






刚好要用到多分类计算map的方法对模型结果进行评价,结果搜到的全是方法介绍,没有直接可用的代码,就自己按照其文献的方法进行代码编写,现在分享给大家,希望对大家有所帮助
计算方法
下面是截取的文章中对于map的描述:

然后网上对于这种方法给了一个测试样例的情况:
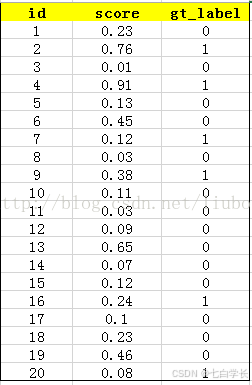
通过这个图我们可以知道id表示这些标签的序号,也可以知道图中一共有20个标签种类。而socre则是表示表示这些预测标签的概率,gt_label其实就是correct(k),只有当该预测标签是测试样例的真实标签时,值才为1。因此,图中表明该测试样例一共6个真实标签。
需要对上述结果按照score的大小进行降序排序
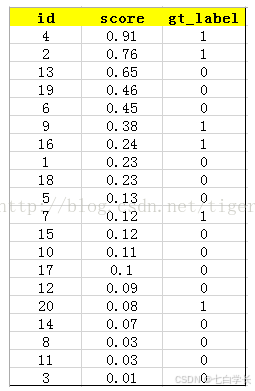
我们以top-5举例
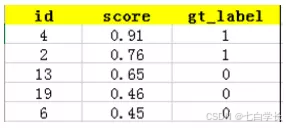
通过该图我们可以看出,TP=2,因为gt_label值为1的标签一共有两个,而真实标签一共有6个,因此也就有4个真实标签没有在里面(没有被预测到),所以我们得知FN=4,也就是有4个标签没有被召回。而剩下三个gt_label值为0的标签则是属于预测有该标签,但实际并无改标签的情况,因此FP=3。可以肯定的是,如果我们要计算top-k的P值,总有FP+TP=k,FN=m-TP,m为公式中样例真实标签的个数。因此,top-5的P和R我们就可以求得。
P=2/(2+3)=2/5
我们很容易就能看出分母其实就是k,即我们可以很容易的理解成
P=截止到k被预测到的真实标签的个数/k
R=2/(2+4)=2/6
我们也很容易的就能看出,分母其实是预测样例真实标签的总数量,即m,所以式子可以总结成
R=截止到k被预测到的真实标签的个数/m
另外,我们可以发现,P最大等于1
其他的top-k的计算方法请自行计算
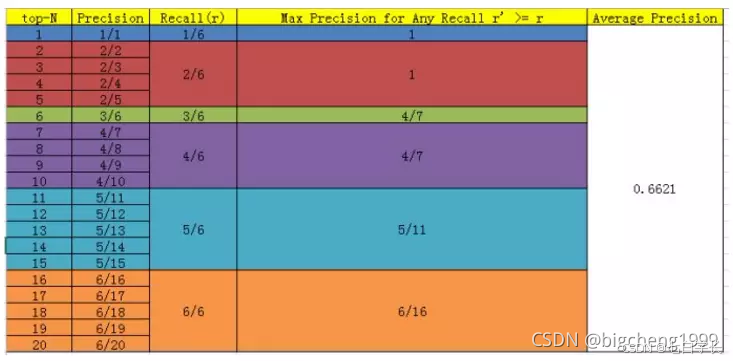
得到P,其实AP就好算了,AP=gt_label*P=correct(k)*P
还有一个很重要的点,我们需要清楚,在计算AP的时候,由于k的取值是从1到多标签的总数,所以我们需要将每个k对应P*correct(k)都相加,但是仔细观察我们就会发现,除了真实标签的correct=1,其他的correct的值均为0,因此我们其实只需要计算截止到真实标签的k对应的P就好,这里用例子解释比较容易理解,比如某个样例有两个标签,L1、L2,设它们的索引为I1、I2(注意索引是从1开始的,因为k是从1开始的),且我们规定,L1比L2的score(预测概率)要高,因此I1比I2要小。通过前面的推理我们很容易就能推出来,P1=1/I1,P2=2/I2,AP=(1/I1+2/I2)/2。注意,在实际编写代码中,I1和I2的顺序千万不要混。
代码
import xlrd
import numpy as np
inpath = r'a.xls'
def extract(inpath,sheet_index,label_index,col_index):
# data = pd.read_excel(inpath)
data = xlrd.open_workbook(inpath, encoding_override='utf-8')
table = data.sheets()[sheet_index] # 选定表
nrows = table.nrows # 获取行号
ncols = table.ncols # 获取列号
label = []
prb = []
for i in range(1, nrows): # 第0行为表头
alldata = table.row_values(i) # 循环输出excel表中每一行,即所有数据
label_value=alldata[label_index]
label.append(label_value)
result = alldata[col_index] # 取出表中第二列数据
prb.append(result)
return label,prb
def ap_statis(y_true1,label):
# 计算单个类的ap
ap0_num1 = 0
ap0_num2 = 0
ap0 = []
for i in range(0,len(y_true1)):
ap0_num1 =ap0_num1+1
if y_true1[i] == label:
ap0_num2 = ap0_num2+1
ap_precision = ap0_num2/ap0_num1
ap0.append(ap_precision)
else:
continue
mean0 = np.mean(ap0)
return mean0
def map(inpath):
ap_list = []
for i in range(0,4):
(y_true, y_pred) = extract(inpath, 0, i, i)#这里其实重复取了一列,用到的其实只有ytrue
label = i
ap = ap_statis(y_true,label)
ap_list.append(ap)
map = np.mean(ap_list)
return map
print('map:',map(inpath))
提示:xls文件中每一列表示每一类按照score排序完的label,因为我是四分类,所以设置的是4循环,其他的可以根据自己情况自行修改。
上述方法介绍转载自此处

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









