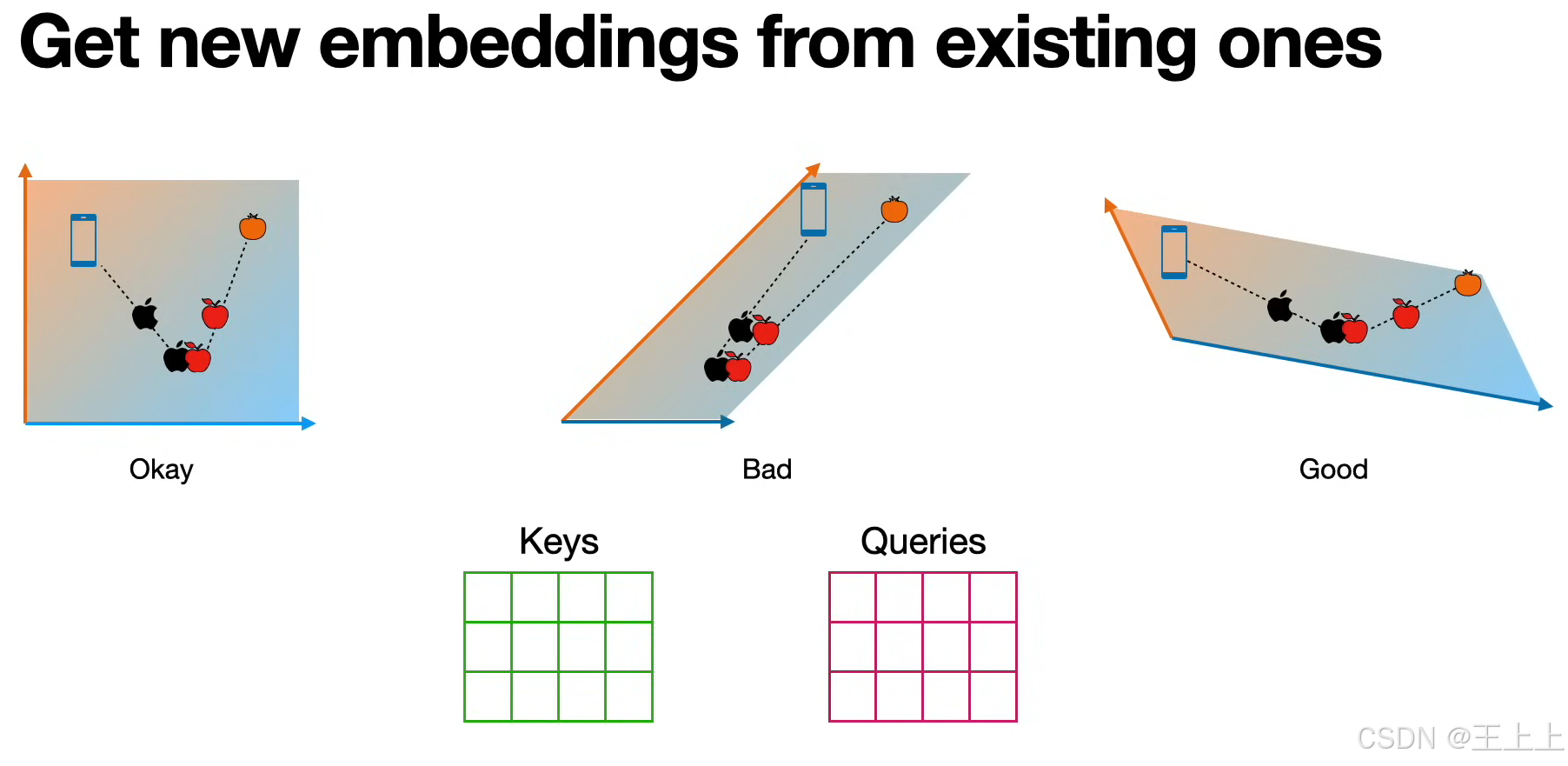
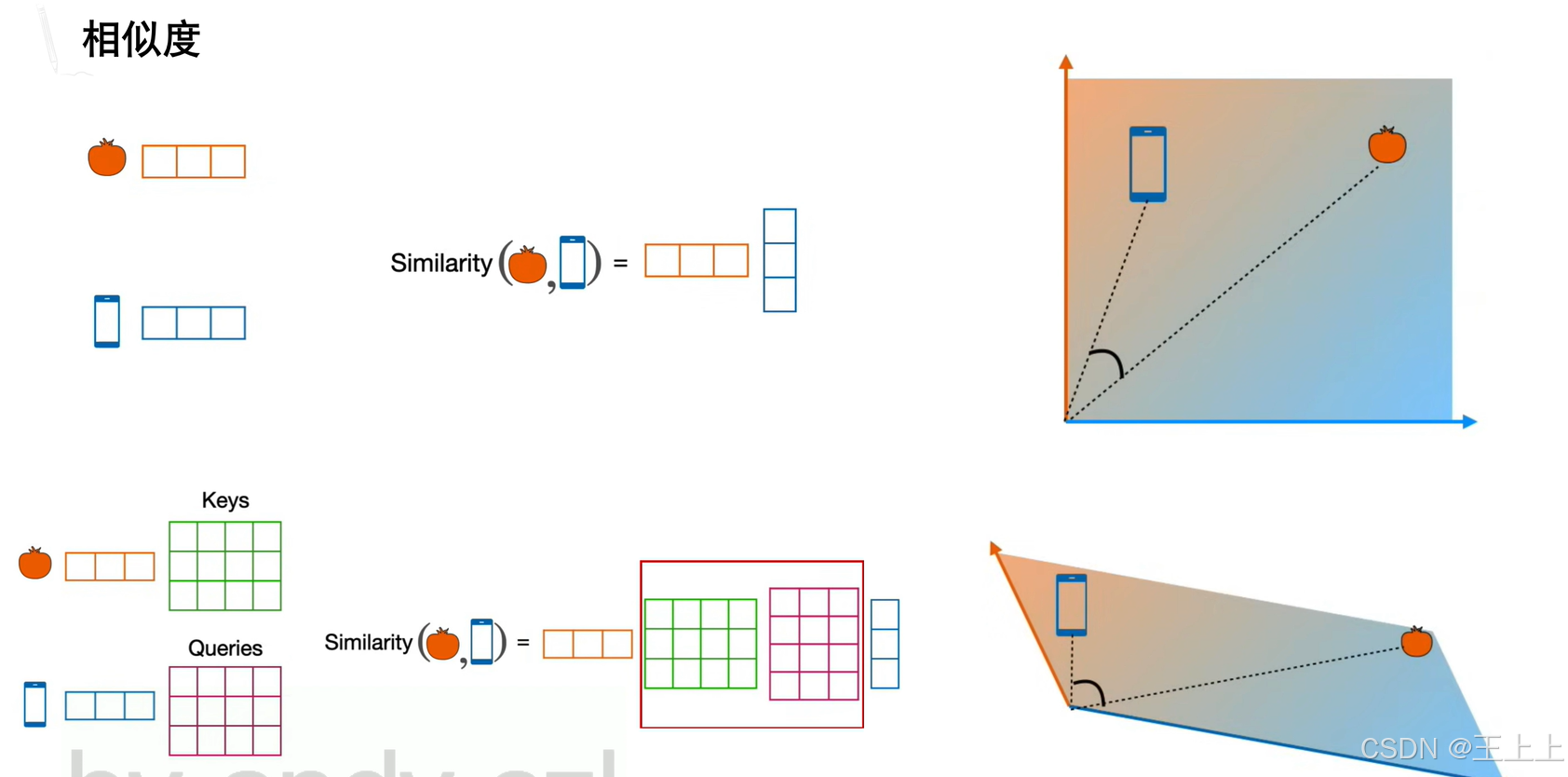
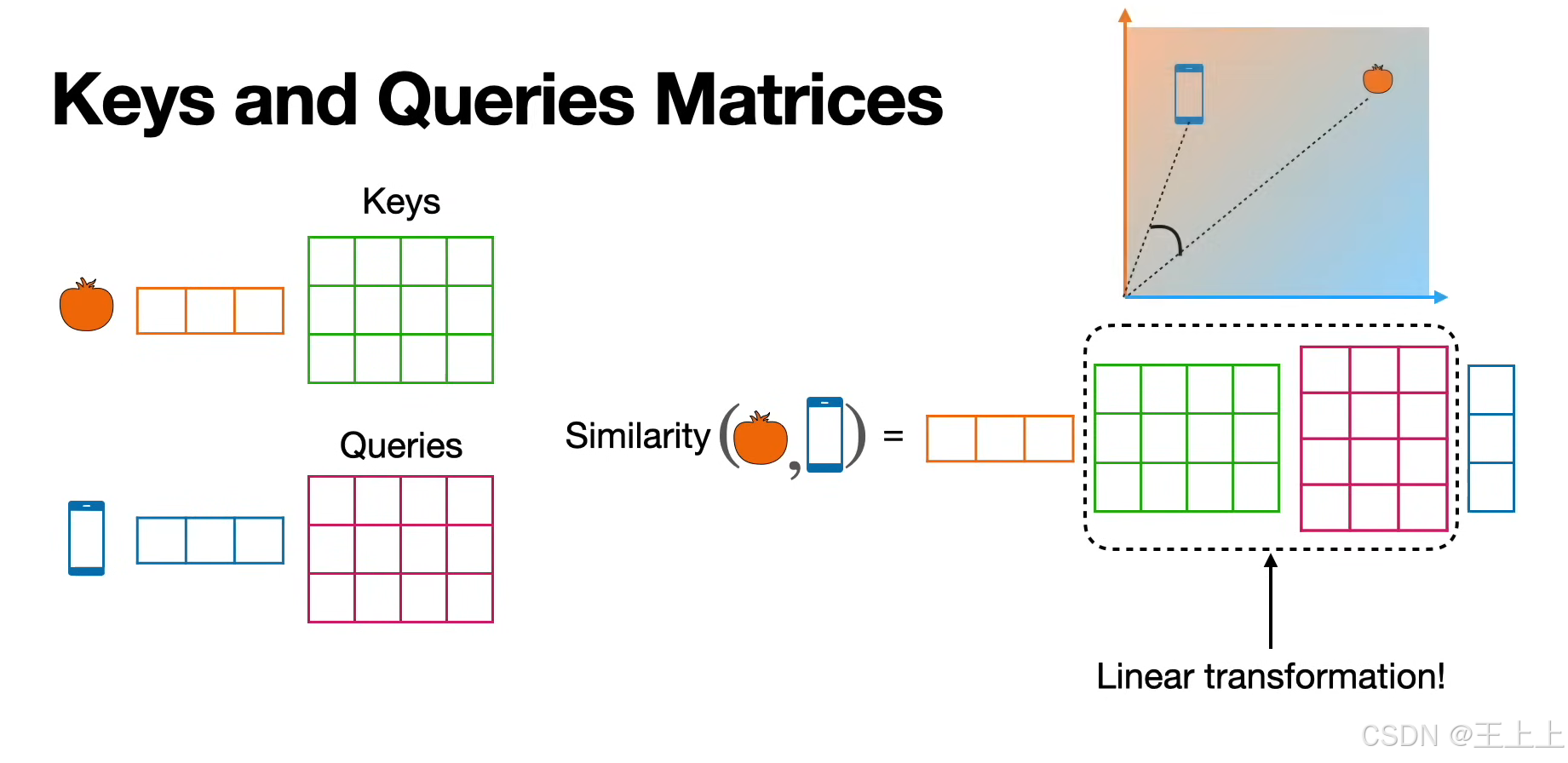
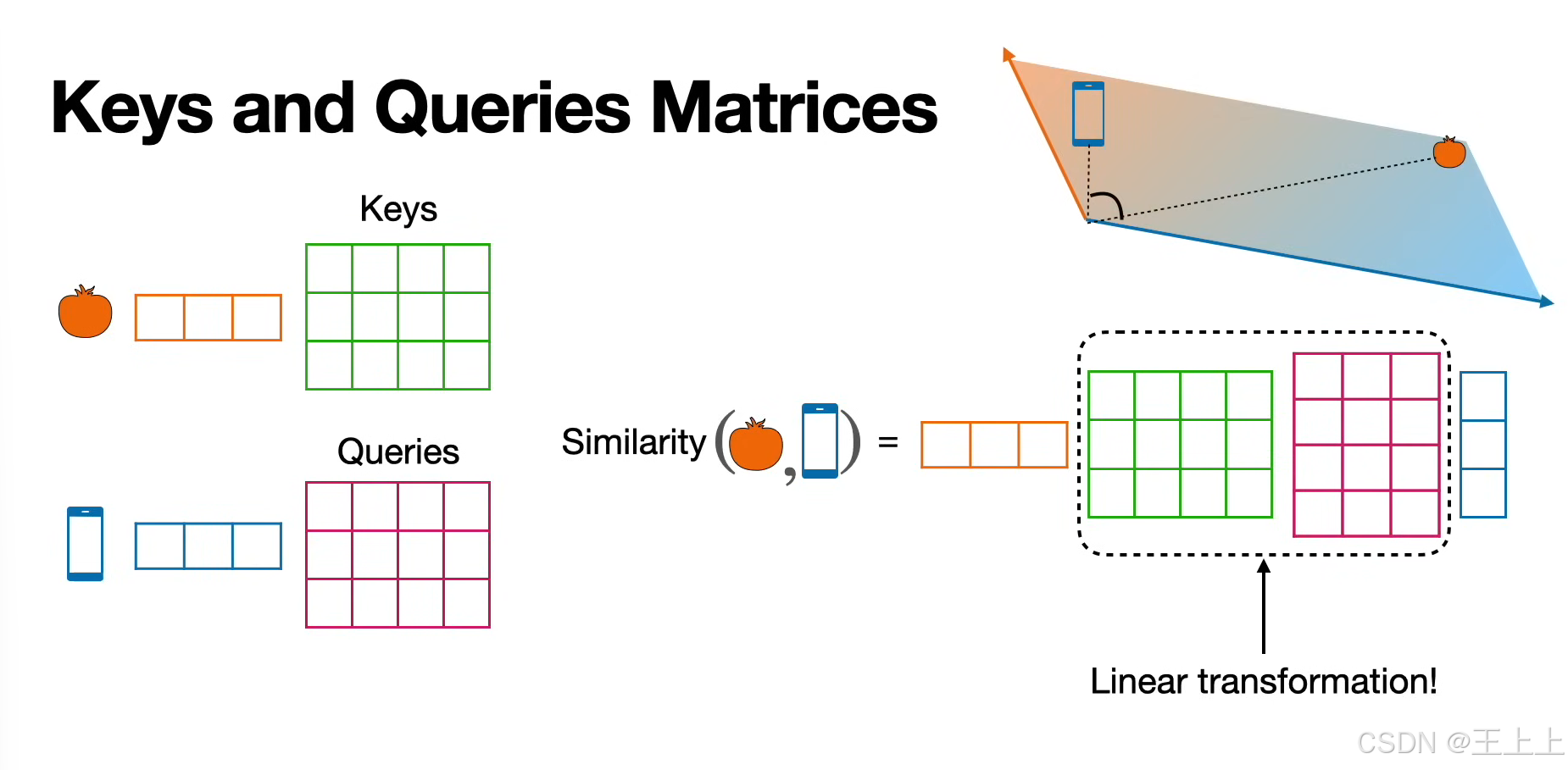
总结一下:
-
Q(查询矩阵)和 K(键矩阵)用于计算相似性:
- 它们的作用是计算所有单词之间的相似性(吸引力)。
- 在这个过程中,它们本身没有发生变化,仅用于相似性的计算和优化。
-
Q 和 K 相乘后,得到的是单词间的相似性矩阵:
- 这个矩阵表示单词之间的吸引力,但还未对词向量进行调整。
-
V(值矩阵)通过 Q 和 K 计算的吸引力进行调整:
- 计算出的吸引力用于改变 V 矩阵的表示方式,使其更符合语境。
- 这个过程不断优化 V,使其更好地表示单词的语义。
-
K、Q、V 的初始化与更新:
- K、Q、V 矩阵最初是基于词嵌入初始化的。
- V 矩阵在训练过程中会不断更新和优化,以更准确地表示单词。
- K 和 Q 仅参与计算相似性,本身不会在训练中更新。
-
优化后的 V 使词嵌入更优:
- 通过 K 和 Q 计算出的吸引力,调整 V,使其语义信息更加精准。
- 这一过程等效于在高维空间中寻找更好的单词表示,使其更加符合上下文。
总的来说,Q 和 K 负责计算单词间的相似性,V 通过这个相似性进行调整,最终优化单词的表示,使其更符合语境。
为了寻找相似性而做优化 -----》不断移动调整寻找最好的词嵌入矩阵

















 946
946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









